✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨
✨ 个人主页:余辉zmh--CSDN博客
✨ 文章所属专栏:MySQL篇--CSDN博客

文章目录
索引
一.MySQL与存储
MySQL给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中;但是磁盘是计算机中的一个机械设备,相比于其他的电子元件,磁盘效率是比较低的 ,再加上IO本身的特征,可以知道,如何提交IO效率,是MySQL的一个重要话题(接下来的内容全部都是围绕这个话题来展开)。
1.MySQL,系统和磁盘三者之间的IO交互
现代操作系统的内存被划分为两个主要区域:
-
用户空间:应用程序运行的地方,MySQL服务器进程在此空间运行
-
内核空间:操作系统内核运行的地方,负责系统级操作
首先MySQL作为一个应用程序,运行在操作系统的用户空间中,他并没有直接访问硬件设备的权限,这是现代操作系统的一个重要安全特性------内存保护机制;
当MySQL需要读取或写入数据时,不能直接访问磁盘,必须通过操作系统作为中介,由操作系统去访问磁盘,因此三者之间的IO交互过程就是:MySQL------>系统------>磁盘。
IO交互流程详解:
- 请求发起阶段
MySQL需要读取磁盘数据时,首先在用户空间发起请求,通过系统调用进入内核空间;
- 权限切换
用户态 → 内核态:系统调用触发CPU模式切换;
权限提升:获得直接访问硬件和内核资源的权限;
- 内核处理阶段
操作系统内核接收到请求后:
检查文件系统缓存;
如果缓存未命中,向磁盘控制器发送I/O请求;
将数据从磁盘读取到内核缓冲区(
4KB页大小);
- 数据传递阶段
内核缓冲区 → MySQL缓冲区:将
4KB的数据拷贝到用户空间的MySQL缓冲区;数据整合:MySQL可能将
多个4KB页组合成16KB的数据库页;
- 返回用户态
系统调用完成,CPU重新切换回用户态,MySQL继续在用户空间处理数据;
关键理解点:
空间隔离:
MySQL服务器和操作系统都在内存中运行;
但工作在不同的内存空间:用户空间 vs 内核空间;
这种隔离确保了系统安全性和稳定性;
双重IO概念:
- 系统与磁盘的IO交互:磁盘数据拷贝到内核缓冲区(4KB);
- MySQL与系统的IO交互:内核缓冲区数据拷贝到MySQL缓冲区(16KB);
2.为什么磁盘的最小读写单位是512字节的扇区,但系统却选择4KB作为IO操作的基本单位,这是因为:
- 如果操作系统直接使用硬件磁盘提供的数据大小进行交互,那么系统的IO代码,就和硬件强相关,就好比,一旦硬件发生变化,系统也必须跟着变化;
- 除此之外,单次IO交互只有512字节,还是太小了;IO单位越小,意味着读取同样的数据内容,需要进行多次磁盘访问,从会带来IO效率上的降低;
- 并且之前学习的文件系统,就是在磁盘的基本结构下建立的,而文件系统的基本读取单位就不是扇区512字节,而是数据块4KB;
因此,系统和磁盘进行IO交互时,是以数据块4KB为单位的。
3.为什么MySQL与系统这里IO操作的基本单位又是16KB,这是因为:
每次系统调用都涉及:
上下文切换:用户态↔内核态的CPU模式切换;
寄存器保存/恢复:需要保存当前进程状态;
内存拷贝:数据在用户空间和内核空间之间的传输;
调度开销:可能涉及进程调度;
而MySQL作为一款应用软件,可以想象成一种特殊的文件系统,他有着更高的IO场景,所以,为了提高基本的IO效率,MySQL的优化策略采用了批量处理原则:
减少系统调用次数:通过增加单次传输数据量来减少调用频率;
4KB → 16KB:将多个系统页合并成一个数据库页;
预读机制:一次性读取可能需要的连续数据;
MySQL直接和系统进行IO交互的基本单位是16KB (后面统一使用InnoDB存储引擎讲解),而不是系统的4KB;这也相当于MySQL间接和磁盘进行数据交互的基本单位也是16KB;这个16KB基本数据单元,在MySQL这里叫作page,也可以叫做页 (注意不是系统的4KBpage,两者有区别的)。
这样的优化策略,可以使原本的4次系统调用优化后变成只需要1-2次系统调用,大大减少了系统调用的开销;
此外还能提高数据吞吐量:
更大的数据块:每次传输更多有用数据;
更好的缓存命中率:16KB页可能包含更多相关数据;
减少碎片化:减少小数据块的随机访问;
4.最后总结:
MySQL中的数据文件,是以page(16KB页)为单位保存在磁盘中的;MySQL中表数据的增删查改(CURD操作),都需要通过计算,找到对应的插入位置,或者找到对应的修改或者查询的数据;- 而只要涉及到计算,就需要CPU的参与,需要先将数据从磁盘加载到内存中;
MySQL服务器在内存中运行的时候,在服务器内部就申请了一个Buffer Poll的大内存空间,来进行各种缓存。其实就是一个很大的用户级缓冲区,来和磁盘数据进行IO交互;- 所以在特定的时间内,数据一定是在磁盘中有,内存中也有。后续操作完内存数据后,再以特定的刷新策略,将内存上的数据刷新到磁盘中,保证数据被修改 。而这时,就涉及到磁盘和内存的数据交互,也就是IO了,而此时IO的基本单位就是page;
- 为了更高的IO效率,就一定要尽可能地减少IO的次数;
二.索引的理解
1.Page页模式
建立测试表
sql
mysql> CREATE TABLE users(
-> id int PRIMARY KEY,
-> age int NOT NULL,
-> name varchar(30) NOT NULL
-> );
Query OK, 0 rows affected (0.42 sec)
mysql> DESC users;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| age | int | NO | | NULL | |
| name | varchar(30) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.02 sec)插入多条记录
sql
mysql> INSERT INTO users values
-> (5, 20, '张三'),
-> (3, 18, '李四'),
-> (1, 19, '王五'),
-> (2, 21, '赵六'),
-> (4, 19, '陈七');
Query OK, 5 rows affected (0.01 sec)
Records: 5 Duplicates: 0 Warnings: 0查看插入结果
sql
mysql> SELECT * FROM users;
+----+-----+--------+
| id | age | name |
+----+-----+--------+
| 1 | 19 | 王五 |
| 2 | 21 | 赵六 |
| 3 | 18 | 李四 |
| 4 | 19 | 陈七 |
| 5 | 20 | 张三 |
+----+-----+--------+
5 rows in set (0.00 sec)根据上面的结果,可以发现虽然插入时故意设置成无序的,但是查看结果时,显示的确实有序的结果,这就是我们想要看到的一个现象。
那为什么变成有序的呢?这又是谁干的?这样排序又有什么好处呢?
首先数据按照id字段自动排序显示,这是因为id字段被定义为 PRIMARY KEY(主键),MySQL会自动为主键创建聚集索引;
聚集索引特性:在InnoDB存储引擎中,表数据实际上是按照主键的顺序物理存储的;
所以当查看数据时,MySQL优化器会选择使用主键索引来扫描数据,自然就按照主键顺序返回结果;
因此变成有序是因为聚集索引的特性以及查询优化,这个工作当然就是由MySQL数据库存储引擎自动完成的了。
至于这样排序有什么好处,在回答这个问题之前先来回到另一个问题:
为什么MySQL与磁盘的IO交互采用Page模式,而不是用多少,加载多少的逐条加载模式?
如果是逐条加载模式:
text
查找id=1 → 加载1次
查找id=2 → 加载2次(需要先加载id=1)
查找id=5 → 加载5次(需要加载id=1,2,3,4,5)而Page模式:
text
查找id=1 → 加载1个page(包含id=1,2,3,4,5)
查找id=2 → 从内存缓冲区获取(无需IO)
查找id=5 → 从内存缓冲区获取(无需IO)在前面已经提到过:为了更高的IO效率,就需要减少IO交互的次数;
显然采用逐条加载的方式,随着数据越来越多,当要查询较大的id值时,所需要的加载次数就会越来越大;而Page方式可以一次性加载多个数据(16KB大小),加载后保存在MySQL缓冲区中,即使部分数据本次用不到,但是可能在之后的查询中就会用到,这时候就不需要重新和磁盘进行IO交互,而是直接从缓冲区中读取即可,这样就大大的减少了IO交互的次数;所以采用Page方式进行IO交互,而不是逐条加载的方式。
明白了这一点,再来看为什么需要进行排序?
排序的重要性:
- 局部性原理:相同的数据很可能被一起访问;
- 预读优化:MySQL可以预测性的加载后续页面;
- 缓存命中率:有序数据更容易保持在内存中;
- 减少磁盘寻道:有序数据在磁盘中的扇区地址也是连续的,顺序访问减少磁头移动
理解单个Page
一个表中如果有大量的数据,就需要大量的page进行存储,也就是说内存中会存在大量的page;因此系统需要对这些page进行管理,管理方式就是先描述再组织,先描述:将page抽象成一个个的结构体,再组织:用数据结构将每个page组织起来;并且数据库表本质上就是文件,所以一个独立的文件是由一个或多个page组成的。
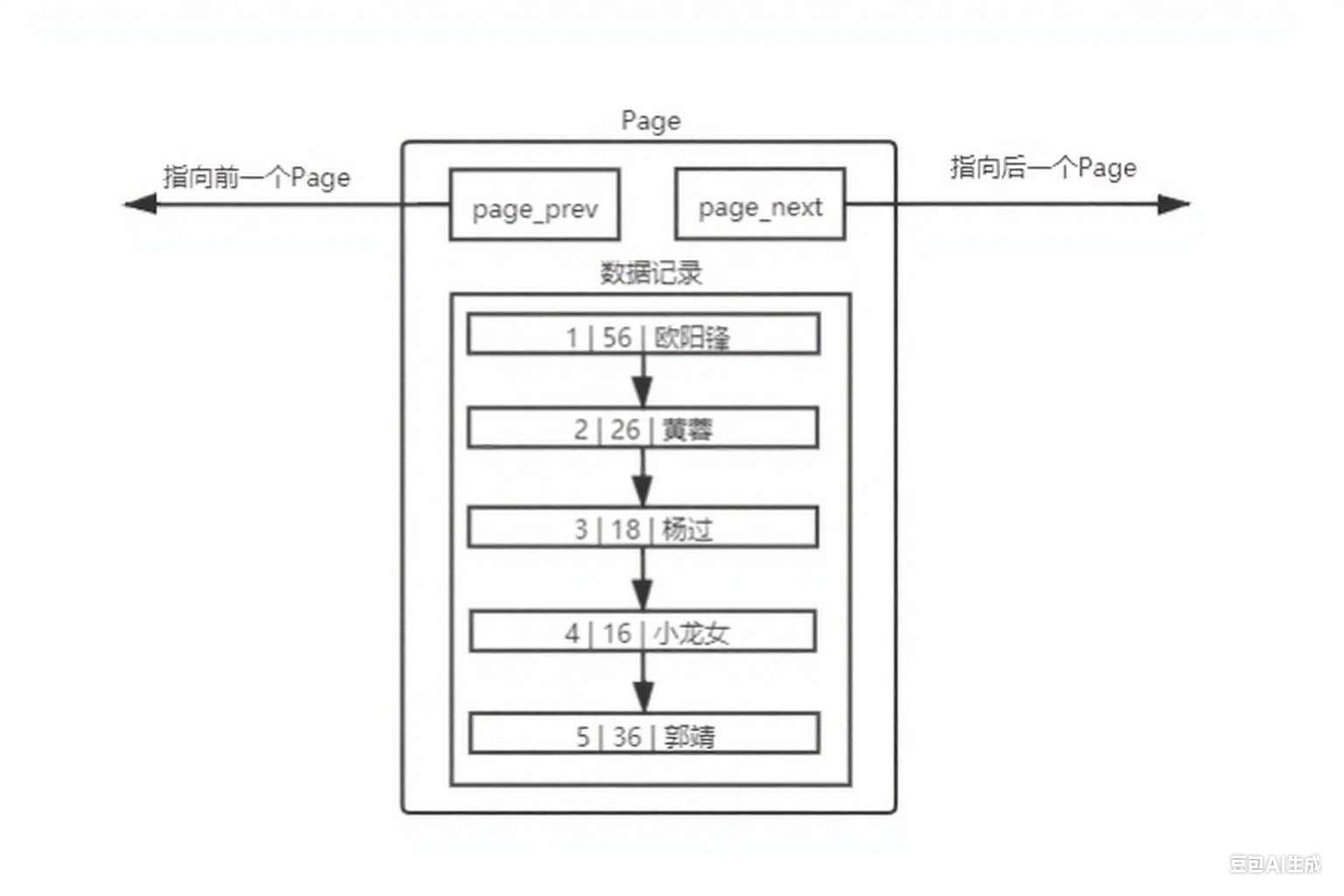
不同的Page,在MySQL中,都是16KB,使用prev和next构成双向链表;因为有主键得存在,MySQL会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看出,数据是有序且彼此关联的;
所以前面提到得存储数据时要进行排序的好处,除了前面提到的几点之外,还有一点就是:
Page内部存放数据的模块,本质上也是一个链表结构,链表的特点也就是增删查改,查询修改慢,所以优化查询的效率是必须的;正是因为有序,在查找的时候,从头到后都是有效的查找,没有任何一个查找是浪费的,而且,如果运气好,是可以提前结束查找过程的。
理解多个Page
在上面的页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据;
那假如有1千万条数据,就一定需要多个Page来保存1千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的;那么,查找特定一条记录,也一定是线性查找;这效率就会大大降低。
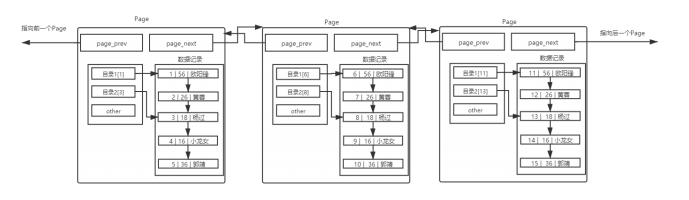
两次链表遍历:
-
页间遍历:从第一个Page开始,逐个遍历Page链表,直到找到目标Page;
-
页内遍历:在目标Page内部,从第一条记录开始,逐个遍历记录链表,直到找到目标数据;
为了解决数据量过大时,两次链表遍历带来的效率低下问题,就需要引入一个新的概念页目录来解决;
2.页目录
先来理解一下什么是页目录?
想象一下你有一本很厚的书,比如《哈利波特》全集;这本书有几千页,如果你想快速找到某个特定的章节或内容,你会怎么做?
方法1:从头开始一页页翻
- 这就像没有索引的数据库表,要找到某条记录需要全表扫描;
方法2:使用目录
-
书的前面有目录,告诉你每个章节在第几页;
-
这就是页目录的作用!
单页情况优化
页内目录管理:
-
一个数据页内部包含页目录 和数据记录;
-
每个页目录项由:键值+指针构成;
-
这里的指针 指向的是某行数据记录 的位置,也就是说页内目录管理的级别是行;
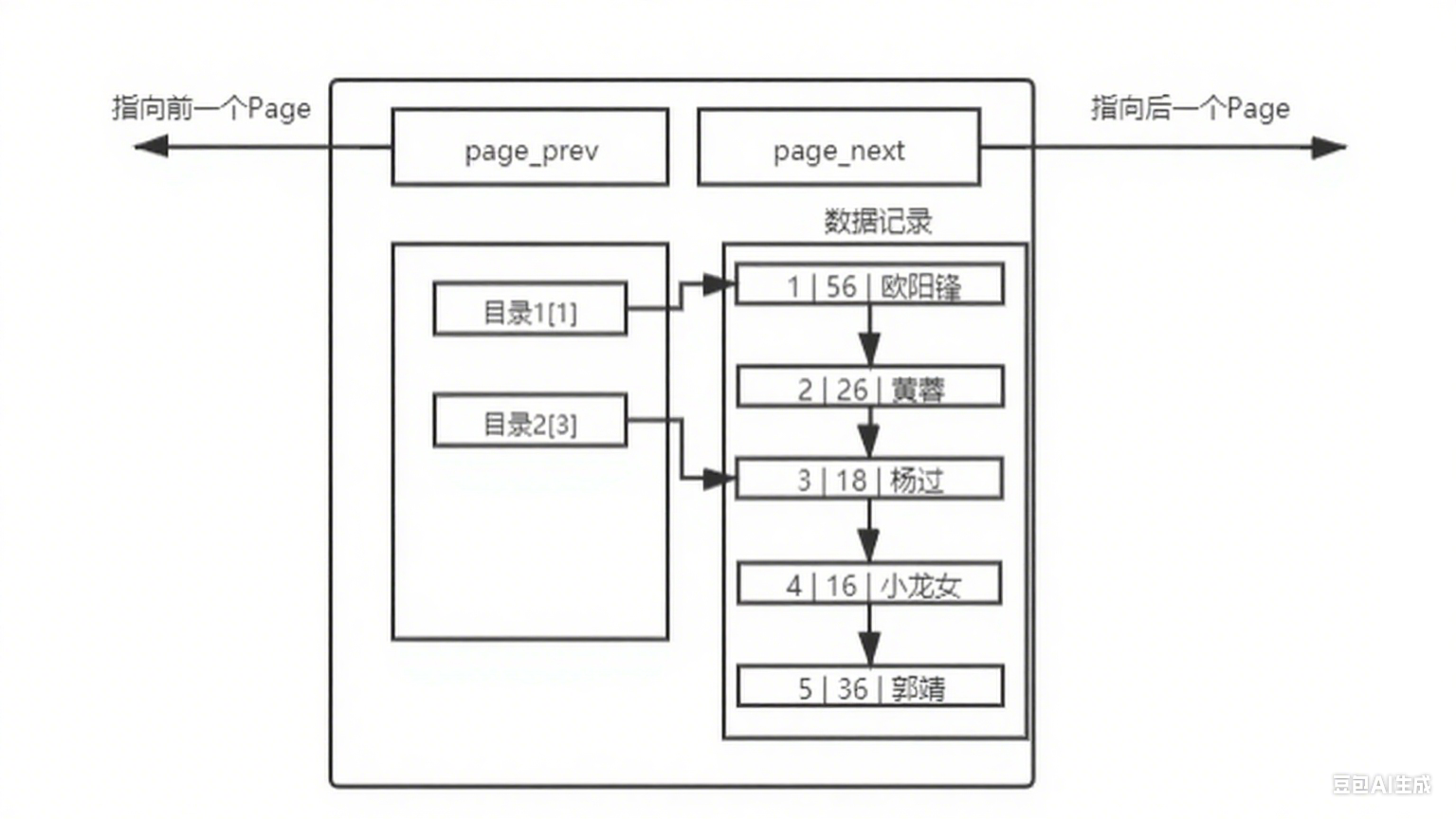
在一个Page内部,引入页目录之后,当要查找id=4的记录,之前必须先行遍历4次,才能拿到结果,现在直接通过页目录23就可以定位到新的起始位置,然后开始线性遍历,不用再从最起始位置开始遍历,大大提高了效率;
这时候再来看前面的那个问题,为什么存储数据时要进行排序?这里的页目录不就很好的体现出来优势了。
单个Page内部的页目录优化:
-
原来:从Page内第一条记录开始,逐个遍历记录链表;
-
现在:先在页目录中查找,找到最接近目标记录的位置,然后从该位置开始遍历;
-
效果:大大减少了Page内部的遍历次数;
多页情况优化
接下来就是解决数据页之间的链表遍历所带来的效率问题,根据数据页内部的解决方式,也可以给每个数据页也带上目录:
页间目录管理:
- 一个目录页内部只包含页目录 ,不包含数据记录;
- 每个页目录项由:键值+指针构成;
- 这里的指针 指向的是某页 的位置,也就是说页间目录管理的级别是页;
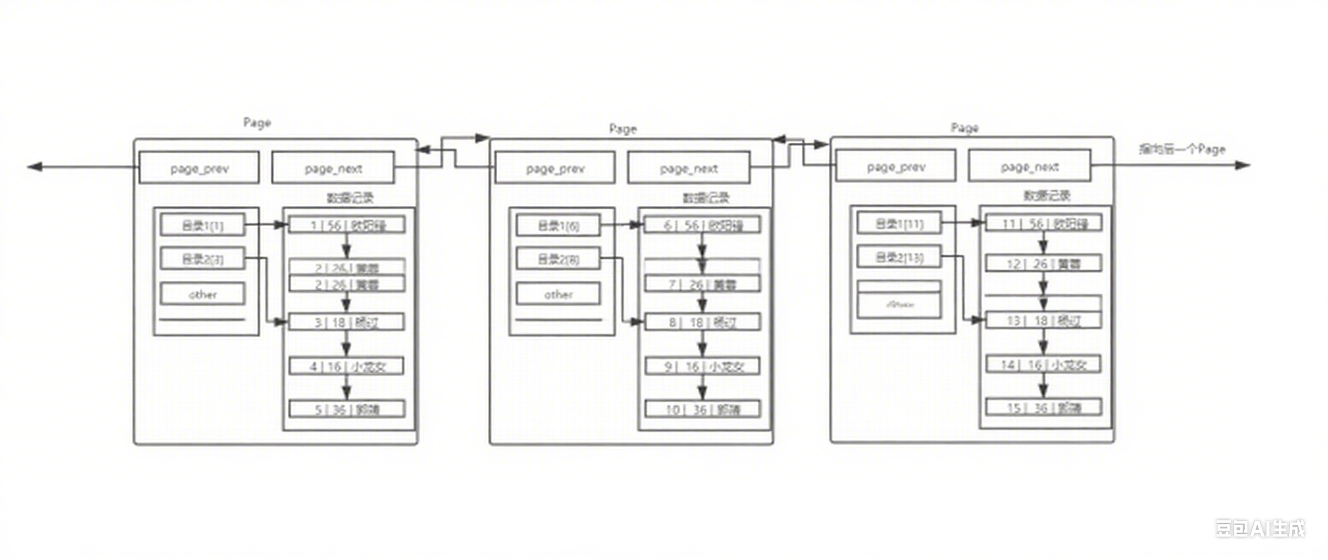
存在一个目录页来管理页目录,目录页中的键值指的是那一页中最小的数据,通过键值数据的比较,找到目标页,再根据指针到目标页中查找目标数据;
目录页的本质也是页,只不过数据页中的数据是表中的行数据记录,而目录页中的数据其实就是每个数据页的指针;
但是,对于数据记录量非常大的表,可能会出现页目录之间的链表也逐渐变长的情况,导致目录页之间的链表遍历降低效率,这里就不用担心了,根据页目录的思路,我们可以给每个目录页也添加页目录,形成多级索引结构,比如说一级页目录,二级页目录等等,逐步形成一个庞大的B+树;
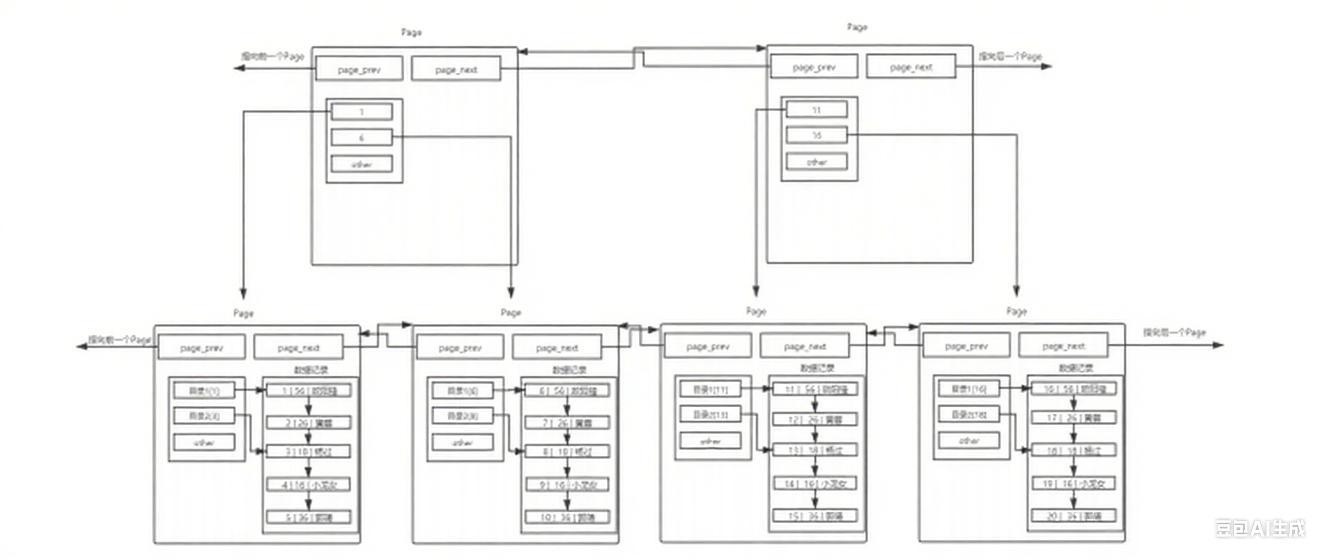
这正是MySQL B+树索引的核心设计思想。
3.B树 VS B+树
B树(B-Tree)结构
1.B树的基本概念
B树是一种自平衡的多路搜索树,专门为磁盘存储设计;
B树的特点
text
B树节点结构示例(m阶B树):
┌─────┬─────┬─────┬─────┬─────┐
│ P0 │ K1 │ P1 │ K2 │ P2 │
└─────┴─────┴─────┴─────┴─────┘
其中:
- Ki:关键字(索引值)
- Pi:指向子节点的指针
- 每个节点最多有m个子节点
- 每个节点最少有⌈m/2⌉个子节点(根节点除外)2.B树的性质
- 所有叶子节点都在同一层;
- 叶子节点和非叶子节点都存储索引和数据;
- 节点内关键字按升序排列;
- 满足平衡性要求;
3.B树查找过程
假设查找关键字K:
- 从根节点开始;
- 在当前节点中查找K;
- 如果找到,直接返回结果;
- 如果没找到,根据K的大小选择对应的子节点指针;
- 重复2,3,4步骤,直到找到或达到叶子节点;
B+树(B+Tree)结构
1.B+树的基本概念
B+树是B树的变种,是MySQL InnoDB存储引擎使用的主要索引结构;
2.B+树的结构特点
sql
B+树结构示例:
根节点(非叶子)
┌─────────┬─────────┬─────────┐
│ 10 │ 20 │ 30 │
└────┬────┴────┬────┴────┬────┘
│ │ │
┌────────┴──┐ ┌────┴────┐ ┌──┴────────┐
│ 5 │ 8 │ │ 15 │ 18 │ │ 25 │ 35 │ 非叶子节点
└──┬───┴─┬──┘ └─┬──┴─┬──┘ └─┬──┴──┬──┘
│ │ │ │ │ │
叶子节点层(存储实际数据):
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
│ 3 │ 4 │→│ 5 │ 6 │→│ 8 │ 9 │→│15 │16 │→│18 │19 │→│25 │26 │
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
↑_______________________________________|(双向链表)- 节点结构差异
sql
-- 非叶子节点(只存储索引)
┌─────┬─────┬─────┬─────┬─────┐
│ P0 │ K1 │ P1 │ K2 │ P2 │ -- 只有索引值和指针
└─────┴─────┴─────┴─────┴─────┘
-- 叶子节点(存储完整数据)
┌─────┬─────┬─────┬─────┬─────┬─────┐
│ K1 │ Data│ K2 │ Data│ ... │Next │ -- 索引值+完整数据+链表指针
└─────┴─────┴─────┴─────┴─────┴─────┘- 叶子节点链表结构
所有叶子节点通过双向链表连接,支持高效的范围查询;
3.B树 VS B+树
- 数据存储位置
B树:
- 非叶子节点和叶子节点都存储数据;
- 数据分散在整个树中;
B+树:
- 只有叶子节点存储完整数据;
- 非叶子节点只存储索引值;
- 查询性能对比
等值查询
- B树:可能在任何层找到数据,查询路径不固定;
- B+树:必须到叶子节点,查询路径固定,IO次数稳定;
范围查询
B树:需要进行中序遍历,效率较低;
B+树:利用叶子节点链表,效率极高;
- 存储空间利用率
B+树优势:
- 非叶子节点不存储数据,可以存储更多索引项;
- 相同的页面大小可以有更高的扇出比(fanout);
- 树的高度更低,查询IO次数更少;
计算示例:
假设页面大小16KB,索引项8字节,数据100字节:
- B树:每个节点约存储 16KB/(8+100)B ≈ 151个项;
- B+树非叶子:每个节点约存储 16KB/8B = 2048个项;
- 磁盘IO效率
B+树在磁盘IO方面的优势:
- 更低的树高度 → 更少的磁盘访问;
- 顺序访问友好 → 利用磁盘预读;
- 更好的缓存局部性;
这就是为什么MySQL InnoDB存储引擎选择B+树作为索引结构的核心原因,它完美适配了数据库系统对高效查询、范围搜索和磁盘IO优化的需求。
4.聚簇索引 VS 非聚簇索引
聚簇索引
1.基本概念
聚簇索引就是数据和索引存储在一起的索引,索引的叶子节点直接存储完整的行数据;
2.特点
text
聚簇索引结构:
根节点
/ | \
内部节点 内部节点 内部节点
/ | \ / | \ / | \
[叶子][叶子][叶子][叶子][叶子][叶子]
↓ ↓ ↓ ↓ ↓ ↓
完整行数据 完整行数据 完整行数据 完整行数据 完整行数据 完整行数据- 一个表中只能有一个聚簇索引(通常是主键);
- 数据按照索引顺序物理存储;
- 查询时通过聚簇索引找到叶子节点,直接返回整行数据;
非聚簇索引
1.基本概念
非聚簇索引是索引和数据分开存储的,索引叶子节点存储的是主键值。
2.特点
sql
非聚簇索引结构:
根节点
/ | \
内部节点 内部节点 内部节点
/ | \ / | \ / | \
[叶子][叶子][叶子][叶子][叶子][叶子]
↓ ↓ ↓ ↓ ↓ ↓
主键ID 主键ID 主键ID 主键ID 主键ID 主键ID
↓ ↓ ↓ ↓ ↓ ↓
通过主键再次查找聚簇索引获取完整数据- 一个表可以有多个非聚簇索引;
- 需要回表操作(先查索引,再查数据);
- 查询时通过非聚簇索引找到叶子节点,获取该记录对应的主键ID值;
- 再通过主键id在聚簇索引中查找完整行数据;
简单总结
聚簇索引:数据和索引在一起,查询快但只能有一个,适用于主键查询,范围查询,排序操作等场景;一次查找,直接获取整行数据;
非聚簇索引:索引指向数据位置,需要回表但可以有多个,适用于多条件查询,辅助查询条件等场景;两次查找,先获取主键,再回表通过主键获取整行数据;
在
MySQL InnoDB中:
主键 = 聚簇索引
其他索引 = 非聚簇索引
三.索引的操作
创建索引
创建主键索引
- 第一种方式
sql
-- 在创建表时,直接在字段名后指定主键索引
mysql> CREATE TABLE user1(
-> id int PRIMARY KEY,
-> name varchar(30) NOT NULL,
-> age int NOT NULL
-> );
Query OK, 0 rows affected (0.07 sec)- 第二种方式
sql
-- 在创建表的最后,指定某列或某几列为主键索引
mysql> CREATE TABLE user2(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL,
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.06 sec)- 第三种方式
sql
mysql> CREATE TABLE user3(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL
-> );
Query OK, 0 rows affected (0.05 sec)
-- 创建表以后添加主键索引
mysql> ALTER TABLE user3 add PRIMARY KEY(id);
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0主键索引的特点:
- 一个表中,最多有一个主键索引,当然可以是复合主键;
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为NULL,且不能重复;
- 主键索引的列基本上是int;
唯一键索引的创建
- 第一种方式
sql
-- 在表定义时,在某列后直接指定unique唯一属性。
mysql> CREATE TABLE user4(
-> id int UNIQUE
-> ,name varchar(30) NOT NULL,
-> age int NOT NULL
-> );
Query OK, 0 rows affected (0.07 sec)- 第二种方式
sql
-- 创建表时,在表的后面指定某列或某几列为unique
mysql> CREATE TABLE user5(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL,
-> UNIQUE(id)
-> );
Query OK, 0 rows affected (0.05 sec)- 第三种方式
sql
mysql> CREATE TABLE user6(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL
-> );
Query OK, 0 rows affected (0.05 sec)
-- 创建表以后添加唯一键索引
mysql> ALTER TABLE user6 add UNIQUE(id);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0唯一键索引的特点:
- 一个表中,可以有多个唯一索引;
- 查询效率高;
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据;
- 如果一个唯一索引上指定not null,等价于主键索引;
普通索引的创建
- 第一种方式
sql
-- 在表的定义最后,指定某列为索引
mysql> CREATE TABLE user7(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL,
-> index(id)
-> );
Query OK, 0 rows affected (0.06 sec)- 第二种方式
sql
mysql> CREATE TABLE user8(
-> id int,
-> name varchar(30) NOT NULL,
-> age int NOT NULL
-> );
Query OK, 0 rows affected (0.06 sec)
-- 创建表以后添加普通索引
mysql> ALTER TABLE user8 ADD INDEX(id);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0- 第三种方式
sql
CREATE TABLE user9(
id INT,
name VARCHAR(30) NOT NULL,
age INT NOT NULL
);
-- 指定索引名
CREATE INDEX idx_id ON user9(id);
-- 或
ALTER TABLE user9 ADD INDEX idx_id(id);普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多;
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引;
查询索引
- 第一种方式
sql
SHOW KEYS FROM 表名- 第二种方式
sql
SHOW INDEX FROM 表名- 第三种方式
sql
DESC 表名删除索引
- 第一种方式
sql
-- 删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;- 第二种方式
sql
-- 其他索引的删除
ALTER TABLE 表名 DROP INDEX 索引名- 第三种方式
sql
DROP INDEX 索引名 ON 表名ec)
Records: 0 Duplicates: 0 Warnings: 0
- 第三种方式
```sql
CREATE TABLE user9(
id INT,
name VARCHAR(30) NOT NULL,
age INT NOT NULL
);
-- 指定索引名
CREATE INDEX idx_id ON user9(id);
-- 或
ALTER TABLE user9 ADD INDEX idx_id(id);普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多;
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引;
查询索引
- 第一种方式
sql
SHOW KEYS FROM 表名- 第二种方式
sql
SHOW INDEX FROM 表名- 第三种方式
sql
DESC 表名删除索引
- 第一种方式
sql
-- 删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;- 第二种方式
sql
-- 其他索引的删除
ALTER TABLE 表名 DROP INDEX 索引名- 第三种方式
sql
DROP INDEX 索引名 ON 表名以上就是关于MySQL索引结构的讲解,如果哪里有错的话,可以在评论区指正,也欢迎大家一起讨论学习,如果对你的学习有帮助的话,点点赞关注支持一下吧!!!