使用nifi实现文件增量抽取
1、说明
本次nifi版本使用2.7.1,数据库使用postgresql,本次示例数据库查询结果为:
[ {
"path" : "aa.txt"
}, {
"path" : "bb.txt"
} ]2、基本思路
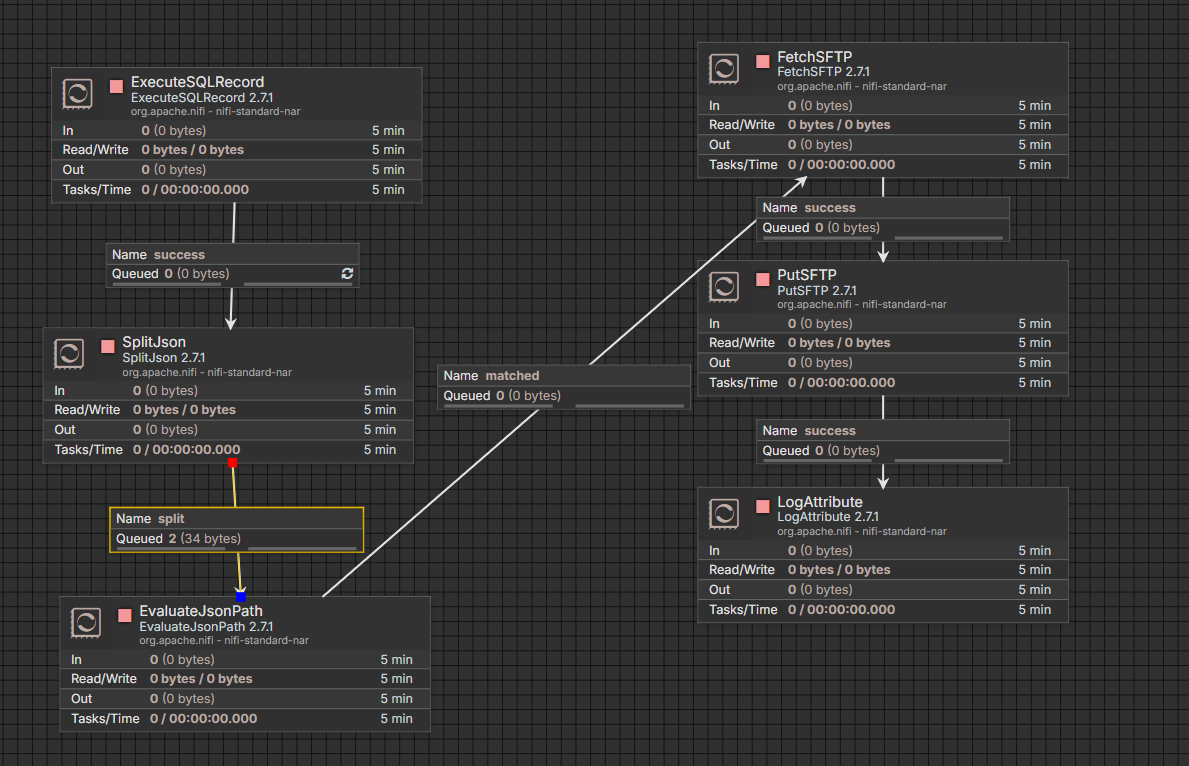
executeSQLRecord->SplitJson->EvaluateJsonPath->FetchSFTP(FetchFTP)->PutSFTP(PutFTP)
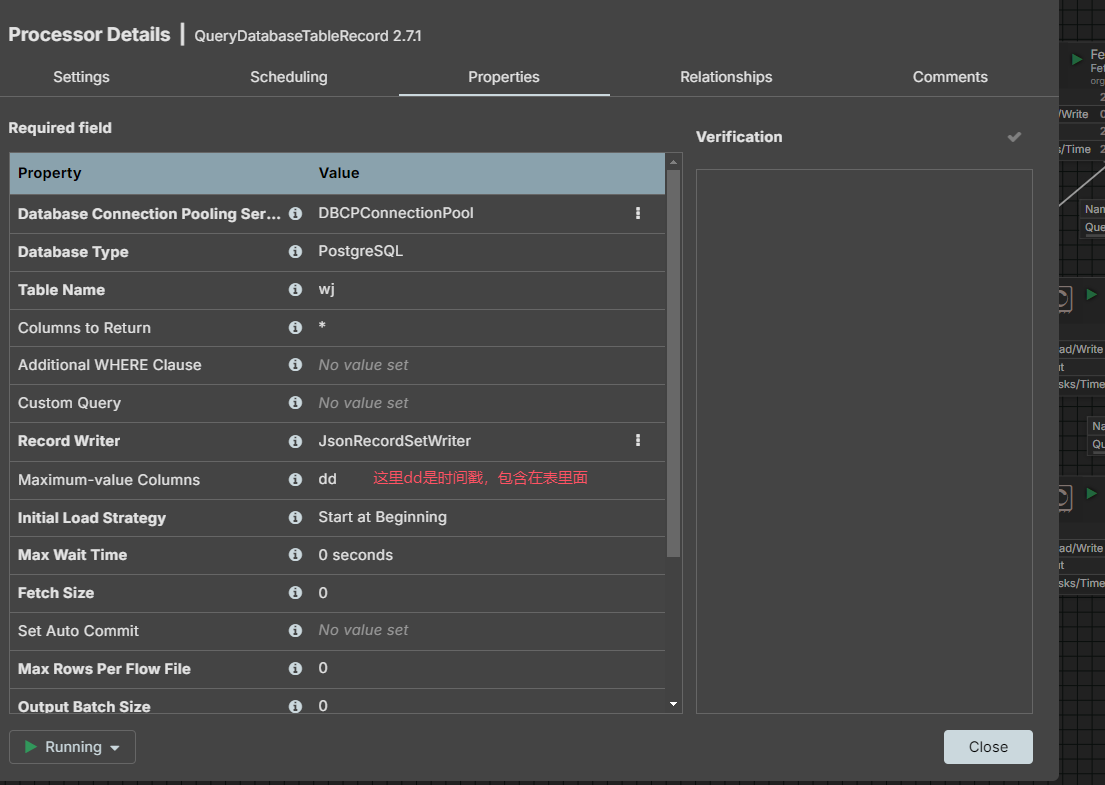
executeSQLRecord实现增量同步数据太麻烦,要实现增量同步,可以修改为QueryDatabaseTableRecord 来实现,关键属性:Maximum-value Columns (增量位点)如下:
3、各插件配置
executeSQLRecord
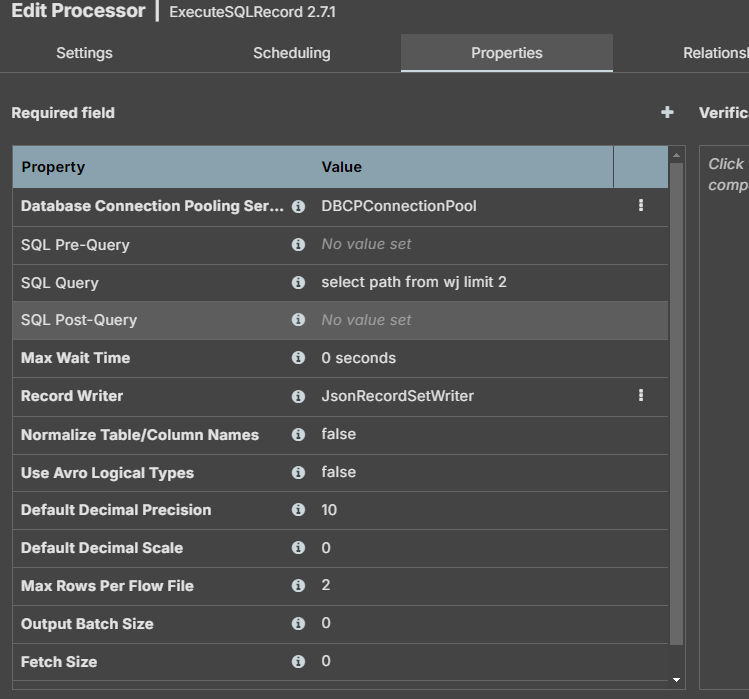
Database Connection Pooling Service 默认没有,新建:DBCPConnectionPool
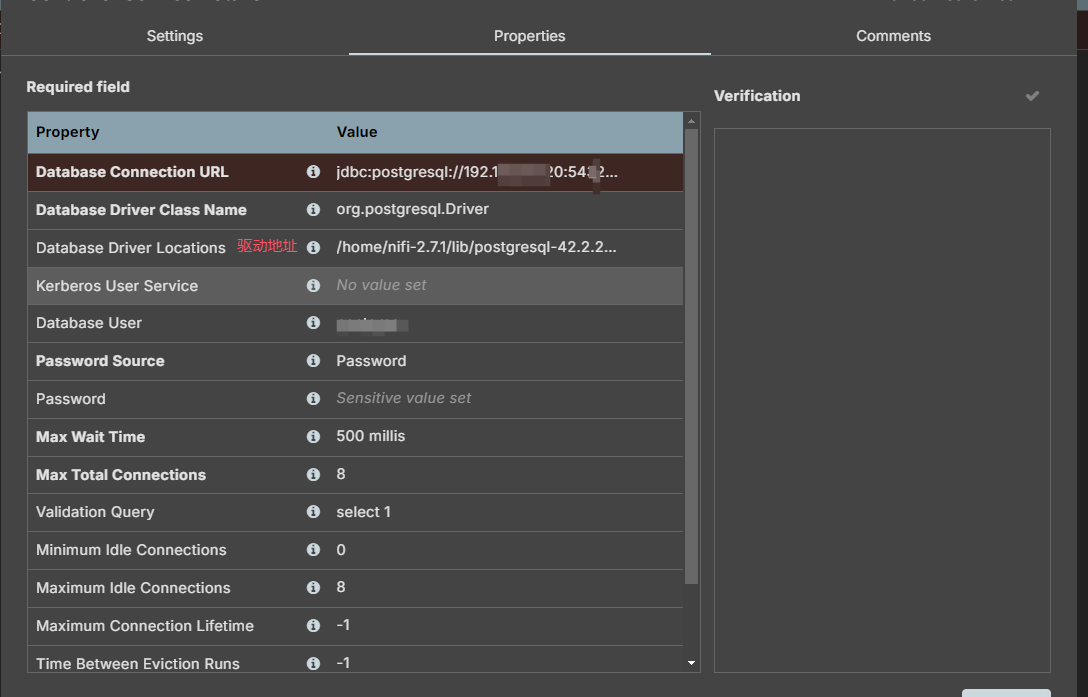
DBCPConnectionPool,连接使用jdbc连接就行,配置如下 :
新建数据库查询返回使用的格式服务JsonRecordSetWriter,在executeSQLRecord的Record Writer选择使用JsonRecordSetWriter:
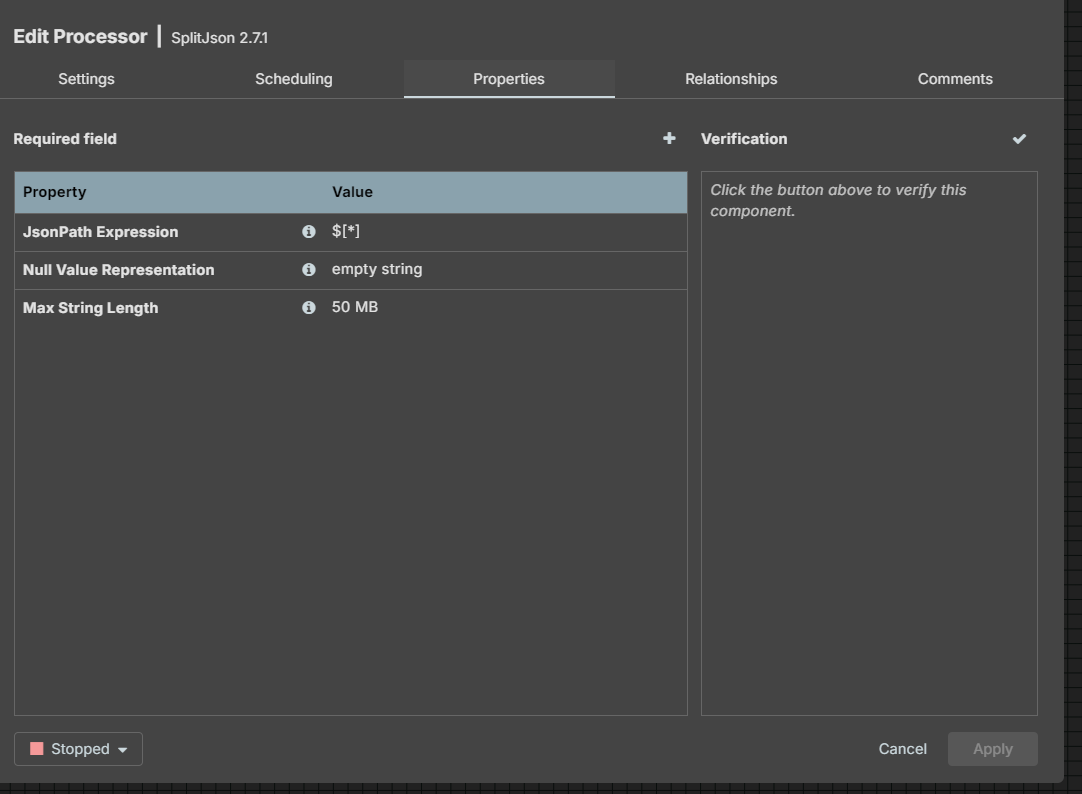
SplitJSON
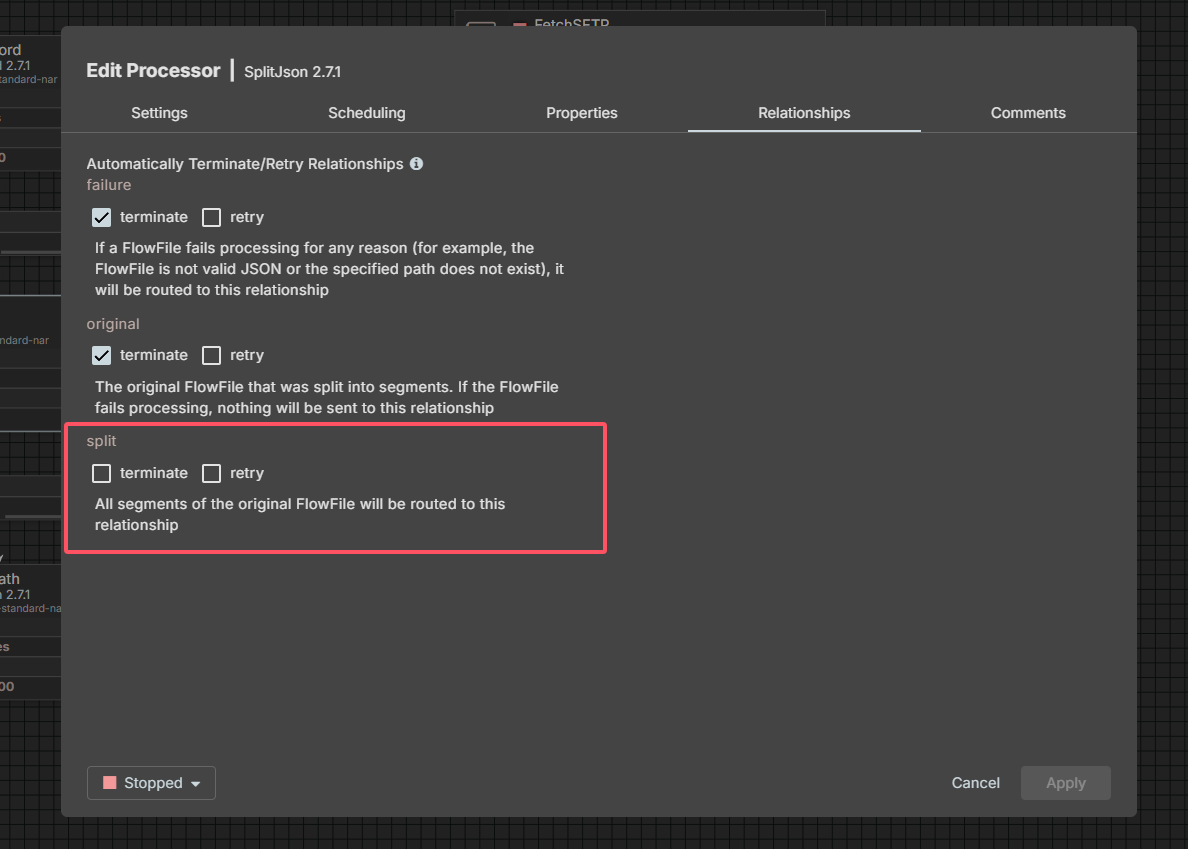
注意:在选择relationships时,不要勾选split,因为下一步的连接关系要使用split,如果这里勾选了split就会失败。因为返回的是JSON数组,所以JsonPath Expression使用$\*
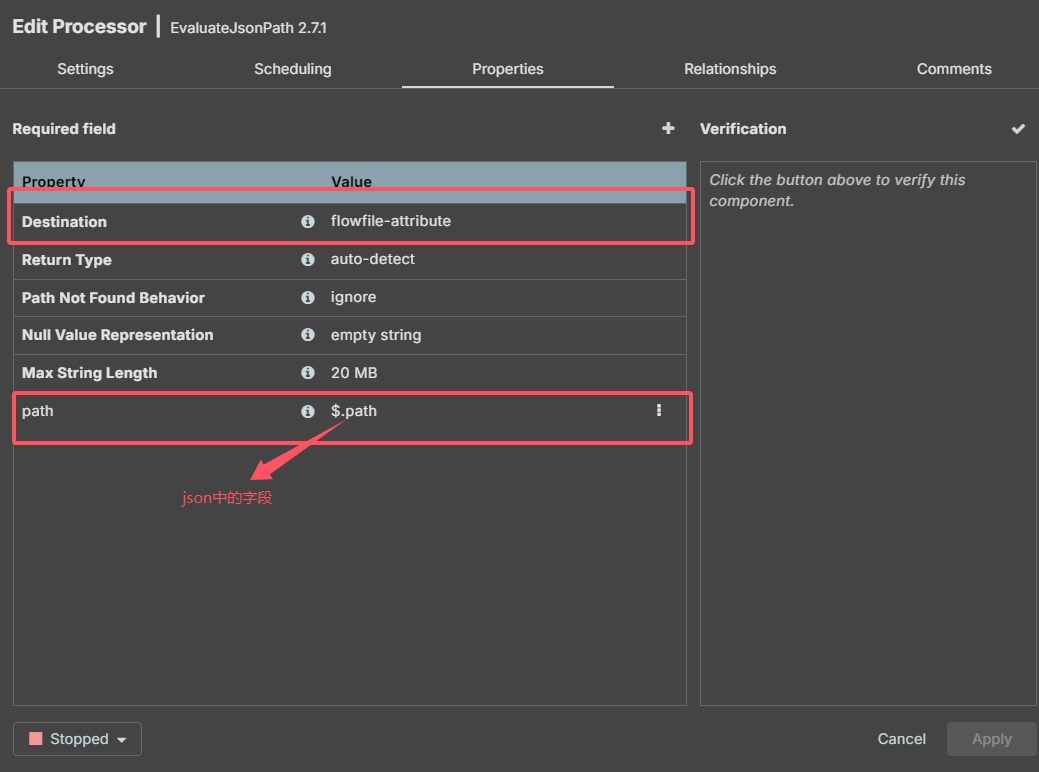
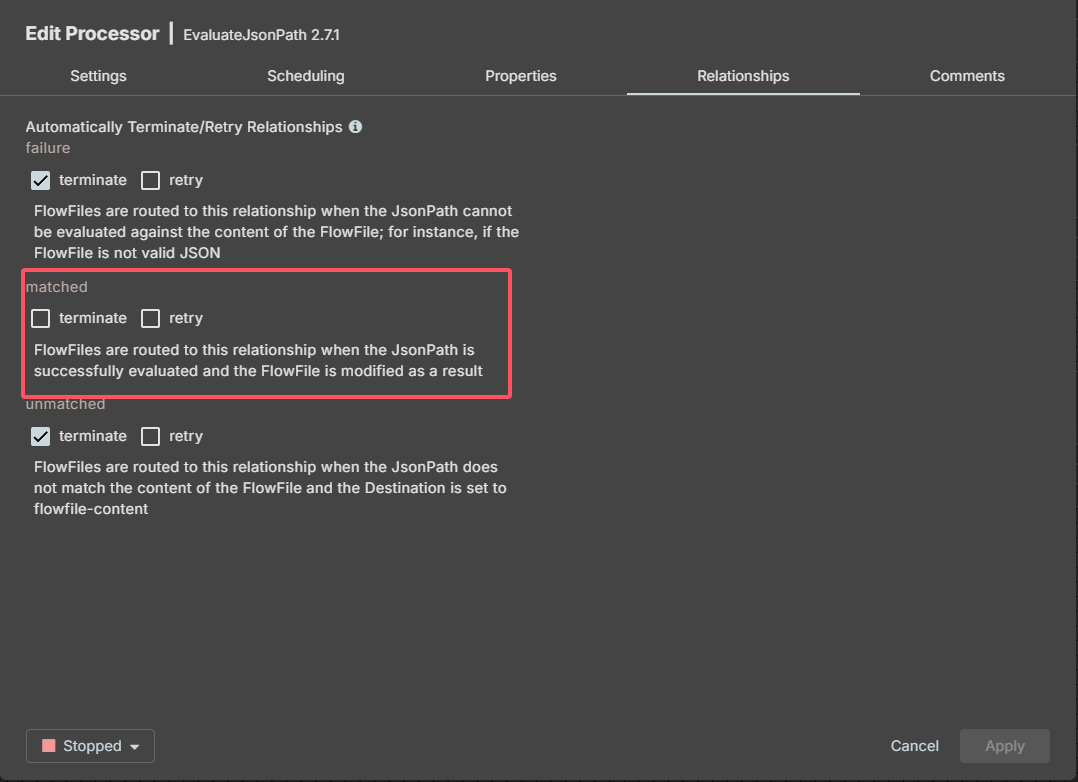
EvaluateJsonPath
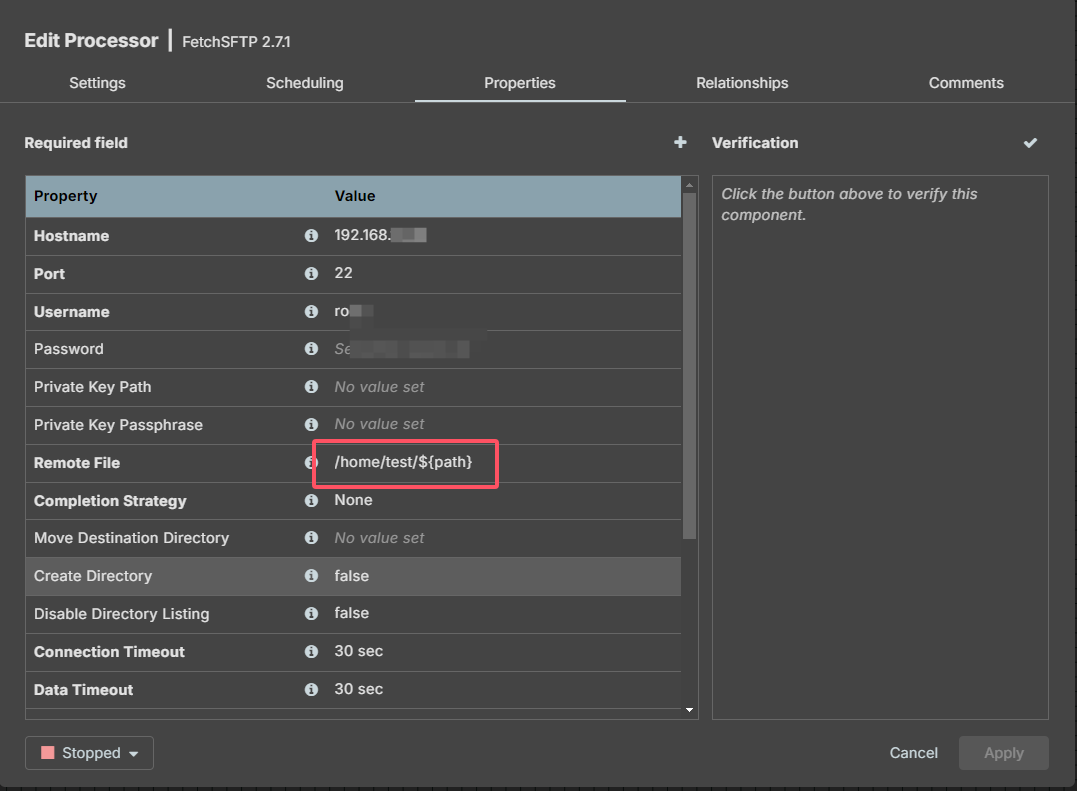
FetchSFTP
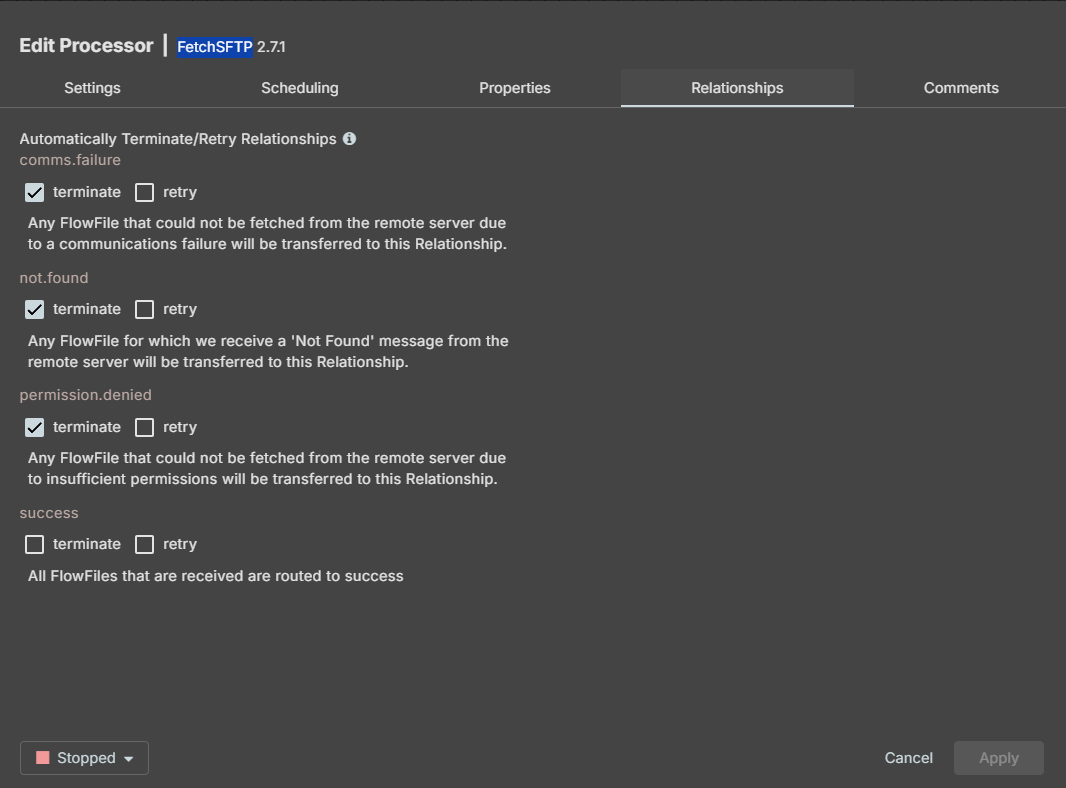
PutSFTP
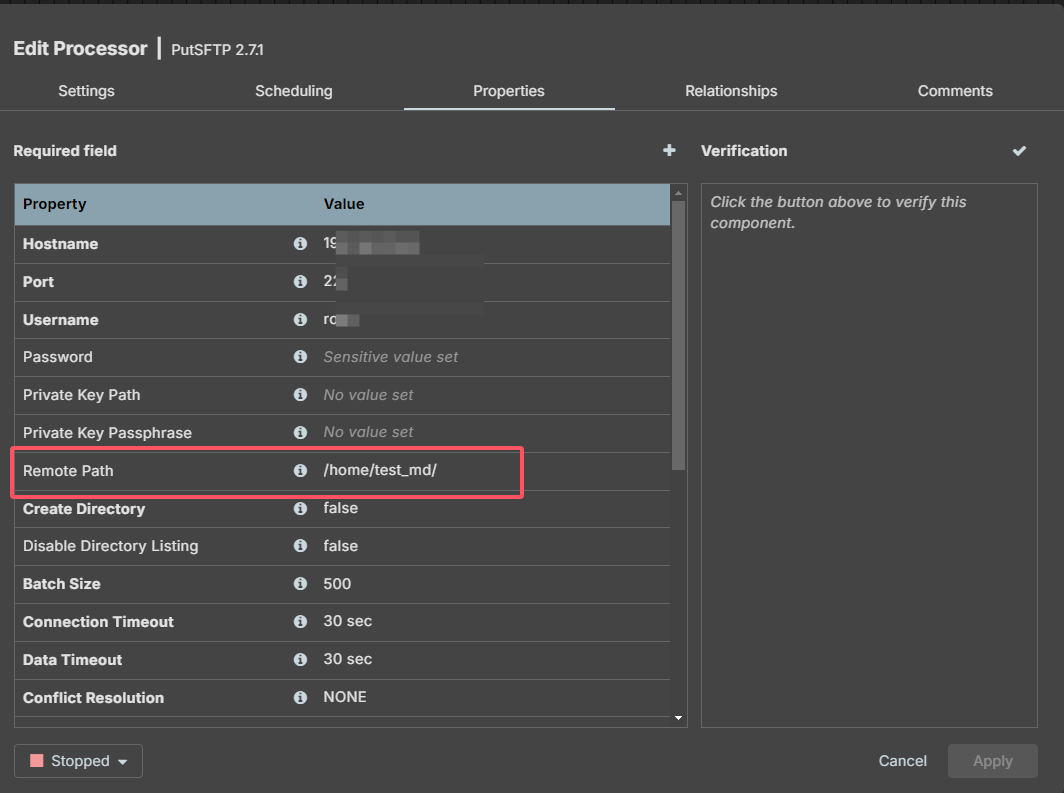
后语
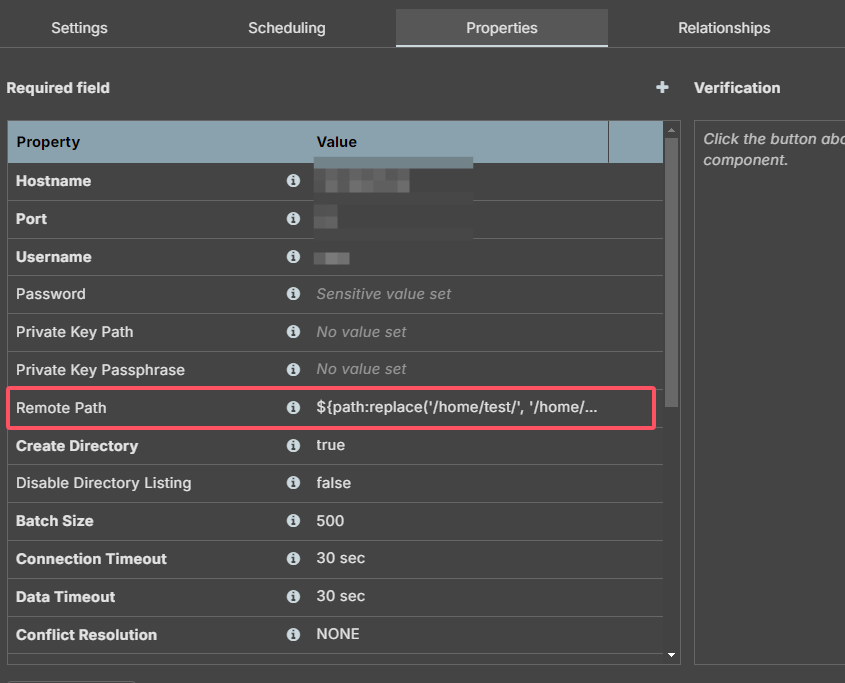
如果数据库路径包含文件夹,如:aa/aa.txt,源目录为:/home/test 目的目录为:/home/test_md,在配置putsftp(putftp)时,remote Path使用replace进行替换:
${path:replace('/home/test/', '/home/test_md/')}