常见的数据结构:二叉树、红黑树、Hash表、B-Tree
MySQL数据库作为一种结构化的数据库,存取操作的瓶颈在磁盘 I/O,因此,基于B-Tree改造的B+ Tree是最适合的数据结构。
为什么B Tree / B+ Tree"适合磁盘读取"?
核心设计思想
降低树高 = 减少磁盘 I/O 次数
为什么 B 系列树"矮"?
-
一个节点可以存 很多 key
-
一个节点大小通常 ≈ 一个磁盘页(16KB)
一个节点:
| k1 | k2 | k3 | ... | k500 |
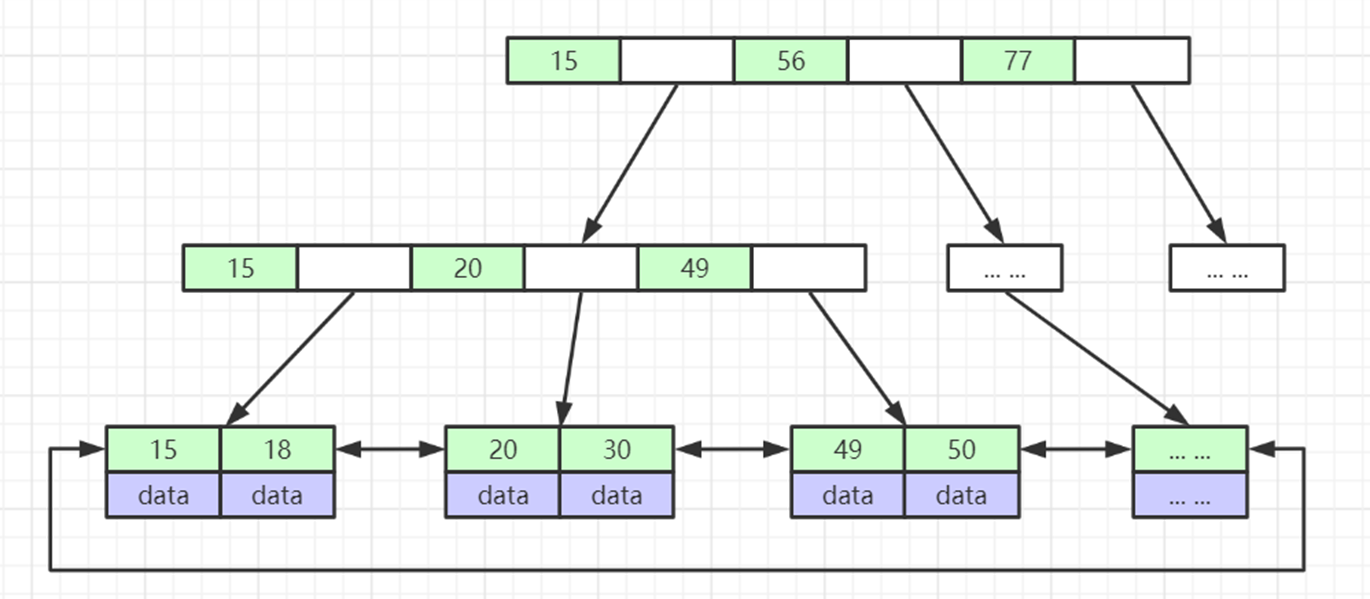
B+ Tree 是什么
B+ Tree = B Tree 的"数据库特化版本"
核心结构特征
-
非叶子节点
-
只存 key + 指针
-
❌ 不存 data
-
-
叶子节点
-
存 完整的 key + data
-
叶子节点之间 用指针连成有序链表
-
示意:
[17 | 35]
/ \
[3 | 9 | 15] → [17 | 20 | 25] → [35 | 40 | 50]B Tree vs B+ Tree 核心区别(表格)
| 对比点 | B Tree | B+ Tree |
|---|---|---|
| 数据存储位置 | 所有节点 | 仅叶子节点 |
| 非叶子节点 | key + data | 仅 key |
| 范围查询 | 中序遍历 | 叶子链表,极快 |
| 磁盘利用率 | 较低 | 更高 |
| 树高 | 较高 | 更低 |
| 顺序扫描 | 较慢 | 非常快 |
为什么 MySQL InnoDB 使用 B+ Tree?
1️⃣ 更低的树高(关键)
-
非叶子节点不存 data
-
一个页能放更多 key
👉 同样的数据量,B+ Tree 更矮
树高 ↓ 磁盘 I/O ↓ 性能 ↑
2️⃣ 范围查询是"数据库刚需"
SELECT * FROM orders WHERE create_time BETWEEN '2025-01-01' AND '2025-12-31';
-
B Tree:中序遍历,多次回溯
-
B+ Tree:找到起点 → 顺着叶子链表扫
👉 连续磁盘访问,极快
3️⃣ 更适合顺序扫描(ORDER BY / GROUP BY)
ORDER BY id;
B+ Tree 的叶子节点本身就是 有序链表
👉 不需要额外排序
4️⃣ 更稳定的查询性能
-
B Tree:命中位置不固定(可能在内部节点)
-
B+ Tree:所有查询最终都到叶子节点
👉 查询路径长度一致,性能稳定
5️⃣ 更符合缓存机制(Buffer Pool)
-
非叶子节点体积小
-
更容易常驻内存
👉 命中率更高
B+Tree的图形化描述