使用Tensor及Antograd实现机器学习
2.6节可以说是纯手工完成一个机器学习任务,数据用Numpy表示,梯度及学习是自
己定义并构建学习模型。这种方法适合于比较简单的情况,如果稍微复杂一些,代码量将
几何级增加。那是否有更方便的方法呢?本节我们将使用PyTorch的一个自动求导的包
------antograd,利用这个包及对应的Tensor,便可利用自动反向传播来求梯度,无须手工
计算梯度。以下是具体实现代码。
1)导入需要的库。
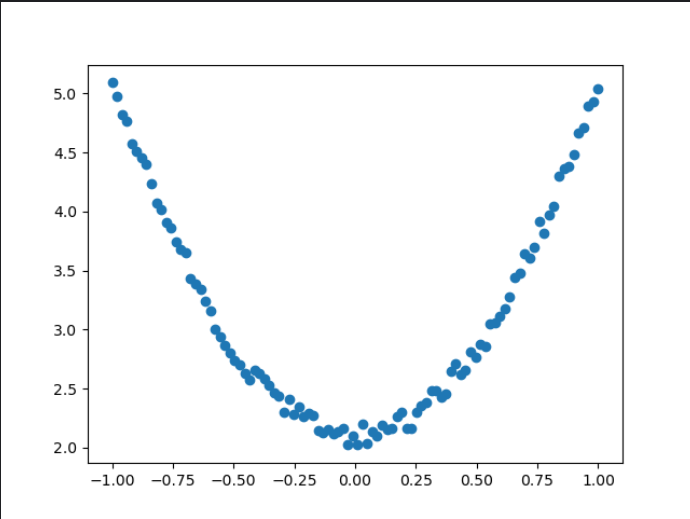
2)生成训练数据,并可视化数据分布情况。
python
import torch as t
from matplotlib import pyplot as plt
t.manual_seed(10)
dytpe=t.float
#生成x坐标数据,x为tensor,需要把x的形状转换为100x1
x=t.unsqueeze(t.linspace(-1,1,100),dim=1)
#生成y坐标数据,y为tensor,形状为100x1,另加上一些噪声
y=3*x.pow(2)+2+0.2*t.rand(x.size())
#画图,把tensor数据转换为numpy数据
plt.scatter(x.numpy(),y.numpy())
plt.show()运行结果:
3)初始化权重参数。
python
# 随机初始化参数,参数w、b为需要学习的,故需requires_grad=True
w = t.randn(1,1, dtype=dtype,requires_grad=True)
b = t.zeros(1,1, dtype=dtype, requires_grad=True)4)训练模型。
python
lr =0.001 # 学习率
for ii in range(800):
# 前向传播,并定义损失函数loss
y_pred = x.pow(2).mm(w) + b
loss = 0.5 * (y_pred - y) ** 2
loss = loss.sum()
# 自动计算梯度,梯度存放在grad属性中
loss.backward()
# 手动更新参数,需要用torch.no_grad(),使上下文环境中切断自动求导的计算
with t.no_grad():
w -= lr * w.grad
b -= lr * b.grad
# 梯度清零
w.grad.zero_()
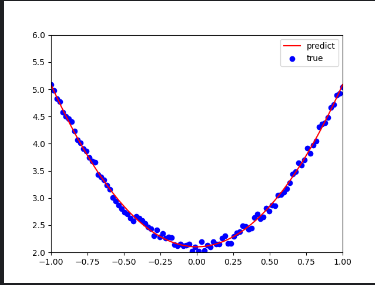
b.grad.zero_()5)可视化训练结果。
plt.plot(x.numpy(), y_pred.detach().numpy(),'r-',label='predict')#predict
plt.scatter(x.numpy(), y.numpy(),color='blue',marker='o',label='true') # true data
plt.xlim(-1,1)
plt.ylim(2,6)
plt.legend()
plt.show()
print(w, b)完整代码
python
import torch as t
from matplotlib import pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 允许重复加载OpenMP
os.environ['OMP_NUM_THREADS'] = '1' # 限制OpenMP线程数
t.manual_seed(10)
dtype=t.float
#生成x坐标数据,x为tensor,需要把x的形状转换为100x1
x=t.unsqueeze(t.linspace(-1,1,100),dim=1)
#生成y坐标数据,y为tensor,形状为100x1,另加上一些噪声
y=3*x.pow(2)+2+0.2*t.rand(x.size())
#画图,把tensor数据转换为numpy数据
#plt.scatter(x.numpy(),y.numpy())
#plt.show()
#随机初始化参数,参数w.b为需要学习的,故需requires_grad=True
w=t.randn(1,1,dtype=dtype,requires_grad=True)
b=t.zeros(1,1,dtype=dtype,requires_grad=True)
#训练模型
lr=0.001 #学习率
for ii in range(800):
#前向传播,并定义损失函数loss
y_pred=x.pow(2).mm(w)+b
loss=0.5*(y_pred-y)**2
loss=loss.sum()
#自动计算梯度,梯度存放在grad属性中
loss.backward()
#手动更新参数,需要用torch.no_grad(),使上下文环境中切断自动求导的计算
with t.no_grad():
w-=lr*w.grad
b-=lr*b.grad
# 梯度清零
w.grad.zero_()
b.grad.zero_()
#可视化训练结果
plt.plot(x.numpy(),y_pred.detach().numpy(),'r-',label='predict')#predict
plt.scatter(x.numpy(),y.numpy(),color='blue',marker='o',label='true')#true data
plt.xlim(-1,1)
plt.ylim(2,6)
plt.legend()
plt.show()
print(w,b)运行结果