以下是高频HQL面试题及对应SQL示例,涵盖核心语法、优化技巧和典型场景,可直接用于面试准备:
一、基础操作与DDL
1. 创建分区表 & 动态插入分区
sql
-- 创建外部分区表(按日期分区)
CREATE EXTERNAL TABLE logs (
user_id STRING,
event STRING,
duration INT
) PARTITIONED BY (dt STRING) -- 分区字段
STORED AS ORC
LOCATION '/user/hive/warehouse/logs';
-- 动态插入分区(自动创建分区目录)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO TABLE logs PARTITION (dt)
SELECT user_id, event, duration, event_date AS dt -- 最后一列为分区字段
FROM raw_logs;二、查询优化
2. 分桶表创建 & SMB Join优化
sql
-- 创建分桶排序表(分桶数4,按user_id排序)
CREATE TABLE users_bucketed (
user_id STRING,
name STRING
) CLUSTERED BY (user_id) SORTED BY (user_id) INTO 4 BUCKETS
STORED AS ORC;
-- 启用SMB Join
SET hive.optimize.bucketmapjoin=true;
SET hive.auto.convert.sortmerge.join=true;
SELECT /*+ MAPJOIN(b) */
a.user_id, a.event, b.name
FROM logs a JOIN users_bucketed b
ON a.user_id = b.user_id; -- 避免Shuffle三、窗口函数实战
3. 计算连续3天活跃用户
sql
SELECT user_id
FROM (
SELECT
user_id,
dt,
LAG(dt, 2) OVER (PARTITION BY user_id ORDER BY dt) AS lag2 -- 取前2天的日期
FROM logs
WHERE event = 'active'
) t
WHERE datediff(dt, lag2) = 2; -- 当前日期与前2天日期差2天(连续3天)// add by me-方法二
SQL统计连续登陆3天的用户(连续活跃超3天用户)_sql连续登录3天用户数-CSDN博客
SELECT user_id,
count(1) AS cnt
FROM
(SELECT user_id, DATE_SUB(dt, rn) AS sub_date
FROM
(SELECT user_id, dt, row_number() over( partition by user_id ORDER BY dt) AS rn
FROM logs) t
GROUP BY user_id, sub_date
) diffTable
GROUP BY user_id, sub_date
HAVING cnt >= 3
连续登陆(含间隔)
llhttps://zhuanlan.zhihu.com/p/29641524870
4. 分组Top N(部门工资前三)
sql
SELECT dept, name, salary
FROM (
SELECT
dept, name, salary,
DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary DESC) AS rk
FROM employees
) t
WHERE rk <= 3;5,去除最大最小值求均值
https://zhuanlan.zhihu.com/p/28466428027
6.波峰波谷(快手)
https://zhuanlan.zhihu.com/p/1885646993512200080
7,AI无效oncall
https://zhuanlan.zhihu.com/p/1893678485387588081
四、数据倾斜解决方案
5. 大表Join倾斜Key打散
sql
-- 假设user_id='999'是倾斜Key
SELECT *
FROM (
SELECT
user_id,
event,
CASE WHEN user_id = '999' THEN concat(user_id, '_', rand()) -- 打散倾斜Key
ELSE user_id END AS join_key
FROM logs
) a
JOIN users b
ON a.join_key = b.user_id;五、高级函数与转换
6. 行列转换
sql
-- 行转列(聚合多行)
SELECT
user_id,
CONCAT_WS(',', COLLECT_LIST(event)) AS events -- 合并事件列表
FROM logs
GROUP BY user_id;
-- 列转行(拆分数组)
SELECT user_id, event_name
FROM logs
LATERAL VIEW EXPLODE(SPLIT(events, ',')) e AS event_name; -- events是逗号分隔字符串7. JSON解析
sql
SELECT
get_json_object(json_col, '$.user.id') AS user_id,
json_tuple(json_col, 'event', 'timestamp') AS (event, ts) -- 同时解析多字段
FROM json_logs;六、性能优化技巧
8. 谓词下推优化
sql
-- 优化前(全表扫描)
SELECT * FROM logs WHERE dt = '2023-08-12' AND duration > 1000;
-- 优化后(分区裁剪+列裁剪)
SELECT user_id, event -- 只取所需列
FROM logs
WHERE dt = '2023-08-12' -- 分区字段过滤
AND duration > 1000; -- ORC格式下自动谓词下推9. MapJoin手动指定
sql
SELECT /*+ MAPJOIN(small_table) */
big_table.id, small_table.name
FROM big_table
JOIN small_table ON big_table.id = small_table.id;七、场景题模板
10. 留存率计算(次日留存)
https://www.zhihu.com/question/294871305/answer/1903544000008417365
sql
SELECT
a.dt,
COUNT(DISTINCT a.user_id) AS dau,
COUNT(DISTINCT b.user_id) AS next_day_retained,
COUNT(DISTINCT b.user_id) / COUNT(DISTINCT a.user_id) AS retention_rate
FROM (
SELECT dt, user_id FROM logs WHERE event='login'
) a
LEFT JOIN (
SELECT dt, user_id FROM logs WHERE event='login'
) b
ON a.user_id = b.user_id
AND b.dt = DATE_ADD(a.dt, 1) -- 次日留存
GROUP BY a.dt;高频考点总结
| 类型 | 关键点 |
|---|---|
| 语法 | PARTITIONED BY vs CLUSTERED BY、LATERAL VIEW explode() |
| 窗口函数 | ROW_NUMBER()/RANK()/DENSE_RANK()、LAG()/LEAD()、ROWS BETWEEN |
| 优化 | 分区裁剪、列裁剪、MapJoin、SMB Join、随机数打散倾斜Key |
| 复杂类型处理 | COLLECT_LIST()/COLLECT_SET()、get_json_object() |
| 实战场景 | 留存率、连续登录、Top N、UV/PV统计 |
提示:面试时务必说明优化原理(如 "SMB Join通过分桶排序避免Shuffle"),并强调数据倾斜处理经验。
几个关键函数
ROWS BETWEEN
sum(sales_volume) over(rows between 1 preceding and current row) sum_sales
sum(sales_volume) over(rows between current row and unbounded following)
sum(sales_volume) over(rows between unbounded preceding and current row) sum_sales
sum(sales_volume) over(rows between current row and 2 following) sum_sales
sum(sales_volume) over(rows between 1 preceding and current row) sum_sales
LAG()/LEAD()
LAG(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY sort_column)
LEAD(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY sort_column)
示例场景
假设有员工薪资表 emp,包含 ename(姓名)、job(职位)、sal(薪资)。
- 获取前一行薪资 :
LAG(sal, 1) OVER (ORDER BY sal)可获取当前行前一行薪资。 1 - 设置默认值 :
LAG(sal, 1, 3.1415)当前行无前一行数据时,默认返回3.1415。 1 - 连续性检查 :通过
LAG(sal, 1)与LEAD(sal, 1)组合,可验证薪资是否连续。 24
ROW_NUMBER()/RANK()/DENSE_RANK()
dense_rank() over(partition by class order by pjs.sn_scores desc) as dense_rank
rank() over(partition by class order by pjs.sn_scores desc) as rank
row_number() over(partition by class order by pjs.sn_scores desc) as row_number
假设学生成绩表按分数降序排列:
- **ROW_NUMBER()**:1, 2, 3, 4, 5(完全按顺序分配) 12
- **RANK()**:1, 2, 2, 4(相同分数共享排名,后续跳过) 15
- **DENSE_RANK()**:1, 2, 2, 3(相同分数仍保持连续排名) 25
[ PARTITIONED BY ] vs [ CLUSTERED BY ]
CLUSTERED BY(分桶表设置)
作用:在建表时指定数据的分桶规则,物理上把数据分到多个文件(桶)中。
示例:
CREATE TABLE table_name (col1 INT, col2 STRING)
CLUSTERED BY (col1) INTO 4 BUCKETS;
原理:Hive 会根据col1的哈希值将数据分散到 4 个桶中,查询时可加速数据读取。
SORTED BY(桶内排序设置)
作用:在建表时指定桶内数据的排序规则。
示例:
CREATE TABLE table_name (col1 INT, col2 STRING)
CLUSTERED BY (col1) SORTED BY (col2 ASC) INTO 4 BUCKETS;
应用:适合需要频繁按col2过滤的场景,如时间字段。
DISTRIBUTED BY(MapJoin 优化)
作用:在INSERT OVERWRITE语句中控制数据分发,常用于优化 MapJoin。
示例:
INSERT OVERWRITE TABLE target_table
SELECT * FROM source_table
DISTRIBUTED BY (join_key);
PARTITIONED BY(分区表定义)
作用:创建分区表,数据按分区字段物理存储在不同目录中。
示例:
CREATE TABLE table_name (col1 INT, col2 STRING)
PARTITIONED BY (dt STRING);
查询优化:
SELECT * FROM table_name WHERE dt = '2023-01-01'; -- 直接过滤分区目录
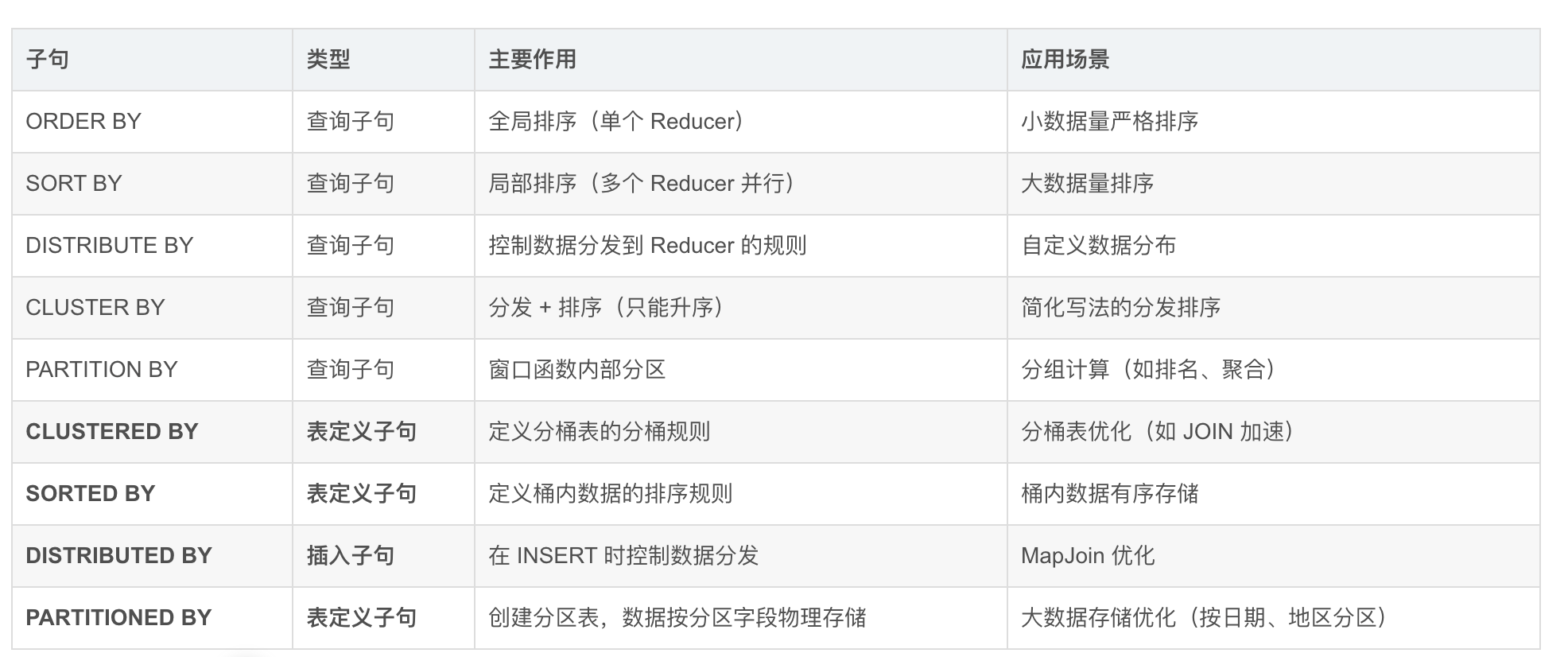
上表来源:
HiveSQL 入门避坑指南:搞懂这些 "BY",让你的 SQL 少跑 80% 的冤枉路_hive cluster by作用-CSDN博客
LATERAL VIEW explode()
Hive之explode()函数和posexplode()函数和lateral view函数_lateral view explode函数-CSDN博客
Hive中的explode函数、posexplode函数与later view函数_hive explode-CSDN博客