当AI遇到"临时抱佛脚"
你有没有遇到过这样的情况:老板突然让你给新来的实习生培训客服技能,但你只有5分钟时间?
你可能会这样做:
- 给他看几个优秀的客服对话记录
- 告诉他:"你看,客户这样问,我们就这样答"
- 然后推他上战场:"去吧,皮卡丘!"
神奇的是,这个实习生竟然真的学会了!
这就是今天我们要聊的主角:「上下文学习(In-Context Learning)」。它让AI像那个聪明的实习生一样,看几个例子就能上手新工作。

图1:传统训练 vs 上下文学习的对比
什么是上下文学习?
你以为的AI学习 vs 实际的上下文学习
「你以为的AI学习:」
第一步:准备10万条训练数据
第二步:训练模型72小时
第三步:调参到崩溃
第四步:终于学会了新任务「实际的上下文学习:」
第一步:给AI看几个例子
第二步:没有第二步了,它就学会了
第三步:你开始怀疑人生就像这样:
「示例对话:」
css
用户:我想退货
客服:好的,请提供您的订单号
用户:ABC123
客服:已为您处理退货申请
用户:商品有质量问题
客服:非常抱歉,我们立即为您安排换货
用户:谢谢
客服:不客气,祝您购物愉快
现在,请回复:
用户:我的包裹还没到
AI客服:[AI神奇地知道该怎么回复]这就是上下文学习的魔法!
这背后的秘密是什么?
贝叶斯推理框架:AI的"读心术"
想象一下,你是一个超级观察家,能从蛛丝马迹中推断出事情的真相。
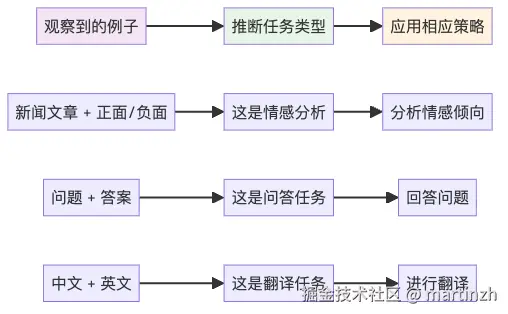
图2:AI如何从示例中推断任务类型
AI的"概念定位器"
AI就像一个超级图书管理员,它在预训练时已经把无数概念整理好了:
- 情感分析的概念
- 翻译的概念
- 问答的概念
- 客服对话的概念
当你给它看例子时,它就会想:
❝
"嗯,这些例子让我想起了我在预训练时见过的客服对话模式,让我调用一下相关的'概念包'..."
❞
这就像你看到"锅、铲、切菜"这些词,立刻就知道这是在讨论做饭一样。
令人震惊的发现
实验一:答案竟然可以是错的?!
研究人员做了一个疯狂的实验:
「正常的训练例子:」
erlang
新闻:股市今天大涨10%
情感:正面
新闻:经济衰退影响就业
情感:负面
现在请分析:公司宣布加薪「疯狂的实验:把答案全部打乱!」
erlang
新闻:股市今天大涨10%
情感:负面 ← 明显错误的标签!
新闻:经济衰退影响就业
情感:正面 ← 这也是错的!
现在请分析:公司宣布加薪你猜结果怎么样?
AI竟然还是能给出合理的答案!这就像:
- 给学生看错误的参考答案
- 但学生依然能考出好成绩
- 这不科学啊!
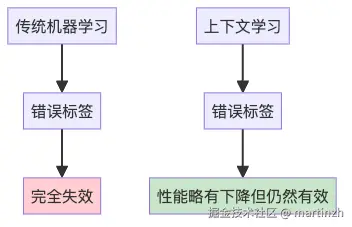
图3:错误标签对不同学习方式的影响
为什么会这样?
原来AI在做贝叶斯推理时,会从多个角度收集"证据":
- 「输入分布」:这些例子是什么类型的文本?
- 「输出空间」:输出的选项有哪些?
- 「格式模式」:文本是怎么组织的?
- 「输入-输出映射」:具体的对应关系
即使你把第4点搞乱了,前3点依然在提供有用信息!
就像你去相亲:
- 对方穿着得体(格式模式)✓
- 在高档咖啡厅见面(输入分布)✓
- 谈论工作和兴趣(输出空间)✓
- 但说话内容颠三倒四(输入-输出映射)✗
你依然能判断出"这是在相亲",只是对这个人的评价会降低一些。
实际应用场景
智能客服训练的完整故事
假设你要为一家电商公司训练智能客服:
「传统方式(老板听了想哭):」
时间:3个月
成本:50万
需要:10万条对话数据
结果:可能还不如人工客服「上下文学习方式(老板听了想笑):」
时间:10分钟
成本:几乎为零
需要:10条优质对话例子
结果:立即上线,效果还不错「具体操作:」
diff
=== 客服培训手册(给AI看的)===
场景1:退货咨询
客户:我想退货,这个商品不满意
客服:好的,请问是质量问题还是其他原因呢?我来帮您处理
客户:颜色和图片差别太大
客服:理解您的感受,我立即为您安排退货,请提供订单号
场景2:物流查询
客户:我的包裹什么时候到?
客服:请提供您的订单号,我帮您查询物流信息
客户:DD123456789
客服:您的包裹正在派送中,预计今晚8点前送达
场景3:商品咨询
客户:这个手机支持5G吗?
客服:是的,这款手机全面支持5G网络,网速更快更稳定
客户:那电池续航怎么样?
客服:正常使用可续航一整天,支持快充30分钟充电80%
=== 现在开始实战 ===
客户:我买的耳机一个响一个不响
AI客服:[神奇地给出专业回复]效果对比
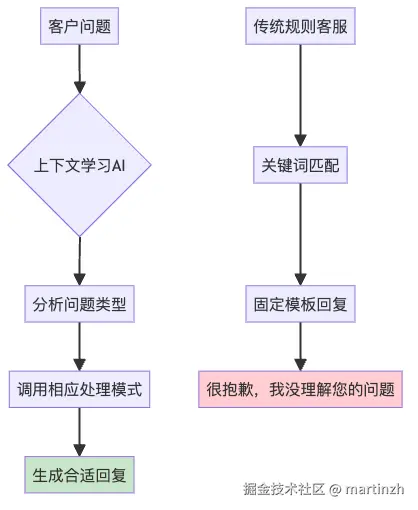
图4:上下文学习AI vs 传统规则客服的处理流程
技术深度解析
AI的"概念仓库"
在预训练过程中,AI就像一个超级学霸,什么都学过:
- 看过无数新闻文章和评论
- 读过各种客服对话记录
- 研究过翻译对照文本
- 分析过问答配对
这些经历都变成了它脑子里的"概念仓库"。
贝叶斯推理的生活化解释
**「贝叶斯推理」**听起来很高大上,其实就是:
观察 → 猜测 → 验证 → 调整 → 得出结论就像你第一次去朋友家:
- 「观察」:门口有狗粮盆
- 「猜测」:这家可能养狗
- 「验证」:听到里面有狗叫声
- 「调整」:确定养狗,而且可能是大型犬
- 「得出结论」:敲门时要小心
AI做上下文学习时,就是这样的过程:
- 「观察」:用户给的例子
- 「猜测」:这可能是什么任务
- 「验证」:例子的模式是否一致
- 「调整」:锁定最可能的任务类型
- 「得出结论」:按这个任务模式回答
为什么预训练这么重要?
想象AI是个刚毕业的大学生:
「没有预训练的AI:」
erlang
老板:帮我写个客服回复
AI:客服是啥?回复是啥?
老板:...「有预训练的AI:」
erlang
老板:帮我写个客服回复
AI:好的,我在大学实习时见过类似的,让我想想...
(调用相关概念)
AI:您好,很抱歉给您带来的不便...未来展望与应用价值
这项技术能解决什么实际问题?
回到我们的智能客服场景:
「问题1:快速适应新业务」
传统方式:新业务线需要重新训练模型
上下文学习:只需要准备几个新业务的对话例子「问题2:处理个性化需求」
传统方式:每个客户的个性化需求都需要单独处理
上下文学习:根据客户历史对话调整回复风格「问题3:多语言支持」
传统方式:每种语言都需要单独训练
上下文学习:给几个目标语言的例子就能工作技术价值总结
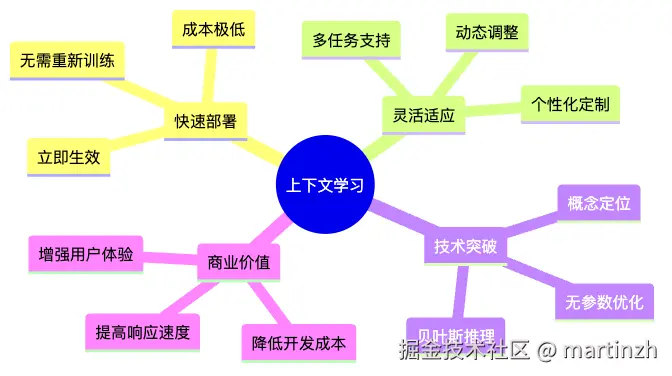
图5:上下文学习的核心价值
魔法背后的思考
上下文学习告诉我们一个有趣的事实:
❝
真正聪明的AI不是那种死记硬背的学霸,而是那种能够举一反三的天才
❞
就像我们人类学习一样:
- 看几个例子就能理解规律
- 在新情况下灵活应用
- 不需要从零开始学习每个新技能
所以下次当有人问你:"AI怎么这么聪明,看几个例子就会了?"
你就可以说:
❝
"这就像你教朋友玩新游戏,不用解释所有规则,玩几局他就懂了。AI的上下文学习也是一样,它通过贝叶斯推理从例子中'定位'到正确的概念,然后应用这个概念来处理新问题。"
❞
保证对方听完后对你刮目相看!