一个基于 PyTorch 的完整模型训练流程
flyfish
| 训练步骤 | 具体操作 | 目的 |
|---|---|---|
| 1. 训练前准备 | 设置随机种子、配置超参数(batch size、学习率等)、选择计算设备(CPU/GPU) | 确保实验可复现;统一控制训练关键参数;利用硬件加速训练 |
| 2. 数据预处理与加载 | 对数据进行标准化/归一化、转换为张量;用DataLoader按batch加载数据 | 统一输入格式,适配模型要求;高效分批读取数据,减少内存占用 |
| 3. 初始化组件 | 定义模型结构并加载到计算设备;选择损失函数(如交叉熵)和优化器(如Adam) | 搭建训练核心框架:模型负责预测,损失函数量化误差,优化器负责参数更新 |
| 4. 训练循环(每个epoch) | 逐轮迭代优化模型参数 | |
| 4.1 模型切换为训练模式 | model.train() |
启用dropout、批量归一化的训练模式,确保梯度计算有效 |
| 4.2 遍历训练数据(每个batch) | 逐批更新参数 | |
| 4.2.1 清零梯度 | optimizer.zero_grad() |
消除历史梯度累积,确保当前batch的梯度计算独立 |
| 4.2.2 前向传播 | output = model(data) |
用当前模型参数对输入数据做预测,得到输出结果 |
| 4.2.3 计算损失 | loss = criterion(output, target) |
量化预测结果与真实标签的差距,作为优化目标 |
| 4.2.4 反向传播 | loss.backward() |
从损失值反向推导,计算所有可训练参数的梯度(参数对损失的影响程度) |
| 4.2.5 参数更新 | optimizer.step() |
根据梯度,按优化器规则调整模型参数,减小损失 |
| 4.3 记录训练指标 | 保存每个epoch的训练损失、准确率 | 跟踪模型在训练集上的学习效果 |
| 5. 验证(每个epoch后) | 评估模型泛化能力 | |
| 5.1 模型切换为评估模式 | model.eval() |
关闭dropout、固定批量归一化参数,确保评估稳定 |
| 5.2 关闭梯度计算 | with torch.no_grad(): |
减少内存占用,加速验证过程(无需计算梯度) |
| 5.3 计算验证指标 | 计算验证损失、准确率 | 评估模型在未见过的数据上的表现,判断泛化能力 |
| 6. 模型保存 | 保存表现最优的模型参数(如验证准确率最高时) | 留存最佳模型,便于后续部署或继续训练 |
| 7. 训练后分析 | 绘制损失/准确率曲线,统计训练时间 | 直观展示训练过程,分析模型收敛状态和效率 |
前向传播→计算损失→反向传播→参数优化
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
import os
from tqdm import tqdm
import time
# 设置随机种子,保证结果可复现
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 定义超参数
class Config:
def __init__(self):
self.batch_size = 64
self.learning_rate = 0.001
self.epochs = 10
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.save_path = './models'
self.log_interval = 100
# 定义简单的卷积神经网络模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7) # 展平
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 准备数据
def prepare_data(config):
# 定义数据变换
transform = transforms.Compose([
ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
download=True,
transform=transform
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=2
)
test_loader = DataLoader(
test_dataset,
batch_size=config.batch_size,
shuffle=False,
num_workers=2
)
return train_loader, test_loader
# 训练函数
def train(model, train_loader, criterion, optimizer, config, epoch):
model.train() # 设置为训练模式
train_loss = 0.0
correct = 0
total = 0
# 使用tqdm显示进度条
pbar = tqdm(train_loader, desc=f'Train Epoch {epoch}')
for batch_idx, (data, target) in enumerate(pbar):
data, target = data.to(config.device), target.to(config.device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
output = model(data)
loss = criterion(output, target)
# 反向传播和优化
loss.backward()
optimizer.step()
# 统计训练信息
train_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
# 打印日志
if batch_idx % config.log_interval == 0:
pbar.set_postfix({
'loss': f'{train_loss/(batch_idx+1):.6f}',
'accuracy': f'{100.*correct/total:.2f}%'
})
# 计算平均损失和准确率
avg_loss = train_loss / len(train_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
# 验证函数
def validate(model, test_loader, criterion, config):
model.eval() # 设置为评估模式
test_loss = 0.0
correct = 0
total = 0
# 不计算梯度
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(config.device), target.to(config.device)
output = model(data)
test_loss += criterion(output, target).item()
# 统计准确率
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
# 计算平均损失和准确率
avg_loss = test_loss / len(test_loader)
accuracy = 100. * correct / total
print(f'\nTest set: Average loss: {avg_loss:.4f}, Accuracy: {correct}/{total} ({accuracy:.2f}%)\n')
return avg_loss, accuracy
# 保存模型
def save_model(model, optimizer, epoch, loss, config):
# 创建保存目录
if not os.path.exists(config.save_path):
os.makedirs(config.save_path)
# 保存模型状态
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, f"{config.save_path}/model_epoch_{epoch}.pth")
print(f"Model saved to {config.save_path}/model_epoch_{epoch}.pth")
# 主函数
def main():
# 初始化设置
set_seed()
config = Config()
print(f"Using device: {config.device}")
# 准备数据
train_loader, test_loader = prepare_data(config)
# 初始化模型、损失函数和优化器
model = SimpleCNN().to(config.device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
# 记录训练过程中的指标
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
# 开始训练
start_time = time.time()
best_val_acc = 0.0
for epoch in range(1, config.epochs + 1):
print(f"\nEpoch {epoch}/{config.epochs}")
print("-" * 50)
# 训练
train_loss, train_acc = train(model, train_loader, criterion, optimizer, config, epoch)
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
# 验证
val_loss, val_acc = validate(model, test_loader, criterion, config)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
save_model(model, optimizer, epoch, val_loss, config)
# 计算总训练时间
end_time = time.time()
total_time = end_time - start_time
print(f"Training complete in {total_time:.0f}s ({total_time/config.epochs:.2f}s per epoch)")
print(f"Best validation accuracy: {best_val_acc:.2f}%")
# 绘制训练曲线
plot_training_history(history)
# 绘制训练历史
def plot_training_history(history):
plt.figure(figsize=(12, 4))
# 绘制损失曲线
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Training Loss')
plt.plot(history['val_loss'], label='Validation Loss')
plt.title('Loss Curves')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Training Accuracy')
plt.plot(history['val_acc'], label='Validation Accuracy')
plt.title('Accuracy Curves')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.tight_layout()
plt.savefig('training_history.png')
print("Training history plot saved as 'training_history.png'")
plt.show()
if __name__ == '__main__':
main()......
--------------------------------------------------
Train Epoch 9: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 938/938 [00:07<00:00, 124.14it/s, loss=0.024222, accuracy=99.22%]
Test set: Average loss: 0.0256, Accuracy: 9926/10000 (99.26%)
Model saved to ./models/model_epoch_9.pth
Epoch 10/10
--------------------------------------------------
Train Epoch 10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 938/938 [00:07<00:00, 127.89it/s, loss=0.021473, accuracy=99.31%]
Test set: Average loss: 0.0266, Accuracy: 9927/10000 (99.27%)
Model saved to ./models/model_epoch_10.pth
Training complete in 85s (8.52s per epoch)
Best validation accuracy: 99.27%
Training history plot saved as 'training_history.png'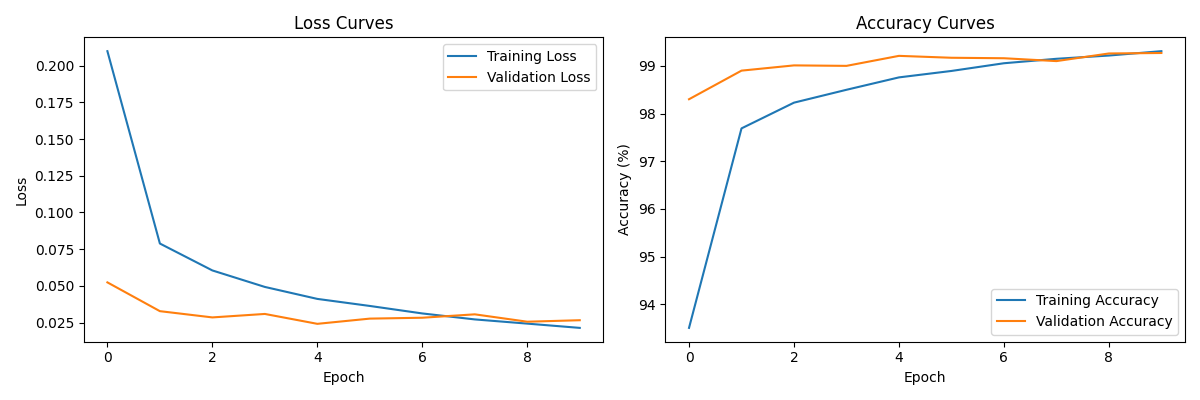
一、左侧:Loss Curves(损失曲线)
蓝色:训练损失(Training Loss)
橙色:验证损失(Validation Loss)
二、右侧:Accuracy Curves(准确率曲线)
蓝色:训练准确率(Training Accuracy)
橙色:验证准确率(Validation Accuracy)