一、什么是微服务
在 Kubernetes 中,控制器负责维持业务副本,但真正把业务"暴露"出去的是 Service 。
一句话理解:
-
Service = 一组 Pod 的稳定访问入口 + 4 层负载均衡
-
Ingress = 7 层路由 + 统一入口 + 灰度 / 认证 / 重写等高级能力
默认情况下,Service 仅具备 4 层(TCP/UDP)能力,如需 7 层(HTTP/HTTPS)请使用 Ingress。
二、微服务(Service)的四种类型总览
| 类型 | 作用与适用场景 |
|---|---|
| ClusterIP | 默认值,集群内部虚拟 IP;仅供集群内部访问,自动 DNS 与服务发现。 |
| NodePort | 在每个节点打开固定端口(30000-32767),外部通过 节点IP:端口 即可访问服务。 |
| LoadBalancer | 基于 NodePort,再申请外部云负载均衡(或 MetalLB);适用于公有云或裸金属+MetalLB。 |
| ExternalName | 将集群内请求通过 CNAME 转发到任意指定域名;常用于外部服务迁移或跨集群调用。 |
三、Service 的默认实现:iptables vs IPVS
-
iptables 模式(默认)
- 规则多、刷新慢,万级 Pod 场景下 CPU 抖动明显。
-
IPVS 模式(推荐生产)
-
内核级四层负载,支持 10w+ 连接,性能稳定。
-
切换后自动生成虚拟网卡
kube-ipvs0,所有 ClusterIP 被绑定到该接口。
-
3.1 一键切换到 IPVS 模式
1.所有节点安装工具
yum install ipvsadm -y2.修改 kube-proxy 配置
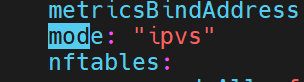
kubectl -n kube-system edit cm kube-proxy
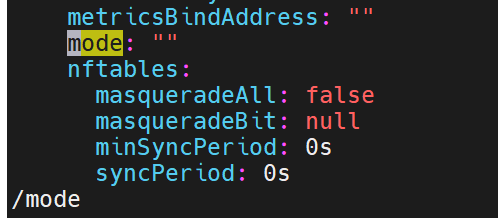
# 找到 mode 字段,改为 "ipvs"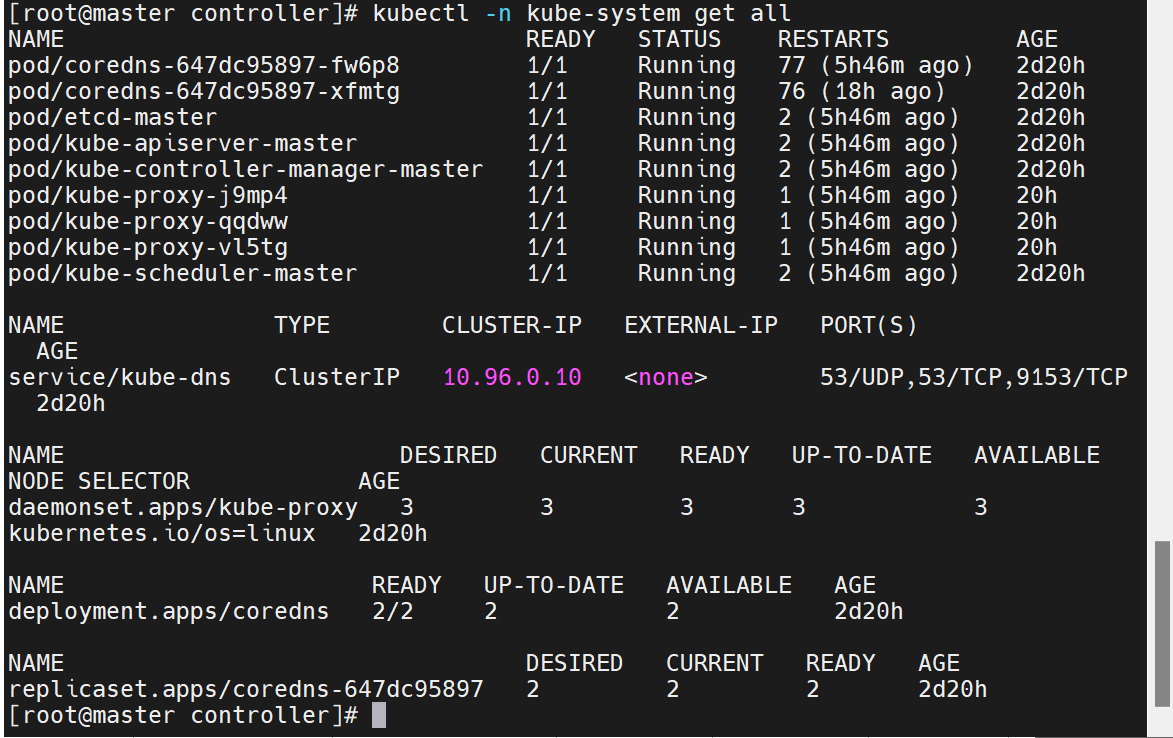
如果什么都没有,说明是默认的使用iptables,这里我们加上ipvs
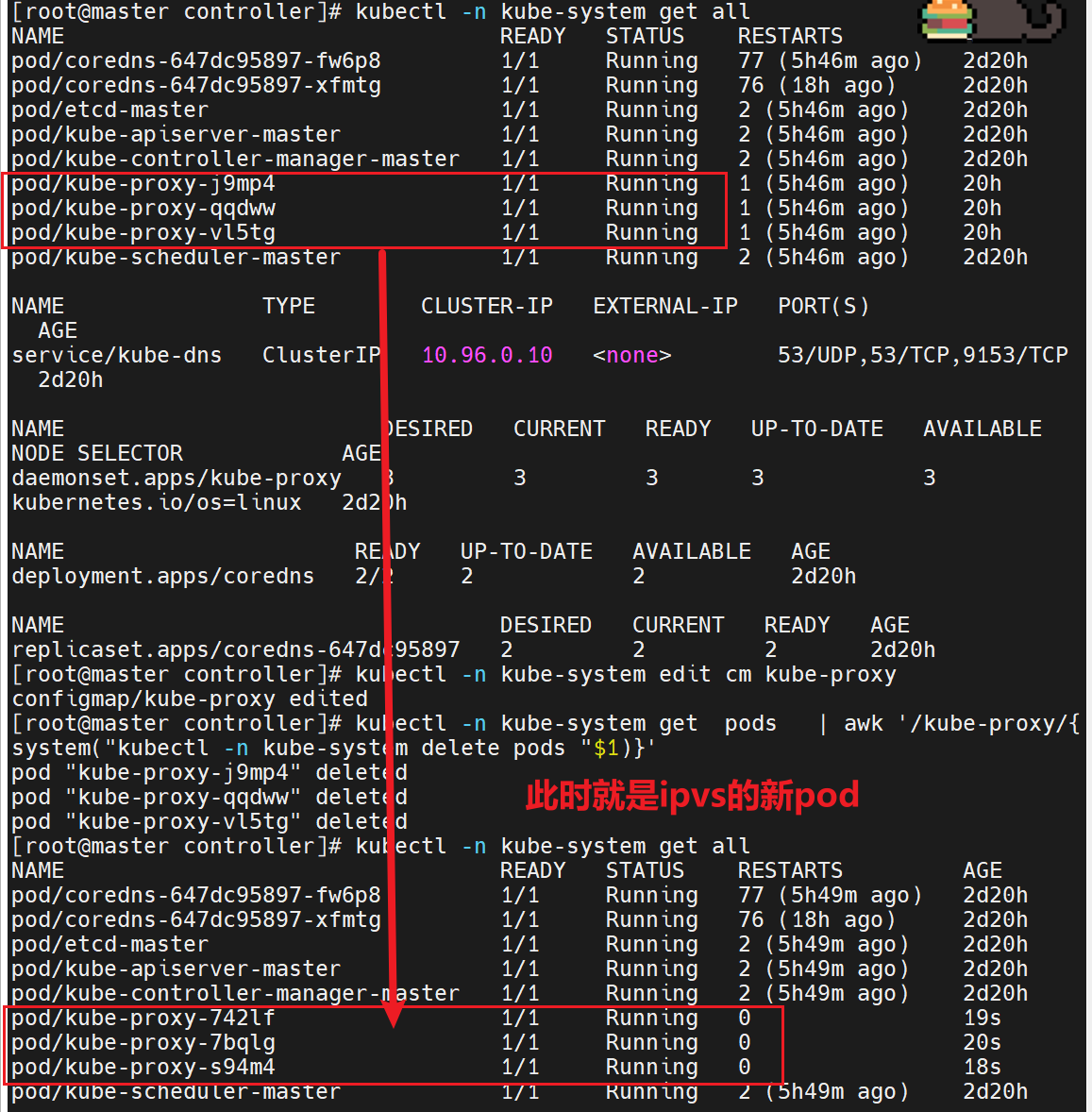
修改配置后,要重启,这里可以删掉之前的网络配置pod,重新刷新新的pod出来,此时就是新策略的pod
3.滚动重启 kube-proxy Pod
kubectl -n kube-system get pods | awk '/kube-proxy/{
system("kubectl -n kube-system delete pod "$1)
}'
4.验证
ipvsadm -Ln | head
# 出现 10.96.x.x:xx rr 即成功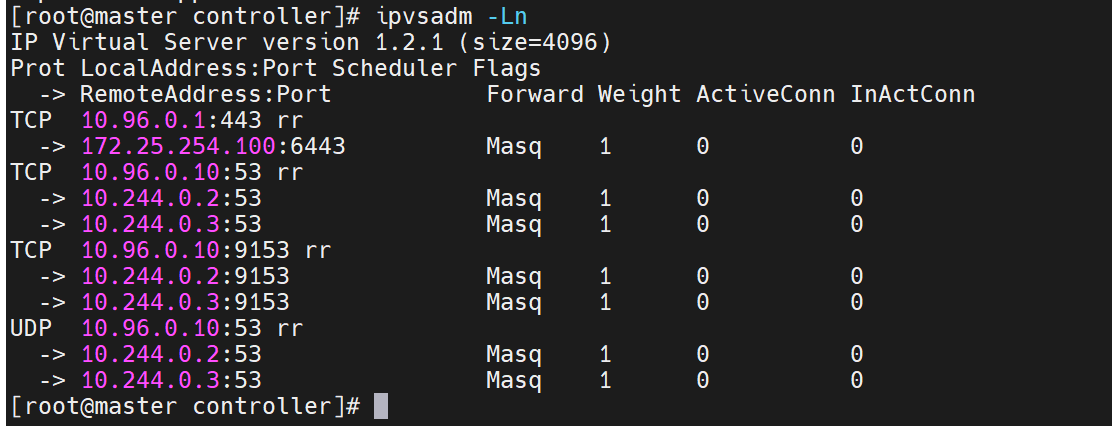
四、微服务类型详解
4.1 ClusterIP ------ 集群内默认访问方式
4.1.1 标准 ClusterIP 示例
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee
name: timinglee
spec:
ports:
- port: 80 # Service 端口
protocol: TCP
targetPort: 80 # Pod 端口
selector:
app: timinglee # 绑定到标签一致的 Pod
type: ClusterIP # 可省略,默认即 ClusterIP
kubectl apply -f clusterip.yml
kubectl get svc timinglee
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# timinglee ClusterIP 10.99.127.134 <none> 80/TCP 16sclusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能

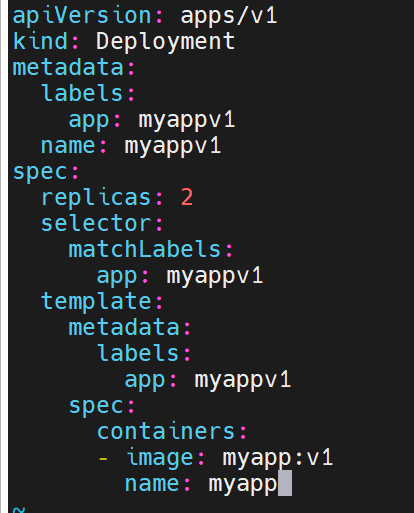
追加内容,此时微服务和控制器就在一个配置文件里了

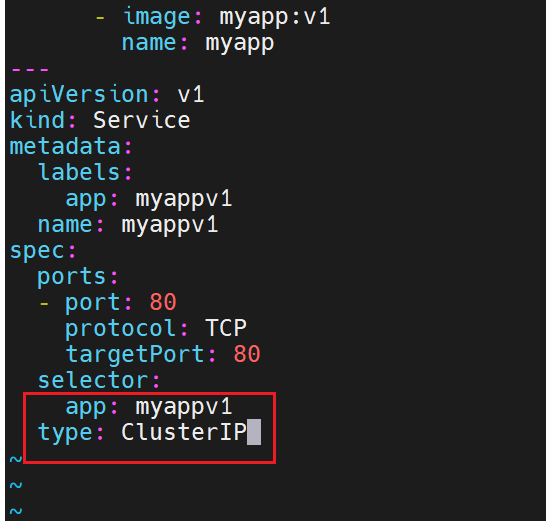
只有集群内部的IP,集群外部的不暴露
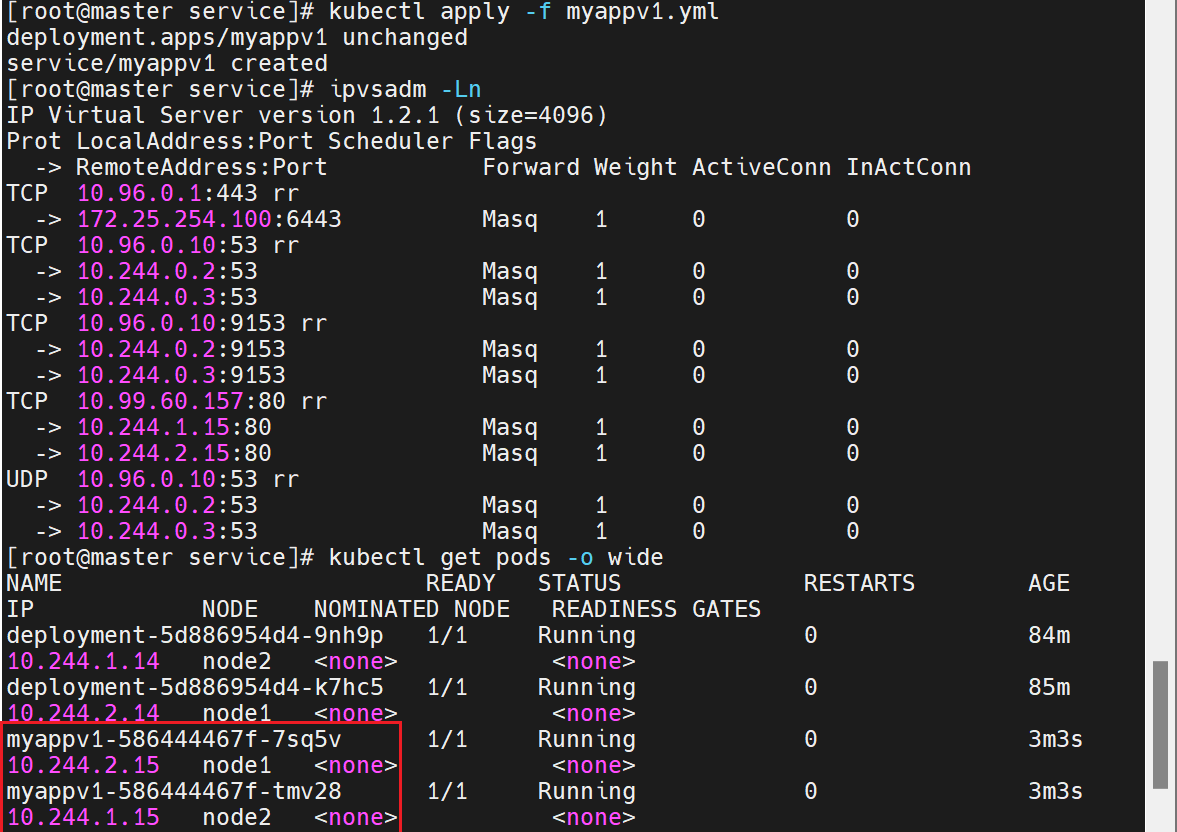
4.1.2 DNS 自动解析验证
# 集群内部可直接解析
dig timinglee.default.svc.cluster.local @10.96.0.10
# ;; ANSWER SECTION:
# timinglee.default.svc.cluster.local. 30 IN A 10.99.127.134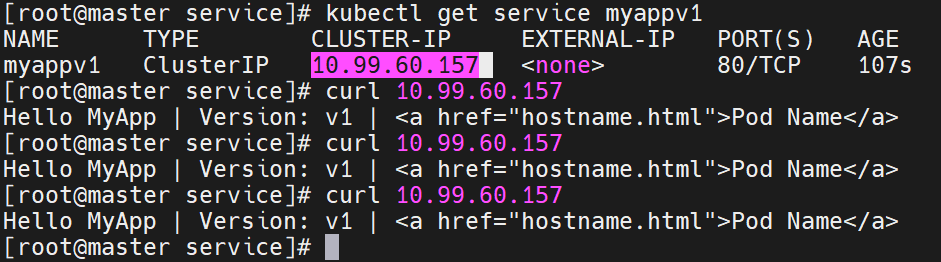
4.2 Headless ------ 无 ClusterIP 的直连模式
适用场景:StatefulSet 的稳定网络标识、客户端自己做负载均衡、自定义 DNS 策略。
apiVersion: v1
kind: Service
metadata:
name: timinglee
spec:
clusterIP: None # 关键字段
ports:
- port: 80
targetPort: 80
selector:
app: timinglee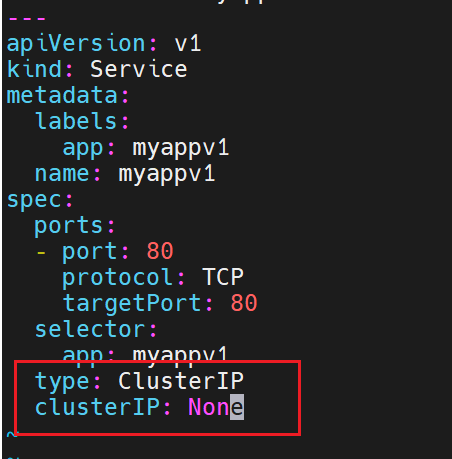
之前有了无头服务,要删掉,不然影响实验
没有了IP以后,后端就没有调度了
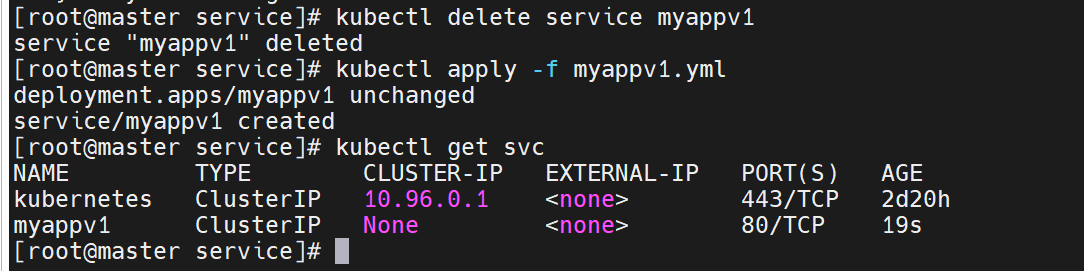
此时我们可以用dns来写,把要访问的server直接指定到后端的服务器中去
#开启一个busyboxplus的pod测试

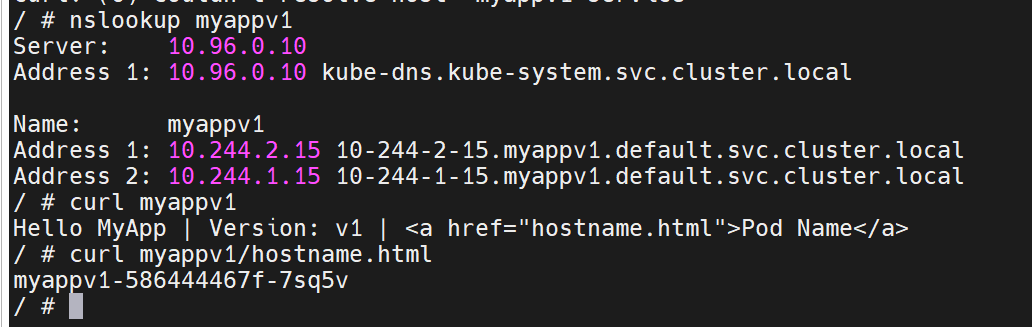
kubectl apply -f headless.yml
kubectl get svc timinglee
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# timinglee ClusterIP None <none> 80/TCP 6sDNS 结果直接返回所有 Pod IP:
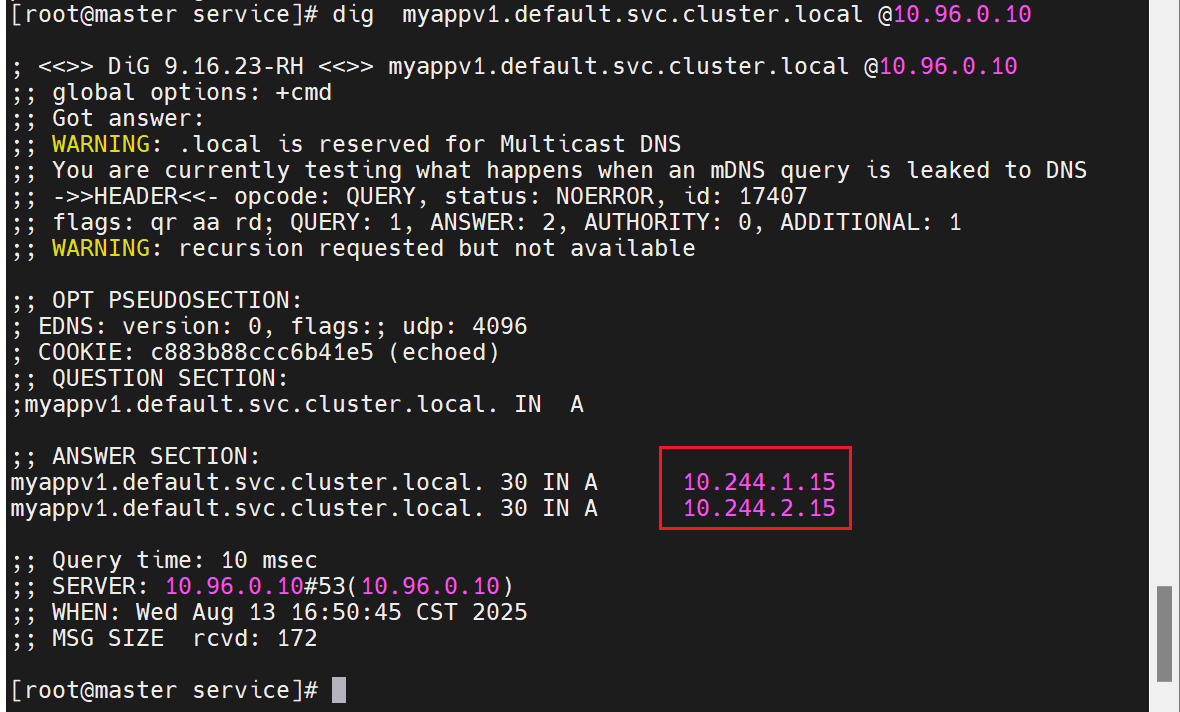
dig timinglee.default.svc.cluster.local @10.96.0.10
# ANSWER SECTION:
# timinglee.default.svc.cluster.local. 20 IN A 10.244.2.14
# timinglee.default.svc.cluster.local. 20 IN A 10.244.1.184.3 NodePort ------ 节点端口暴露
4.3.1 快速示例
apiVersion: v1
kind: Service
metadata:
name: timinglee-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 31771 # 可省略,自动分配 30000-32767
selector:
app: timinglee
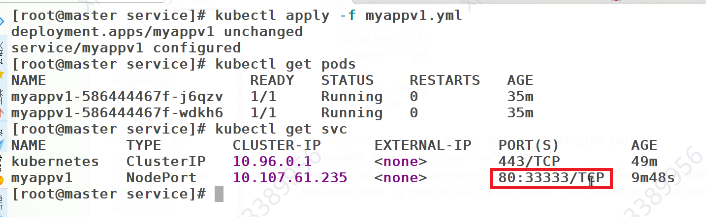
kubectl apply -f nodeport.yml
kubectl get svc timinglee-service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# timinglee NodePort 10.98.60.22 <none> 80:31771/TCP 8s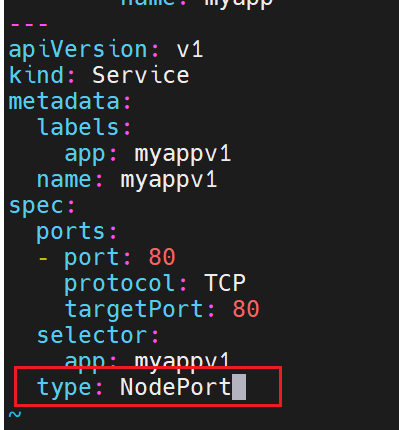
之前的服务设置了无头服务,这里要删除之前环境,重新运行
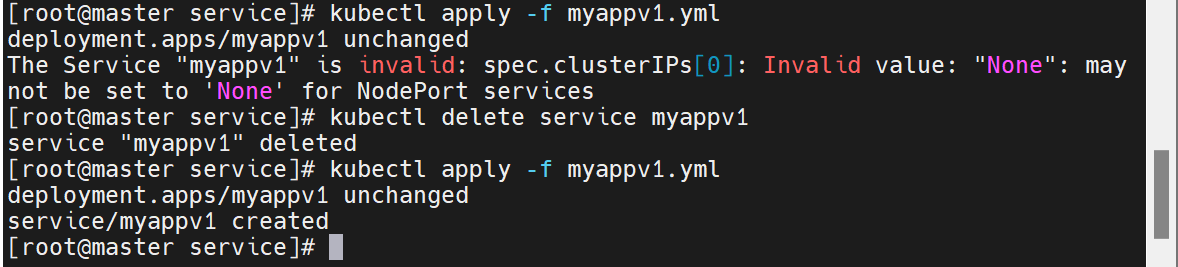
多了一个端口

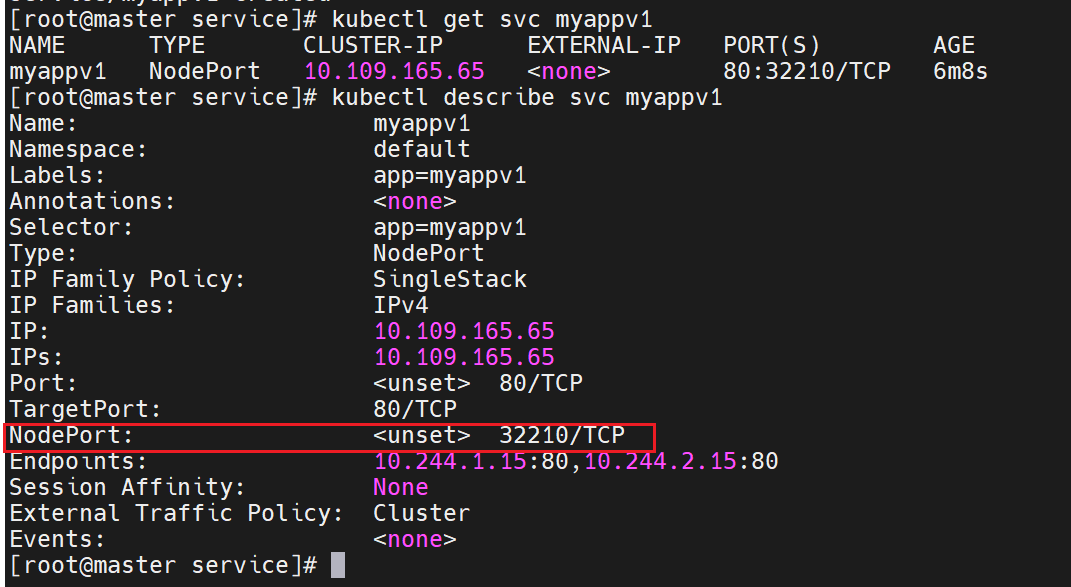
这个端口用来直接对外暴露

外部访问测试:
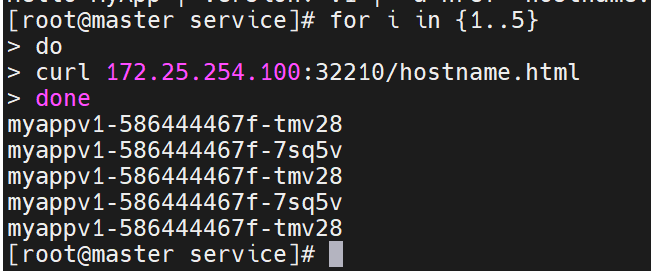
curl 172.25.254.100:31771/hostname.html
# timinglee-c56f584cf-fjxdk
nodeport在集群节点上绑定端口,一个端口对应一个服务
直接负载到下面两个
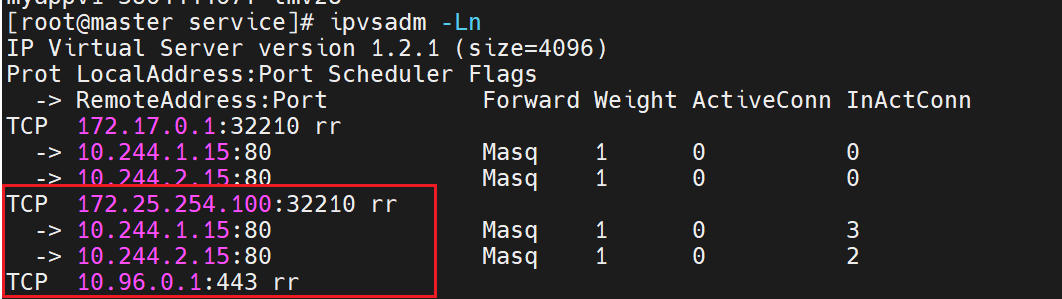
用clusterip来访问后端的
访问模式

对应的端口是不固定的,但是我们可以直接指定,但是有范围限制最大30000
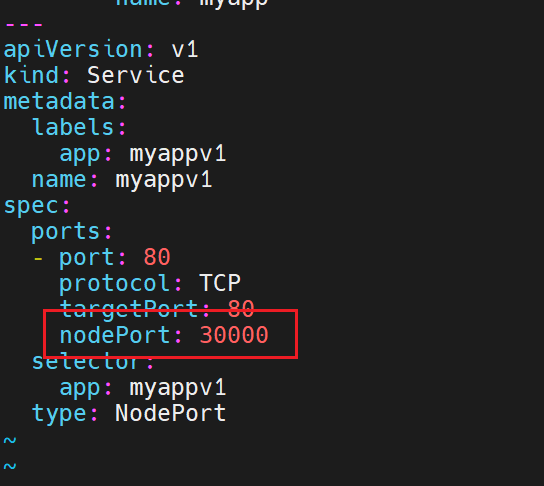

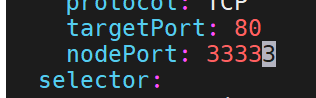

但是想要超过限制也可以,修改配置文件就行。但是集群会挂掉,要等待自愈


加上这句话- --service-node-port-range=30000-40000
刚刚还不能超过的限制,现在就可以了
NodePort 默认端口范围 30000-32767;如需自定义范围,请修改 kube-apiserver 参数
--service-node-port-range=30000-40000。
4.4 LoadBalancer ------ 云或裸金属的外部 VIP
4.4.1 公有云场景
apiVersion: v1
kind: Service
metadata:
name: timinglee-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
app: timinglee在 云厂商(AWS/GCP/阿里云) 上,提交 YAML 后会自动为 Service 分配一个公网 VIP:
kubectl get svc timinglee-service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# timinglee LoadBalancer 10.107.23.134 203.0.113.10 80:32537/TCP 4s4.4.2 裸金属场景:MetalLB
MetalLB 为裸金属或私有集群实现 LoadBalancer 功能。
① 安装 MetalLB
# 1) 确保 kube-proxy 为 IPVS 模式(见第 3.1 节)
kubectl edit cm -n kube-system kube-proxy # mode: "ipvs"
kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pod "$1)}'
# 2) 下载官方清单
wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
# 3) 修改镜像地址(私有仓库)
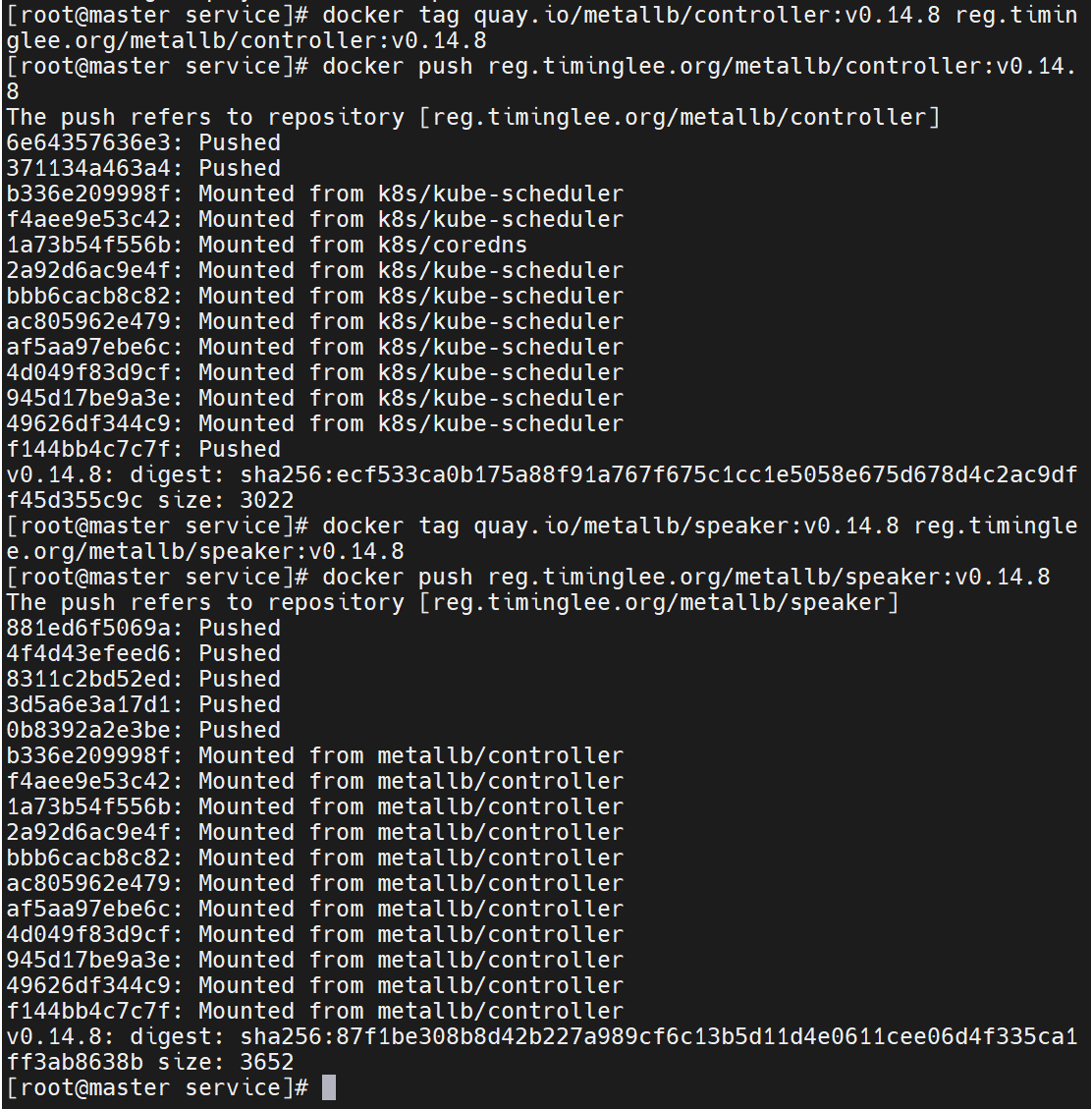
sed -i 's#quay.io/metallb/controller:v0.14.8#reg.timinglee.org/metallb/controller:v0.14.8#' \
metallb-native.yaml
sed -i 's#quay.io/metallb/speaker:v0.14.8#reg.timinglee.org/metallb/speaker:v0.14.8#' \
metallb-native.yaml
# 4) 推送镜像到 Harbor
docker pull quay.io/metallb/controller:v0.14.8
docker pull quay.io/metallb/speaker:v0.14.8
docker tag ... && docker push ...
# 5) 部署
kubectl apply -f metallb-native.yaml
kubectl -n metallb-system wait --for=condition=ready pod -l app=metallb --timeout=120s② 配置 IP 地址池
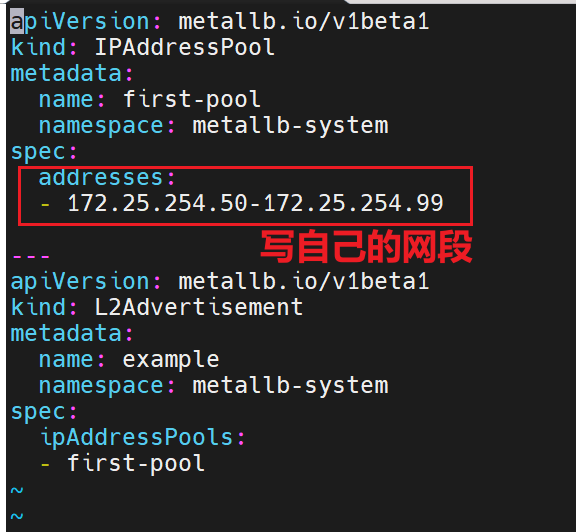
# configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 172.25.254.50-172.25.254.99 # 与本地网络同段
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
spec:
ipAddressPools:
- first-pool
kubectl apply -f configmap.yml再次查看 Service:
kubectl get svc timinglee-service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# timinglee LoadBalancer 10.109.36.123 172.25.254.50 80:31595/TCP 9m9s集群外直接访问 VIP:
curl 172.25.254.50
# Hello MyApp | Version: v1 | ...部署安装
必须要把集群做成ipvs的模式

并且重启网络方面的pod


这个文档里的路径已经修改好了,如果是未修改的,记得把路径换成自己的软件仓库

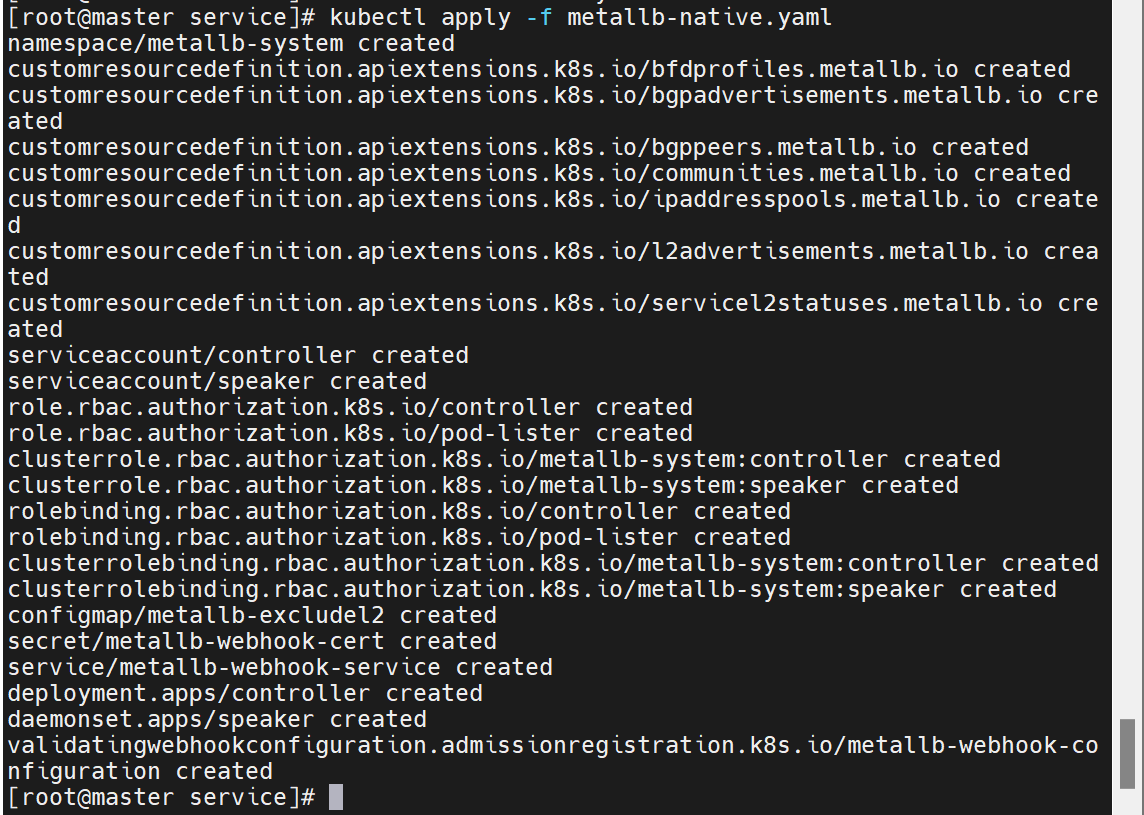
这个生效了之后,才能改配置

之前这里还是正在生效,现在已经有了IP

#通过分配地址从集群外访问服务

已经自动分配对外IP
4.5 ExternalName ------ DNS CNAME 转发
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
-
业务尚在集群外(如 RDS、COS、第三方 API)。
-
迁移过程中保持调用方 域名不变,仅改 DNS 指向。
apiVersion: v1
kind: Service
metadata:
name: timinglee-service
spec:
type: ExternalName
externalName: www.timinglee.org # 目的域名kubectl apply -f externalname.yml
kubectl get svc timinglee-serviceNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee ExternalName
www.timinglee.org 2m58s
集群内 Pod 访问 timinglee-service 时,DNS 会直接返回 www.timinglee.org 的地址,无需维护 IP 变化。
集群内部的IP在访问时,做的是域名解析
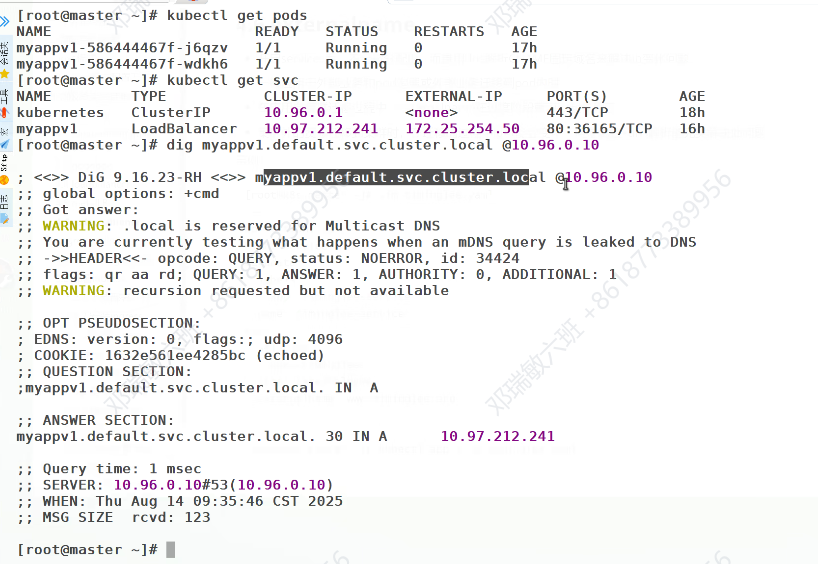
把真实的微服务转化成其他主机上
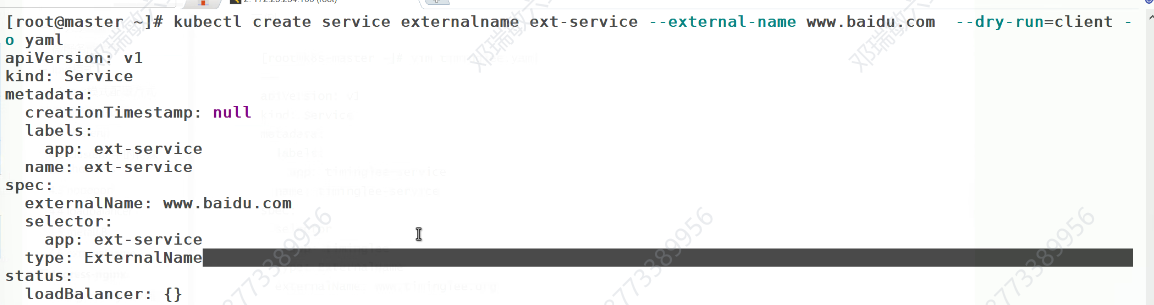

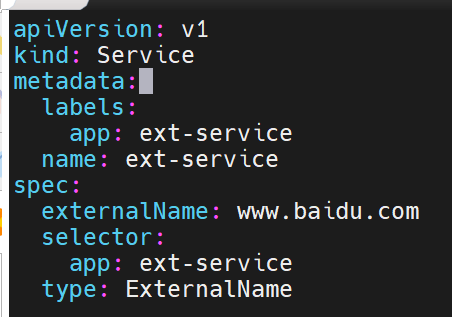
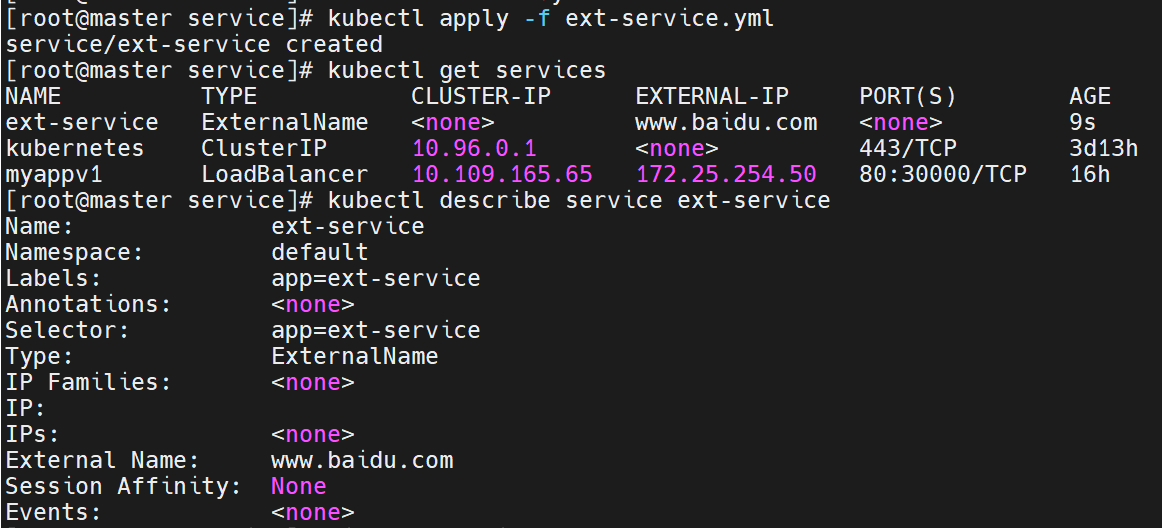
没有IP时如何被访问的,通过dns的域名解析
验证 DNS 解析
这行命令测试 Kubernetes 集群内部 DNS(10.96.0.10是集群 DNS 服务的 IP)是否能正确解析ext-service对应的域名:
结果显示ext-service.default.svc.cluster.local(集群内部服务域名)被解析为www.baidu.com
最终解析到百度的实际 IP 地址(103.235.46.115和103.235.46.102)
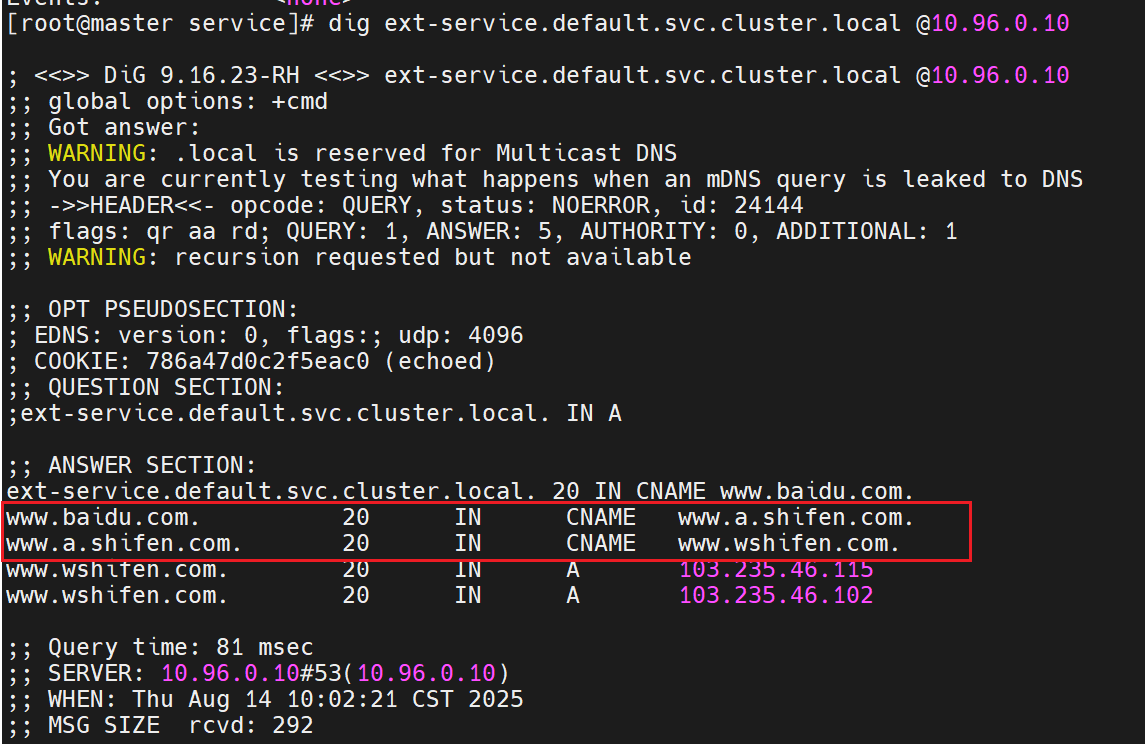
得到了集群内部的主机
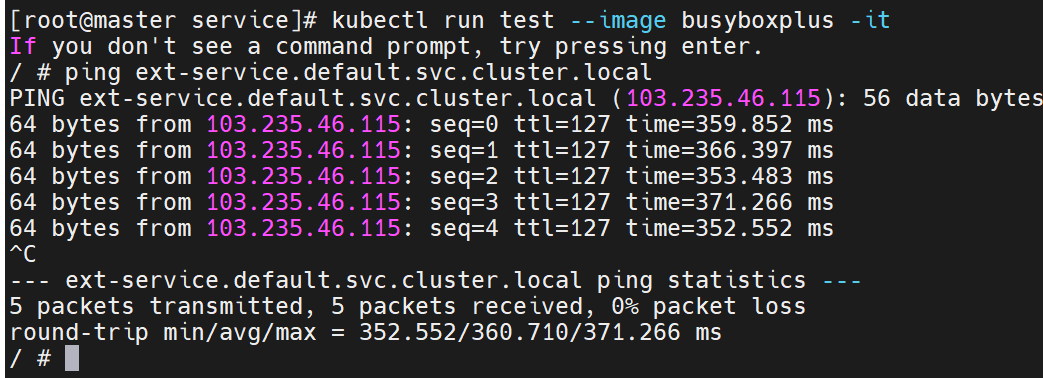
微服务把集群外部的资源映射到集群内部,让集群内部可以使用
五、Ingress-Nginx 全景实战
Ingress = 7 层路由 + 多域名 + 灰度 + 认证 + TLS + 重写
在service前面在加一个nginx
在集群暴露时,再加一个反向代理
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
Ingress由两部分组成:Ingress controller和Ingress服务
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
5.1 部署 Ingress-Nginx(裸金属)
# 1) 下载官方清单
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.11.2/deploy/static/provider/baremetal/deploy.yaml
# 2) 镜像同步到私有仓库
docker tag registry.k8s.io/ingress-nginx/controller:v1.11.2 \
reg.timinglee.org/ingress-nginx/controller:v1.11.2
docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.3 \
reg.timinglee.org/ingress-nginx/kube-webhook-certgen:v1.4.3
docker push ...
# 3) 修改清单中的镜像地址
sed -i 's#registry.k8s.io/ingress-nginx/controller#reg.timinglee.org/ingress-nginx/controller#' deploy.yaml
sed -i 's#registry.k8s.io/ingress-nginx/kube-webhook-certgen#reg.timinglee.org/ingress-nginx/kube-webhook-certgen#' deploy.yaml
# 4) 部署 & 等待就绪
kubectl apply -f deploy.yaml
kubectl -n ingress-nginx wait --for=condition=ready pod -l app.kubernetes.io/name=ingress-nginx --timeout=120s
在部署文件里




上传ingress所需镜像到harbor
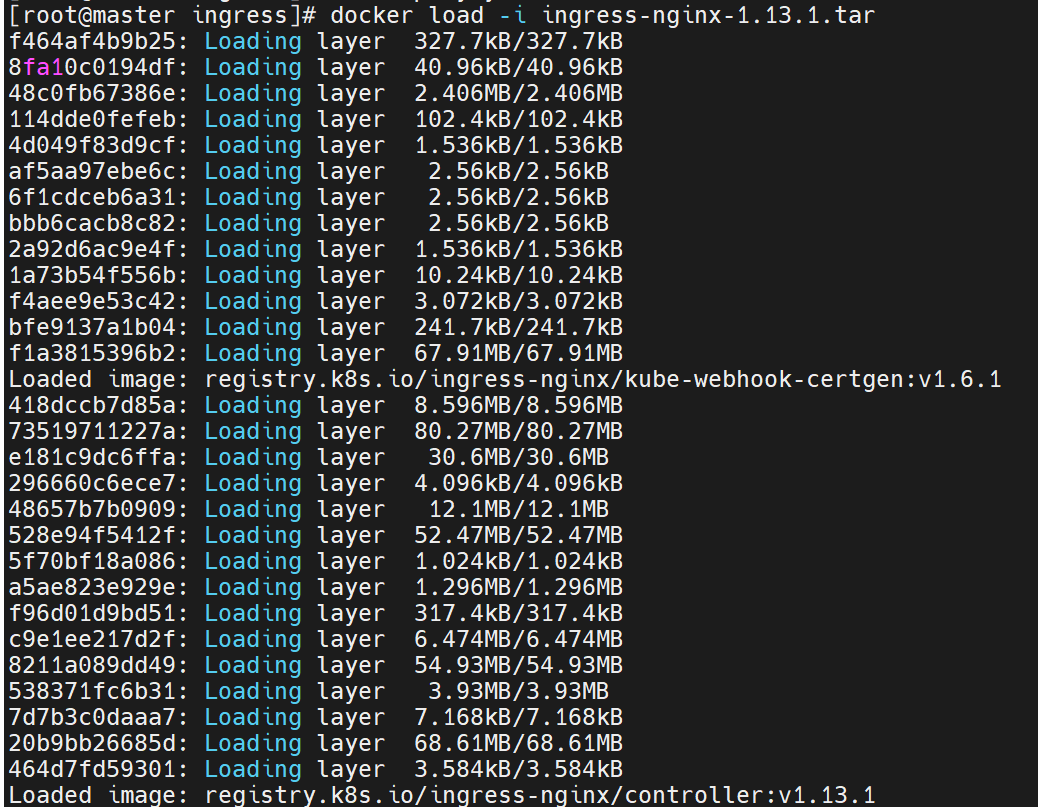

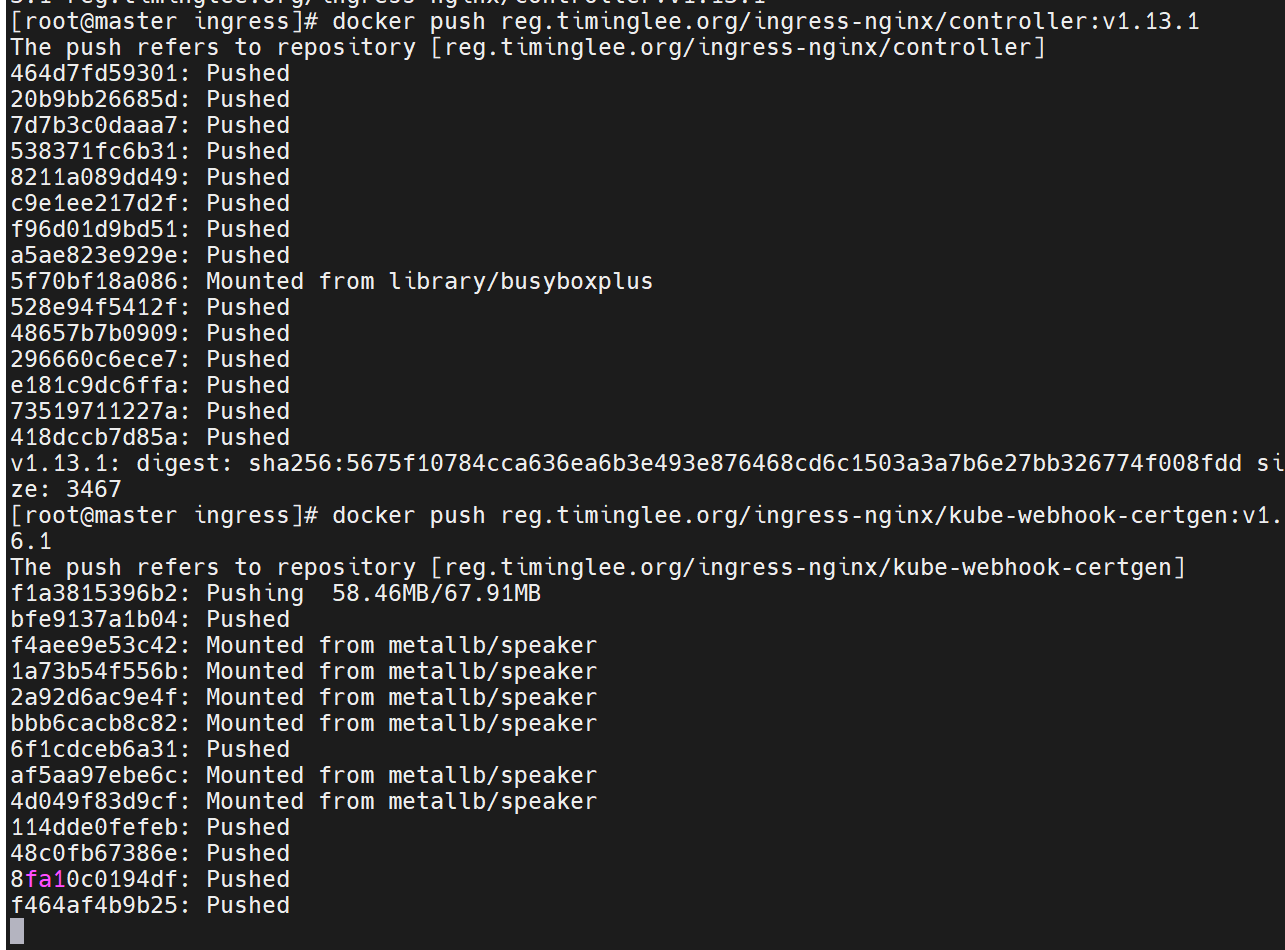
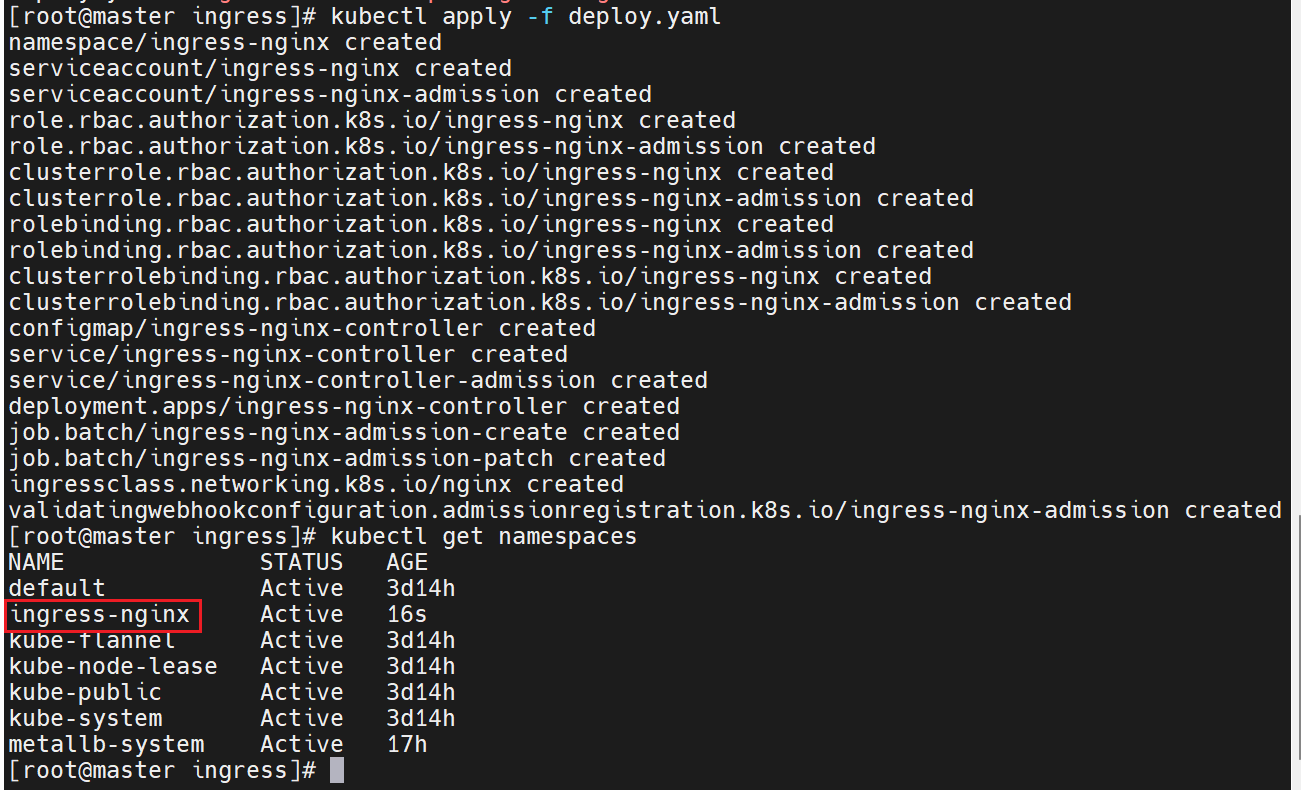
运行配置文件,并且查看是否建立了新的命名空间
此时查看还是没有对外开放的ip的,因为微服还没有修改,现在还是只能集群内部访问


#修改微服务为loadbalancer
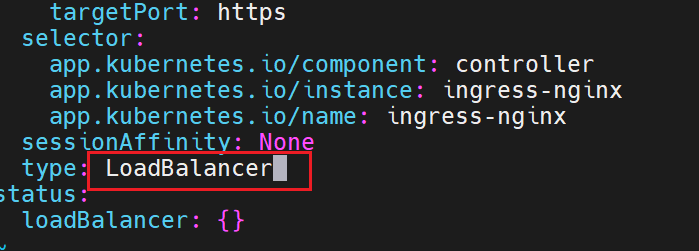
此时就有对外开放的IP了
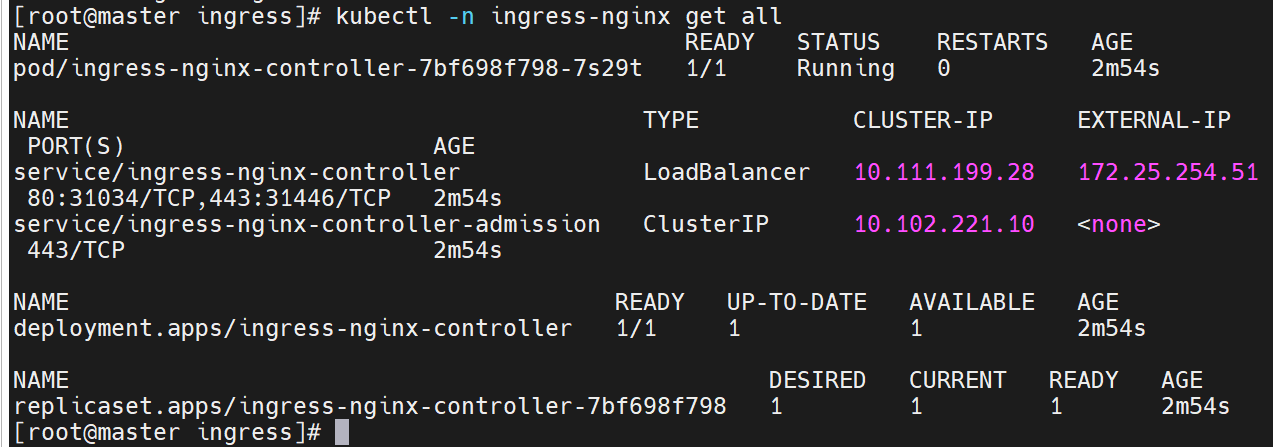
在ingress-nginx-controller中看到的对外IP就是ingress最终对外开放的ip
测试ingress
生成一下模板

上面是控制器,下面是微服务
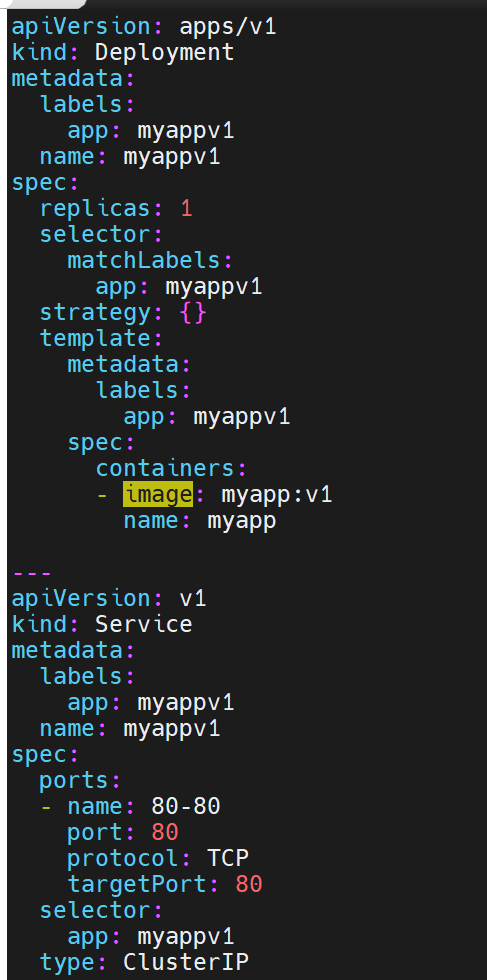
默认 Service 类型为 NodePort,如需 LoadBalancer:
kubectl -n ingress-nginx edit svc ingress-nginx-controller
# 把 type: NodePort 改为 type: LoadBalancer
kubectl -n ingress-nginx get svc
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
# ingress-nginx-controller LoadBalancer 10.103.33.148 172.25.254.50 80:34512/TCP,443:34727/TCP5.2 基于路径的多版本分流
5.2.1 部署两套版本业务
# myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-v1
spec:
replicas: 1
selector:
matchLabels: {app: myapp-v1}
template:
metadata:
labels: {app: myapp-v1}
spec:
containers:
- name: myapp
image: myapp:v1
---
apiVersion: v1
kind: Service
metadata:
name: myapp-v1
spec:
selector:
app: myapp-v1
ports:
- port: 80
targetPort: 80
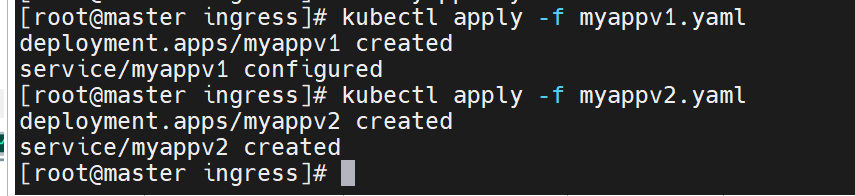
kubectl apply -f myapp-v1.yaml
# 同理再建 myapp-v2.yaml(镜像改为 v2,service 名为 myapp-v2)
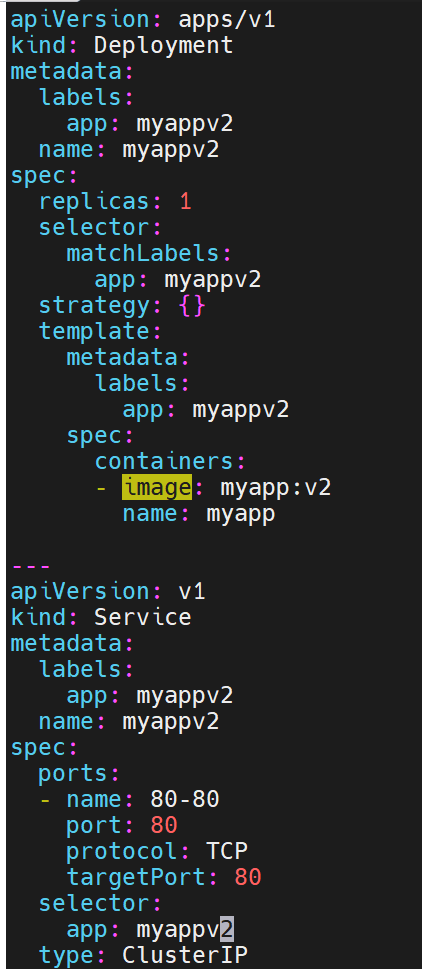
装了两台主机,两台主机呈现不同web页面
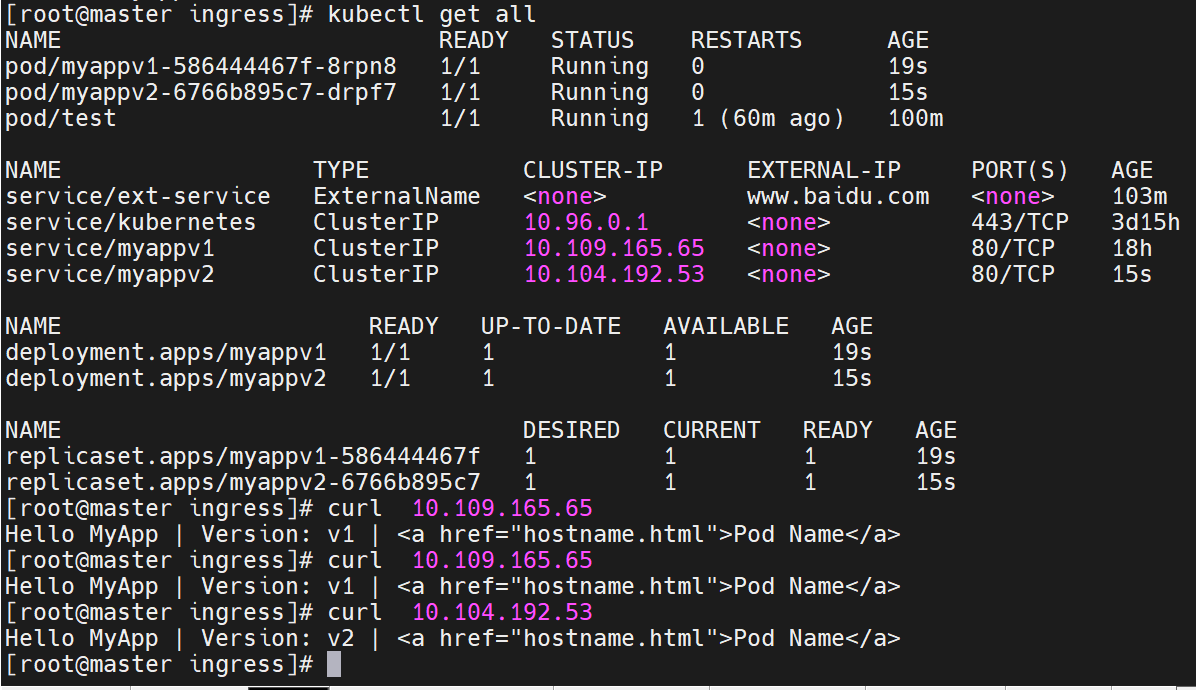
核心动作都是nginx完成的

调用nginx类,访问微服务的80端口

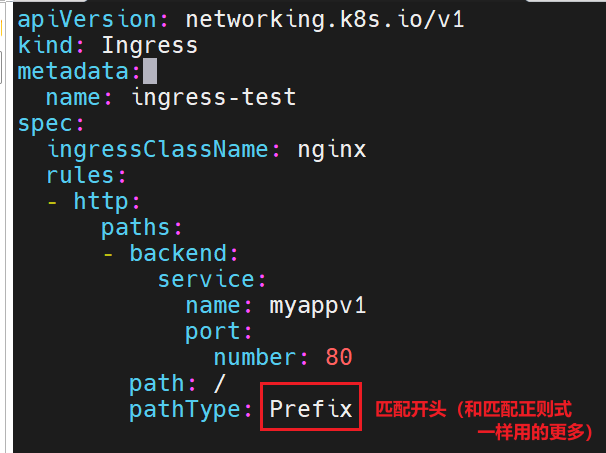
当我们去访问我们刚刚设立的对外IP时,它带我们去看的时myappv1的80端口里的内容
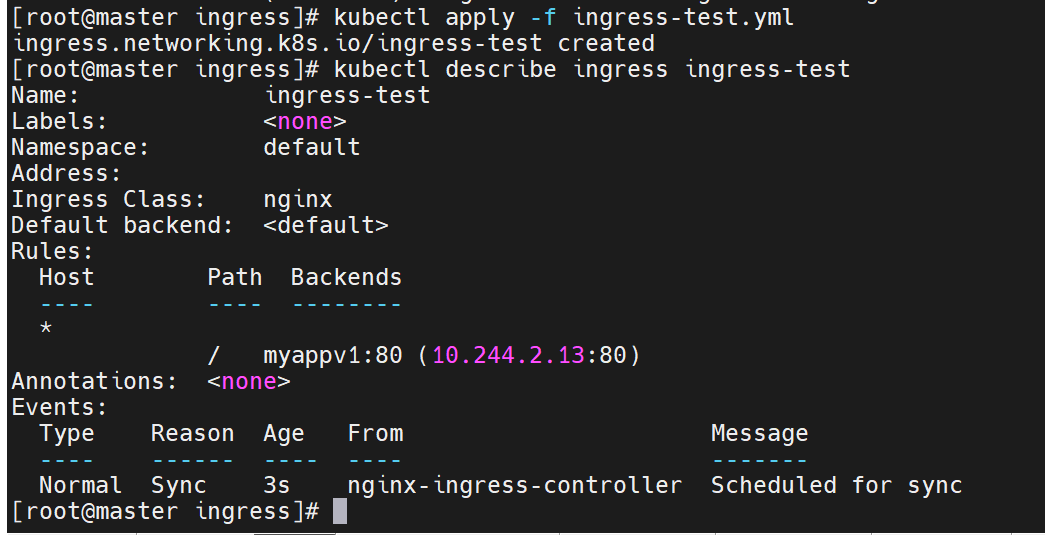

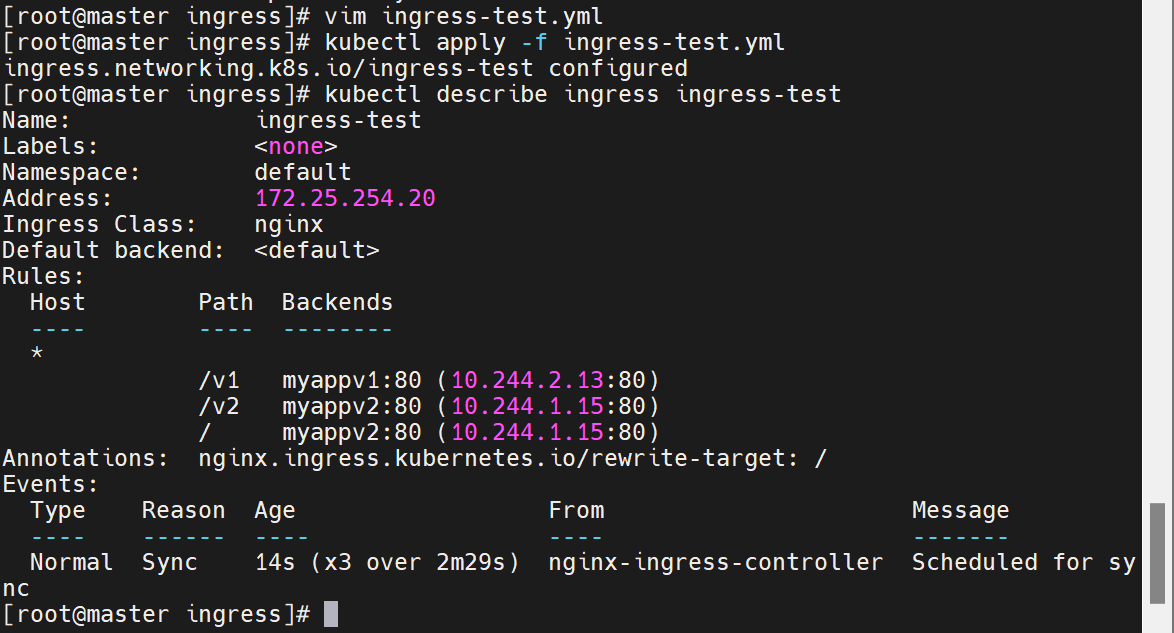
5.2.2 创建基于路径的 Ingress
# ingress-path.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-path
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: myapp.timinglee.org
http:
paths:
- path: /v1
pathType: Prefix
backend:
service:
name: myapp-v1
port: {number: 80}
- path: /v2
pathType: Prefix
backend:
service:
name: myapp-v2
port: {number: 80}
kubectl apply -f ingress-path.yaml
curl http://myapp.timinglee.org/v1 # Version: v1
curl http://myapp.timinglee.org/v2 # Version: v2此时直接访问是不行的,因为没有设定默认发布目录
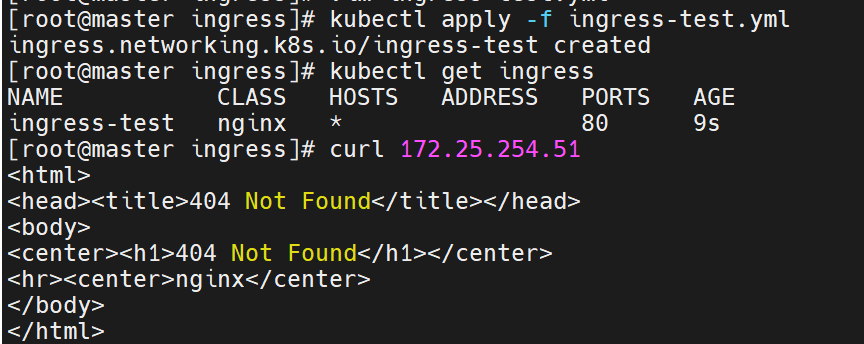
可以设定一下
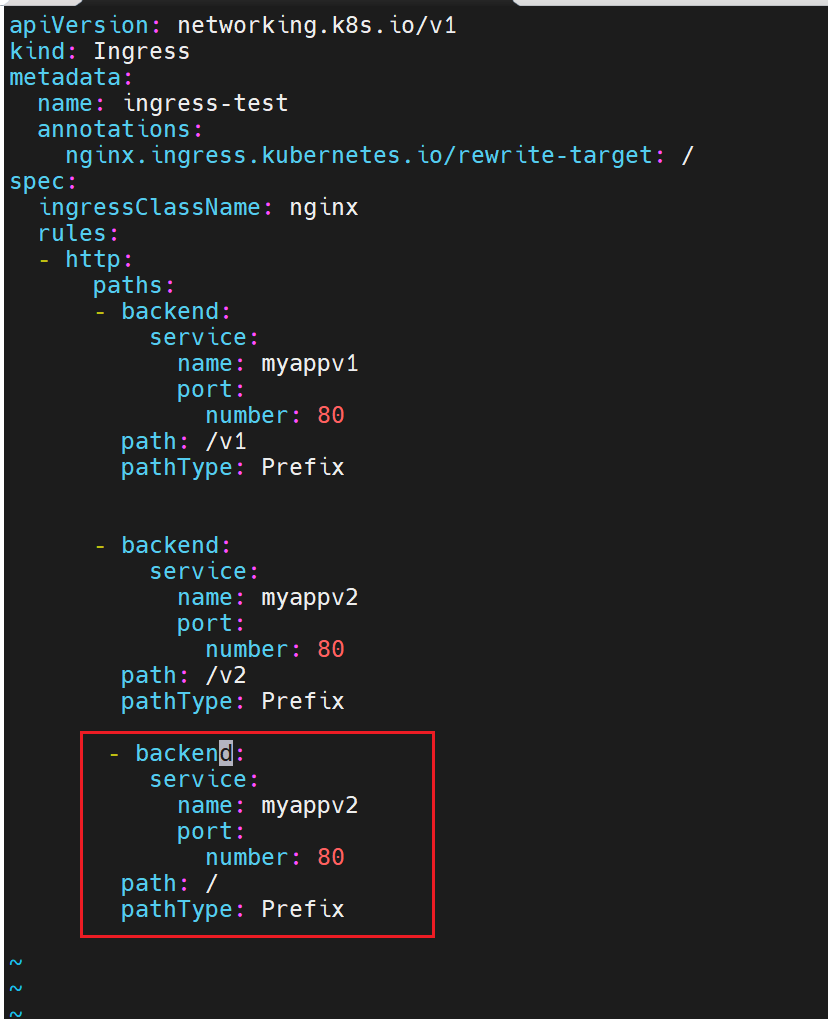

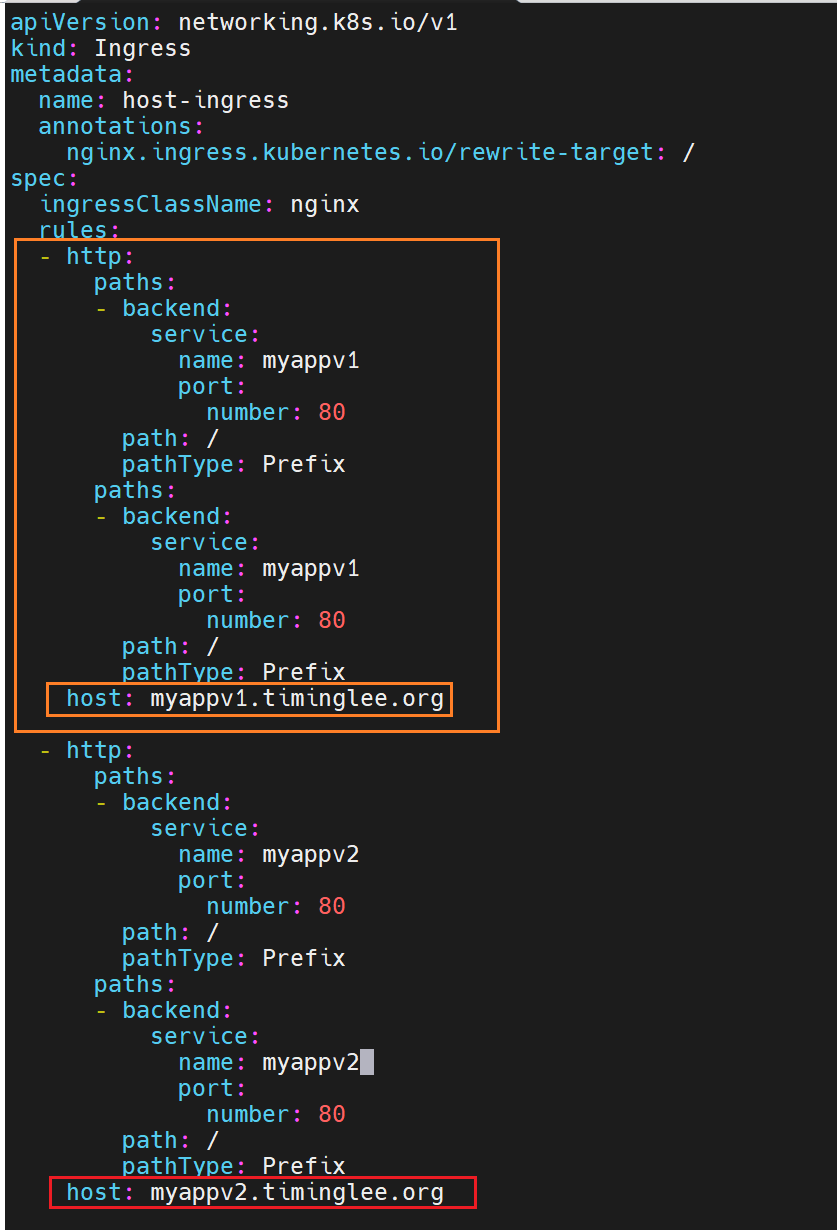
5.3 基于域名的多业务入口
# ingress-domain.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-domain
spec:
ingressClassName: nginx
rules:
- host: myappv1.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v1, port: {number: 80}}
- host: myappv2.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v2, port: {number: 80}}
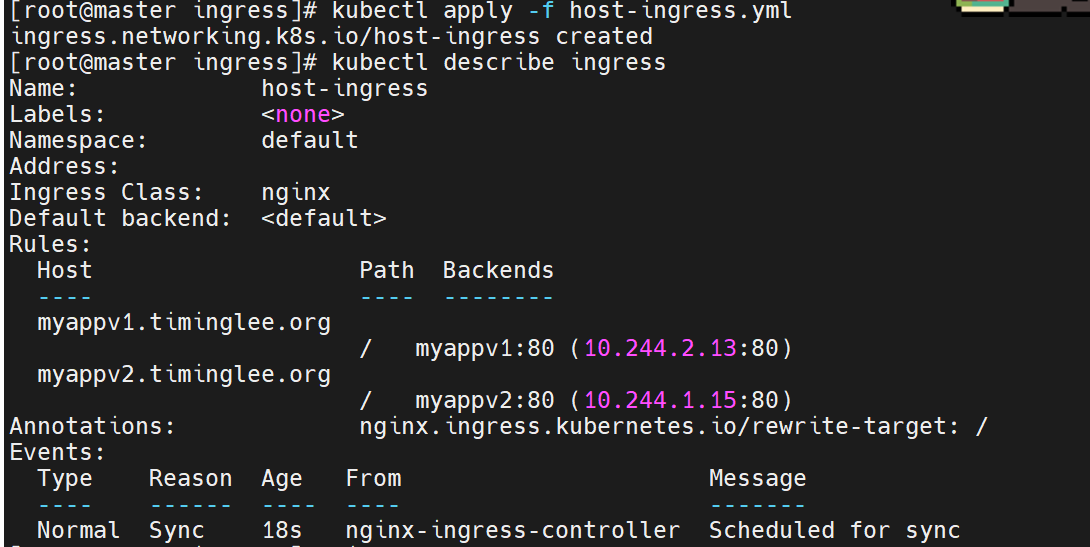
kubectl apply -f ingress-domain.yaml
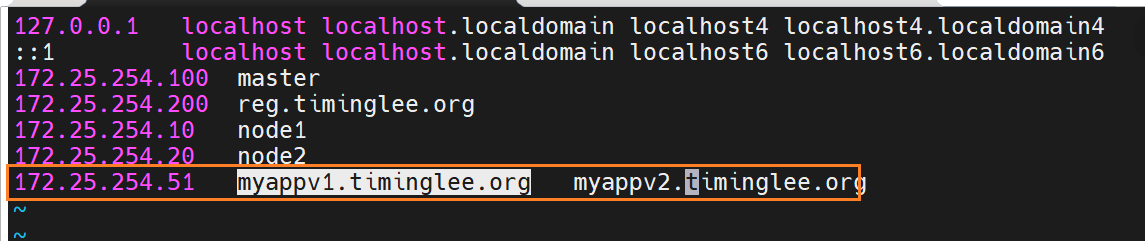
curl http://myappv1.timinglee.org # Version: v1
curl http://myappv2.timinglee.org # Version: v2
子集写在最前面也行,写最后面也行
此时我们

5.4 HTTPS(TLS)一键启用
5.4.1 自签证书 & Secret
openssl req -x509 -newkey rsa:2048 -nodes -keyout tls.key -out tls.crt -days 365 \
-subj "/CN=myapp-tls.timinglee.org"
kubectl create secret tls web-tls-secret --cert=tls.crt --key=tls.key5.4.2 启用 TLS 的 Ingress
# ingress-tls.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-tls
spec:
ingressClassName: nginx
tls:
- hosts: [myapp-tls.timinglee.org]
secretName: web-tls-secret
rules:
- host: myapp-tls.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v1, port: {number: 80}}
kubectl apply -f ingress-tls.yaml
curl -k https://myapp-tls.timinglee.org # HTTPS 成功生成证书去加密
设置非交互式输入
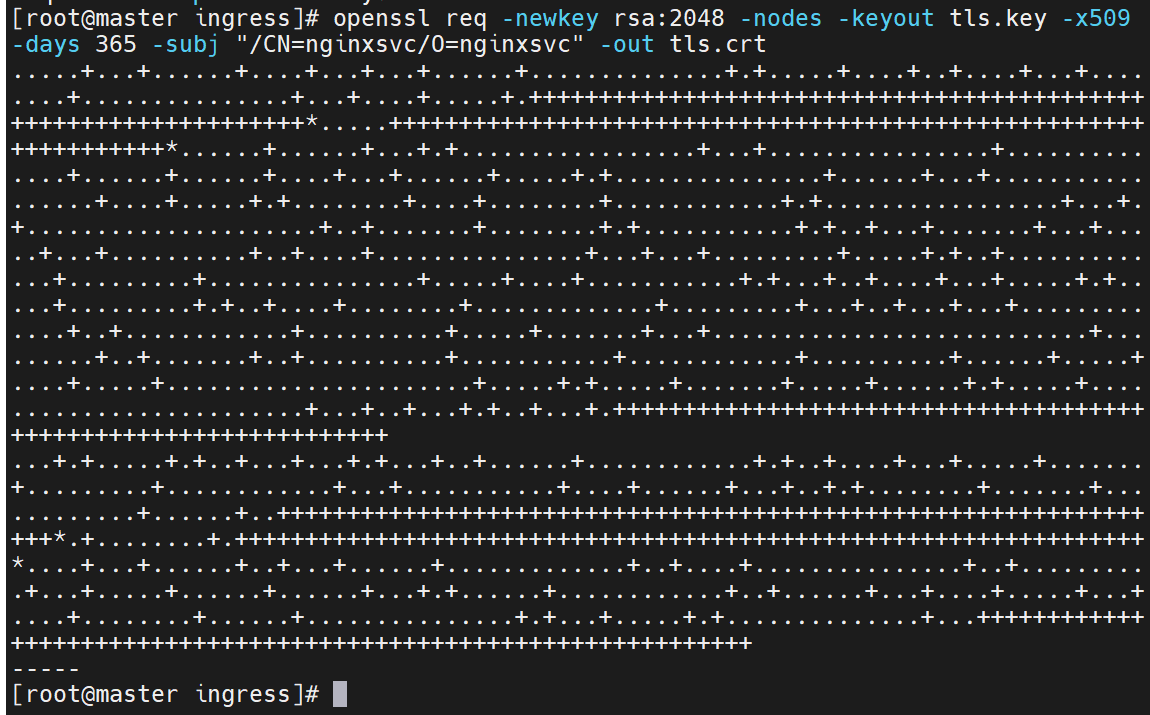
此时生成的证书与集群无关

把证书变成资源,能被集群调用

里面有两个文件
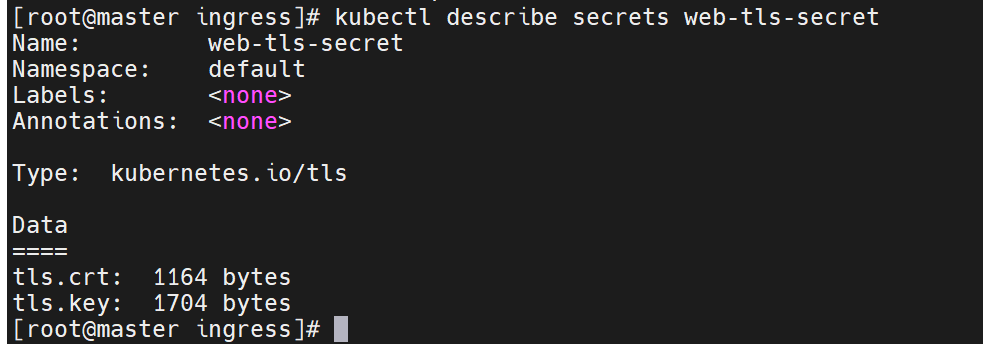
查看资源信息,它们以键值的方式保存了
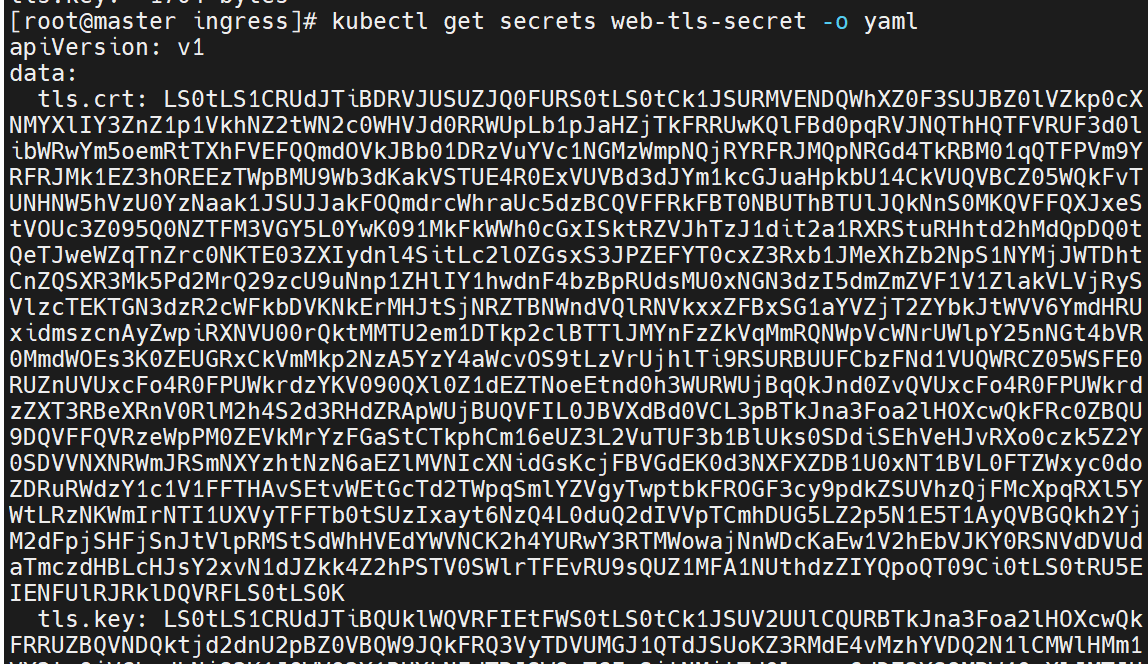

要把加密的模式保存到配置文件中去
一次性可以给多个设备加密 host
最终要调用的资源里的证书
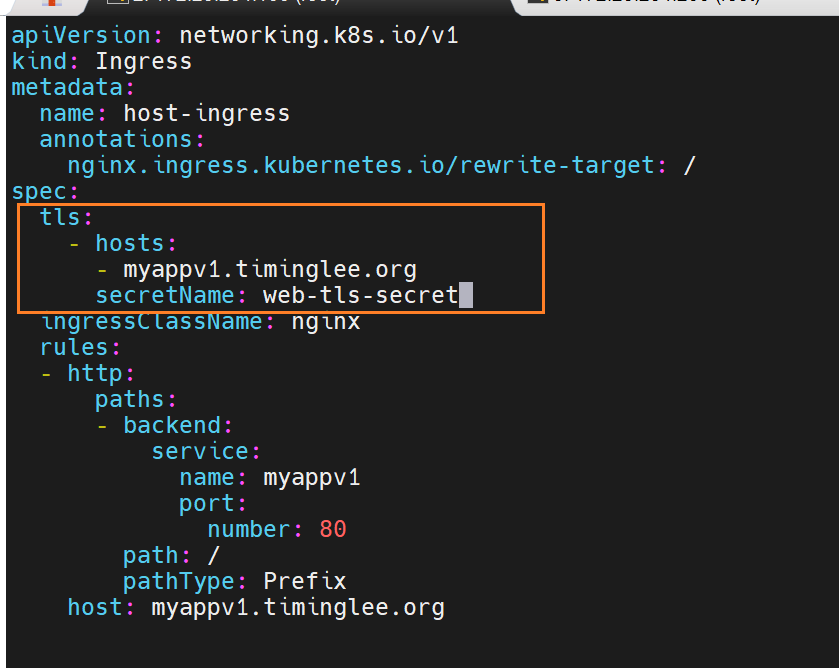
查看新建的ingress的详细情况,是否加密成功
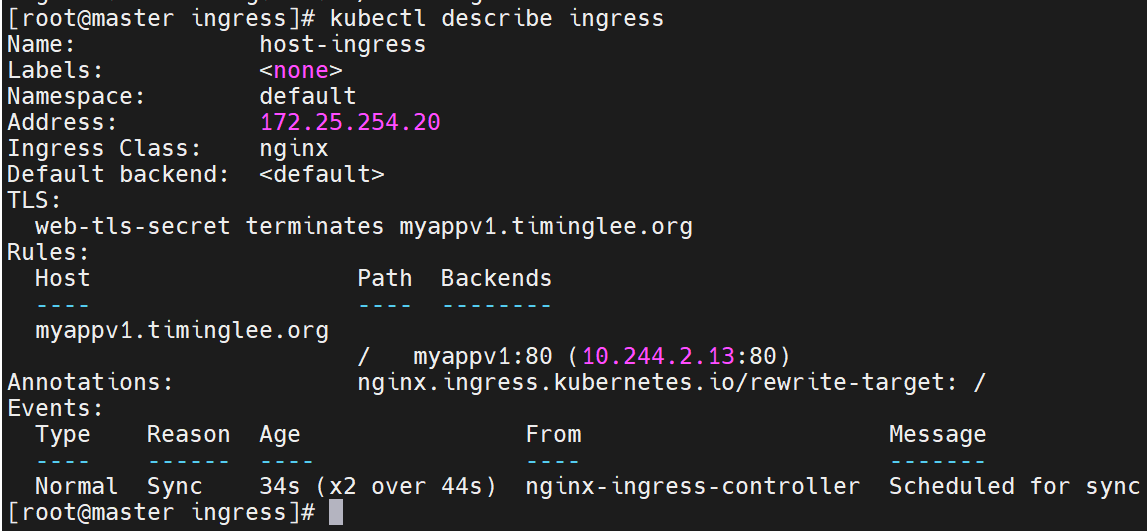
此时直接访问已经不行了
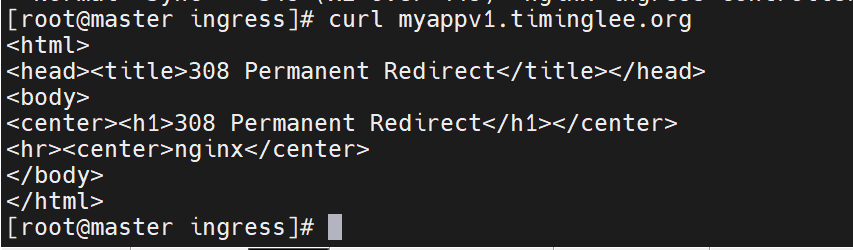

https:// 表示使用 HTTPS 协议 访问,符合 Ingress 配置中强制 HTTPS 的要求,因此不会被重定向。
-k 参数的作用是 跳过 SSL 证书验证。如果你的 Ingress 使用的是自签名证书(而非可信 CA 颁发的证书),curl 会默认验证证书并报错(如 SSL certificate problem)。加上 -k 后会忽略证书验证,从而成功建立连接并获取响应。
5.5 Basic Auth 用户认证
5.5.1 生成密码文件并写入 Secret
dnf install -y httpd-tools
htpasswd -cm auth lee # 输入两次密码
kubectl create secret generic auth-web --from-file=auth5.5.2 在 Ingress 中开启认证
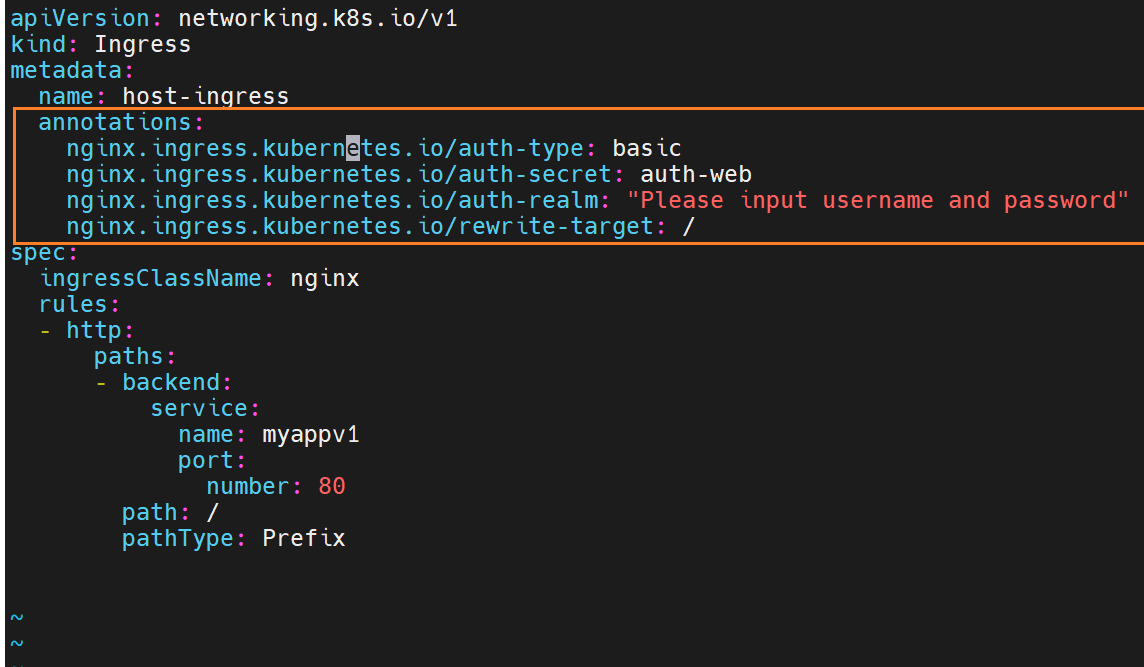
# ingress-auth.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-auth
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
spec:
ingressClassName: nginx
tls:
- hosts: [myapp-tls.timinglee.org]
secretName: web-tls-secret
rules:
- host: myapp-tls.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v1, port: {number: 80}}用户级别的访问限制
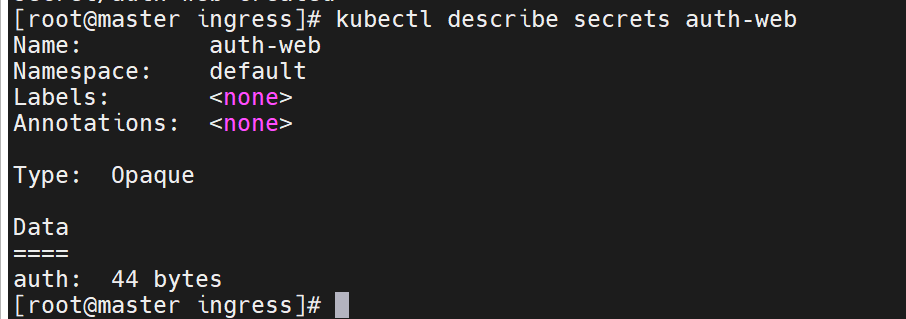
此时的文件还是没有关系和集群

要通过这个命令,把这个叫做htpasswd的文件抽象成集群中的资源


编辑配置文件,要用到参数

 在调用时,也会验证这些参数
在调用时,也会验证这些参数
错误情况:
这里会错误,是因为他默认调用auth这个名字,而之前创建用户密码时,储存的文件名不是它,系统此时访问不了
修改名字:
删除之前储存的资源
重新建立资源
删除之前运行的配置文件
重新运行一次就行了
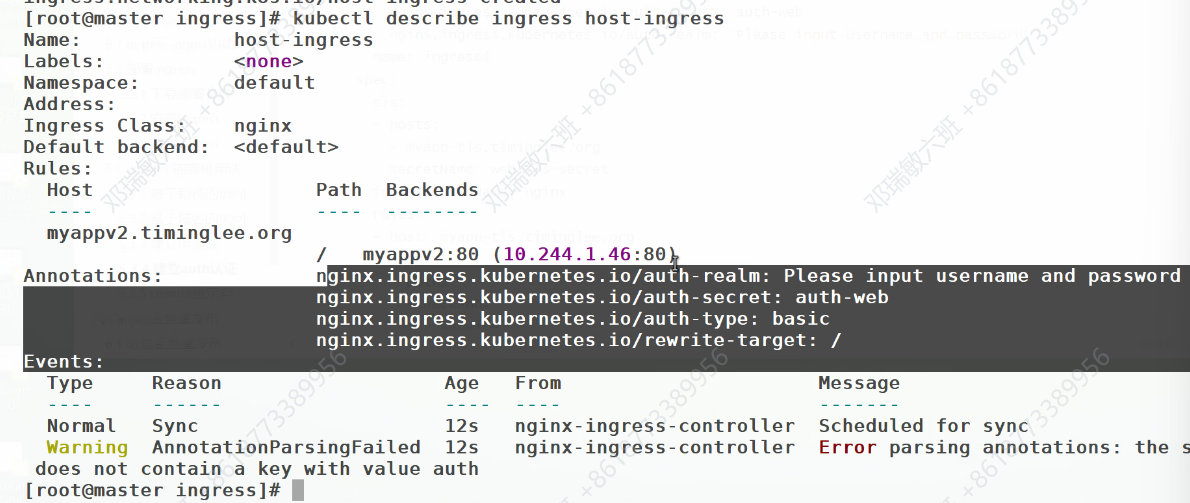




kubectl apply -f ingress-auth.yaml
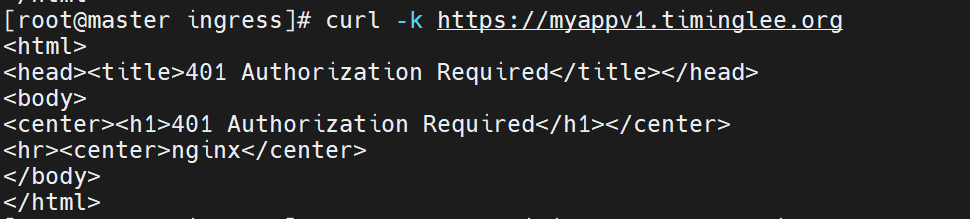
curl -k https://myapp-tls.timinglee.org # 401 Unauthorized
curl -k -u lee:lee https://myapp-tls.timinglee.org # 200 OK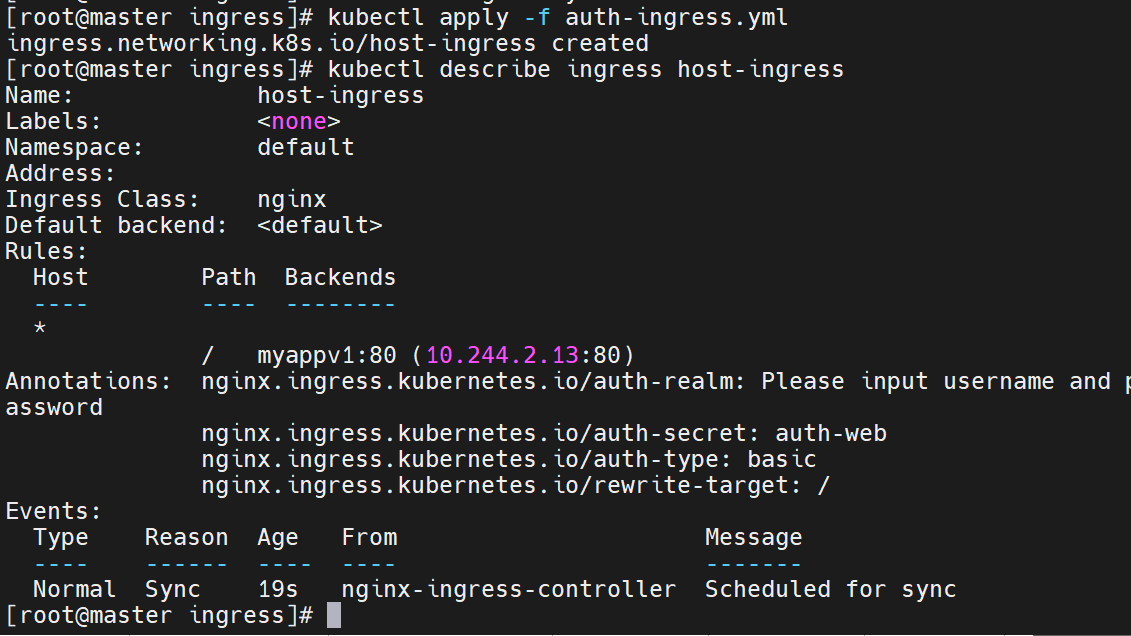

5.6 URL 重写(Rewrite)与正则
5.6.1 根路径重定向
nginx.ingress.kubernetes.io/app-root: /hostname.html5.6.2 正则捕获与重写
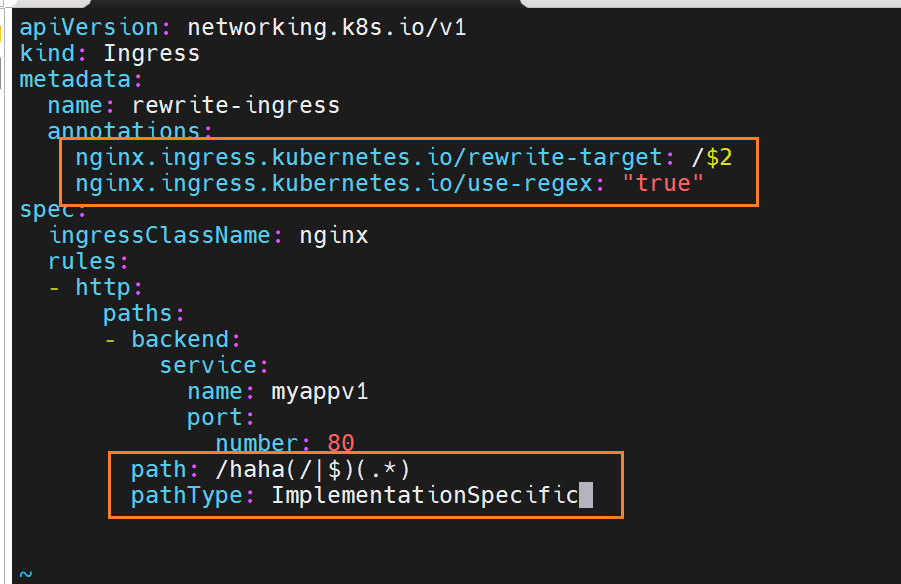
# ingress-rewrite.yaml
metadata:
annotations:
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- host: myapp-tls.timinglee.org
http:
paths:
- path: /lee(/|$)(.*) # 匹配 /lee 或 /lee/xxx
pathType: ImplementationSpecific
backend:
service: {name: myapp-v1, port: {number: 80}}
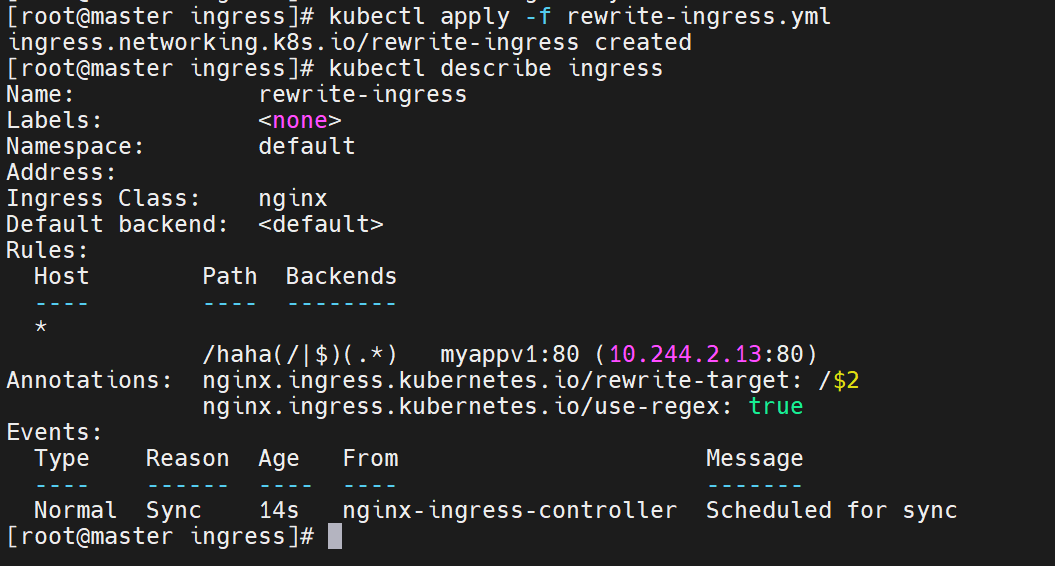
curl -k -u lee:lee https://myapp-tls.timinglee.org/lee/hostname.html
# 实际返回 /hostname.html 内容
匹配正则表达式

测试:

六、金丝雀(Canary)发布
6.1 核心思路
-
先少量、后全量:降低新版本全量故障风险
-
Ingress-Nginx 支持 Header / Cookie / 权重 三种灰度策略
-
发布过程 只增不减:Pod 总数 ≥ 期望值,业务无中断
6.2 基于 Header 的灰度
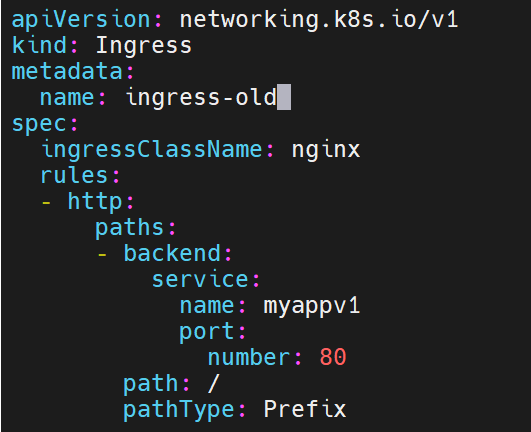
6.2.1 正式流量 Ingress(v1)
# myapp-v1-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v1-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v1, port: {number: 80}}部署老版本的


升级后的访问是要基于什么情况下访问
要写参数来设置了
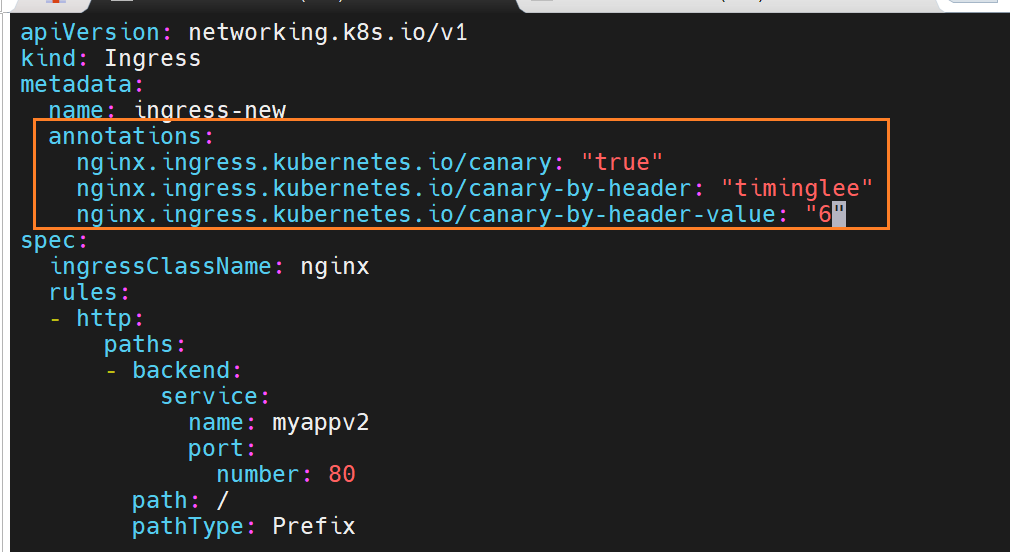

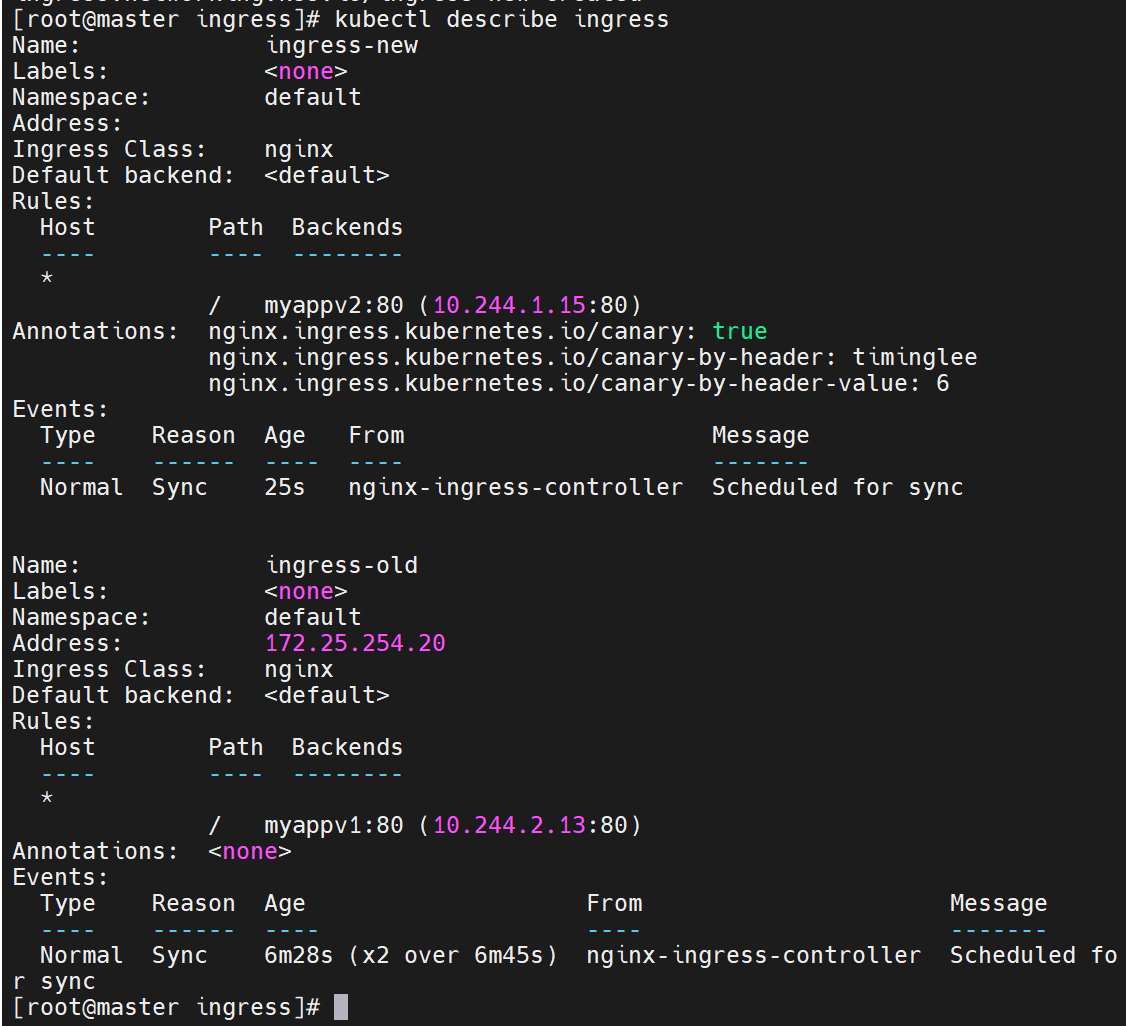
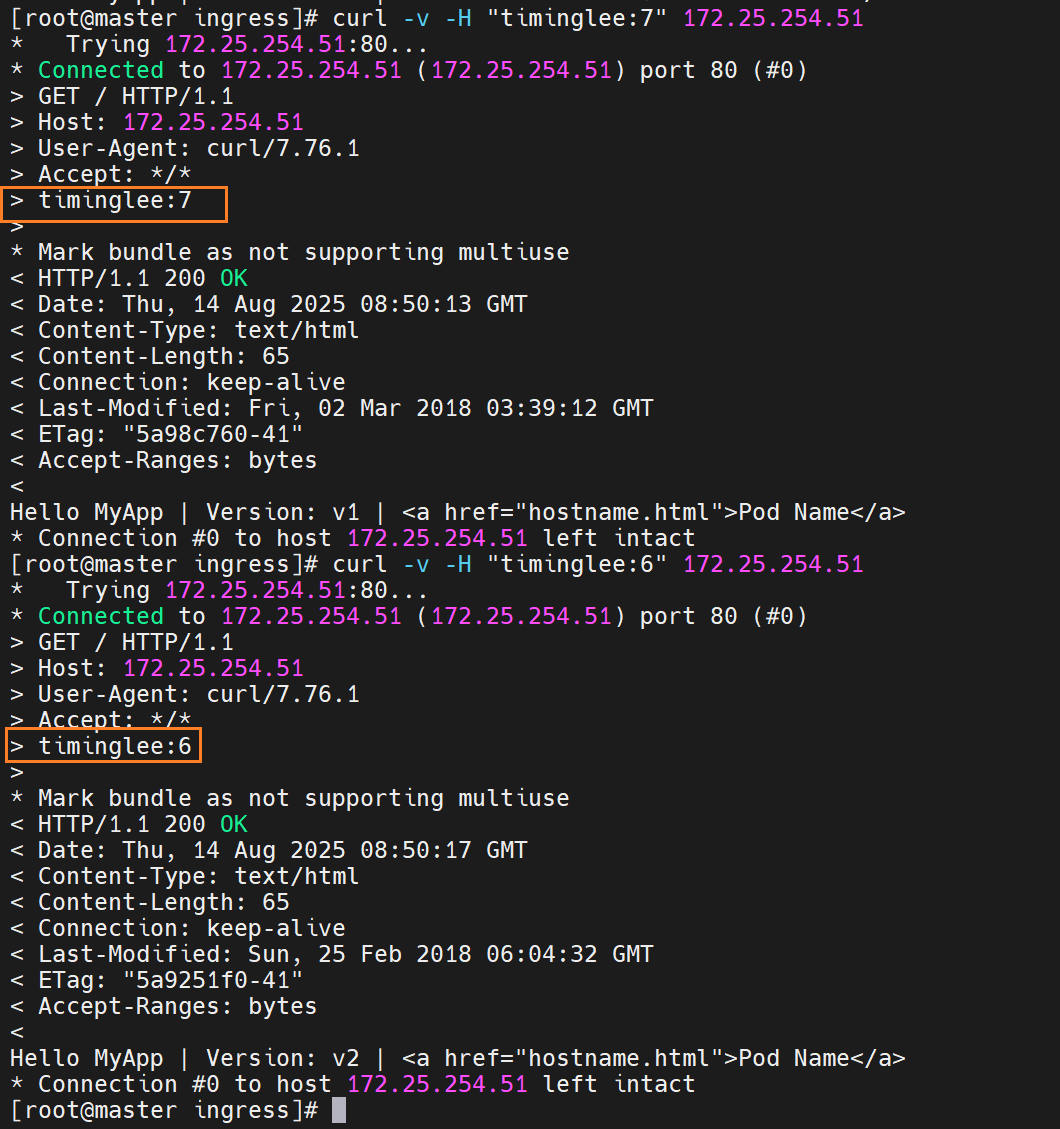
当携带timinglee的值是6时,就访问new的
6.2.2 灰度流量 Ingress(v2)
# myapp-v2-canary-header.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v2-canary
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "version"
nginx.ingress.kubernetes.io/canary-by-header-value: "2"
spec:
ingressClassName: nginx
rules:
- host: myapp.timinglee.org
http:
paths:
- path: /
pathType: Prefix
backend:
service: {name: myapp-v2, port: {number: 80}}
kubectl apply -f myapp-v1-ingress.yaml
kubectl apply -f myapp-v2-canary-header.yaml
# 测试
curl http://myapp.timinglee.org # v1
curl -H "version: 2" http://myapp.timinglee.org # v2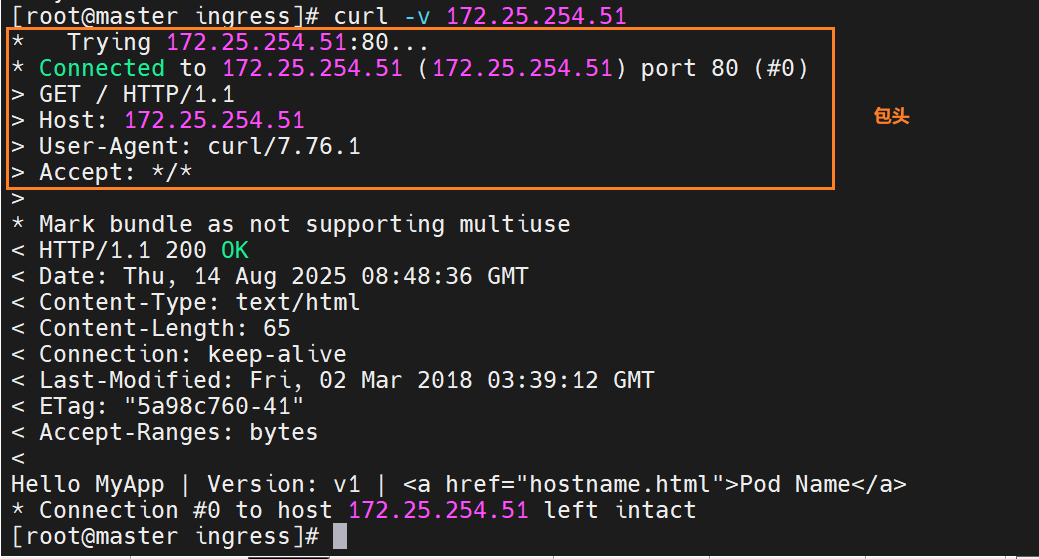

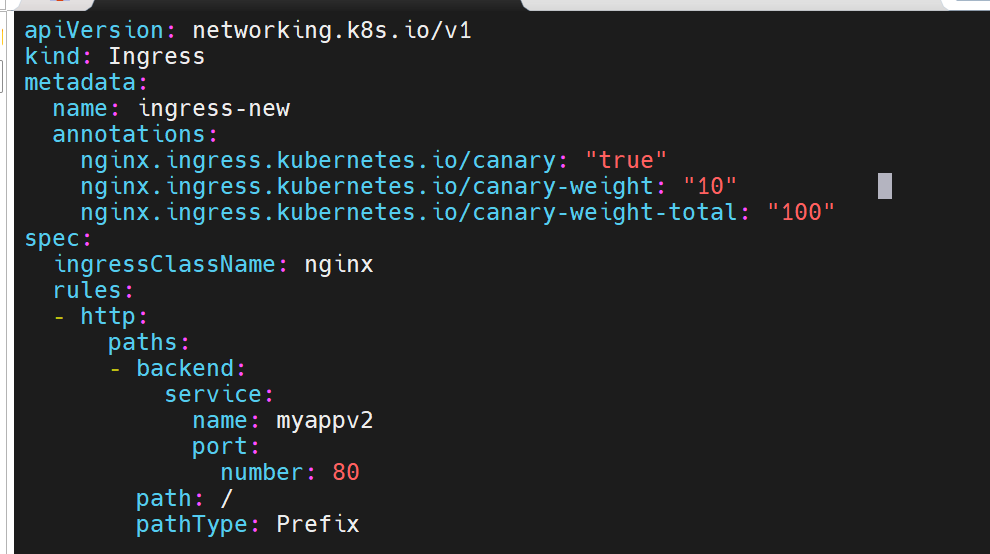
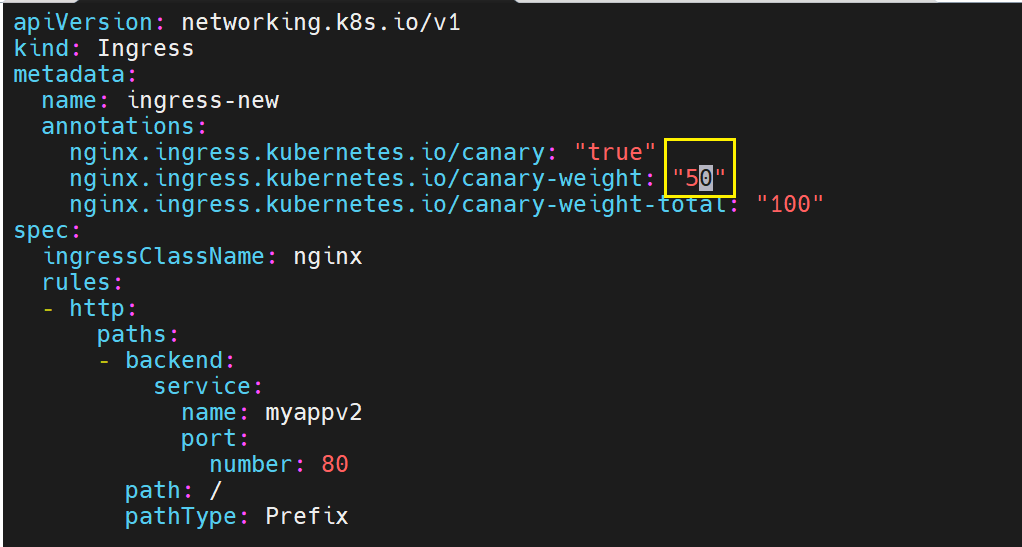
6.3 基于权重(Weight)的灰度
# myapp-v2-canary-weight.yaml
metadata:
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10" # 10%
nginx.ingress.kubernetes.io/canary-weight-total: "100"
kubectl apply -f myapp-v2-canary-weight.yaml
# 100 次采样脚本
for i in {1..100}; do curl -s myapp.timinglee.org | grep -c v2; done | awk '{v2+=$1} END{print "v2:"v2", v1:"100-v2}'
# v2:10, v1:90 # 符合 10% 权重

脚本测试:
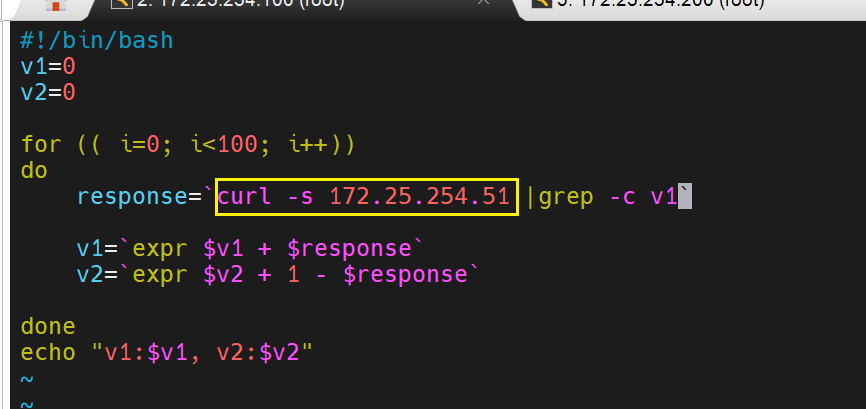
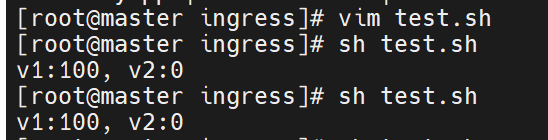
测试没有问题了
就修改权重
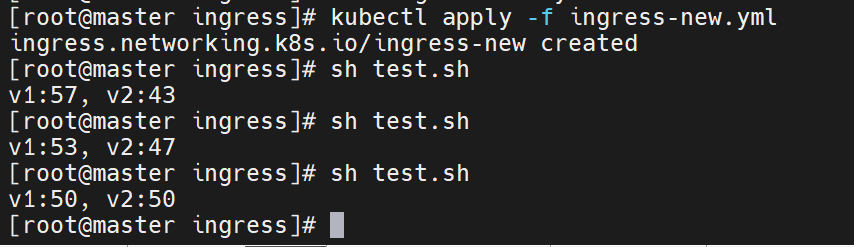
直到最后没有问题,old的版本就可以删除了
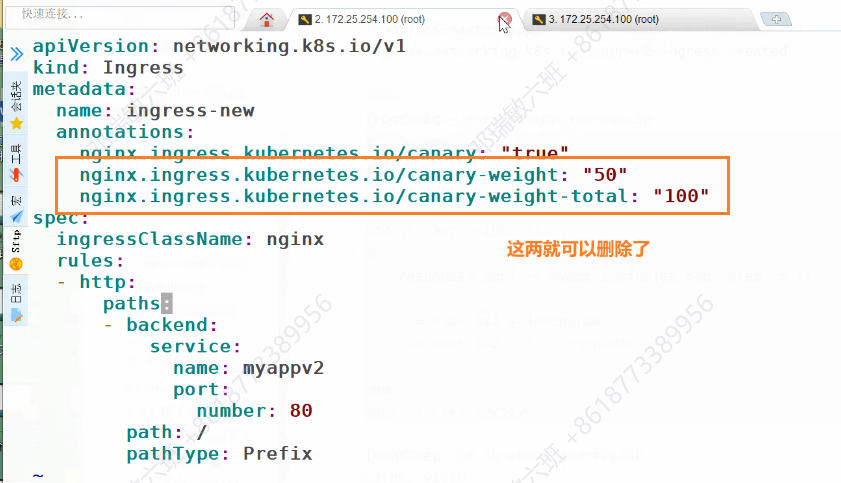
调整权重只需修改 annotation 后 kubectl apply,即可实现 平滑全量滚动。
七、一键清理
kubectl delete ingress --all
kubectl delete svc --all -l app=myapp-v1,app=myapp-v2
kubectl delete deploy --all -l app=myapp-v1,app=myapp-v2