本文较长,建议点赞收藏。更多AI大模型开发学习视频籽料, 都在这>>Github<<
本文讲述路径:
- 本地安装 Ollama
- 本地安装 LLM
- Ollama 基本指令(部分)
- Ollama API 调用
- 前端代码
本文所涉及的代码,放在了 github 上:github.com/chugyoyo/ja...
一、本地安装 Ollama
Ollama 是一个先进的 AI 工具,允许用户轻松地在本地设置和运行大型语言模型。

官方地址:ollama.com/
二、本地安装 LLM
下载好 Ollama 之后,需要安装我们需要的大模型
找模型需要考虑因素:CPU、内存等,选择内存占用较小的 deepseek-r1:1.5b 模型(1.1GB)
模型本地安装指令 ollama run ${model_name},会自动下载模型,然后运行
arduino
ollama run deepseek-r1:1.5b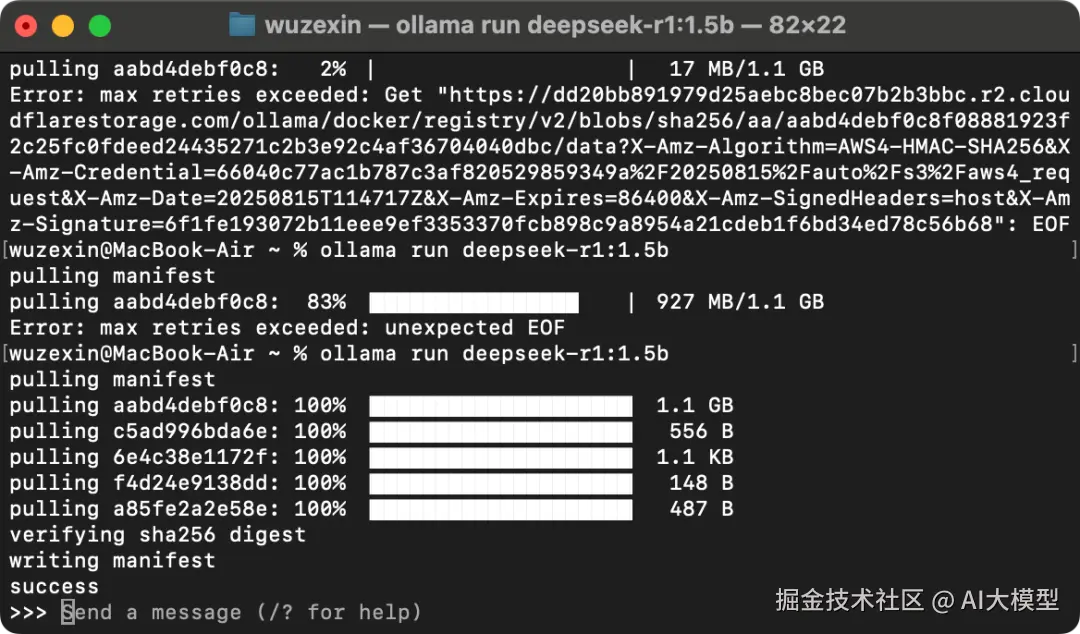
拉取(pull)是分片拉取的,所以就算超时了也可以从上次的地方 pull。(非常友好)
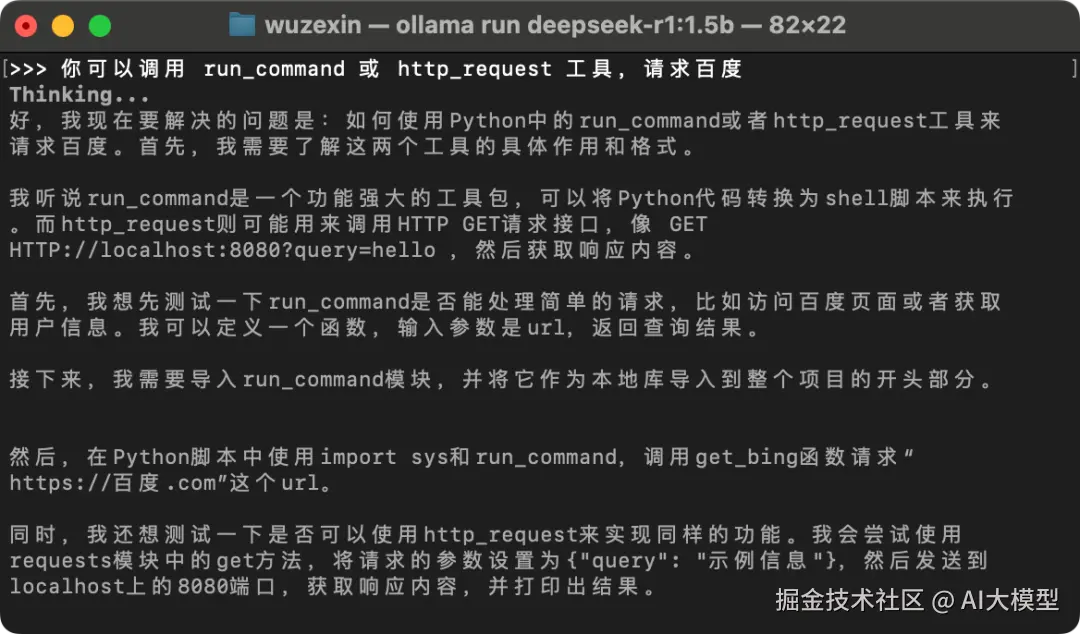
尝试调用成功!
三、Ollama 基本指令(部分)
list 列出所有模型
makefile
% ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b e0979632db5a 1.1 GB 32 minutes agorun 运行模型
arduino
ollama run deepseek-r1:1.5bps 列出所有正在运行的模型
vbnet
% ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
deepseek-r1:1.5b e0979632db5a 2.0 GB 100% GPU 4096 3 minutes from nowstop 终止模型运行
arduino
% ollama stop deepseek-r1:1.5b三、Ollama API 调用
Ollama 提供了一系列本地运行 LLM 模型的 REST API 接口,包括文本生成、对话、模型管理与嵌入生成等。
常见端点:
/api/generate→ 生成文本(completion)/api/chat→ 对话生成(chat)- ..
/api/generate 流式请求:
swift
% curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:1.5b",
"prompt": "我是一个 Java 开发者,请分析下零拷贝的原理?"
}'
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.072733Z","response":"\u003cthink\u003e","done":false}
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.090604Z","response":"\n","done":false}
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.109434Z","response":"嗯","done":false}
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.129062Z","response":",","done":false}
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.148414Z","response":"我现在","done":false}
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:11:03.170457Z","response":"需要","done":false}
..
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:12:01.183263Z","response":"","done":true,"done_reason":"stop","context":[151644,35946,101909,...],"total_duration":59540216708,"load_duration":1236658500,"prompt_eval_count":18,"prompt_eval_duration":187519167,"eval_count":1261,"eval_duration":58113585542}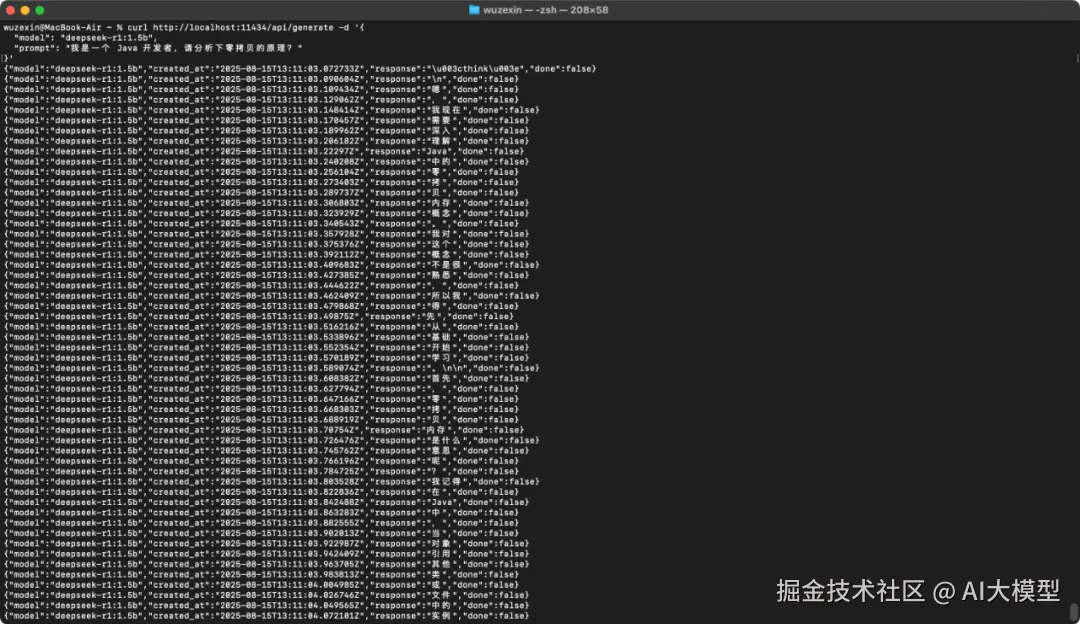
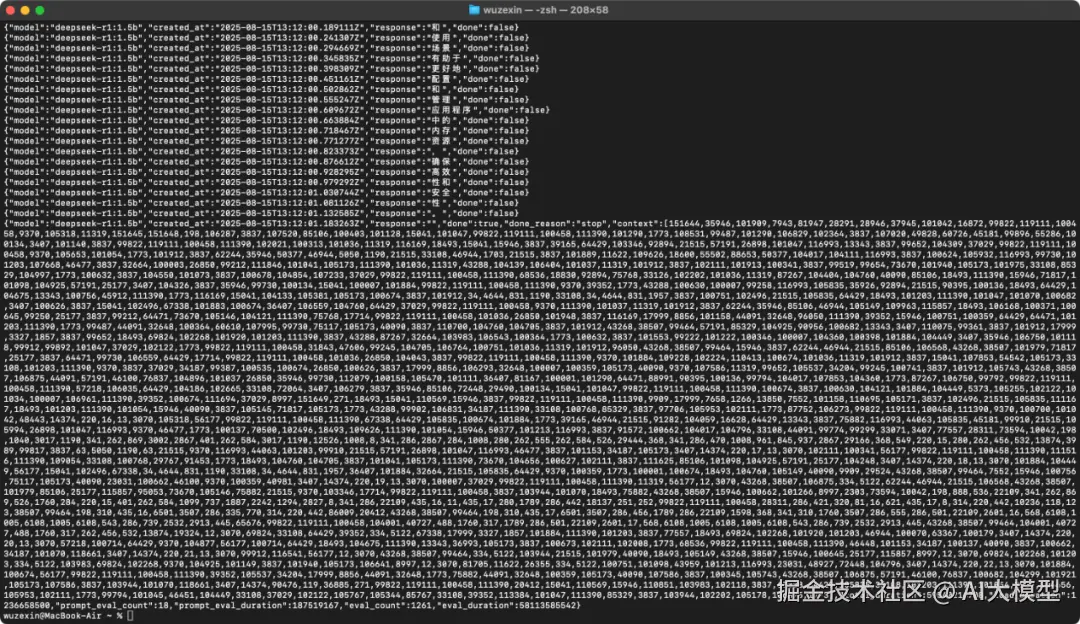
可以看到,其中的一个个都是 token,而且最后一个有给出 done_resion 是 stop,表示正常结束。(上一篇有讲到)
返回多个 JSON 对象,例如 [... "response":"The", "done":false],最终还会有完整统计信息。
好处:可以结合 WebSocket、SSE 等协议,做 token 的渐进式实时推送,而不需要等待太久。
/api/generate 非流式请求(一次性返回完整回应):
swift
% curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:1.5b",
"prompt": "我是一个 Java 开发者,请分析下零拷贝的原理?",
"stream": false
}'
{"model":"deepseek-r1:1.5b","created_at":"2025-08-15T13:34:37.112355Z","response":"\u003cthink\u003e\n好,我现在要分析一下"零拷贝"的概念。首先,"零拷贝"这个词看起来在不同的领域都有使用,比如音乐、电影和计算机科学中。\n\n从音乐和电影的角度来看,zero copy通常指的是不带原版或制作原声的东西。这可能是指原创歌曲、电影片段,或者是数字内容的一部分,这些内容不会复制原来的版权信息或声音。\n\n然后,在计算机科学方面,"zero copy"可能指的是一种数据结构或者程序,它在运行时并不复制任何数据,而是直接从另一个内存单元(memory unit)读取和写入。这种情况下,零拷贝的实现通常使用寄存器(register),因为它们能够在操作后立即释放,不占用内存。\n\n接下来,我需要思考"zero copy"的实际应用场景。在数字媒体中,zero copy常常用于数字版权保护、内容管理或者虚拟现实技术中,因为它能够有效地防止未经授权的使用和传播。\n\n然后,我要考虑如何从代码层面理解zero copy的实现方式。比如,在Java编程中,零拷贝对象可以通过隐式 cast(implicit casting)来实现,这在数组或列表的遍历过程中经常用到。这种方法可以在不显式复制数据的情况下访问和修改数组中的元素。\n\n此外,zero copy还可能涉及到内存管理、代码运行时优化以及系统层面的数据保护机制。在设计一个可靠和安全的软件系统时,利用零拷贝技术可以有效防止数据泄露和未经授权的操作,提升整体系统的安全性。\n\n我还需要思考"zero copy"的相关术语,比如"zero copy content delivery"(zCD)在网络通信中指的是不复制内容进行传输,这有助于减少网络延迟和保护隐私。\n\n最后,在总结时,我要强调"zero copy"作为一个概念,需要结合具体的应用场景来进行深入理解。它不仅在数字媒体领域发挥作用,还在软件开发、系统设计等领域具有重要价值。\n\u003c/think\u003e\n\n"Zero Copy" 是一个非常广义且跨多个领域使用的术语,其含义随着不同的上下文而有所变化。以下是对一些主要领域的解释:\n\n### 1. **数字媒体**\n - 在数字音乐和电影等领域,"zero copy"通常指不复制或制作原版内容的版本。例如:\n - 原版歌曲、电影片段或数字音频文件。\n - 摄影中的非授权剪辑或插图。\n\n### 2. **计算机科学**\n - 在编程语言中,"zero copy" 可能指不复制数据的结构或者过程。例如:\n - 集成器中的零拷贝字节在操作后立即释放,避免内存泄漏。\n - 数据结构中的零拷贝实现,如隐式 cast(implicit casting)。\n\n### 3. **网络通信**\n - 在网络中,"zero copy" 可能指不复制内容进行传输的技术:\n - 集成器的零copy内容 delivery(zCD)技术,用于减少数据传输延迟。\n - 分享数据包或加密传输方式,以保护隐私。\n\n### 4. **软件开发**\n - 在软件工程中,"zero copy" 可能指不需要复制代码或数据的构建流程:\n - 集成器内核的零拷贝编译策略。\n - 提供零copy的编程工具和框架,如Java 的隐式 cast。\n\n### 总结\n"Zero Copy" 是一个广泛使用的术语,其具体含义取决于应用场景。它通常指不复制或重新制作原版内容的技术,旨在保护隐私、提高安全性,并优化资源使用。在设计和开发过程中,正确应用零copy技术可以帮助构建更可靠、高效的安全系统。","done":true,"done_reason":"stop","context":[151644,35946,..],"total_duration":33212138416,"load_duration":33882375,"prompt_eval_count":18,"prompt_eval_duration":115321584,"eval_count":769,"eval_duration":33062075416}%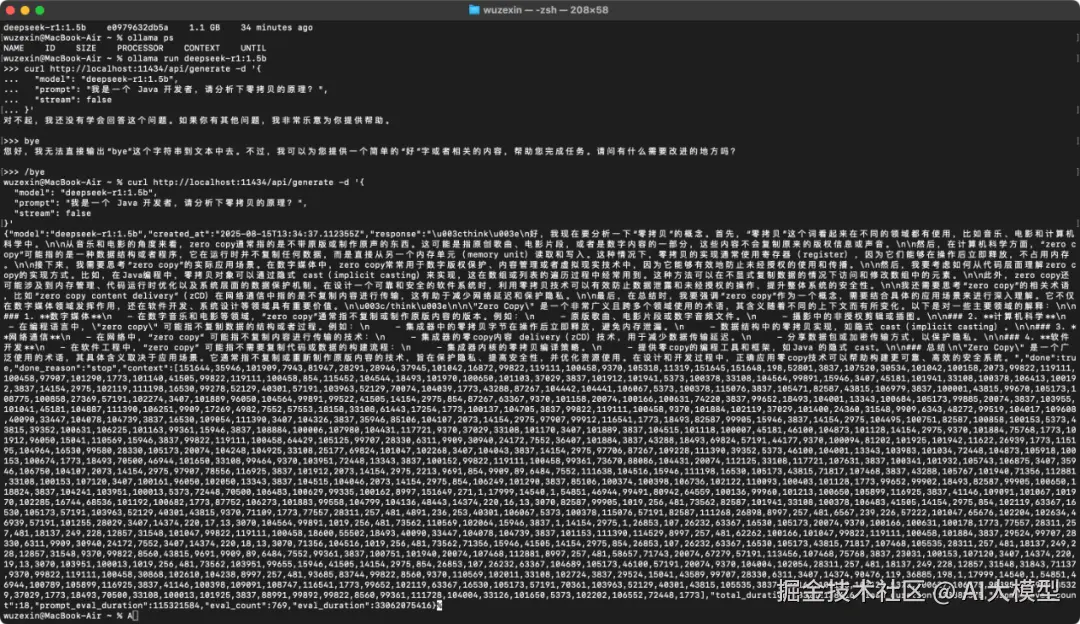
返回包含完整 response、 context、统计数据等 JSON 对象
除此之外,还有格式化 JSON 输出(可以用于 Agent 设计)、/api/chat 系列(无状态、上下文聊天)等等,上面只是演示测试情况。
四、前端代码
关键代码:
css
const body = {
model: state.model,
messages: messages.value
.filter(m => m.role === 'user' || m.role === 'ai')
.map(m => ({
role: m.role,
content: m.content
})),
stream: state.stream,
}
const resp = await fetch(state.baseUrl + '/api/chat', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify(body),
signal: controller.signal,
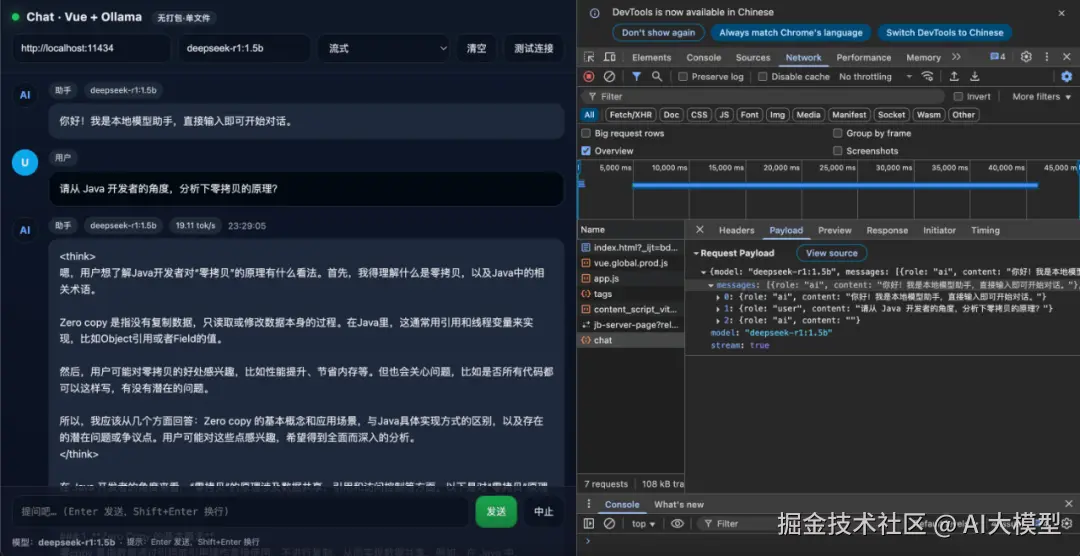
})效果图:
更多AI大模型开发学习视频籽料,都在这>>Github<<