背景
前一阵数分小姐姐跑路了把任务都交接给数仓了,最近发现其中的一个 hive 报表任务每天运行 1.5~2h 同时占用大量资源,晒下问题 sql:
sql
INSERT OVERWRITE TABLE live_room_expo_day
SELECT
'${date}' AS dt,
NVL(country, 'total') AS country,
NVL(platform, 'total') AS platform,
'total' AS version,
NVL(page, 'total') AS page,
NVL(is_new, 'total') AS is_new,
NVL(content_type, 'total') AS content_type,
NVL(is_visitor, 'total') AS is_visitor,
-- 曝光相关指标
COUNT(DISTINCT IF(event IN('feed_exposure','banner_exposure'), lid, NULL)) AS exp_lives,
COUNT(DISTINCT IF(event IN('feed_exposure','banner_exposure'), host_uid, NULL)) AS exp_host_uid,
COUNT(DISTINCT IF(event IN('feed_exposure','banner_exposure'), uid, NULL)) AS exp_users,
COUNT(DISTINCT IF(event IN('feed_exposure','banner_exposure'), CONCAT(lid,uid), NULL)) AS exp_cnt,
...省略其他32个count distinct指标
-- 点击相关指标
COUNT(DISTINCT IF(event IN('feed_click','banner_click') AND show_type='selective', lid, NULL)) AS selective_click_lives,
COUNT(DISTINCT IF(event IN('feed_click','banner_click') AND show_type='selective', host_uid, NULL)) AS selective_click_host_uid,
COUNT(DISTINCT IF(event IN('feed_click','banner_click') AND show_type='selective', uid, NULL)) AS selective_click_users,
COUNT(DISTINCT IF(event IN('feed_click','banner_click') AND show_type='selective', CONCAT(lid,uid), NULL)) AS selective_click_cnt
FROM (
SELECT
uid,
event,
version,
NVL(lid, rid) AS lid,
page,
platform,
host_uid,
is_pugc,
name,
live_dur_min,
NVL(is_new, 0) AS is_new,
IF(country IN('SA','AE','QA','KW'), country, 'other') AS country,
NVL(content_type, 'live') AS content_type,
aid,
device_id,
user_tag,
CASE
WHEN version >= '2.0.0' AND extend['show_type'] IS NOT NULL THEN extend['show_type']
WHEN version >= '3.0.0' AND extend['page_chanel'] = 'live' THEN 'selective'
WHEN version >= '3.0.0' AND extend['page_chanel'] = 'video' THEN 'engaging'
WHEN version >= '2.0.0' THEN 'other'
ELSE 'old version'
END AS show_type,
CASE
WHEN version < '2.0.0' THEN 'old version'
WHEN is_login = 1 THEN 'other'
ELSE 'visitor'
END AS is_visitor
FROM live_room_exposure_detail
WHERE dt = '${dt}'
AND page <> 'test'
AND country <> 'CN'
) a
GROUP BY country, platform, page, is_new, content_type, is_visitor WITH CUBE;关键信息:
- 包含 6 个维度的 cube,也就是最后产出 2⁶=64 种粒度的数据。
- 这段 sql 的查询语句中用到 40 个 count distinct。
我凭感觉想到的就是不需要优化啦,直接使用 spark sql 引擎运行就好喽,因为在我的过往经验中,spark sql 的种种表现几乎是完全胜于 hive sql 的。
结果就是几乎所有这种类型的任务(对数分好多这种任务 😭)切换到 spark sql 跑几乎都全军覆没,根本跑不动。
神奇,到底是为什么呢?
结果在排查 Spark 执行计划时发现了端倪。请看:
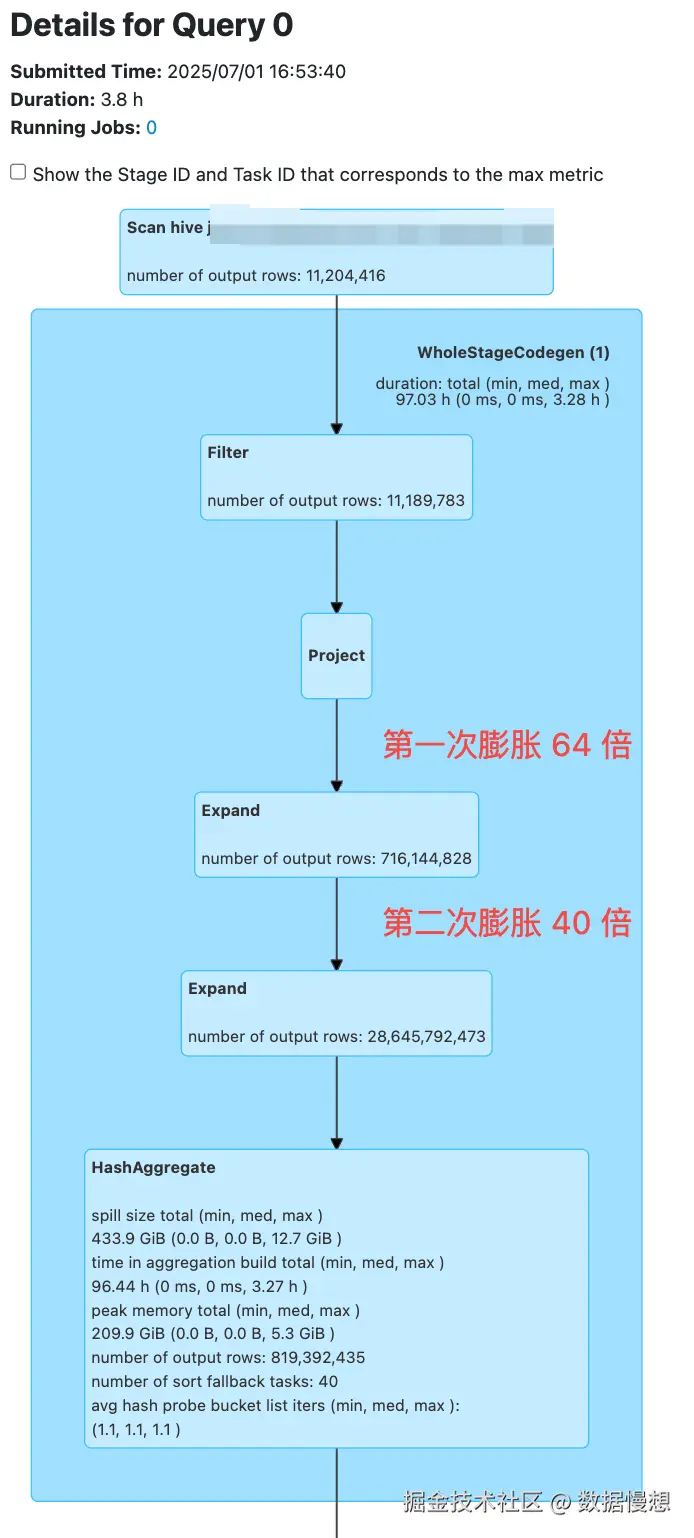 这张表的数据量是
这张表的数据量是82936714条,此时已经运行了 3.8h,已经远超 hive 任务的运行时长,但是目前只扫描了 1000 多 w 行数据,并且一共膨胀了 2560 倍,当前已膨胀条数 286 亿+条,预计共膨胀 82936714*2560=212,317,987,840,约等于 2123 亿条数据。。。果断把任务 kill 了。然后查找了相关资料对这两次膨胀才有了一定的了解。
两次 expand 背后的原理
第一次膨胀 64 倍
社区 Spark SQL 对多维分析采用 Expand 方式,一次读入数据,读入的每条数据会生成多条(2n,n 为维度大小)。也就是说,Expand 方式会将数据放大 2n 倍,然后将放大后的数据进行聚合。例如,下面的这条 SQL 语句。
css
select A,B, sum(C) from myTable group by A, B vwith cube在 Spark SQL 默认的 Expand 执行方式中,数据将会被放大 4 倍,对应逻辑如下图所示。每条数据会按照(A,B)两列的组合,添加一个 Grouping ID,以区分所属的分组。最终执行等价于在 4 倍数据上的一次聚合操作。

Expand方式执行的Cube
然而,当维度比较大或初始数据量比较大时,在这种数据指数性膨胀的执行方式下,数据 Shuffl e 的性能往往会非常差,某些资源有限的情形下还会出现 OOM 的问题。因此,团队在 Spark SQL 中增加了多维分析的 Union 实现方式。Union 方式不是一次读入数据,而是读入 2n 次数据,分别计算,然后将计算的结果合并。对于案例 SQL,Union 方式的思路如下图所示。可以看到,Union 方式会读取 4 次数据表,然后将 4 次的求和结果合并到一起。

Union方式执行的Cube
Union 方式和 Expand 方式各有优缺点,Expand 方式读取数据的次数只有一次,但数据会膨胀 2n 倍,而 Union 方式会读取数据 2n 次。总体来说,Expand 方式适合维度小的多维分析,Union 方式适合维度大的多维分析。本质上,Union 方式是一种"细水长流"的策略,与常见的 IO 复用等优化思想相反。
第二次膨胀 40 倍
这里是由于 40 个 count(distinct)的 expand 导致数据膨胀 40 倍,为了不影响篇幅大小,之后会专门出一篇文章给大家讲解下。
解决方案
cube 改为 union all
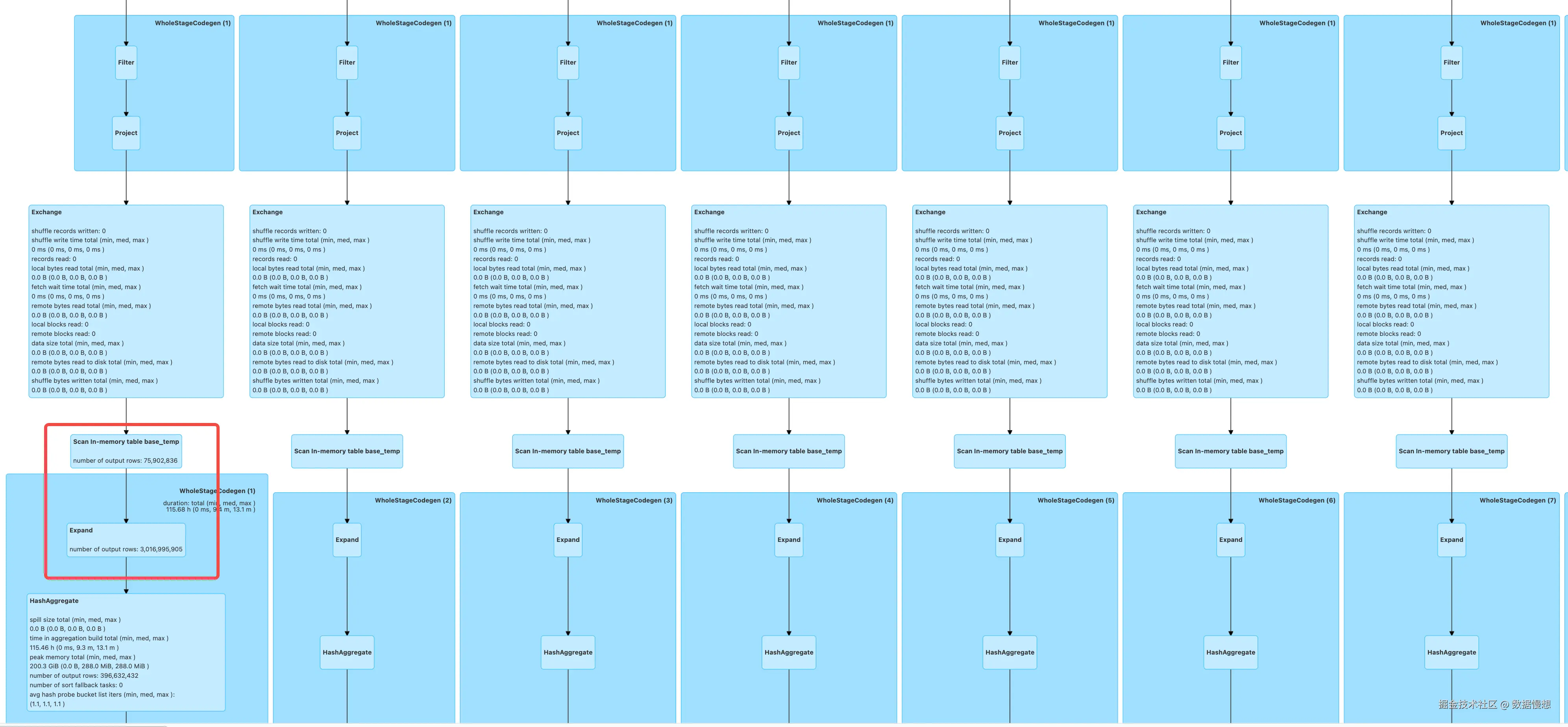 尽管改成了把 cube 改成了 union all 但是,依然还是会触发 count(distinct)产生的 40 倍膨胀,而且由于底表的数据量已经达到了接近 1 亿条,可以从 spark UI 中很明显的看到膨胀的进程的速度是非常缓慢的,所以这个方案被否定。
尽管改成了把 cube 改成了 union all 但是,依然还是会触发 count(distinct)产生的 40 倍膨胀,而且由于底表的数据量已经达到了接近 1 亿条,可以从 spark UI 中很明显的看到膨胀的进程的速度是非常缓慢的,所以这个方案被否定。
优化掉 count(distinct)和 cube
从以上分析可以得知,任务很明显发生了大数据量维度爆炸的严重性能问题,spark 在对于大数据量并且多维的 cube 表现是很差的,所以需要规避掉这种情况。
直接上代码。
less
@staticmethod
def generate_cube_combinations(dimensions):
"""
生成CUBE的所有组合
dimensions: 维度列表,如 ['country', 'platform', 'page', 'is_new', 'content_type', 'is_visitor']
"""
combinations_list = []
# 生成所有可能的组合(包括空组合)
for r in range(len(dimensions) + 1):
for combo in itertools.combinations(dimensions, r):
combinations_list.append(list(combo))
logging.info(f"生成组合数: {len(combinations_list)}")
logging.info(f"组合列表: {combinations_list}")
return combinations_list
def main(self):
# 定义维度和指标
dimensions = ['country', 'platform', 'page', 'is_new', 'content_type', 'is_visitor']
# 使用size(collect_set())替代count(distinct),参考SQL模板的优化
metrics = {
'exp_lives': "size(collect_set(case when event in('feed_exposure','banner_exposure') then lid end))",
'exp_host_uid': "size(collect_set(case when event in('feed_exposure','banner_exposure') then host_uid end))",
'exp_users': "size(collect_set(case when event in('feed_exposure','banner_exposure') then uid end))",
'exp_cnt': "count(case when event in('feed_exposure','banner_exposure') then lid_uid_key end)",
...省略其他32个count distinct指标
'selective_click_lives': "size(collect_set(case when event in('feed_click','banner_click') and show_type='selective' then lid end))",
'selective_click_host_uid': "size(collect_set(case when event in('feed_click','banner_click') and show_type='selective' then host_uid end))",
'selective_click_users': "size(collect_set(case when event in('feed_click','banner_click') and show_type='selective' then uid end))",
'selective_click_cnt': "count(case when event in('feed_click','banner_click') and show_type='selective' then lid_uid_key end)"
}
# 第一步:创建基础数据
temp_table_query = f"""
CACHE TABLE base_temp OPTIONS ('storageLevel' 'MEMORY_AND_DISK')
AS
SELECT
/*+repartition(50)*/
uid,
event,
nvl(lid, rid) as lid,
host_uid,
nvl(is_new, 0) as is_new,
platform,
page,
if(country in('SA', 'AE', 'QA', 'KW'), country, 'other') as country,
nvl(content_type, 'live') as content_type,
case
when version >= '2.0.0' and extend['show_type'] is not null then extend['show_type']
when version >= '3.0.0' and extend['page_chanel'] = 'live' then 'selective'
when version >= '3.0.0' and extend['page_chanel'] = 'video' then 'engaging'
when version >= '2.0.0' then 'other'
else 'old version'
end as show_type,
case
when version < '2.0.0' then 'old version'
when is_login = 1 then 'other'
else 'visitor'
end as is_visitor,
concat(nvl(lid, rid), uid) as lid_uid_key
FROM live_room_exposure_detail
WHERE dt='{self.dt}'
AND page<>'test'
AND country<>'CN'
group by 1,2,3,4,5,6,7,8,9,10,11,12
"""
self.spark.sql(temp_table_query)
logging.info("成功创建临时表 base_temp")
cube_combinations = self.generate_cube_combinations(dimensions)
query = self.build_cube_query_batch(dimensions, "base_temp", cube_combinations, metrics)
logging.info(query)
self.spark.sql(query).repartition(1).write.mode("overwrite").insertInto("jaco_live_room_expo_day_cube")
def build_cube_query_batch(self,dimensions, base_table, combinations_batch, metrics):
"""
构建一批组合的查询
"""
union_queries = []
for combo in combinations_batch:
# 构建SELECT字段
select_fields = []
group_fields = []
for dim in dimensions:
if dim in combo:
select_fields.append(f"nvl({dim}, 'total') as {dim}")
group_fields.append(dim)
else:
select_fields.append(f"'total' as {dim}")
for metric_name, metric_expr in metrics.items():
select_fields.append(f"{metric_expr} as {metric_name}")
group_by_clause = ", ".join(group_fields) if group_fields else ""
if group_by_clause:
query = f"""
SELECT
'{self.date}' as dt,
{', '.join(select_fields)}
FROM {base_table}
GROUP BY {group_by_clause}
"""
else:
query = f"""
SELECT
'{self.date}' as dt,
{', '.join(select_fields)}
FROM {base_table}
"""
union_queries.append(query)
return " UNION ALL ".join(union_queries)总结下以上代码:
- 分析 sql 后发现可以预先对 live_room_exposure_detail 对这张底表做一个去重从而减少一大半数据量,这一步很关键
- 将 count distinct 替换成collect_set 操作,这一步其实还可以继续优化,思路是对需要 distinct 的字段,比如以上案例中的 lid,host_uid 以及 concat(lid,uid)做一个去重打标,然后再一个外层对打标数据进行 sum 汇总。
- 将 cube 操作通过函数 generate_cube_combinations进行自动化维度组装,最终拼接成一个完整的 union all 语句
总结
通过这次 Spark SQL 多维分析优化实践,成功将原本需要 1.5-2 小时的 Hive 报表任务优化到了 3.2 分钟,性能提升了近 30 倍!我把这次的优化也同时进行了团队组内分享,得到了领导的赞扬并且大家也达成一致对于后续同类型的任务也沿用这套方法和代码进行优化啦!
核心优化策略回顾
- 数据预处理优化:对底表进行去重操作,大幅减少后续计算的数据量(我个人认为这一步是最重要的)
- 聚合函数替换 :将
COUNT DISTINCT替换为COLLECT_SET,避免了大量 count distinct 触发的底层 expand - cube 重构:通过程序化生成 CUBE 维度组合,将复杂的多维分析转换为高效的 UNION ALL 查询
最后卖个关子,其实在代码中我还做了一个很有效的隐蔽的优化对性能有很大的提升,不知道细心的同学发现了没有?大家还有什么更好的解决方案吗,欢迎评论区留言!
更多 Flink / Spark / Doris / Clickhouse / Paimon 实战文章,请关注公众号 「数据慢想」