1. standalone ha
Standalone集群中Worker汇报资源、提交应用程序、Driver申请资源时都需要与Master进行通信,如果Standalone集群中只有一个Master,当Master挂掉后就会影响以上通信,所以在Standalone集群中配置Master HA就有必要。
Master HA中有两个Master,一个Master为Active Master,另外一个是StandBy Master,当Active Master挂掉后,StandBy Master 切换为Active Master自动接管Spark集群,我们可以使用Zookeeper进行主备Master切换,zookeeper具备选举和存储功能,可以存储Spark集群Worker、Application信息。
1.1 节点规划
Standalone集群Master和备用的Master在各个节点上划分如下:
| 节点名称 | ActiveMaster | StandByMaster | Worker |
|---|---|---|---|
| hadoop101 | ★ | ||
| hadoop102 | ★ | ||
| hadoop103 | ★ | ||
| hadoop106 | ★ |
按照如下步骤进行Master HA搭建。
1.2 部署
1.2.1 配置spark-env.sh
在hadoop106节点上配置$SPARK_HOME/conf/spark-env.sh文件,写入如下内容:
export SPARK_MASTER_HOST=hadoop106
export SPARK_MASTER_PORT=30277
export SPARK_MASTER_WEBUI_PORT=30280
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=3g
export SPARK_WORKER_WEBUI_PORT=30281
export SPARK_WORKER_DIR=/data/spark
export SPARK_PID_DIR=/opt/module/spark-3.5.5
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop101:2181,hadoop102:2181,hadoop103:2181 -Dspark.deploy.zookeeper.dir=/sparkmasterha"以上配置项解释如下:
- spark.deploy.recoveryMode:Spark集群恢复模式为 ZOOKEEPER。
- spark.deploy.zookeeper.url:指定zookeeper集群地址。
- spark.deploy.zookeeper.dir:Spark 在 ZooKeeper 中存储集群状态信息的路径。
1.2.2 将spark-env.sh发送到其他spark standalone节点
[root@hadoop106 ~]# scp -r /opt/module/spark-3.5.5 hadoop101:`pwd`
[root@hadoop106 ~]# scp -r /opt/module/spark-3.5.5 hadoop102:`pwd`
[root@hadoop106 ~]# scp -r /opt/module/spark-3.5.5 hadoop103:`pwd`1.2.3 配置备用Master
这里选择hadoop101节点为StandBy Master,在该节点上配置$SPARK_HOME/conf/spark-env.sh,修改"SPARK_MASTER_HOST"为hadoop101。
1.2.4 启动Standalone集群
#在hadoop106启动Standalone集群
[root@hadoop106 ~]# cd /opt/module/spark-3.5.5/sbin
[root@hadoop106 sbin]# ./start-all.sh
#在hadoop101启动StandBy Master
[root@hadoop101 ~]# cd /opt/module/spark-3.5.5/sbin
[root@hadoop101 sbin]# ./start-master.sh1.3 验证
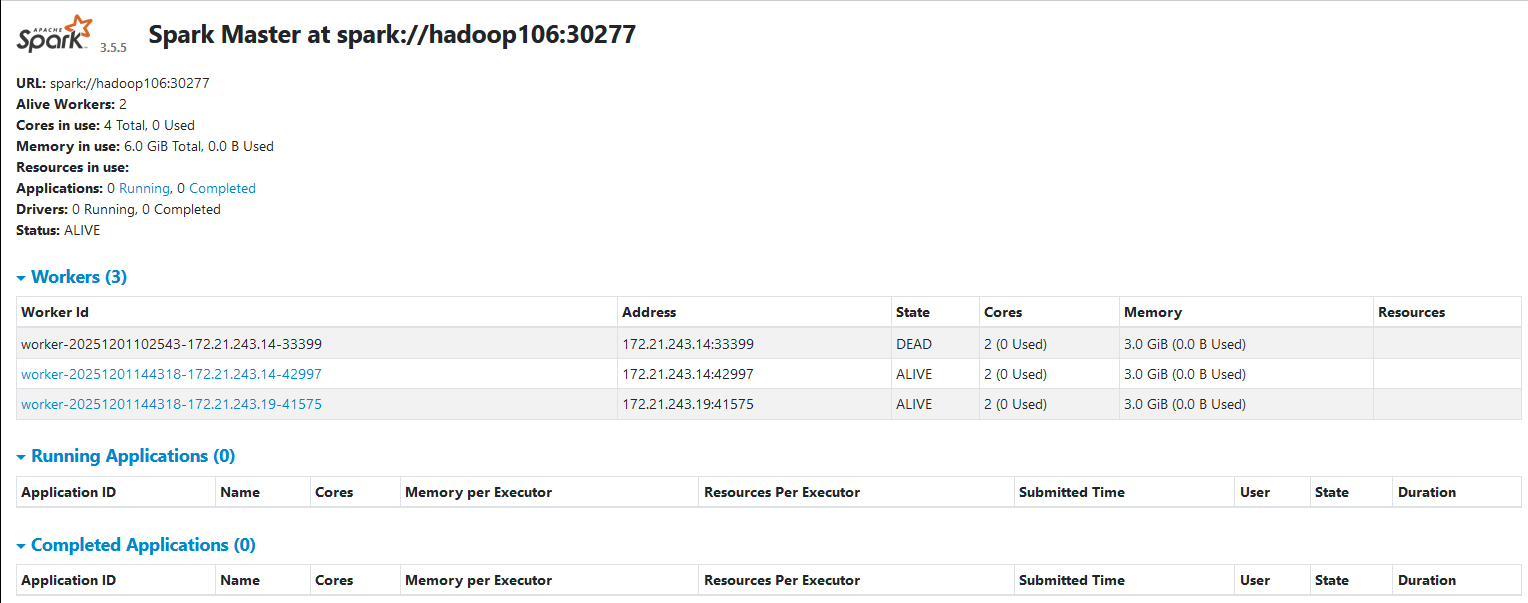
1.3.1 WebUI访问Active Master和StandBy Master WebUI
Active Master WebUI:
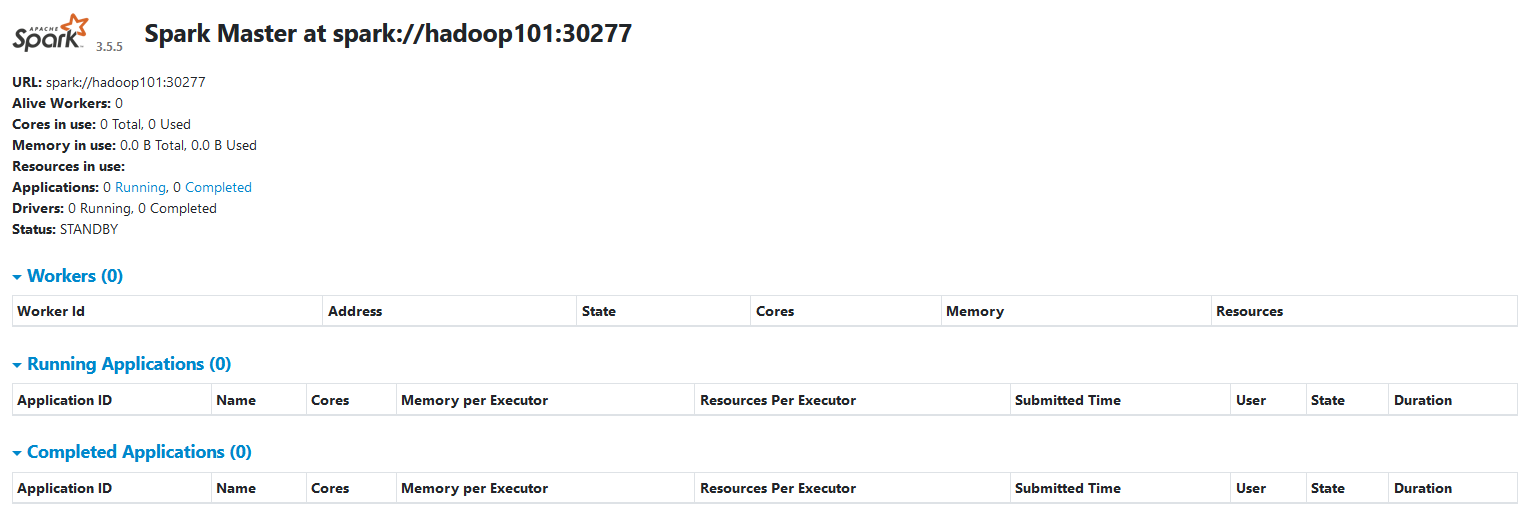
StandBy Master WebUI:
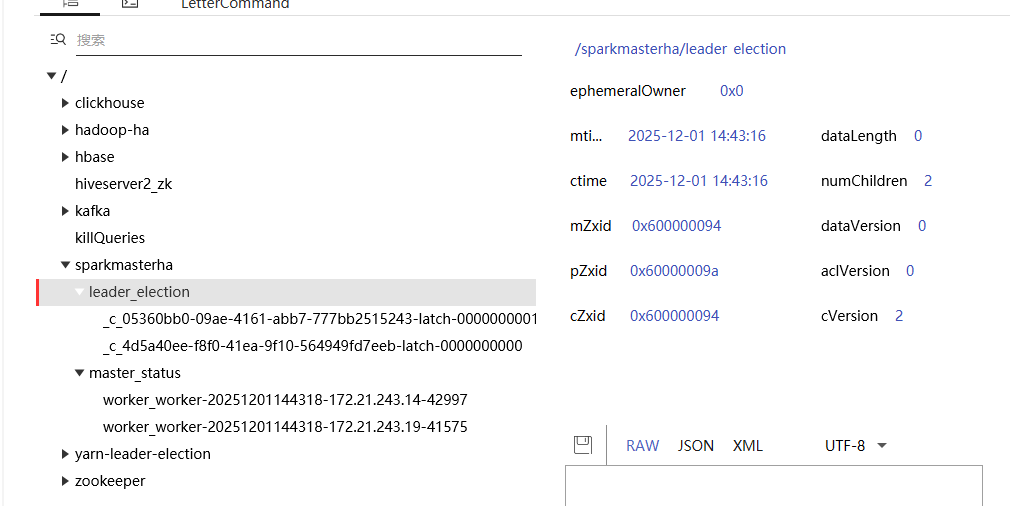
zookeeper WebUI:
1.3.2 提交任务测试
提交任务命令
spark-submit --master spark://hadoop106:30277,hadoop101:30277 --deploy-mode cluster --conf spark.task.maxFailures=3 --class org.apache.spark.examples.SparkPi /opt/module/spark-3.5.5/examples/jars/spark-examples_2.13-3.5.5.jar 20000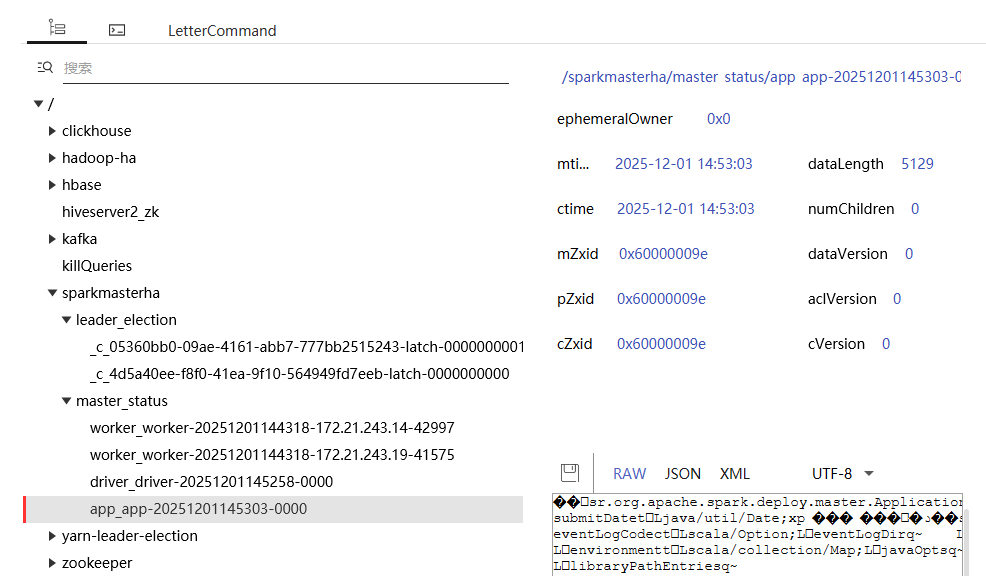
hadoop106节点上,能够获取到提交的任务
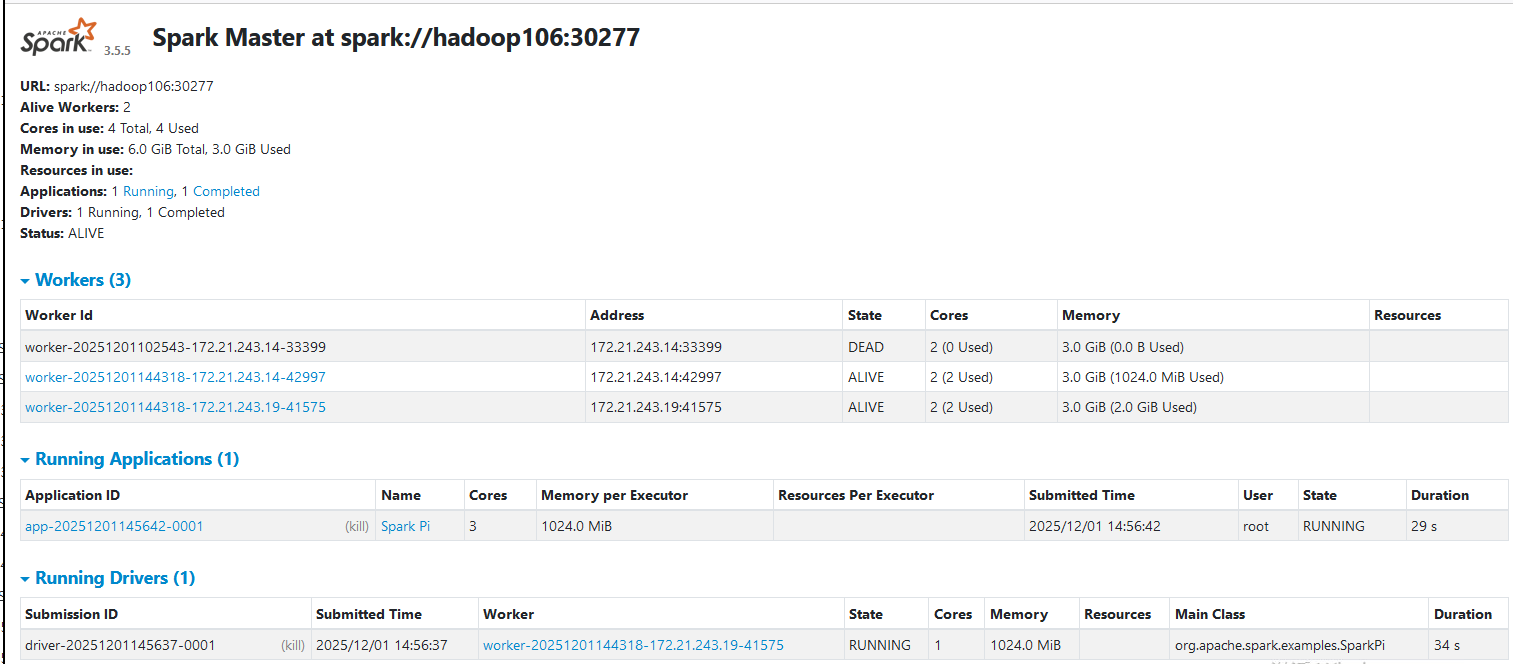
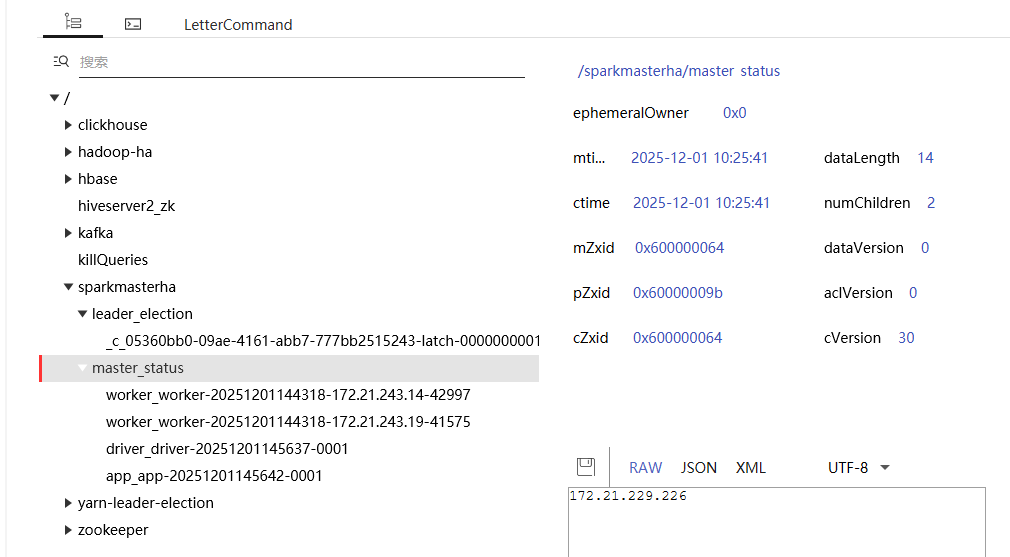
kill 掉 hadoop106节点上的master。zookeeper的node删除
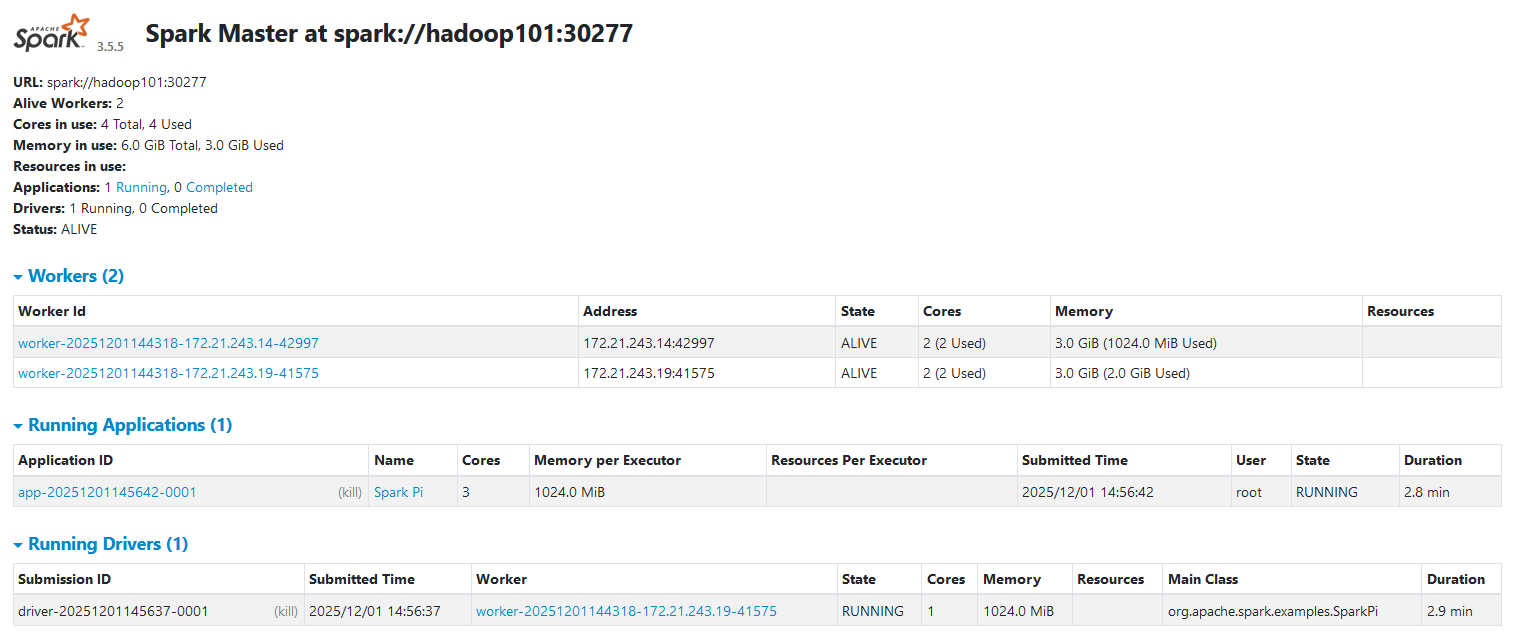
任务由hadoop101接管并执行完毕
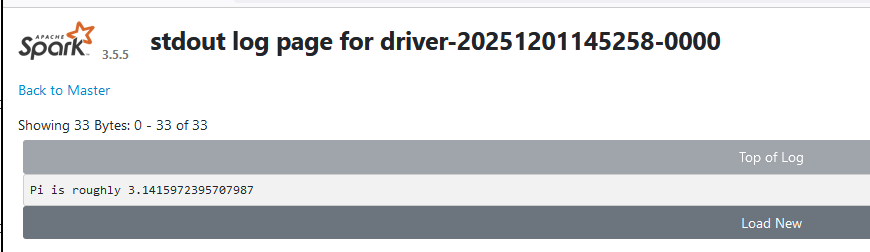
2. spark任务重提测试
2.1 standalone模式
2.2.1 CoarseGrainedExecutorBackend进程挂掉
master会把这个任务重启
[root@hadoop103 ~]# jps
19024 Worker
23380 QuorumPeerMain
19770 CoarseGrainedExecutorBackend
[root@hadoop103 ~]# kill -9 19770
[root@hadoop103 ~]# jps
19024 Worker
23380 QuorumPeerMain
19882 CoarseGrainedExecutorBackend2.2.2 DriverWrapper进程挂掉
任务失败
[root@hadoop102 conf]# jps
9938 CoarseGrainedExecutorBackend
30837 QuorumPeerMain
9862 DriverWrapper
8968 Worker
[root@hadoop102 conf]# kill -9 9862
[root@hadoop102 conf]# jps
30837 QuorumPeerMain
8968 Worker
31049 DFSZKFailoverController
改变提交参数
spark-submit --master spark://hadoop106:30277,hadoop101:30277 --deploy-mode cluster --supervise --class org.apache.spark.examples.SparkPi /opt/module/spark-3.5.5/examples/jars/spark-examples_2.13-3.5.5.jar 20000任务失败后,master会一直重新提交任务,直到运行成功
[root@hadoop102 conf]# jps
30837 QuorumPeerMain
10599 CoarseGrainedExecutorBackend
8968 Worker
10523 DriverWrapper
[root@hadoop102 conf]# kill -9 10523
[root@hadoop102 conf]# jps
30837 QuorumPeerMain
8968 Worker
10697 DriverWrapper
[root@hadoop102 conf]# kill -9 10697
[root@hadoop102 conf]# jps
30837 QuorumPeerMain
8968 Worker
10856 DriverWrapper
2.2 spark on yarn模式
2.2.1 YarnCoarseGrainedExecutorBackend进程挂掉
[root@hadoop103 ~]# jps
21488 YarnCoarseGrainedExecutorBackend
23918 NodeManager
[root@hadoop103 ~]# kill -9 21488
[root@hadoop103 ~]# jps
23918 NodeManager
[root@hadoop105 ~]# jps
19408 NodeManager
6594 ApplicationMaster
6441 SparkSubmit
6698 YarnCoarseGrainedExecutorBackend
[root@hadoop105 ~]# jps
19408 NodeManager
6594 ApplicationMaster
6441 SparkSubmit
6698 YarnCoarseGrainedExecutorBackend
6813 YarnCoarseGrainedExecutorBackend
[root@hadoop105 ~]# kill -9 6813
[root@hadoop105 ~]# jps
19408 NodeManager
6594 ApplicationMaster
6441 SparkSubmit
6698 YarnCoarseGrainedExecutorBackend
[root@hadoop104 ~]# jps
14939 NodeManager
[root@hadoop104 ~]# jps
14939 NodeManager
25085 YarnCoarseGrainedExecutorBackendAM进程会找一台合适的nodemanager重新启动进程

2.2.2 ApplicationMaster进程挂掉
[root@hadoop103 ~]# jps
22265 YarnCoarseGrainedExecutorBackend
23918 NodeManager
22174 ApplicationMaster
[root@hadoop103 ~]# kill -9 22174
[root@hadoop103 ~]# jps
23918 NodeManager
22383 ApplicationMasteryarn会重启一次AM进程
root; groups with modify permissions: EMPTY
25/12/01 16:18:34 INFO Client: Submitting application application_1764227554448_0009 to ResourceManager
25/12/01 16:18:34 INFO YarnClientImpl: Submitted application application_1764227554448_0009
25/12/01 16:18:35 INFO Client: Application report for application_1764227554448_0009 (state: ACCEPTED)
25/12/01 16:18:35 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1764577114256
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0009/
user: root
25/12/01 16:18:45 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:18:45 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop103
ApplicationMaster RPC port: 44489
queue: default
start time: 1764577114256
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0009/
user: root
25/12/01 16:19:10 INFO Client: Application report for application_1764227554448_0009 (state: ACCEPTED)
25/12/01 16:19:10 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1764577114256
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0009/
user: root
25/12/01 16:19:16 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:19:16 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop103
ApplicationMaster RPC port: 41209
queue: default
start time: 1764577114256
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0009/
user: root
25/12/01 16:19:46 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:20:16 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:20:46 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:21:16 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:21:46 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:22:17 INFO Client: Application report for application_1764227554448_0009 (state: RUNNING)
25/12/01 16:22:24 INFO Client: Application report for application_1764227554448_0009 (state: FINISHED)
25/12/01 16:22:24 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop103
ApplicationMaster RPC port: 41209
queue: default
start time: 1764577114256
final status: SUCCEEDED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0009/
user: root
25/12/01 16:22:24 INFO ShutdownHookManager: Shutdown hook called
25/12/01 16:22:24 INFO ShutdownHookManager: Deleting directory /tmp/spark-64fa15fc-483a-4708-ac5e-4c9d6b17757e
25/12/01 16:22:24 INFO ShutdownHookManager: Deleting directory /tmp/spark-0e326f3d-314b-4eb2-ba7f-110daaf9ba9ekill 两次AM 进程,任务执行失败。
root; groups with modify permissions: EMPTY
25/12/01 16:26:37 INFO Client: Submitting application application_1764227554448_0010 to ResourceManager
25/12/01 16:26:37 INFO YarnClientImpl: Submitted application application_1764227554448_0010
25/12/01 16:26:38 INFO Client: Application report for application_1764227554448_0010 (state: ACCEPTED)
25/12/01 16:26:38 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1764577597406
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0010/
user: root
25/12/01 16:26:50 INFO Client: Application report for application_1764227554448_0010 (state: RUNNING)
25/12/01 16:26:50 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop104
ApplicationMaster RPC port: 43071
queue: default
start time: 1764577597406
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0010/
user: root
25/12/01 16:27:03 INFO Client: Application report for application_1764227554448_0010 (state: ACCEPTED)
25/12/01 16:27:03 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1764577597406
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0010/
user: root
25/12/01 16:27:09 INFO Client: Application report for application_1764227554448_0010 (state: RUNNING)
25/12/01 16:27:09 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop103
ApplicationMaster RPC port: 40025
queue: default
start time: 1764577597406
final status: UNDEFINED
tracking URL: http://hadoop101:8088/proxy/application_1764227554448_0010/
user: root
25/12/01 16:27:17 INFO Client: Application report for application_1764227554448_0010 (state: FAILED)
25/12/01 16:27:17 INFO Client:
client token: N/A
diagnostics: Application application_1764227554448_0010 failed 2 times due to AM Container for appattempt_1764227554448_0010_000002 exited with exitCode: 137
Failing this attempt.Diagnostics: [2025-12-01 16:27:16.923]Container killed on request. Exit code is 137
[2025-12-01 16:27:16.925]Container exited with a non-zero exit code 137.
[2025-12-01 16:27:16.925]Killed by external signal
For more detailed output, check the application tracking page: http://hadoop101:8088/cluster/app/application_1764227554448_0010 Then click on links to logs of each attempt.
. Failing the application.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1764577597406
final status: FAILED
tracking URL: http://hadoop101:8088/cluster/app/application_1764227554448_0010
user: root
25/12/01 16:27:17 INFO Client: Deleted staging directory hdfs://mycluster/user/root/.sparkStaging/application_1764227554448_0010
25/12/01 16:27:17 ERROR Client: Application diagnostics message: Application application_1764227554448_0010 failed 2 times due to AM Container for appattempt_1764227554448_0010_000002 exited with exitCode: 137
Failing this attempt.Diagnostics: [2025-12-01 16:27:16.923]Container killed on request. Exit code is 137
[2025-12-01 16:27:16.925]Container exited with a non-zero exit code 137.
[2025-12-01 16:27:16.925]Killed by external signal
For more detailed output, check the application tracking page: http://hadoop101:8088/cluster/app/application_1764227554448_0010 Then click on links to logs of each attempt.
. Failing the application.
Exception in thread "main" org.apache.spark.SparkException: Application application_1764227554448_0010 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1312)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1745)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:1034)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:199)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:222)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:91)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1125)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1134)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
25/12/01 16:27:17 INFO ShutdownHookManager: Shutdown hook called
25/12/01 16:27:17 INFO ShutdownHookManager: Deleting directory /tmp/spark-39839360-c274-42ed-bc1c-9a1ad6112c92
25/12/01 16:27:17 INFO ShutdownHookManager: Deleting directory /tmp/spark-e2efae43-bbe4-409d-92a7-fb7c856281e0因为yarn.resourcemanager.am.max-attempts默认为2,也可由spark.yarn.maxAppAttempts
设置默认值为2,不能超过yarn.resourcemanager.am.max-attempts的值。