写在前面 :
在 AI 训练中,我们最怕遇到两种病:
- 学不会(欠拟合):脑子太笨,简单的规律都看不出来。
- 想太多(过拟合):脑补过度,把噪音当成了规律死记硬背。
这一章,我们不讲复杂的数学,只讲怎么通过**调整数据(特征工程)和约束模型(正则化)**来治好这两块心病。
上一章自测题(最后一题)解答:用一句人话解释三步
- 前向传播 (Forward):拿着当前的参数,把输入数据丢进去,算出一次"我猜的结果"。
- 反向传播 (Backward):发现猜错了以后,沿着计算链条往回追责,算出"每个参数改一点点,会让 Loss 变好还是变坏"(也就是梯度)。
- 更新参数 (Update):按梯度给的方向去拧参数旋钮(学习率决定拧多大),让下一次猜得更准、Loss 更小。
用一个"预测房价"的小例子把这三步串起来(不追公式,只看逻辑):
- 已知一条数据 :面积 x=80x=80x=80 平,真实房价 y=200y=200y=200 万。
- 我们先用一个很粗的模型 :ypred=w×xy_{pred}=w \times xypred=w×x(先不加其它花里胡哨的东西),当前参数先猜 w=2w=2w=2 万/平。
- 前向传播 :把 xxx 丢进去算预测值:ypred=2×80=160y_{pred}=2 \times 80=160ypred=2×80=160 万(这是"我猜的结果")。
- 反向传播 :和真实值一比,发现你猜低了:160160160 万 vs 200200200 万。于是"追责"得到一个结论:想让预测变大,就该把 www 往上调(这就是梯度在告诉你"往哪边改能变好")。
- 更新参数 :比如把 www 从 222 调到 2.52.52.5 万/平。下一次再算:ypred=2.5×80=200y_{pred}=2.5 \times 80=200ypred=2.5×80=200 万,更接近真实值。
- 训练的本质 :对很多很多条数据重复这个过程,让 www 慢慢变成"更靠谱的单价"。
0. 术语小词典(专为小白准备)
为了不让你在后面反复卡住,这里先把本章会频繁出现的词翻译成"人话":
- 特征 (Feature):你拿来做判断的"线索"。比如预测房价:面积、地段、楼层都是特征。
- 参数 (Parameter) :模型脑子里那堆可调的"旋钮"(常见是权重 www)。训练就是不断拧这些旋钮。
- 损失函数 / Loss:裁判的打分标准。模型猜得越离谱,Loss 越大;越接近答案,Loss 越小。
- 训练集 / 验证集 / 测试集 :
- 训练集:用来"做题练习",让模型学习。
- 验证集:用来"模拟考",帮你判断有没有学歪(是否过拟合),也常用来决定什么时候停。
- 测试集:最后"期末考试",训练过程一般不碰它,用来客观评估模型。
- 泛化 (Generalization):举一反三的能力。训练集很好不算本事,没见过的新数据也能好才算。
1. 核心矛盾:欠拟合 vs 过拟合
在开始治病前,我们先得会"确诊"。
1.1 欠拟合 (Underfitting) ------ "书呆子"
- 症状:考试不及格,平时作业也不及格。
- 原因:模型太简单了(比如用一条直线去拟合曲线),或者特征太少了(只知道身高就想预测体重)。
- 口语:"这题太难了,我看不懂。"
1.2 过拟合 (Overfitting) ------ "杠精"
- 症状:平时作业 100 分,一到考试就不及格。
- 原因 :模型太复杂了,它把训练数据里的噪音也当成了规律。
- 例子 :
- 机器看了一万张猫的照片。
- 其中有一张猫的照片背景里有个绿色的水杯。
- 机器记住了:"只要有绿色水杯的,就是猫!"
- 结果:给你一张绿色水杯的照片,它说是猫。给你一张换了背景的猫,它说不是。
- 口语:"我不管,书上就是这么写的!"
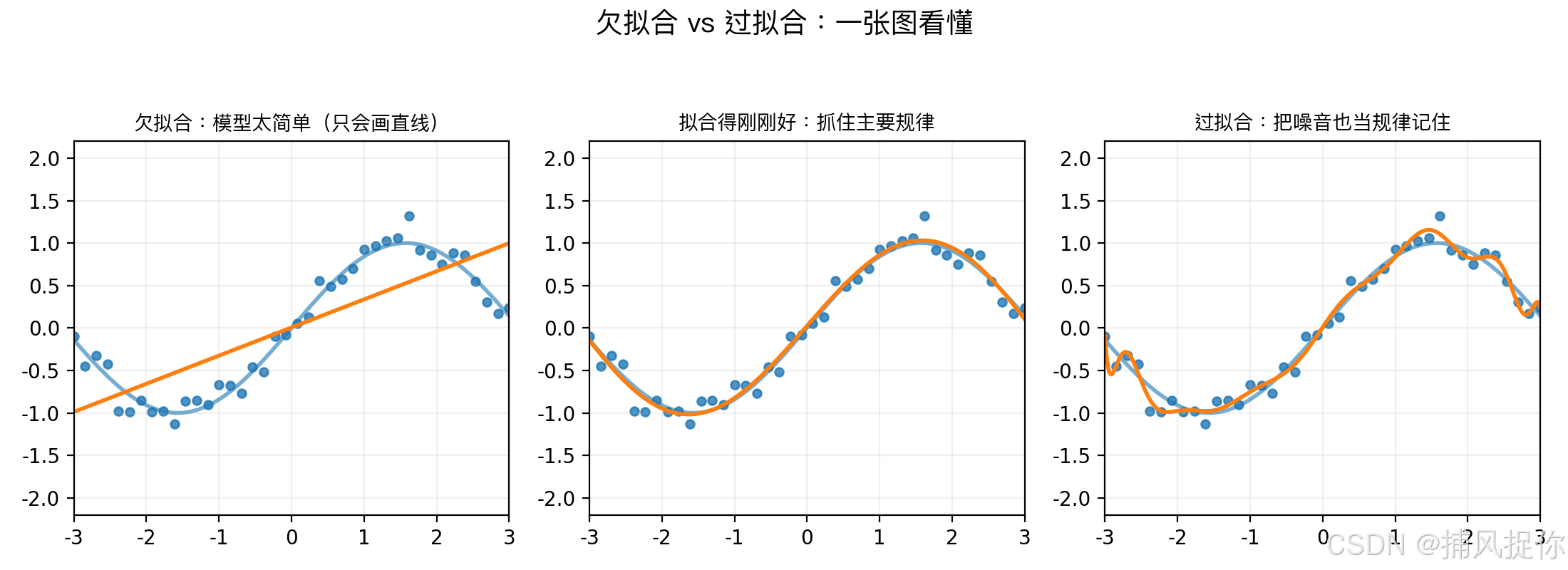
- 左:模型太简单,只能抓到很粗的趋势(欠拟合)
- 中:抓住主要规律,不被噪音带跑(刚刚好)
- 右:把噪音也当规律背下来(过拟合)
2. 治疗"学不会":升维打击 (Polynomial Features)
如果模型欠拟合(分不开红豆和绿豆),通常是因为线索不够 或者维度太低。
2.1 什么是升维?
有时候,在二维平面上怎么也分不开的数据,到了三维空间就很容易分开。
- 场景:桌子上混放着红豆和绿豆,画一条直线分不开。
- 升维:你猛拍一下桌子,豆子都跳到了空中(变成三维)。
- 结果:你发现红豆跳得高,绿豆跳得低。拿一块板子横着一插,就分开了!
2.2 怎么做?
给数据加点"魔法":
- 原始特征 :x1x_1x1 (身高), x2x_2x2 (体重)
- 增加特征 :x12x_1^2x12 (身高的平方), x1×x2x_1 \times x_2x1×x2 (身高乘以体重)
- 原理 :通过引入非线性的特征,让本来只能画直线的模型,突然学会了画曲线(抛物线)。
3. 治疗"想太多":三大疗法
过拟合是 AI 届的癌症。为了防止模型死记硬背,我们有三套组合拳。
疗法一:减负 (降维 / PCA)
逻辑:线索太多反而会干扰判断。把没用的线索扔掉。
- 场景 :预测房价。
- 特征 A:房屋面积(平方米)
- 特征 B:房屋面积(平方尺) -> 完全重复,删!
- 特征 C:房东早餐吃了什么 -> 完全噪音,删!
- PCA (主成分分析) :
- 它不是简单地删除,而是把 1000 个特征"挤压"成 10 个最有代表性的超级特征。
- 比喻:把三维的茶壶拍成一张二维照片。虽然降了一维,但保留了绝大部分信息。
疗法二:适可而止 (Early Stopping)
逻辑:别学太久,学傻了。
- 过程 :
- 第 1 周:课本习题 60 分,模拟考 50 分。 -> 继续学。
- 第 5 周:课本习题 90 分,模拟考 85 分。 -> 状态最好!
- 第 10 周:课本习题 100 分,模拟考 60 分。 -> 学傻了!
- 操作 :在第 5 周模拟考成绩开始下降的那一刻,强制停止训练,保存那时的模型。
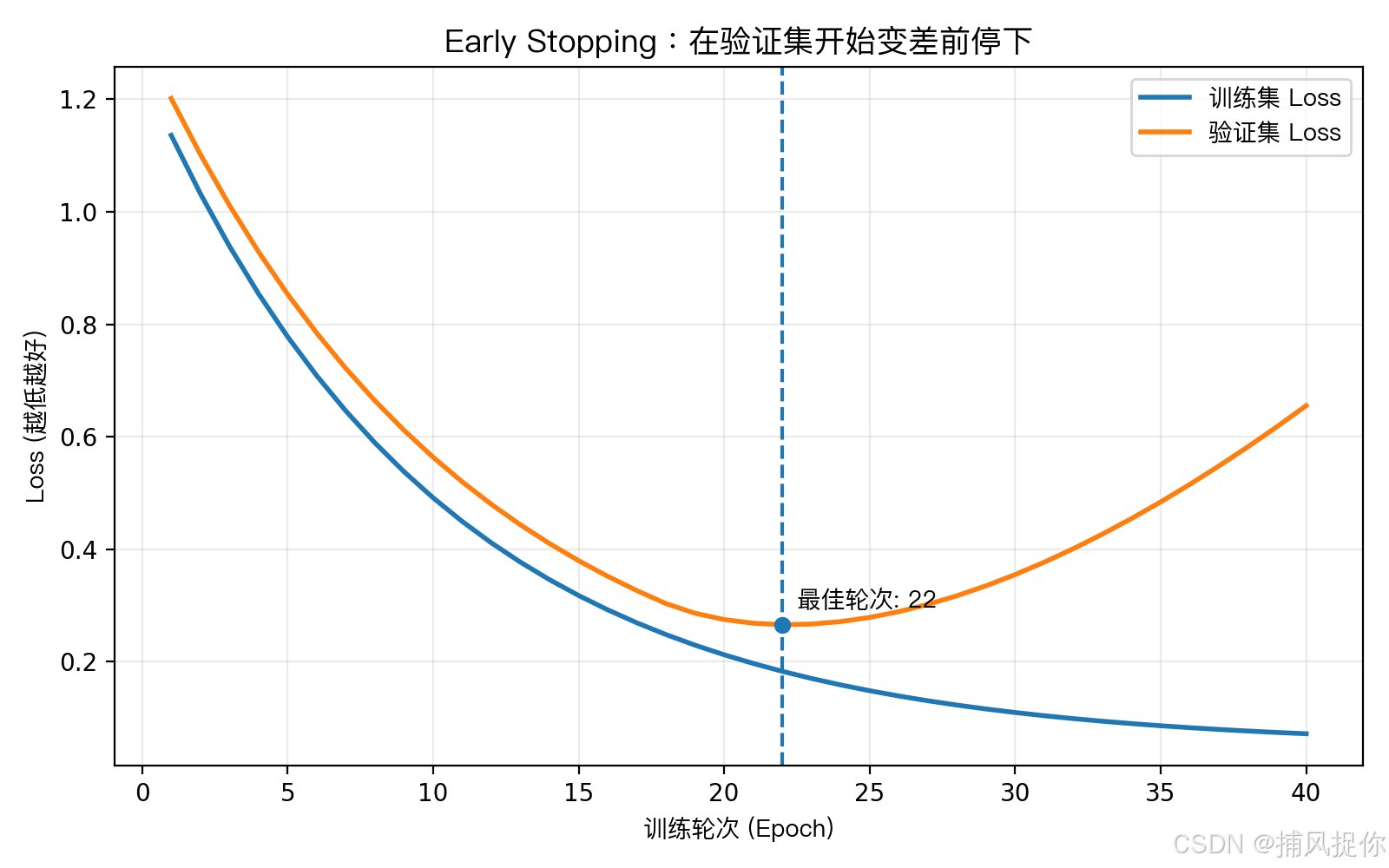
- 训练集 Loss 往往会一直下降,因为模型越来越会"背题"
- 验证集 Loss 先降后升时,通常意味着开始过拟合
- Early Stopping 就是在验证集最好的那一轮停下来并保存模型
疗法三:严加管教 (惩罚项 / 正则化)
逻辑 :给模型戴上"紧箍咒",不准它把参数 www 搞得太大。
- 直觉 :
- 参数 www 越大,模型越敏感,越容易受噪音影响(过拟合)。
- 参数 www 越小,模型越迟钝,越平滑(稳健)。
- L1 正则化 (Lasso) :
- 效果 :让很多参数直接变成 0。
- 作用:自动帮你把没用的特征删掉(特征筛选)。
- L2 正则化 (Ridge) :
- 效果 :让参数变得很小,但不会是 0。
- 作用:让模型变得"中庸"、"稳重",不会因为一点点噪音就跳脚。
用一个很具体的例子把它们说清楚:
- 任务:预测房价。
- 你给模型的线索(特征) :面积 x1x_1x1、地铁距离 x2x_2x2、小区门口是否有"网红咖啡店" x3x_3x3。
- 模型学出来的旋钮(参数) :w1,w2,w3w_1,w_2,w_3w1,w2,w3,分别表示"每个线索有多重要"。
- 如果不加管教 :模型可能会把一些"偶然碰巧"的线索当真理,比如在训练数据里,恰好"有网红咖啡店"的小区都更贵,于是它把 w3w_3w3 拧得很大,这就容易过拟合。
- L1(Lasso)在干嘛 :它会对"每个旋钮的存在本身"都收费。结果就是:很多没那么关键的旋钮会被直接拧到 0,相当于模型自己说"这个线索我不用了"。所以它看起来像在自动删特征。
- L2(Ridge)在干嘛 :它不会逼你把旋钮关掉,而是对"大旋钮"收更重的费。结果就是:所有旋钮都会被压小一些,尤其是特别夸张的那个会被压得更狠,但一般不会刚好变成 0。所以它更像"整体降火",让模型别那么敏感。
4. 总结:AI 医生的处方单
| 病症 | 症状 | 处方 (解决方案) | 原理 |
|---|---|---|---|
| 欠拟合 (Underfitting) | 啥都学不会,Loss 降不下去 | 1. 升维 (加特征) 2. 换更复杂的模型 (深度学习) | 给模型更多线索,增加脑容量。 |
| 过拟合 (Overfitting) | 训练集满分,测试集零分 | 1. 降维 (PCA) 2. Early Stopping 3. 正则化 (L1/L2) 4. 加数据 (最根本的) | 减少噪音干扰,限制模型死记硬背。 |
5. 🧠 脑洞时间:课后思考
练习题:招聘的艺术
假设你要招聘一个员工(训练一个模型)。
- 候选人 A:能力 95 分,但要求配备 10 个助理,办公室要 200 平米。(模型复杂,参数巨大)
- 候选人 B:能力 90 分,但只需要一台电脑,给个工位就能干。(模型简单,参数小)
正则化 (Regularization) 就是老板心中的那杆秤:
- 我们不仅看能力(Loss),还要看成本(参数复杂度)。
- 总分=能力分−λ×成本总分 = 能力分 - \lambda \times 成本总分=能力分−λ×成本
- 通常情况下,我们会优先选 B ,因为他性价比高,而且不容易出幺蛾子(泛化能力强)。
👋 互动时间
觉得这次的"治病"比喻怎么样?
- 点赞:终于分清欠拟合和过拟合了!
- 评论:你在实际工作中遇到过"过拟合"吗?比如测试环境好好的,上线就挂了?欢迎分享你的血泪史!
👉 下一篇预告:归一化
为什么身高 1.8 米和体重 140 斤不能直接加在一起算?
因为单位不一样!
下一篇,我们讲讲怎么把所有数据都拉到同一起跑线上,让模型学得更快。