脉冲神经网络 (SNNs) 因其事件驱动和低功耗特性而备受关注。然而,现有的视觉脉冲Transformer(如Spikformer)在残差连接 结构中存在非脉冲计算(整数-浮点乘法),限制了其在类脑芯片上的部署效率。本文提出 Spikingformer ,通过将膜电位残差 (MS Residual) 连接与自注意力机制结合,消除了非脉冲计算,实现了完全的尖峰驱动 (Spike-driven) 建模。该模型在ImageNet及NLP等13个数据集上刷新了SNN的性能纪录,成为SNN领域的通用基础骨干网络。
01 论文基本信息

- 标题: Spikingformer: A Key Foundation Model for Spiking Neural Networks
- 核心模块 : 脉冲分词器 (Spiking Tokenizer) 、预激活脉冲自注意力 (PSSA) 、脉冲多层感知机 (SMLP) 、膜电位残差 (MS Residual)。
02 算法框架与核心模块
2.1 算法框架
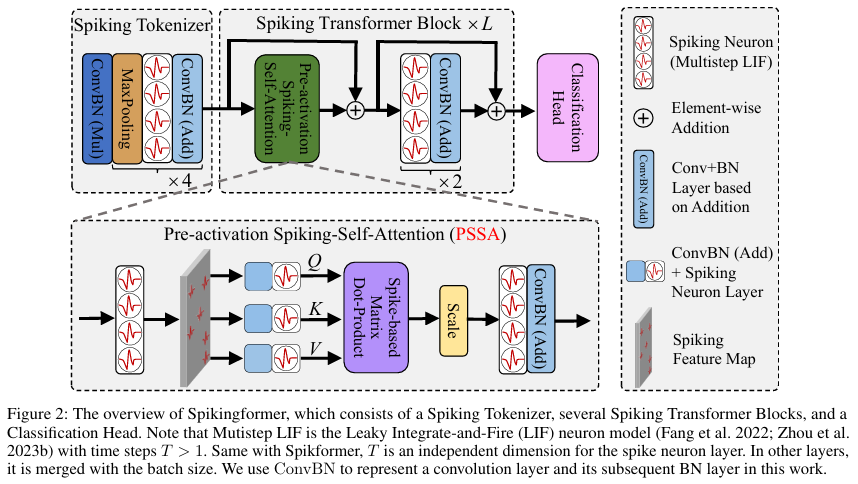
Spikingformer 采用类 ViT 架构,由脉冲分词器、多层脉冲Transformer块及分类头组成。输入图像经分词器降采样并编码为脉冲序列,进入特征提取层,最后通过全局平均池化完成分类任务。
2.2 核心模块
模块一:膜电位残差 (MS Residual)
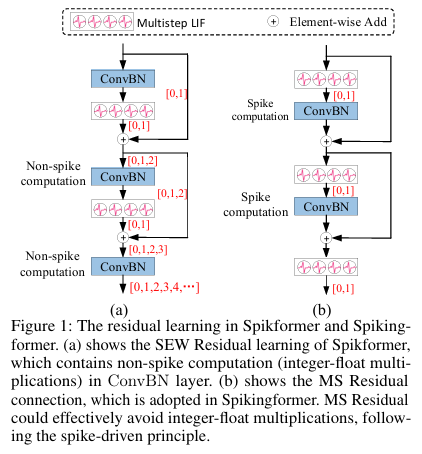
- 核心功能: 解决传统 SEW 残差结构产生的非脉冲计算问题,确保全网符合尖峰驱动原则。
- 实现逻辑 : 相比于 SEW 残差(图 1a),MS 残差(图 1b)在脉冲神经元(SN)之后进行加法运算,其数学表达为:
Ol=ConvBNl(SNl(Ol−1))+Ol−1O_l = \text{ConvBN}l(\text{SN}l(O{l-1})) + O{l-1}Ol=ConvBNl(SNl(Ol−1))+Ol−1
Ol+1=ConvBNl+1(SNl+1(Ol))+OlO_{l+1} = \text{ConvBN}{l+1}(\text{SN}{l+1}(O_l)) + O_lOl+1=ConvBNl+1(SNl+1(Ol))+Ol - 优势 : 输出 OlO_lOl 在进入下一层卷积前必先经过脉冲神经元(SN),确保了卷积层的输入始终为二值化脉冲(0或1),从而将计算简化为纯加法(AC),大幅降低能耗。
模块二:预激活脉冲自注意力 (PSSA)
- 核心功能: 在保持全局建模能力的同时,实现完全的尖峰驱动矩阵乘法。
- 实现逻辑 : 修改了脉冲神经元的位置以适应 MS 残差,并使用卷积层替代线性层以增强泛化。其注意力机制表达为:
Attention(Q,K,V)=ConvBN(SN(QKTV×s))\text{Attention}(Q, K, V) = \text{ConvBN}(\text{SN}(QK^T V \times s))Attention(Q,K,V)=ConvBN(SN(QKTV×s))
其中 Q,K,VQ, K, VQ,K,V 均为纯脉冲数据,计算过程仅涉及索引加法。 - 优势 : 相比传统自注意力,消除了 Softmax 算子,显著降低了计算复杂度和能耗。
03 模块适用任务
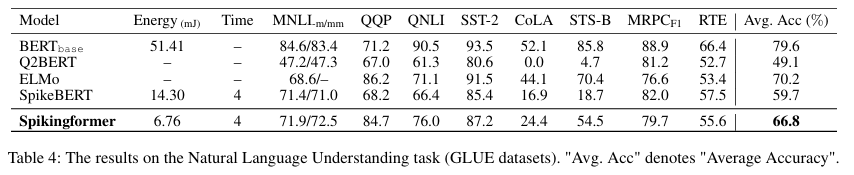
- 核心应用场景 : 适用于静态图像分类 (如 ImageNet)、神经形态视觉数据处理 (如 DVS-Gesture)以及自然语言理解(如 GLUE 任务)。
- 方法论核心: 通过重新设计残差学习路径,使 Transformer 结构与脉冲神经元的动力学特性(LIF模型)在底层数学逻辑上完美对齐。
- 启发性拓展 :
- 可作为高效的基础模型部署于边缘类脑硬件,实现低功耗实时推断。
- 其纯脉冲驱动的架构为构建超大规模能源效率型通用人工智能(General AI)提供了技术路径。
04 实验结果与可视化分析
核心实验与结论
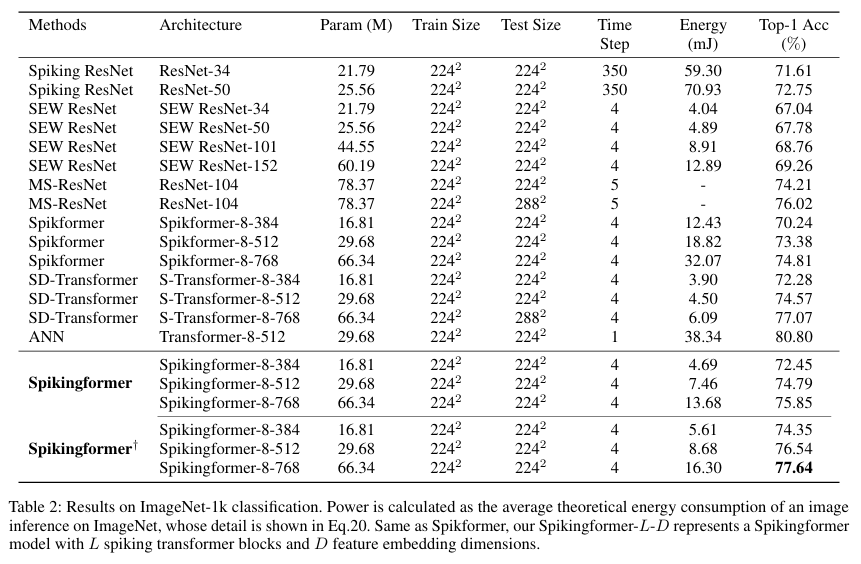
实验:ImageNet-1k 分类性能与能耗分析。
- 实验目的: 验证 Spikingformer 在大规模数据集上的分类精度及其相对于传统 SNN 的能耗优势。
- 关键结果 :
- 精度 : Spikingformer-8-768 在 ImageNet 上达到 75.85% 的 Top-1 准确率,而其改进版 Spikingformer†^\dagger† 更是达到了 77.64%。
- 能耗 : 相比于 Spikformer,Spikingformer-8-512 的理论能耗从 18.82 mJ 降至 7.46 mJ ,降幅达 60.36%。
- 作者结论: Spikingformer 成功解决了 Transformer 结构在 SNN 化过程中的能耗陷阱,实现了性能与效率的双重领先,证明了 MS 残差在深层 SNN 中的优越性。
总结与观点
1. 总结 (Summary)
本文针对现有脉冲 Transformer 中由于 SEW 残差连接导致的非脉冲计算瓶颈,提出了一种名为 Spikingformer 的新型全脉冲架构。通过引入 MS 残差连接,Spikingformer 确保了网络各层之间传递的是纯粹的二值脉冲信号,从而在硬件实现上仅需低功耗的加法器(AC)。该模型在计算机视觉和自然语言处理的多个基准测试中均展现了卓越的性能。
2. 观点 (Perspectives)
- 架构范式转移: Spikingformer 纠正了早期脉冲 Transformer 中"不彻底"的尖峰驱动设计,明确了 MS 残差才是 SNN 深度化和硬件友好化的正确路径。
- 能耗效率的降维打击: 通过将乘加运算(MAC)彻底转变为加法运算(AC),SNN 在保持与 ANN 相当精度的同时,在能效比上具有量级优势。
- 跨模态泛化潜力 : 该模型在 NLP 任务上的成功尝试,打破了 SNN 仅限于视觉领域的固有印象,预示着脉冲驱动的语言大模型的可能性。
- 降采样的关键作用 : 变体 Spikingformer†^\dagger† 引入的 CML 降采样 模块进一步证明了在脉冲空间进行精确梯度回传对提升 Transformer-SNN 性能的重要性。