在本章中,我们将探索应用于图的传统与非传统机器学习方法。随后,我们会在第 2 章奠定的基础之上,深入传统的基于图的机器学习。我们将先讨论图数据表示的细微差别,从通用方法过渡到对亚马逊共购(copurchasing)网络的一个聚焦型案例研究。随着推进,我们会揭示可用该数据集完成的多种任务。
本章的核心在于图特征工程------这是决定机器学习模型性能成败的关键一步。我们将阐明其重要性、面临的挑战,以及可从图中提取的不同类型特征。通过动手实践,你将完成特征提取,并将图派生的度量整合到诸如价格、产品类别等产品属性中。例如,我们将展示这些度量如何增强与客户偏好相关的属性,从而为决策与产品改进提供洞见。
接下来,我们将利用这些图特征来驱动传统机器学习模型。你将了解节点分类、链接预测、图聚类等任务。通过实践示例,我们会演示如何构建与验证预测模型,着重于对高评分产品的预测。
在本章的尾声,你将接触利用节点嵌入的特征学习这一概念。借助随机游走等算法,你将为亚马逊共购数据集生成嵌入,并探究其潜在应用。
在读完本章后,你将全面理解如何在传统机器学习任务中有效使用图特征,以及它们如何在解决复杂问题时提供优势。让我们启程吧!
图机器学习的方法
以深度学习的兴起为参照点,我们可以将图机器学习(GML)的方法分为两个时期:深度学习之前(以传统方法为特征)与深度学习之后(涵盖非传统技术)。
传统的基于图的机器学习
这类算法早于深度学习方法的广泛采用,指的是使用既有算法与技术对图结构数据执行机器学习任务。此类方法通常基于图性质(如节点度、中心性等)手工构造特征。
传统的图算法常采用 PageRank、基于随机游走的方法或图聚类算法来完成诸如节点分类或链接预测等任务。由于依赖人工特征,它们可能在可扩展性上受限,并在特征更新时需要人工干预。不过,这类算法的一大优势是可解释性强。因为依赖预定义的特征与规则,其内部机理往往比深度学习等更复杂的方法更易理解。
非传统的基于图的机器学习
这一类图算法指的是利用深度学习的较新方法,包括 GNN、GCN、GAT 以及图嵌入等技术。它们直接在图结构上运行,能够从原始数据中自动学习表示。
这些技术因其能够处理大规模图并在多种任务上达到当前最优的表现而日益流行。然而,一个潜在的缺点是,相较传统方法,它们可能在一定程度上牺牲可解释性。
在本章中,我们将重温传统方法,以理解图任务在过去是如何工程化实现的。非传统方法将贯穿后续各章------从第 4 章开始。首先,让我们通过表 3-1 来比较两类方法的差异;该表从若干维度概述了它们之间的区别。
表 3-1 传统与非传统图机器学习方法在三个维度上的比较:表示学习、互操作性与可扩展性
| 图的方面 | 传统的基于图的机器学习 | 非传统的基于图的机器学习 |
|---|---|---|
| 表示学习 | 依赖手工构造的特征。 | 直接从图数据中学习表示。 |
| 可解释性 | 在特征与算法层面提供可解释性,便于清晰理解预测是如何产生的。 | 可能为提升性能而牺牲一定可解释性。 |
| 可扩展性 | 在扩展到大型图时可能吃力,因为需要手动干预来手工打造特征。 | 借助深度学习并运行于 GPU/TPU 等计算框架,可利用并行计算架构的优势。 |
为传统机器学习表示图(Representing Graphs for Traditional ML)
让我们从如何为传统机器学习表示图开始这段旅程!处理图数据的关键,在于把它们表示成传统机器学习(ML)算法能够消化的形式 。本节我们将深入探讨图表示,不止停留在理论层面------还会动手实践一个来自亚马逊的热门数据集(亚马逊共购网络)。我们将演示如何从该数据集中提取图表示;读完之后,你将扎实掌握如何表示图,并为后续的上手机例做好准备。
图表示(Graph Representation)
在第 1 章中,我们探讨了图数据表示这一概念:即将数据编码或映射为图结构,其中**节点(nodes)**表示实体,**边(edges)**表示实体之间的关系。这种表示在处理充满复杂关系的数据时尤为有用,例如分子结构、社交网络,甚至是道路网络。
精彩之处在于:当你把数据组织成图表示后,就可以应用图算法 进行分析、发掘隐藏洞见,并最终在其之上进行预测。关键是要在用于图机器学习(GML)之前,正确而充分地刻画数据。
在图表示方面,常见的数据结构有多种,各有优劣。下面回顾两种最常用的表示:邻接表(adjacency list)与邻接矩阵(adjacency matrix) 。
邻接表 与邻接矩阵 是表示图的两种常用数据结构。为说明这两种技术,我们将参考图 3-1,其中给出了一个示例图,并演示如何从中推导出相应的表示。
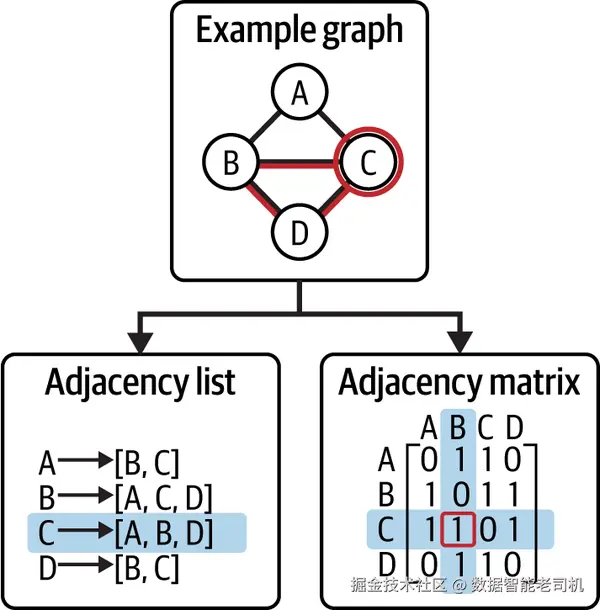
用于表示图的两种常见数据结构如下:
邻接表(Adjacency list)
这是一种由"若干个列表"组成的图表示方法。图中的每个节点对应一个列表,列表中包含与该节点直接由边相连 的相邻节点的引用或标识。邻接表适合表示稀疏图 (边的数量远小于节点数),也适合无法完全装入内存的超大图。在此情况下,可以将邻接表存储在磁盘上,按需访问。
邻接矩阵(Adjacency matrix)
以一个二维矩阵来表示图。矩阵的维度为 n × n ,其中 n 为图的节点数。矩阵中第 (i, j) 个条目表示第 i 个节点与第 j 个节点之间是否存在一条边:若存在,则 (i, j) 置为 1;若不存在,则置为 0。邻接矩阵常被采用的原因在于可对其执行快速的矩阵运算 。但当图很稀疏时效率不佳,因为矩阵中的大量条目都将是 0。
将亚马逊共购网络表示为图
要有效发挥图表示的威力,首先必须明确数据集中关键的节点、边及其属性 。通过有条理地组织这些信息,才能为更深入的洞察与更丰富的理解铺平道路。本节将以 Amazon 共购数据集 为载体,演示这一建图过程。我们选择该数据集,是因为它在图特征方面信息丰富且易于解释 ,便于从图结构中提取有价值的洞见,并切合一个常见场景:预测客户行为与购物偏好。
Amazon 共购网络数据集^1 依据客户的购买模式,刻画产品之间的关系。数据集中每个产品都可表示为一个节点 ,两件产品之间的共购行为 可表示为它们对应节点之间的一条边。这自然适合图表示:产品为节点,共购关系为边。
这是一个广受使用的数据集,因为产品并非孤立存在,其购买模式揭示出的复杂关系最适合用图来表达。需要指出的是,按该数据的说明,此数据集表示的是一个有向图 。基于亚马逊网站的"购买此商品的顾客也同时购买了(Customers Who Bought This Item Also Bought)"功能,数据字典采用这样的假设:如果产品 A 经常与产品 B 被共同购买 ,则在图中包含一条从 A 指向 B 的有向边。不过需要注意,这种解读可能与"共购"在直觉上的理解有所不同------后者通常被视为对称关系 。换言之,"A 与 B 一起被购买"通常等价于"B 与 A 一起被购买"。在这种直觉语境中,可以将关系视为无向 (无箭头)或双向(两端各有一个箭头)。
尽管直觉上常将此类关系视为双向,本书在本章中将遵循数据发布方的说明 ,将其视为单向(有向)关系 。在有向图中,边用箭头表示,以指示节点之间交互的方向与流向。这可以类比为带有单行道的地图:行进方向被明确标注。
接下来看看该数据集的构成。我们在表 3-2 中摘取并呈现了部分统计信息。可见数据集主要围绕产品 展开,并与多种类别 关联,其中 Books 占比最大。
表 3-2 Amazon 共购数据集概览
| 统计项 | 数量 |
|---|---|
| Products(产品) | 548,552 |
| Reviews(评论) | 7,781,990 |
| Products by product group(按产品组划分) | --- |
| └─ Books | 393,561 |
| └─ DVDs | 19,828 |
| └─ Music CDs | 103,144 |
| └─ Videos | 26,132 |
现在把数据集拆解为图的组成部分:节点、边与属性 。一个通用的经验法则是:通常名词^2(实体/参与者)对应节点 ,而动词/动作 对应边 。实体与动作都可以带有额外细节,称为属性。据此,我们可以按功能对数据的各列进行归类:
Amazon 共购的节点及其属性
该数据集主要围绕产品 (本质上是"实体"或"名词")展开,因此可将其视为潜在的关键节点 。在此语境中,每个产品对应一个节点。查看每个产品的元数据,通常包含:标题 、ASIN(Amazon 标准识别号) 、销售排名 、类别 、平均评分 、评论 等。这些描述性信息可作为节点的有用属性,有助于加深我们对数据集的理解与分析。
Amazon 共购的边及其属性
在确定产品为关键节点后,下一步是发现产品两两之间的关系 。细查数据可知,产品之间主要存在一种关系:共购 。当产品 A 与产品 B 常被一起购买时,我们在这两个节点之间建立一条连接 。这条连接即为一条边 ,表示二者之间存在共购关系。边同样可以携带自己的属性,例如共购频次 ,或表示两产品关系强度的权重等。
在明确了图表示的各个组成部分后,看看它们如何整合在一起。图 3-2 给出了由 Amazon 共购数据集生成的图形示意图:从 Patterns of Preaching: A Sermon Sampler 指向 Candlemas: Feast of Flames 的箭头表明,购买前者意味着也会购买后者,反之则不然。

在 Amazon 共购数据集中导航图任务
图为我们提供了一种强大的方式来可视化与分析数据,发掘宝贵洞见与隐藏模式。既然我们已经掌握了如何从数据集中获得图表示,接下来就深入探讨该数据集的动态,并思考在其之上可以执行的各类任务:
推荐系统
图在推荐系统中极具威力。当某位顾客购买了某个产品时,可以在图上遍历以找到与之紧密共购的产品,并将其推荐给顾客。这与亚马逊网站上的"购买此商品的顾客也同时购买(Customers Who Bought This Item Also Bought)"功能类似。
社区发现(Community detection)
可以识别那些经常被一起购买的产品簇/社区。这有助于揭示客户细分或潜在的产品捆绑关系。
中心性分析(Centrality analysis)
通过识别在共购网络中最居中/最关键的产品,企业可以定位对购买决策影响最大的关键库存产品。
让我们进入令人兴奋的上手环节:我们将构建一张图 。本章使用 Python 3.8 。你还需要安装 NetworkX (3.2) 、Matplotlib 和 pandas (2.1.1) 等库。
下载数据集后,你会看到单个文件 amazon-meta.txt ,其内容是半结构化 格式。要使用这些数据,我们需要先进行解析。解析脚本会生成三个文件:
- 第一个文件 products.csv 表示节点(产品) ,包含 ASIN、标题、similar(相似商品)、总评论数等产品信息。
- 第二个文件 reviews.csv 表示评论,包含评论日期、客户、评分、投票数等。
- 第三个文件 amzn_directed_graph.csv 表示边。
在后续步骤中,你将使用上述所有文件,除了 reviews.csv。下面开始编码步骤:
加载数据(Loading data)
首先,我们将两个 CSV 文件载入为 DataFrame:一个包含产品之间的边/关系 (amzn_directed_graph.csv),另一个包含产品的元数据 (products.csv),分别命名为 edges_df 与 products_df。
数据清洗(Data cleaning)
使用 dropna() 方法删除 products_df 中的缺失行,确保图中不会出现信息不完整的节点。
初始化图(Graph initialization)
接着,使用 NetworkX 创建一个有向图 对象 G,调用 nx.DiGraph()。有向图意味着关系(边)具有方向:即从一个产品(源)指向另一个产品(目标):
ini
import networkx as nx
import pandas as pd
# 载入 CSV 文件
edges_df = pd.read_csv('amzn_directed_graph.csv')
products_df = pd.read_csv('products.csv')
# 数据中删除缺失值
products_df = products_df.dropna()
# 创建一张有向图
G = nx.DiGraph()添加节点(Adding nodes)
图对象 G 已就绪,接下来需要把节点加入图中 。下面的代码遍历 products_df 的每一行,并为每个产品添加一个节点。每个节点会被赋予若干属性,如 ASIN、title、group、salesrank 等。
添加边(Adding edges)
在添加完节点后,根据 edges_df 添加边 。对于该 DataFrame 中的每一行,从 FromNodeID 指向 ToNodeID 添加一条边,用以表示两个节点(即产品)之间的共购关系:
ini
# 从 products DataFrame 添加节点
for idx, row in products_df.iterrows():
G.add_node(row['Id'],
ASIN=row['ASIN'],
title=row['title'],
group=row['group'],
salesrank=row['salesrank'],
similar=row['similar'],
categories=row['categories'],
total_reviews=row['total_reviews'],
avg_rating=row['avg_rating'])
# 从 edges DataFrame 添加边
for idx, row in edges_df.iterrows():
G.add_edge(row['FromNodeId'], row['ToNodeId'])构建好图后,你可以可视化它,以便获取直观洞见并理解产品之间的关系。下面的代码使用 NetworkX 与 Matplotlib 对图的一小部分进行可视化:
ini
import matplotlib.pyplot as plt
# 画布尺寸
fig = plt.figure(figsize=(14, 8))
# 仅绘制图的一小部分子图(前 5 个节点的诱导子图)
H = G.subgraph(list(G.nodes)[:5])
pos = nx.spring_layout(H, iterations=50)
node_colors = plt.cm.Pastel1(range(len(H)))
# 绘制节点与边
nx.draw_networkx_nodes(H, pos, node_size=500, node_color=node_colors,
edgecolors='black', linewidths=0.5)
nx.draw_networkx_edges(H, pos, edge_color='gray', alpha=0.6, width=1.5)
# 调整标签位置(如需垂直偏移可修改 y 偏移量)
label_pos = {node: (x, y+0.) for node, (x, y) in pos.items()}
# 绘制标签(假设你已定义 split_label 用于换行等处理)
labels = {node: split_label(H.nodes[node]['title']) for node in H.nodes()}
nx.draw_networkx_labels(H, label_pos, labels, font_size=10, font_family='Arial',
font_weight='bold')
plt.axis('off')
plt.show()可视化结果见图 3-3。
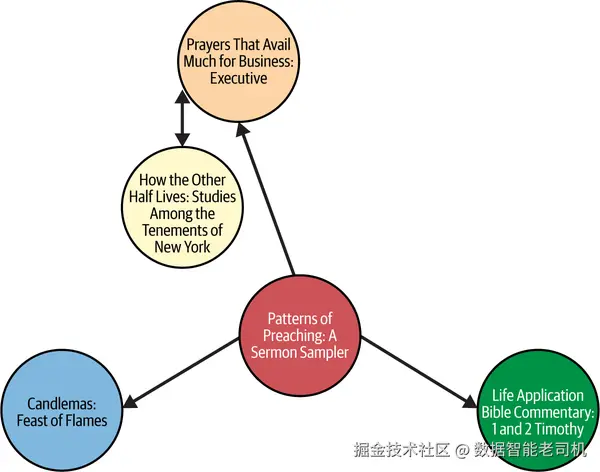
在图 3-3 的可视化中,我们可以基于亚马逊的共购模式看到一些图书之间的关系。每个节点代表一本书,连接线(边)表示顾客常常会同时购买这些书。图中的一个例子是 Prayers That Avail Much For Business: Executive 与 How the Other Half Lives: Studies Among the Tenements of New York 之间的双向连接。这表明许多亚马逊顾客会将这两本书一起购买。
注意
你可以在我们的 GitHub 仓库中获取完整可运行的示例(notebook 3)。
图特征工程(Graph Feature Engineering)
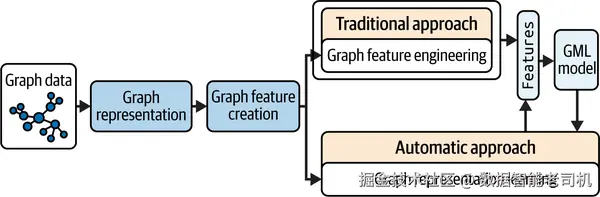
到目前为止,我们已经准备好了图数据,甚至将其表示成了邻接矩阵 。现在可以进入特征阶段 :把这种图表示编码/转换为特征,以便机器学习模型能够消化使用。图 3-4 展示了整个流程以及各部分如何相互衔接。
在图学习中,创建特征有两种思路:
- 传统方式:图特征工程 。在这种方式中,你需要手动决定如何提取特征。例如,你可以预先定义一种方法来提取所有节点特征。
- 更先进的方式:图表示学习(graph representation learning) 。在表示学习中,特征是在模型训练过程中 被学习到的,而不是单独提取。模型会自动学习 有意义的特征,通常是节点/图嵌入 。这些嵌入通常取自神经网络的最后一层 ,并用于下游任务。图表示学习就像是教会模型理解图数据的"本质",从而自行找出有效特征。
本章将带你实践传统的图特征工程 。而在接下来的章节中,我们会更深入地探讨图表示学习,并了解神经网络如何参与其中。准备好了吗?
重要性与挑战(Importance and Challenges)
理解手边可用的特征有多重要,怎么强调都不为过。图特征工程就像把原始数据加工成你的机器学习模型能"消化"的格式。这一步至关重要:精心构造的图特征能让模型捕捉图中复杂的关系,从而带来更准确的预测。
当然,我们也需要正视这一过程所伴随的严峻挑战 ,例如如何确定特征的生成方式并保证其相关性。噪声与离群点 会进一步使过程复杂化,需要谨慎处理。图结构本身可能十分复杂,使得确定"生成哪些特征、如何高效生成并确保其涵盖关键信息"都变得不易。此外,处理超大规模图在计算上也充满挑战:需要大量资源(如大内存与 GPU/TPU 算力)以及高效算法来工程化特征,进一步提升了该步骤的复杂度。
图特征的类型(Types of Graph Features)
理解了这些特征为何重要之后,我们来看它们到底是什么。按所描述的图组件(节点、边、整图),图特征大致分为三类:
- 节点特征(node features) :描述图中节点本身的性质,如社交网络中"人的姓名"。
- 边特征(edge features) :描述节点之间的关系,如两个用户之间连接的强度。
- 图级特征(graph features) :从全局鸟瞰整张图,揭示整体连通性、密度等宏观属性。
节点层面的特征(Node-level features)
在图结构语境中,节点层面的特征是与每个节点关联的独特属性或特性 ,用于概括节点所代表实体的信息。在不同应用中(如社交网络分析或道路网络),节点可代表用户或路口。在 Amazon 共购网络数据集中,产品就是节点。相应特征捕捉这些实体的信息,例如标题、销售排名等。
下面谈谈在图机器学习(GML)中可以为节点挖掘的不同类型特征,并逐一说明其含义:
节点度(Node degree)
最基础的节点级特征,表示与某节点相连的边的数量。在社交网络中,节点度可理解为该节点"紧邻"的朋友/邻居数。在像共购图这样的有向图 中,度可以分为入度(in-degree)与出度(out-degree) ,分别表示指向该节点的边数与由该节点指向外部的边数。
节点中心性(Node centrality)
"中心性"是一个家族概念,涵盖多种刻画网络中单个节点重要性的度量。可以把它们视作帮助我们找出"图中最重要节点"的工具箱。这里我们回顾三种常见的中心性指标:度中心性(degree centrality) 、中介中心性(betweenness centrality)与接近中心性(closeness centrality) 。实际上还有更多指标,如感兴趣可参考 Mark Needham 与 Amy E. Hodler 的 Graph Algorithms。
- 度中心性:依据节点拥有的连接数量衡量其重要性。高度中心性的节点通常被视为图中最具影响力的节点。
- 中介中心性:衡量一个节点在其他节点对之间的最短路径上充当"瓶颈/桥梁"的频繁程度。
- 接近中心性:衡量一个节点到图中所有其他节点的"接近程度"(通常与最短路径距离的倒数有关)。中心性高意味着连接更"快捷",中心性低则意味着更"孤立"。
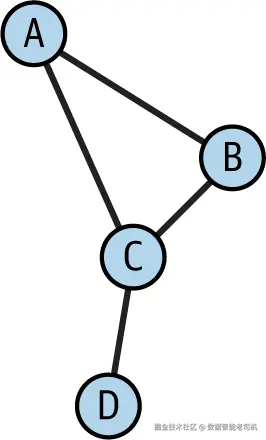
我们将使用图 3-5 来演示这三种中心性的计算。图 3-5 中的图包含四个节点 A、B、C、D,边为:(A, B), (A, C), (B, C), (C, D)。
- 度中心性:A = 2(连有两条边),B = 2,C = 3,D = 1。
- 接近中心性 :节点 C 的接近中心性为 3/6 = 0.5,因为在六对顶点之间的最短路径中((A, B)、(A, D)、(B, D)),它位于其中三条的路径上。
边层面的特征(Edge-level features)
当我们谈到边层面(或关系层面)特征时,指的是连接两个节点的边 所具有的性质或属性。在本文使用的 Amazon 共购数据集语境下,可以利用多种此类特征来预测两件产品是否可能被一起购买。示例特征包括:
边权重(Edge weight)
衡量两个节点之间这条边的强度或重要性 ,通常用数值(权重)表示。在该数据集中,连接两件产品的边的权重可以表示它们共购关系的频率或强度 。权重越高,越表明这两件产品被一起购买的倾向越强------该权重可由销售排名 或共同出现的频次等因素推得。
边类型(Edge type)
一种分类特征 ,指示两个节点之间关系的类型。在该数据集示例中,边类型被标注为 "similar to ",即共购关系,表示由于相似性而常被一起购买的产品。
时间戳(Timestamps)
指示边创建或最近更新 时间的时间型特征 。尽管该数据集中未提供,但若能获取,这类特征有助于跟踪产品交互的时序。例如,时间戳可以揭示两件产品在何时段频繁被共同购买 。这些时间戳也可能从产品评论 中推导,进而反映顾客的购买与评论时间。
边属性(Edge attributes)
指与边相关、且可能与当前机器学习任务有关的其他特征 。在本数据集中,边属性可包括产品分类 、两产品的共购频次 与平均评分 等。产品分类作为边属性能为两件产品之间的关系提供更多上下文------例如,如果两件产品属于同一类别 ,这可能强化 它们的共购关联。此外,从评论中派生的属性(如投票数 )可作为平均评分 的信号,兼顾流行度 与情感倾向。评分更高的产品更可能被共同购买,因此作为边属性能提供有价值的洞见。
图层面的特征(Graph-level features)
所谓图层面特征 ,就是整张图所具有的性质或属性。为便于理解,来看一个金融科技(fintech)应用 的假设场景:我们有一张代表银行客户之间资金交易 的图。若要为一个预测客户违约概率 的机器学习模型构造特征,就可以考虑如下图级特征:
图密度(Graph density)
衡量图中实际边数 相对于可能边数 的比例。密图 边多,稀疏图 边少。在该交易网络的示例中,高密度 可能意味着高水平的金融活动 以及更高的违约风险,因为客户之间潜在的连接与交互更多。
图直径(Graph diameter)
图中任意两点之间所有最短路径 的长度里,最大的那一个 。直径大的图,其节点更分散/不连通 ;直径小的图,其节点更紧密相连 。在交易网络中,直径大可能意味着部分客户更为孤立、连接更少,这可能是违约的风险因子。
图平均度(Graph average degree)
图中每个节点的边数 的平均值 。平均度越高,节点间总体连接越紧密。在交易网络中,较高的平均度可能表明客户联系广泛、支持网络更强 ,这在一定程度上可能对违约起保护作用。
图聚类系数(Graph clustering coefficient)
衡量图中节点倾向于聚集成小团体 的程度。聚类系数高意味着紧密小群体 很多;聚类系数低则意味着小群体较少、节点更分散。回到交易网络示例,若聚类系数高,可能存在彼此支持的紧密客户群 ;这种团结也可能有助于防范欺诈。
让我们稍作回顾,然后在 Amazon 共购数据集 上尝试应用这些特征。
上手实践:从 Amazon 共购图中提取特征
我们已经看到,图会编码节点之间的关系,其结构蕴含的丰富信息可以转化为机器学习任务的特征。这些图派生特征 能够补充现有属性、丰富数据表示,并有望提升模型表现。接下来,我们就从示例数据集中动手提取特征。
图特征的派生(Graph feature derivation)
特征可以由多种图度量与性质派生。下面给出两种常用特征及其推导方式:
节点度(Node degree)
在共购数据集中,某个产品的度表示有多少其他产品 经常与它一起被购买。度高意味着该产品常与许多其他产品被共购,暗示其受欢迎度或通用性更高。
节点聚类系数(Node clustering coefficient)
在共购数据集中,某个产品的聚类系数高,意味着购买该产品的顾客也倾向于把与它共购的那些产品彼此一并购买。这可能指向产品捆绑或常被配套使用的商品组合。
回到先前的编码示例。这里我们将利用 NetworkX 提供的特征函数。下面的代码为 Amazon 共购图计算上述两种特征(节点度与聚类系数),并把它们作为属性附加到节点上:
python
import networkx as nx
# 每个节点的度
degree = dict(G.degree())
# 每个节点的聚类系数
clustering_coefficient = nx.clustering(G)
# 将这些作为节点属性写回
nx.set_node_attributes(G, degree, 'degree')
nx.set_node_attributes(G, clustering_coefficient, 'clustering')运行这段代码后,节点会多出"degree"和"clustering"两个属性。我们称其为特征 ,因为它们是结合图语境所归纳出的附加表征 。例如,产品节点的度可以反映该产品在数据集中的受欢迎程度。
利用图派生度量丰富产品属性
在提取了诸如度与聚类系数等图特征之后,就可以用它们来增强现有数据集 。这些特征能提供原始属性中未必显性的额外上下文信息 。将图派生特征与主数据集合并后,我们便能对每个产品做出更丰富 的表示,同时刻画其自身属性 与其在更广泛共购网络中的角色。
下面的代码把原始产品属性与图特征合并:
css
# 将图特征整理为 DataFrame
graph_features_df = pd.DataFrame({
'Id': list(G.nodes),
'degree': list(degree.values()),
'clustering': list(clustering_coefficient.values())
})
# 将其与原始产品特征合并
merged_df = pd.merge(products_df, graph_features_df, on='Id')图特征在机器学习建模中的应用(Graph Features in ML Modeling)
既然我们已经弄清这些图特征是什么,以及如何把它们融入到我们的图数据设置中,接下来就进入更令人兴奋的部分------在机器学习模型中使用这些特征 。但在动手之前,先对处理图数据时涉及的任务与技术 做一番概览。为便于说明,我们将从这些任务中选取一个------节点分类(node classification) ------作为演示示例。
任务与技术概览(Task and Techniques Overview)
与任何机器学习问题一样,图问题也通过特定任务 来加以解决。任务为问题提供形式化定义,并指引我们的处理方式。常见的图任务有多种,这里将简要介绍其中一些。图 3-6 给出了各类任务的可视化示意。你可以把图中的问号 与虚线 理解为"图例":它们是提示我们每个任务旨趣的小线索。比如在节点分类 中,带有问号的那些节点就是我们的模型要去推断的对象------就像解谜一样,要判断它们应被标注为深色 还是浅色。
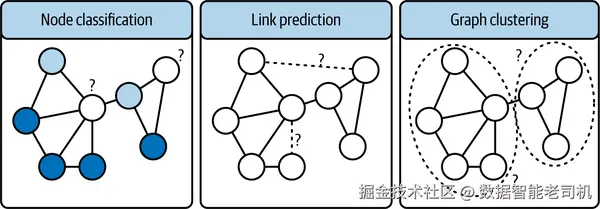
节点分类(Node classification)
节点分类的核心是为图中的节点赋予身份或标签 。我们要根据节点自身的特征,以及其邻居的标签来判断该节点属于哪个类别。此任务的一种常用技术是随机游走(random walk) :该算法在图上"行走/遍历",收集节点及其上下文的信息,然后利用所学来对节点进行分类。
链接预测(Link prediction)
该任务旨在预测图中一对节点之间是否应存在一条边 ,本质上是在判断哪些节点应该被连接。常用技术之一是Jaccard 系数 ,这是一种简单而有效的度量:它通过"交集大小 / 并集大小"来计算两集合的相似度。在链接预测中,可以用它基于两个节点共有邻居 的多少来估计它们之间形成边的可能性。Jaccard 系数越高,通常表示这两个节点之间形成连接的可能性越大。
用于链接预测的其他技术还包括 Adamic--Adar 指数 与邻域计算 等。如需进一步了解,推荐参考 Niyati Aggrawal 与 Adarsh Anand 的著作 Social Networks: Modeling and Analysis 中的链接预测章节。
图聚类(Graph clustering)
图聚类是将节点进行分组,使得同一簇内的节点彼此更相似,而与簇外节点的相似度较低。两种常见技术包括:
- 谱聚类(Spectral clustering) :利用图的特征值来构建聚类。
- 社区发现算法(Community detection algorithms) :顾名思义,这类算法致力于在图中找到紧密连接的节点群体(社区) 。
现在,我们已经通过将原始产品元数据与图派生特征进行整合 来丰富数据集,因此更有利于利用这份更全面的数据来提升机器学习模型的决策能力。
使用预测模型预测高评分产品(Predicting High-Rated Products with a Prediction Model)
通过预测产品可能获得的成功或口碑,企业可以受益匪浅。若能预判某个产品是否有望获得较高的平均评分 ,企业就能在营销策略 与库存管理方面做出更明智的决策。
例如,被预测为高评分的产品可以更积极地进行推广、提高备货量,甚至与其他产品进行捆绑促销。相反,预计评分偏低的产品可进一步进行质量检查与改进,或采用不同的营销方式。
在本节中,我们将使用 scikit-learn(sklearn) 来构建机器学习模型。sklearn 是一个流行的 Python 机器学习库,提供了从线性回归 到复杂集成方法在内的广泛建模与验证工具。
在动手之前,我们先明确本次要解决的问题与所使用的数据。下面概述我们即将开展的机器学习任务,以及输入 与期望输出的清晰定义:
任务定义(Task definition)
我们的任务是节点分类 。本质上,我们尝试预测某个产品是否会获得高评分。
目标定义(Target definition)
也称为输出标签 。目标变量 high_rating 基于列 avg_rating 与阈值定义:若产品的平均评分 大于 4.5,则标注为高评分(1);否则标注为非高评分(0)。
输入特征(Input features)
用于预测的特征同时包含:
- 原始产品元数据:
salesrank、total_reviews - 图派生特征:
degree、betweenness、clustering
数据划分(Data splitting)
采用常规的 ML 流程:数据集按 80%/20% 划分为训练集与测试集,使用 sklearn 的 train_test_split 实现。
模型训练(Model training)
选择 sklearn 的 RandomForestClassifier 。这是一种常用且灵活的集成学习方法:通过训练多棵决策树并集成其输出进行预测,从而更稳健、较不易过拟合。训练仅使用训练集。
下面给出完整代码片段:
ini
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# Define our target variable based on avg_rating
merged_df_cleaned['high_rating'] = merged_df_cleaned['avg_rating'] \
.apply(lambda x: 1 if x > 4.5 else 0)
# Splitting data into training and test set
X = merged_df_cleaned[['degree', 'clustering', 'salesrank', 'total_reviews']]
y = merged_df_cleaned['high_rating']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
# Training a random forest classifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)一旦分类器 clf 训练完成,就在未见过的数据 上评估其表现,以了解其泛化能力,确保模型不是记住了训练数据(过拟合),而是学到了可推广的规律。我们使用测试集进行评估:
scss
# Predictions
y_pred = clf.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(report)输出示例:
markdown
Accuracy: 0.6951206405502713
precision recall f1-score support
0 0.77 0.81 0.79 52619
1 0.48 0.41 0.44 21817
accuracy 0.70 74436
macro avg 0.62 0.61 0.62 74436
weighted avg 0.68 0.70 0.69 74436上述代码片段使用训练好的随机森林在测试集上预测产品评分,并输出准确率 与每个类别的精确率(precision) 、召回率(recall) 、F1 分数等详细指标。
现在,构建不包含图特征的同一模型进行对比:
ini
# Splitting data into training and test set
X = merged_df_cleaned[['salesrank', 'total_reviews']]
y = merged_df_cleaned['high_rating']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
# Training a random forest classifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)对测试集进行预测并输出评估报告:
scss
# Predictions
y_pred = clf.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(report)输出示例:
markdown
Accuracy: 0.6744720296630663
precision recall f1-score support
0 0.77 0.77 0.77 52619
1 0.44 0.43 0.44 21817
accuracy 0.67 74436
macro avg 0.61 0.60 0.60 74436
weighted avg 0.67 0.67 0.67 74436将图派生特征 加入模型后,性能出现了显著提升:准确率由 67.4% 提高到 69.5% ,提升 2.1 个百分点 。这凸显了将图洞见 与传统数据特征相结合的价值,可增强模型的预测能力 。在实践中,融入这类图度量往往是实现更高预测精度的一项战略性举措。
用节点嵌入进行特征学习(Feature Learning with Node Embeddings)
在图论中,**节点(nodes)表示实体,边(edges)表示这些实体之间的关系或交互。正如图像有像素、自然语言文本有词向量作为特征一样,图也需要一种机制,把其结构信息转换为适合机器学习的格式------这正是节点嵌入(node embeddings)**发挥作用的地方。
节点嵌入 是图中节点的向量表示 。这些嵌入捕捉图的拓扑结构、节点的位置以及其邻域信息。其核心思想是:让结构相似 的节点在向量空间中由彼此接近 的向量表示。学得这样的表示后,我们就可以在节点分类、链接预测、推荐等多种机器学习任务中使用这些嵌入。
学习节点嵌入的方法有多种。其中一种流行的方法是 node2vec :它利用**随机游走(random walks)**在图上生成节点序列,类似于自然语言处理中的"句子"。然后将这些序列送入类似 word2vec 的模型来学习嵌入。
注意(NOTE)
向量表示是在多维空间中的数值表示 ,每一维对应于节点的某个属性,这使得我们可以在向量之间进行数学运算和比较。这里要区分学习嵌入(learning embeddings)与提取向量(extracting vectors) :
- 学习嵌入:训练一个模型来生成编码了数据语义信息的向量。
- 提取向量表示:不经过显式学习,直接从数据或图中构造向量,往往基于特定特征或性质(例如,把向量长度定义为某节点可能拥有的最大邻居数;此时每一维可表示一个邻居节点)。
随机游走算法(Random Walk Algorithm)
随机游走 是在图上的一条路径:从某个节点出发,每一步从当前节点随机选择一个邻居并移动到该邻居,如此反复,直到达到指定步数或满足终止条件。
随机游走可按如下方式描述:
- 从一个节点开始。
- 若是无向图 ,随机选择一个相邻节点并移动过去;若是有向图 ,从当前节点可达的出边邻居中随机选择并移动过去。
- 重复第 2 步,直到达到预设步数,或当前节点已没有进一步的出边可走。
请参考图 3-7 所示的示意图。
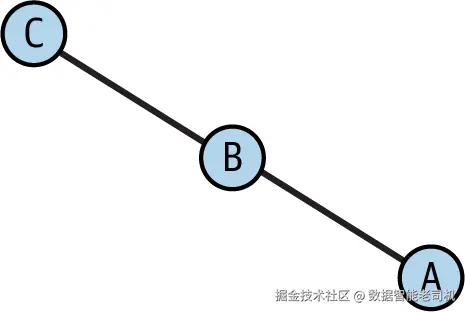
步骤如下:
- 从节点 B 开始。
- 可能的移动:A 或 C(因为它们都是 B 的邻居)。
- 假设我们随机选择移动到 A。
- 从 A 出发,唯一的下一步是回到 B(因为在该图中 A 只有一个邻居)。
- 如果游走长度为 3 ,我们会回到 B 并在此停止。
Amazon 共购数据集与节点嵌入
回到 Amazon 共购数据集,看看节点嵌入为何相关且有益。在此之前,先学习如何生成它们。
Amazon 共购数据集的节点嵌入用例
先铺垫一下如何最大化利用这些节点嵌入。由于这里每个节点代表一个产品 ,我们会为每个产品 创建嵌入------可以把它看作给每个产品分配一个由向量表示的"唯一 ID"。妙处在于,嵌入是向量,因此可以对它们做基本的数学运算,计算它们之间的相似度或差异。
在我们的数据集中,一个起步的应用就是用节点嵌入来捕捉产品相似性 。根据共购模式生成产品的节点嵌入,能捕捉产品之间的隐式相似:经常被共同购买的产品,其嵌入在向量空间中会更接近。这可用于多种场景:
- 推荐系统
给定一个产品,利用嵌入的余弦相似度找到最相似的产品,可作为推荐系统的基础。 - 产品分类
将嵌入作为特征,用于将产品分类或预测其销售排名。 - 异常检测
找到与同类产品嵌入显著不同的产品,可能意味着异常的购买模式。
接下来开始使用 node2vec 库,基于 Amazon 共购数据集生成节点嵌入。
生成节点嵌入
在前面的示例中,我们已经获得了 Amazon 共购数据集的图表示 。这里我们将直接使用 node2vec 生成节点嵌入。虽然本章主要讲传统图机器学习,但引入 node2vec 这一在网络中学习节点表示的通用且广泛采用的技术,能够增强传统方法,更好地刻画数据中的复杂关系结构与模式。
生成节点嵌入的流程如下:
- 使用 node2vec 算法在共购图上生成随机游走序列。
- 在这些游走序列上训练著名的 skip-gram(word2vec 的组成部分)模型,以学习嵌入。
- 训练完成后,每个产品(节点)都会有一个对应的向量(嵌入) ,刻画其在共购图中的上下文。
我们把步骤实现为三个阶段:node2vec 初始化 、模型训练 、特征提取与合并。
步骤 1:node2vec 初始化
先安装并导入 node2vec(使用 !pip install node2vec)。然后用如下参数实例化 node2vec:
- 我们的 Amazon 共购图
G; - 嵌入维度
dimensions(默认 64); - 随机游走参数:单次游走长度
walk_length=30,每个节点执行num_walks=200次游走。
步骤 2:模型训练
调用 fit() 在步骤 1 生成的游走上训练 skip-gram 模型:
- 上下文窗口大小
window=10,即在游走序列中用 10 个邻近节点来预测当前节点; min_count=1表示所有在游走中出现过一次的节点都会被用于训练。
ini
!pip install node2vec
from node2vec import Node2Vec
node2vec = Node2Vec(G, dimensions=64, walk_length=30,
num_walks=200, workers=4)
model = node2vec.fit(window=10, min_count=1)模型训练好后,继续看看如何把这些嵌入关联回节点。
步骤 3:特征提取与合并
创建字典 node2vec_features 来保存节点嵌入。遍历图 G 的节点,从已训练模型中取出对应的向量表示并存入字典,以节点为键:
ini
node2vec_features = {}
for node in G.nodes():
node2vec_features[node] = model.wv[node]为更好地表示产品并捕捉更细腻的关系,可将学到的节点嵌入 与原始产品元数据 (如 salesrank)结合。这样可同时覆盖产品的固有属性 (如销量排名)与其在共购网络中的关系属性。
下面的代码把 node2vec 特征与部分原始元数据合并:
ini
# 将 node2vec 特征字典转为 DataFrame
features_df = pd.DataFrame.from_dict(node2vec_features, orient='index')
# 将 features_df 与 products_df 按索引(Id)连接
features_df = features_df.join(products_df.set_index('Id'), on=features_df.index)
# 只使用 node2vec 向量与原始元数据中的 salesrank
X = list(features_df['node2vec'])
X = pd.DataFrame(X)
X['salesrank'] = features_df['salesrank']为了对产品进行聚类/相似检索 ,可使用如下代码:训练一个 K-近邻(KNN) 模型(此处用作基于相似度的检索工具)于组合特征上,并采用适合高维嵌入的余弦距离来度量产品间相似性:
ini
from sklearn.neighbors import NearestNeighbors
model_knn = NearestNeighbors(metric='cosine', algorithm='brute',
n_neighbors=20, n_jobs=-1)
model_knn.fit(X)训练好的 model_knn 随后可用于做推荐:定义 get_recommendations_with_titles(..) 函数,给定 product_id,找到其在 features_df 中的索引,利用 KNN 检索最相近的产品,并返回它们的 ID 与 标题:
ini
def get_recommendations_with_titles(product_id, k=5):
product_index = features_df.index.get_loc(product_id)
# 使用已训练模型检索相似产品
distances, indices = model_knn.kneighbors(
X.iloc[product_index, :].values.reshape(1, -1),
n_neighbors=k+1
)
# 取出推荐的相似产品 ID(排除自身,故从第 2 个开始)
recommended_ids = features_df.index[indices[0]].tolist()[1:]
# 根据 ID 取标题
recommended_titles = products_df[products_df['Id']
.isin(recommended_ids)]['title'].tolist()
return list(zip(recommended_ids, recommended_titles))
# 生成推荐
product_id_test = features_df.index[10]
recommendations_with_titles = get_recommendations_with_titles(product_id_test)
# 打印结果
print("Given the input product ID:", product_id_test, "titled:",
products_df[products_df['Id'] == product_id_test]['title'].iloc[0])
print("\nThe recommended products based on copurchasing patterns are:")
for id_, title in recommendations_with_titles:
print("- Product ID:", id_, "titled:", title)输出示例:
csharp
Given the input product ID: 5 titled:
"Prayers That Avail Much For Business: Executive"
The recommended products based on co-purchasing patterns are:
- Product ID: 352954 titled: "Entrepreneurship"
- Product ID: 200336 titled: "Executive Temping : A Guide for Professionals"
- Product ID: 42322 titled: "Chaos or Creativity?"
- Product ID: 387069 titled: "A Handbook of Model Letters for the Busy Executive"
- Product ID: 117493 titled:
"Balancing Your Body : A Self-Help Approach to Rolfing Movement"注意(NOTE)
你可以在我们的 GitHub 仓库中获取完整可运行的示例(notebook 3_4)。
总结(Summary)
本章我们梳理了如何为传统机器学习表示图的诸多细节。首先回顾了基础的图表示方式,包括邻接矩阵 与邻接表 。我们以 Amazon 共购数据集 为主要示例,实际演示了建图与图表示的全过程。
在深入图特征工程 时,我们强调了其重要性及所面临的挑战,系统说明了节点级、边级与图级 等多类图特征。通过上手实践,我们从 Amazon 共购图中提取了特征,展示了图派生度量 如何丰富产品属性。随后在图特征的建模 部分,我们介绍了关键任务,如节点分类、链接预测与图聚类 ,并给出了一个预测高评分产品的实战案例,演示了如何结合图特征与传统 ML 技术来构建与验证预测模型。
最后,本章引出了用节点嵌入进行特征学习 的概念,重点强调了 node2vec 所采用的随机游走算法。借助 Amazon 共购数据集,我们展示了节点嵌入的生成与应用,强调了其在提升机器学习模型方面的潜力。
1 本数据集的访问时间为 2023 年 10 月 19 日 。请注意,相关信息可能已发生变化。
2 名词(不含代词)用于指称一类人、地点或事物。此处的名词既可以是指一般事物的普通名词 (如 "a city/一座城市"、"a country/一个国家"),也可以是指特定命名事物的专有名词 (如 "Dublin:某座城市的名称"、"Libya:某个国家的名称")。
3 Bhuvaneswari, A., & Jijina, K. K. (2023). A novel friend recommendation system using link prediction in social networks. 见 N. Hoda 与 A. Naim(编),Social Capital in the Age of Online Networking: Genesis, Manifestations, and Implications(pp. 28--40)。IGI Global。