1.前言
随着 征程 6 芯片家族的阵容不断壮大,算法工具链在量化精度方向的优化也在持续深入,具体体现在两个方面:
- 征程 6P 与 征程 6H 工具链已陆续进入发布和试用阶段,在此背景下,QAT(量化感知训练)需要以更高效的方式适配算子的浮点计算能力,以确保量化精度和用户的使用体验;
- MatMul、Conv、Linear 等 Gemm 类算子目前已正式支持双 int16 输入,这一改进有助于提升相关算子在量化计算时的精度和调优时的效率。
为了更全面、稳妥地支持上述新功能,同时对当前的 qconfig 量化配置以及回退逻辑进行优化升级,工具链从 OE3.5.0 开始支持新版 qconfig 量化模板。新版本针对 qconfig 模板开展了大量的重构工作,重构后的 qconfig 模板不仅能更好地适配新的芯片特性和算子功能,还同时保持对旧版本 qconfig 的维护,保障了用户在升级过程中的平滑过渡,减少了因版本迭代带来的适配成本。
2.新版 qconfig 模板配置流程
本章将系统且全面地为大家呈现新版 qconfig 模板的核心内容,涵盖其关键更新点、规范的基本使用流程以及对相关产出物的详细介绍。
2.1 主要更新点
在更新点方面,新版 qconfig 模板的迭代升级紧密贴合 征程 6 平台家族的持续发展以及工具链不断优化的实际需求,通过针对性的设计与调整,进一步提升了量化配置的效率、灵活性与适配性。其与旧版流程的区别主要体现在以下四个方面:
- 模板与回退机制的统一管理:将模板和回退进行了统一,在同一个流程下管理;
- 强化对特定量化配置的友好性:对浮点计算的量化配置、Conv/Matmul 等 Gemm 算子单/双 int16 输入配置更加友好;
- fuse 默认行为的调整与优化:旧模板默认 conv-bn-add-relu 全部 fuse,然后再根据硬件限制回退至 int8。为了实现更高的计算精度,新模板首先配置 dtype,若不符合要求则不做 fuse,最终 dtype 结果更加符合预期,而且针对不同芯片架构的硬件特性设计了不同的 fuse 行为;
- 新增量化配置文件保存功能: 支持保存量化配置文件
qconfig_dtypes.pt、qconfig_dtypes.pt.py以及qconfig_changelogs.txt。其中,qconfig_dtypes.pt为可供用户加载的算子级别的量化配置文件,实现了配置的便捷迁移与共享;qconfig_dtypes.pt.py``则以 Python 脚本形式保存配置信息,便于用户查看;qconfig_changelogs.txt则记录了配置过程中的算子变更日志,包括量化参数调整记录、模板使用信息等,为配置的追溯、调试提供了清晰的依据,进一步提升了量化配置的可解释性与可复用性。
2.2 基本使用流程
新版 qconfig 模板在使用流程上围绕基础 qconfig 配置 reference_qconfig、templates 量化模板配置展开,各环节紧密关联,共同助力用户实现高效、精准的量化配置。新版 qconfig 模板的基本使用流程如下所示:
Plain
import torch
import torch.nn as nn
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.dtype import qint8,qint16
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization.observer_v2 import MinMaxObserver,MSEObserver,FixedScaleObserver
my_qconfig_setter=QconfigSetter(
#1.基础qconfig,获取默认配置和observer
reference_qconfig=get_qconfig(observer=MSEObserver),
#2.模板,仅关注dype,按照顺序生效,前面模板的配置可被后面的模板覆盖。因此模板的顺序很重要
templates=[
...
],
#3.采用默认的优化模板
enable_optimize=True,
#4.qconfig模板配置文件保存路径
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)以上就是新版 qconfig 模板的基本使用流程,下面将对其核心部分 QconfigSetter 接口和工具链提供的多个 templates 进行介绍。
2.2.1 QconfigSetter 接口介绍
QconfigSetter 接口的定义如下所示:
代码路径:horizon_plugin_pytorch/quantization/qconfig_setter/qconfig_setter.py
Plain
class QconfigSetter(ModernQconfigSetterBase):
"""Manage qconfig settings of a model.
Args:
reference_qconfig: Qconfig to provide observer.
templates: Qconfig templates, will be applyed in order.
enable_optimize: Whether enable the default optimize.
save_dir: Save directory of qconfig settings.
custom_qconfig_mapping: Custom mapping from mod name to qconfig.
CAUTION: This mapping will overwrite the dtype setted by templates.
You'd better not change dtype through this argument, or
the config result will not be optimal (Model may contain
CPU ops on board, for example).
Defaults to None.
enable_attribute_setting: Whether enable the qconfig setted through
qconfig attribute.
enable_propagate: Whether enable propagate for custom_qconfig_mapping
and qconfig attr. Defaults to False.
"""
def __init__(
self,
reference_qconfig: QConfig,
templates: Sequence[TemplateBase],
enable_optimize: bool = True,
save_dir: str = "./qconfig_setting",
custom_qconfig_mapping: Optional[Dict[str, QConfig]] = None,
enable_attribute_setting: bool = False,
enable_propagate: bool = False,
):
super().__init__(reference_qconfig)
self.templates = list(templates)
self.enable_optimize = enable_optimize
self.save_dir = save_dir
if custom_qconfig_mapping is None:
custom_qconfig_mapping = {}
self.custom_qconfig_mapping = {
k: canonicalize_qconfig(v)
for k, v in custom_qconfig_mapping.items()
}
self.enable_attribute_setting = enable_attribute_setting
self.enable_propagate = enable_propagate
if save_dir is not None:
os.makedirs(save_dir, exist_ok=True)-
reference_qconfig【必要配置】:配置 observer,可选项包括 MSEObserver 、MinMaxObserver 等。
-
templates【必要配置】:配置使用到的 qconfig 模板,仅关注 dtype,按照顺序依次生效。
-
enable_optimize【必要配置-用户可不关注】: 是否采用默认的优化 pass,默认配置为 True,相关优化如下:
CanonicalizeTemplate: 按算子类型对 dtype 配置进行合法化,当前默认规则有:- Gemm 类算子输入不支持 float
- 插值类算子:在不同 march 下有不同的限制
- DPP、RPP 等特殊算子仅支持 int8
- 其他算子的通用规则:算子的 input dtype 和 output dtype 不能同时存在 qint 和 float
EqualizeInOutScaleTemplate:对于 relu,concat,stack 算子,应该在算子输出统计 scale,否则精度或性能存在损失。为此:- 将前面算子的 output dtype 配置为 float32
- Relu,concat,stack 算子在 export hbir 时,在 input 处插入伪量化,scale 复用 output scale
FuseConvAddTemplate:硬件支持 conv + add 的 fuse,不同的芯片架构的融合条件不一致,满足融合条件会有以下行为:- 将 conv 的 output dtype 配置为 float32
- 将 add 对应的 input dtype 配置为 float32
GridHighPrecisionTemplate:根据经验,grid sample 的 grid 计算过程用 qint8 精度不够,因此自动将相关算子配置为 qint16 计算。InternalQuantsTemplate:模型分段部署场景下,会在分段点处插入 QuantStub,用于记录此处的 dtype 和 scale,此类 QuantStub 的 dtype 配置必须和输入保持一致。OutputHighPrecisionTemplate:当 Gemm 类算子作为模型输出时,将其配置为高精度输出。PropagateTemplate:对于拆分为子图实现的算子,存在经验性配置,如LayerNorm和Softmax内部小算子应该使用高精度。SimpleIntPassTemplate:性能优化,对于 op0->op1->op2 此类计算图,若以下条件同时成立,则将 op1 输出类型修改为 int:- op2 需要 int 输入
- op0 可以输出 int
- op1 当前输出为 float16,且属于以下类型
- cat, stack
- mul_scalar
- 无精度风险的查表算子(即在 fp16 上默认使用查表实现的算子)
SimplifyTemplate:删除多余的量化节点配置(将对应的 dtype 修改为 None)
进一步的说明可以参考用户手册【Qconfig 详解】。
-
save_dir【必要配置】:量化配置文件保存的路径。
2.2.2 templates 介绍
horizon_plugin_pytorch 中提供了比较齐全的量化配置 templates 供用户使用,下面将逐一对这些模板进行介绍:
- ModuleNameTemplate(必要配置):通过 module name 指定 dtype 配置或量化阈值,包括激活/weight 量化配置,固定 scale 配置;配置粒度支持全局、模型片段和算子等;配置 dtype 包括 qint8、qint16、torch.float16、torch.float32 等,相关配置项可以参考用户手册【Qconfig 详解】;
- MatmulDtypeTemplate(必要配置):通过名称或前缀配置 Matmul 算子单 int16/双 int16 输入,支持批量配置,相关配置项可以参考用户手册【Qconfig 详解】;
- ConvDtypeTemplate(必要配置):通过名称或前缀配置 Conv/Linear 算子单 int16/双 int16 输入,支持批量配置,相关配置项可以参考用户手册【Qconfig 详解】;
- SensitivityTemplate(可选配置):通过量化敏感度列表提升数据类型精度,默认将敏感算子配置为 int16,支持激活敏感和 weight 敏感算子分别配置高精度,相关配置项可以参考用户手册【Qconfig 详解】。
- LoadFromFileTemplate:从
qconfig_dtypes.pt文件中加载量化配置,仅可加载全局及每个算子的量化类型,暂时无法加载 fix_scale 配置,且不支持对 qconfig 进行修改。而且需要注意,此时 enable_optimize 必须配置为 False,否则无法保证配置结果的正确性,部署时可能存在 CPU 算子。
用户配置的模板按顺序生效,前面模板的配置会被后面的模板覆盖。
一般来说,用户会使用到 ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate 和 SensitivityTemplate 这 4 个模板,其中前 3 个模板为必要配置。以下是 templates 的常用配置,如下所示:
Plain
from horizon_plugin_pytorch.quantization.qconfig_setter import *
import torch
#加载精度debug工具产出的敏感度列表
table1=torch.load("xxx_optput1_L1.pt")
table2=torch.load("xxx_optput2_L1.pt")
templates=[
#1. 基础配置部分
ModuleNameTemplate({"":qint8}), #全局feat int8,此时weight 默认为int16
#conv类算子的 input配置为 int8,weight配置为int8
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
#matmul类算子两个输入均配置为 int8
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{"quant":{"dtype":qint8,"threshold":1.0}},#quant int8,固定scale,配置
),
#2. Matmul 单/双int16输入配置
MatmulDtypeTemplate(
input_dtypes=[qint8/qint16,qint8/qint16],
prefix=["head","xxxxx"]#prefix中配置的名称与torch.nn.Module.name_module()返回的一致
),
#3.Conv 单/双int16输入配置
ConvDtypeTemplate(
input_dtype=qint8/qint16,
weight_dtype=qint8/qint16,
prefix= ["backbone","xxxxx"],#prefix中配置的名称与torch.nn.Module.name_module()返回的一致
),
# 4. 敏感度模板配置
#配置top10 weight敏感的算子为int16
SensitivityTemplate(
sensitive_table=table1,#精度debug工具产出的敏感度列表
topk_or_ratio=10, #配置整数的时候是topk,小数的时候是ratio
sensitive_type= 'weight',#只配置weight敏感的算子,还可以选择 'activation'、 'both',默认是both
),
#配置50%激活敏感的算子为int16
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.5, #配置整数的时候是topk,小数的时候是ratio
sensitive_type= 'activation',#配置激活敏感的算子
),
]2.3 产出物介绍
在完成新版 qconfig 模板配置并执行 prepare 操作后,工具链将自动生成并保存 5 个文件,分别为 model_check_result.txt、fx_graph.txt、qconfig_changelogs.txt、qconfig_dtypes.pt.py 及 qconfig_dtypes.pt,各文件功能与技术细节如下:
model_check_result.txt、fx_graph.txt:二者均由prepare接口自动生成,model_check_result.txt中包括未 fuse 的 pattern、每个 op 输出/weight 的 qconfig 配置、异常 qconfig 配置提示等,fx_graph.txt保存的是模型的 fx trace 图;qconfig_dtypes.pt.py和qconfig_dtypes.pt:为QconfigSetter接口输出的量化配置载体,完整记录全局及算子级别的量化精度参数,包括每个算子的 input、weight 和 output 的量化精度,如 qint8、qint16 和 torch.float16 等,其中。py 文件供用户阅读,。pt 文件可以使用LoadFromFileTemplate接口加载,qconfig_dtypes.pt.py中信息如下所示;
Plain
{
#算子级别量化配置
'backbone.conv1.conv1_1.conv': {'input': None, 'weight': 'qint8', 'output': None}, 'backbone.conv1.conv1_1.act': None,
'backbone.conv1.conv1_2.conv': {'input': torch.float32, 'weight': torch.float32, 'output': None},
'backbone.conv1.conv1_2.act': {'input': None, 'weight': None, 'output': 'qint16'}
...
}qconfig_changelogs.txt:每个算子 qconfig 根据 Templates 的变化逻辑,页面如下所示:
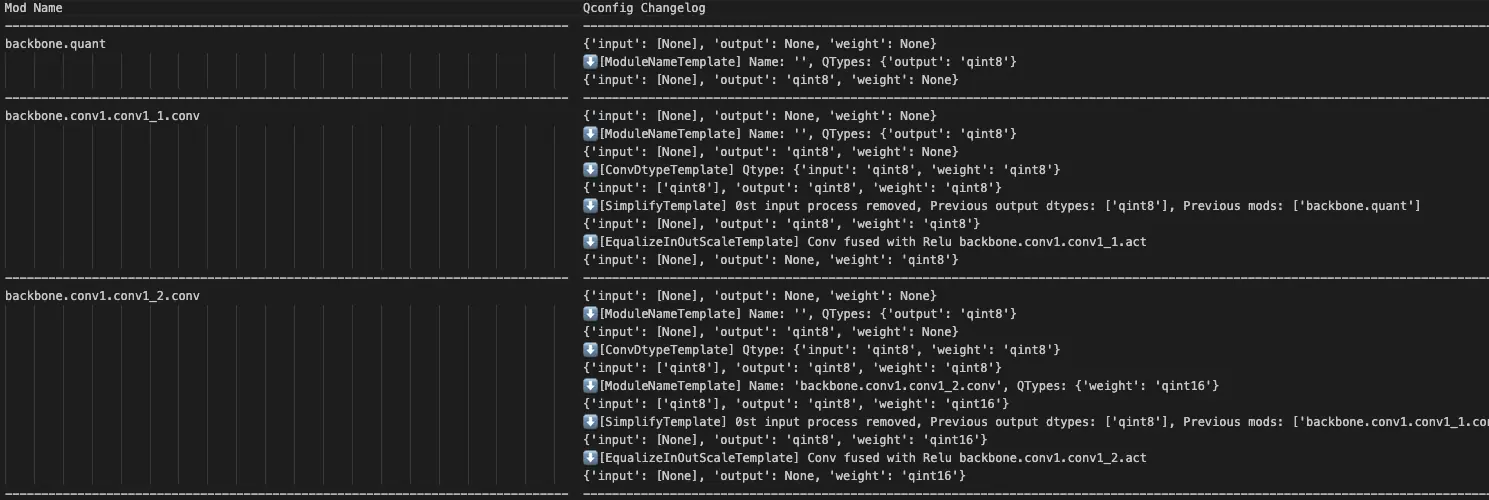
3. 使用示例
本章节将会提供上述模板的使用方法以及在典型场景下的配置示例。
3.1 配置全局 fp16/int16/int8
3.1.1 配置全局 int8
配置全局 qconfig 时必须要配置 ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate 这 3 个模板,以下为使用示例:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.qconfig_template import ModuleNameQconfigSetter,
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.全部算子配置为 int8 输出
ModuleNameTemplate({"":qint8}),
#2.conv 的 input配置为 int8,weight配置为int8
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
#3.matmul 两个输入均配置为 int8
MatmulDtypeTemplate(input_dtypes=qint8),
],
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)配置全局 int16 的方式与全局 int8 类似,将上述示例中的 qint8 修改为 qint16 即可。
注意:
- 配置全局 feat 为 int8/int16/fp16 的时候必须要对 Conv 类算子的 weight 进行配置,否则 weight 会自动做 int16 计算,并可能出现不符合预期的 CPU 算子;
- 配置全局 int8 后,model_check_result.txt 可能会显示模型中仍然存在 int16 计算的算子,这是工具为了提升量化精度做的自动化行为,比如 norm 这种进行拆分实现的算子,内部采用 int16 较高精度的计算,然后输出为 int8。
3.1.2 配置全局 feature int16+weight int8+prefix 批量配置
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.配置全局feat int16,weight int8
ModuleNameTemplate({"":qint16}),
ConvDtypeTemplate(input_dtype=qint16, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint16),
#2.配置backbone部分全int8
ModuleNameTemplate({"backbone":qint8}),
MatmulDtypeTemplate(
input_dtypes=[qint8,qint8],
prefix=["backbone"]
),
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
prefix= ["backbone"],
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.2 fixscale 配置
模型中的某些地方很难依靠统计的方式获得最佳的量化 scale,比如物理量,此时当算子的输出值域确定时就可以设置 fixed scale。新版 qconfig 模板配置 fixed scale 的方式为配置输入/输出的量化类型"dtype"和阈值"threshold",其中 scale 的计算为:

其中 threshold 一般为算子输入/输出的绝对值的最大值;n 则为量化位宽,比如 int8 量化位宽 n=8。
如下为配置 quantstub 算子输出 scale 和 conv 算子输入 scale 的示例:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 配置全局int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{
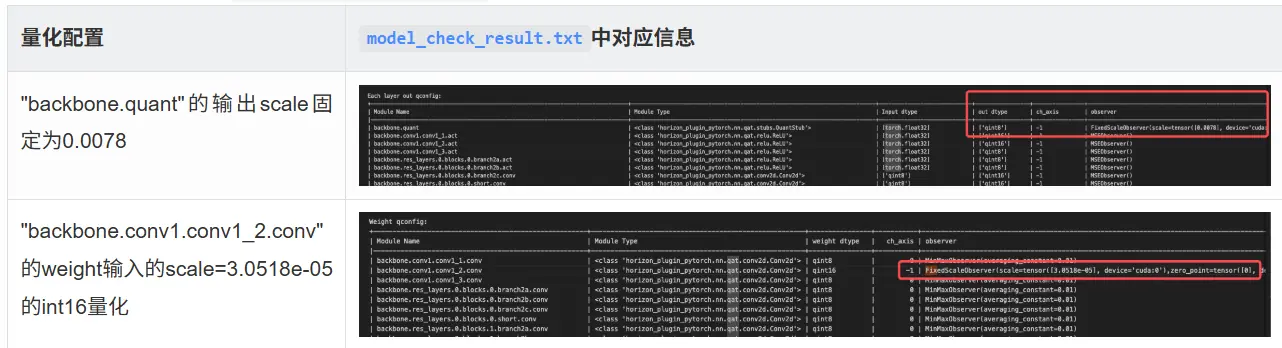
#2.fixscale:配置算子输出的dtype和threshold,此时scale=1/128=0.0078125
"backbone.quant":{"dtype":qint8,"threshold":1.0},
#3.fixscale:配置conv的weight输入为fix_scale的int16量化,
#scale=1/32768=3.0518e-05
"backbone.conv1.conv1_2.conv":{"dtype": {"weight": qint16}, "threshold": {"weight": 1.0}},
},
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)通过 prepare 后生成的 model_check_result.txt 可以验证配置是否生效:
3.3 批量配置 conv/matmul 单/双 int16 输入
ConvDtypeTemplate 和 MatmulDtypeTemplate 支持单/双 int16 输入的批量配置,相关示例如下:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基础配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.Conv 单int16输入配置:将激活输入为int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint16,
weight_dtype=qint8,
prefix= ["backbone.res_layers.0","encoder.encoder.0.layers.0"],
),
#3.Conv 单int16输入配置:将weight配置int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_2.conv"],
),
#4.Conv 双int16输入配置(按需配置)
ConvDtypeTemplate(
input_dtype=qint16,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_1.conv"],
),
#5.matmul单int16配置:将第0个输入配置为int8,第1个输入配置成int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint8,qint16],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul","encoder.encoder.1.layers.0.self_attn.matmul"]
),
#6.matmul单int16配置:第0个输入配置成int16,将第1个输入配置为int8(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.1.self_attn.matmul"]
),
#7.matmul双int16配置:将2个输入都配置为双int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint16],
prefix=["encoder.encoder.0.layers.2.self_attn.matmul"]
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.4 LoadFromFileTemplate 使用示例
当从旧模板迁移到新的 qconfig 量化模板时,推荐的做法是先把旧版本的量化配置 qconfig_dtypes.pt 保存下来,然后使用 LoadFromFileTemplate 进行加载,这里仅介绍此接口的用法,后续章节有完整的迁移教程。
LoadFromFileTemplate 接口使用时需要注意以下问题:
- qconfig_dtypes.pt 不保存算子的 fix_scale 信息,如果原 qconfig 里存在 fix_scale 的算子,需要在加载 qconfig_dtypes.pt 后再次进行配置。
- 使用 LoadFromFileTemplate 接口时 enable_optimize 必须配置为 False,因为保存下来的 dtype 一般是优化后的,优化过程不可重入,Load qconfig_dtypes.pt 后不再支持对 qconfig 中 dtype 的修改。
LoadFromFileTemplate 使用示例如下:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.加载量化配置pt文件
LoadFromFileTemplate("qconfig_dtypes.pt"),
#2.对fix_scale的算子进行补充配置
ModuleNameTemplate({"backbone.quant":{"dtype":qint8,"threshold":1.0}})
],
#3.无需开启任何优化
enable_optimize=False,
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.5 典型场景配置
由于征程 6 系列平台的差异,qconfig 的配置自然也会有所区别。本节将结合平台差异,提供新版 qconfig 模板在典型场景下的配置示例。
3.5.1 征程 6E/M 平台一般配置
征程 6E/M 平台以定点算力为主,在进行混合量化精度调优过程中,建议以全局 int8 精度为例,针对部分对量化较为敏感的算子,可将其配置为更高的 int16 精度。以下为配置示例。
配置示例 1:全局 int8+ 手动配置量化敏感度高的算子为 int16
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.配置全局feat int8,weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.根据精度debug工具分析,将敏感算子配置为int16(按需配置)
#将weight敏感的conv配置为int16(按需配置),支持批量配置
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_3.conv"],
),
#3.将敏感的Matmul配置为int16输入(按需配置)
#将第0个输入敏感的matmul配置为int16(按需配置),支持批量配置
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul"]
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)配置示例 2:全局 int8+ 使用敏感度模板配置部分敏感算子为 int16
除了手动将部分敏感算子配置为 int16,新版 qconfig 模板提供了 SensitivityTemplate,该模板用于将精度 debug 工具所产出的敏感度列表中,量化敏感度排序 topk 或者占一定比率 ratio 的敏感算子,配置为更高的量化精度。相关示例如下:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
#精度debug工具跑出来的算子量化敏感度列表
table1=torch.load("output1_ATOL_sensitive_ops.pt")
table2=torch.load("output2_ATOL_sensitive_ops.pt")
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 基础配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.配置output1输出敏感度Top10的算子为int16(按需配置)
SensitivityTemplate(
sensitive_table=table1,
topk_or_ratio=10,
),
#3.配置output2输出敏感度10%的算子为int16(按需配置)
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.1,
),
],
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)topk_or_ratio 参数的选择:需要用户根据量化精度和部署性能进行权衡,一般来说,配置的高精度算子越多,量化精度越好,而部署性能影响则会越大。
3.5.2 征程 6P/H 平台一般配置
对于征程 6 P/H 这种有浮点算力的平台,推荐将 feature 输出配置为 fp16+conv 和 matmul 类算子全部配置为 int8 作为基础配置,然后再将量化敏感的算子配置为 int16。如下为配置示例。
配置示例 1:基础配置 + 手动配置量化敏感度高的算子为 int16
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.qconfig_template import ModuleNameQconfigSetter,
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基本配置
#全局 feat fp16
ModuleNameTemplate({"": torch.float16}),
#将conv和matmul类算子配置为全int8输入
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
),
MatmulDtypeTemplate(
input_dtypes=[qint8, qint8],
),
#2.根据debug工具分析结果,将敏感的Conv/Matmul配置为int16输入(按需配置)
#将conv中敏感的weight输入配置为int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_3.conv"],
),
#将matmul中敏感的输入配置为int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul"] ),
],
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)配置示例 2:基础配置 + 使用敏感度模板配置部分敏感算子为 int16
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
#精度debug工具跑出来的算子量化敏感度列表
table1=torch.load("output1_ATOL_sensitive_ops.pt")
table2=torch.load("output2_ATOL_sensitive_ops.pt")
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基本配置
#全局 feat fp16
ModuleNameTemplate({"": torch.float16}),
#将conv和matmul类算子配置为全int8输入
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
),
MatmulDtypeTemplate(
input_dtypes=[qint8, qint8],
),
#2.配置output1输出敏感度Top10的算子为int16(按需配置)
SensitivityTemplate(
sensitive_table=table1,
topk_or_ratio=10,
),
#3.配置output2输出敏感度10%的算子为int16(按需配置)
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.1,
),
],
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.5.3 配置算子为 float32 计算
在做精度调优的时候,有时候想要快速定位引起量化误差的瓶颈,此时会将模型片段或者算子配置为 float32 计算,如下为将指定模型片段和算子配置为 float32 计算的示例:
Plain
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 基础配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{
#2.批量配置"encoder.encoder.0.layers.0"为float32计算
"encoder.encoder.0.layers.0": torch.float32,
#3.配置"backbone.conv1.conv1_2.conv.act"算子为float32计算
"backbone.conv1.conv1_2.conv.act": torch.float32,}
),
],
save_dir=args.save_path,
)3.5.4 QAT 训练时固定激活 scale
在 QAT 精度调优实践中发现(主要是图像分类任务实验),做完 calibration 后,把 activation 的 scale 固定住,不进行更新,即设置 activation 的 averaging_constant=0 ,QAT 训练精度相比于不固定 activation 的 scale 的量化精度会更好。相关配置示例如下所示:
Plain
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.fake_quantize import FakeQuantize
from horizon_plugin_pytorch.quantization.qconfig import QConfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import get_qconfig
my_qconfig_setter=QconfigSetter(
#将激活的averaging_constant参数配置为0
reference_qconfig= QConfig(
output=FakeQuantize.with_args(
observer=MinMaxObserver,
averaging_constant=0,#averaging_constant配置为0
), ),
templates=[
#配置weight和激活全局int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)4. 新版 qconfig 模板迁移
用户在迁移到新版 qconfig 模板时,建议根据以下情况进行不同的操作:
- 如果用户部署平台为征程 6B、征程 6H 和征程 6P,为了更方便地利用浮点算力,建议使用新版 qconfig 模板。
- 如果用户模型从未适配过 QAT 链路,建议用户直接参考第 3 章使用新版 qconfig 模板进行配置。
- 如果用户模型已经适配过老版本 qconfig 模板,且在模型迭代中还需要修改 qconfig 配置,比如增加 int16 算子等,那么建议用户参考第 3 章重新进行新版 qconfig 模板的适配。
- 如果用户模型已经适配过老版本 qconfig 模板,且确认在模型迭代中不再需要修改 qconfig 配置,那么则建议用户按照下面的流程进行迁移工作。
若用户已经稳定使用老版本 qconfig 模板,而且模型迭代中不需要再修改量化配置,那么建议按照以下流程进行适配:
- 首先,使用
SaveToFileTemplate接口保存旧模板下的量化配置文件qconfig_dtypes.pt,其中涵盖每个算子的 dtype; - 其次,需检查模型中是否存在采用 fix_scale 的算子。鉴于 qconfig_dtypes.pt 目前尚不支持保存 fix_scale 的算子信息,并且新旧模板在 fix_scale 的配置方面存在差异,若存在 fix_scale 的算子,那么就必须对新模板下 fix_scale 的配置进行适配;
- 最后,运用
LoadFromFileTemplate接口加载已保存的qconfig_dtypes.pt``文件,将量化 dtypes 配置导入新模板中,从而实现量化配置的迁移衔接。
这里要特别注意,加载已保存的 qconfig_dtypes.pt 文件后不支持再对模型中的算子 dtype 做修改。
下面将详细介绍迁移的具体步骤和操作要点。
4.1 保存旧版本的 qconfig_dtypes 文件
horizon_plugin_pytorch 提供了 SaveToFileTemplate 接口用于将量化配置文件保存为 qconfig_dtypes.pt。其路径和使用方式如下:
Plain
from horizon_plugin_pytorch.quantization.qconfig_setter.templates import *
...
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(...),
calibration_8bit_weight_16bit_act_qconf