在深入了解了 GPT 系列模型的发展脉络之后,我们不禁要问:大模型的未来一定是"越大越强"吗? OpenAI 的 GPT-3 拥有 1750 亿参数,Google 的 PaLM 甚至达到了 5400 亿。但在另一条赛道上,Meta 提出了一个截然不同的答案 ------ LLaMA(Large Language Model Meta AI) 。它不仅在多个任务中击败了 GPT-3 和 PaLM,还做到了完全基于开源数据训练,小型号甚至能在单张 GPU 上运行。这意味着,大模型不再是巨头专属,人人都能参与语言模型的研究与应用。

本篇我们就来拆解 LLaMA 的核心设计理念、技术细节与实验表现,看看它是如何在"开源、高效、强性能"之间实现完美平衡的。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
阅读这篇文章前你可以思考三个问题:
- LLaMA 模型和 GPT-3、PaLM、Chinchilla 有什么核心区别?
- LLaMA 是如何做到"小模型高性能"的?
- LLaMA 在模型开源和数据使用方面解决了哪些实际问题?
一、LLaMA 是什么?

LLaMA(Large Language Model Meta AI)是 Meta AI 发布的一系列基础语言模型,参数规模从 7B 到 65B 不等 。不同于其他巨型模型如 GPT-3(175B)和 PaLM(540B),LLaMA 的目标是:在更小模型尺寸下,达到甚至超越主流模型的性能,同时具备开放、可复现的研究价值。
LLaMA-13B 的性能已经超过了 GPT-3,而 LLaMA-65B 可以和 PaLM-540B 平起平坐!
二、技术创新点有哪些?
LLaMA 的强大性能不是凭空而来的,而是得益于它在多个方面做出的改进:
2.1架构优化
- 预归一化(Pre-Norm):使用 RMSNorm 提升训练稳定性;
- SwiGLU 激活函数:替代 ReLU,提高表达能力;
- RoPE 位置编码:用旋转位置编码代替绝对位置编码,保留序列信息;
- 高效注意力机制:使用 xformers 中优化的因果注意力,降低内存消耗;
- 梯度检查点和并行训练:节省显存开销,使训练 65B 成为可能。
2.2数据来源公开且多样
与 GPT-3 等模型不同,LLaMA 训练 完全基于公开数据集,不依赖私有或不可获取的数据源:
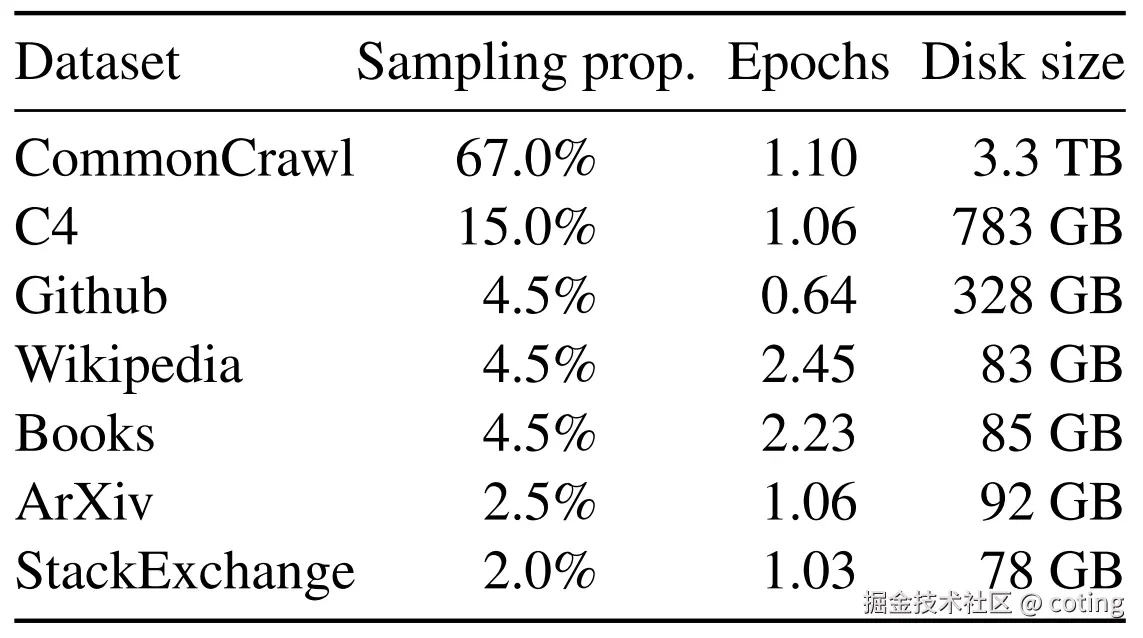
- CommonCrawl (67%)
- C4 (15%)
- GitHub / Wikipedia / Books / ArXiv / StackExchange
这样做的最大好处是:完全可复现、可分享,极大地降低了研究门槛。
2.3模型规格与训练参数
LLaMA 提供了 7B、13B、33B、65B 四种规模,训练总 token 数最高达到 1.4 万亿 。使用了 AdamW 优化器 、cosine 学习率调度 ,所有训练均在 2048 块 A100 80GB GPU 上完成。
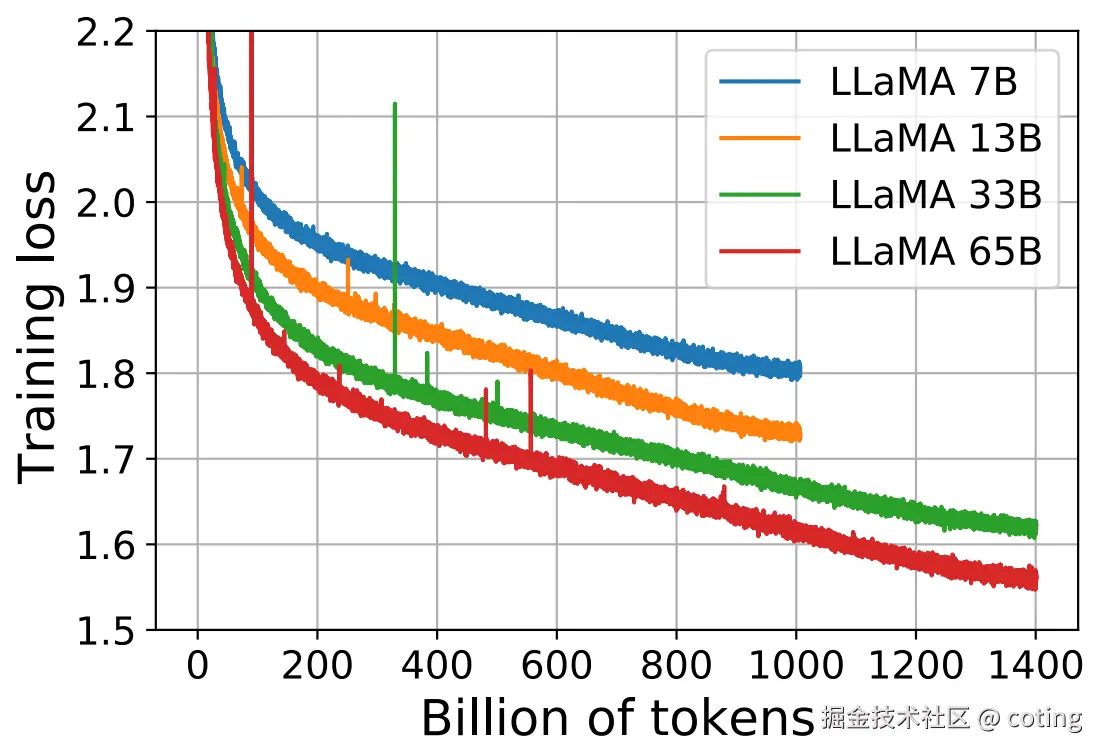
三、表现到底有多强?
LLaMA 在多个标准基准测试中都有惊艳表现,尤其在 零样本(zero-shot) 和 少样本(few-shot) 任务中:
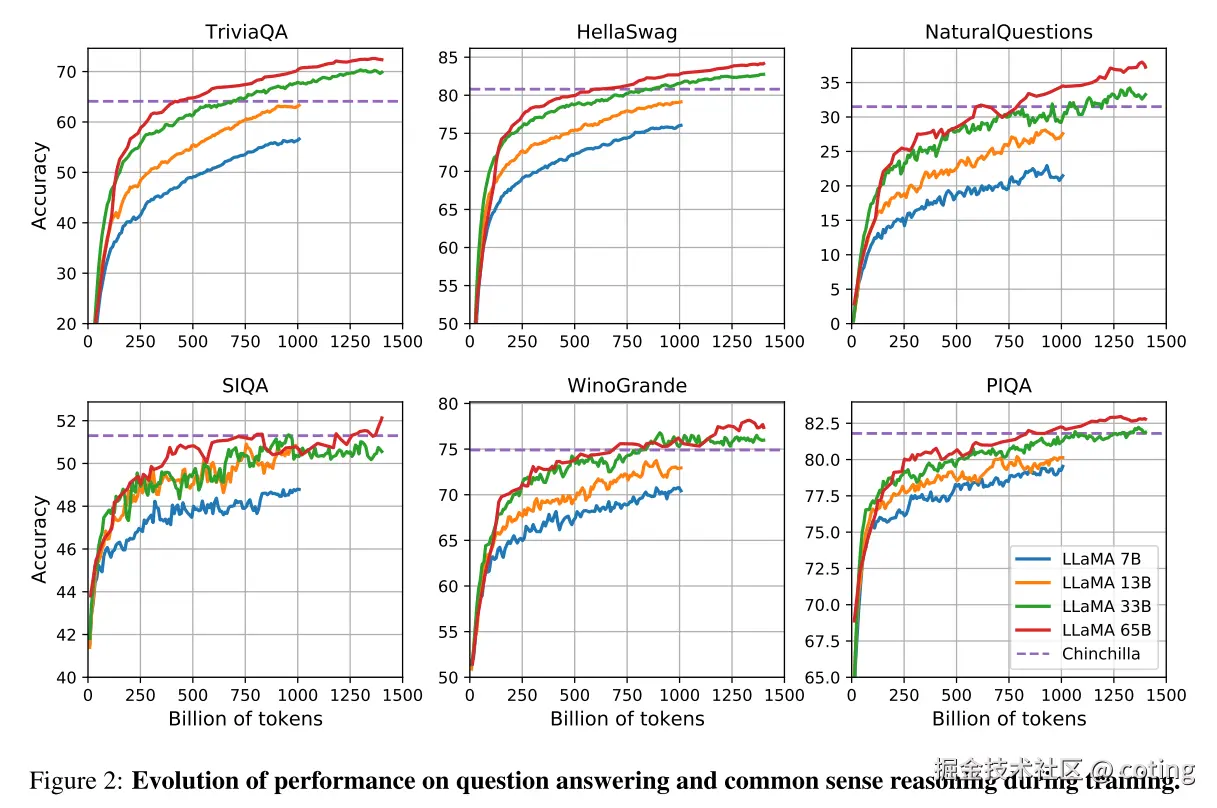
3.1常识推理任务(如 BoolQ、PIQA、ARC)
LLaMA-13B 超过 GPT-3,LLaMA-65B 更是全面碾压 Chinchilla 和 PaLM。
3.2阅读理解(RACE)、问答(Natural Questions、TriviaQA)
- LLaMA-65B 的准确率可达 GPT-3 的水平,甚至在 TriviaQA 上小幅领先。
- LLaMA-13B 可在一张 V100 GPU 上运行,做到了低成本部署。
3.3数学与代码推理
尽管未专门微调数学数据,LLaMA-65B 在 GSM8k 上超过了 Minerva-62B。在代码生成任务(如 HumanEval 和 MBPP)中,LLaMA-65B 的表现也优于同尺寸 PaLM 和 LaMDA。
四、LaMA 的优势
LLaMA 不是单纯的"又一个大模型",它是一次具有开源精神和工程美感的范例:
- 开源数据训练:不涉及私有资源,降低再现难度;
- 碳足迹较低:LLaMA-13B 的训练耗电仅为 PaLM 540B 的 10%,更绿色节能。
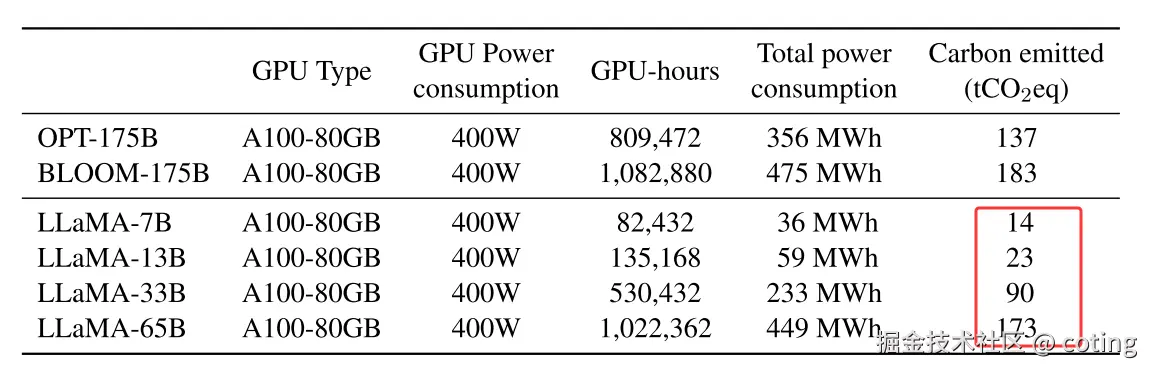
LLaMA 就像大模型界的"中量级冠军",在不靠体型取胜的同时,用技术和策略打赢了许多场硬仗。
五、不足与挑战
- 在某些任务(如 MMLU)上稍逊于 Chinchilla 和 PaLM,可能与预训练书籍数据量较小有关;
- 存在一定的 性别、宗教等偏见问题,生成毒性内容的概率随模型增大而上升;
- 仍有生成虚假信息的可能性(TruthfulQA 上最高仅 57% 真实性)。
回到开头,我们来回答那三个问题:
1. LLaMA 模型和 GPT-3、PaLM、Chinchilla 有什么核心区别?
LLaMA 最大的区别在于其完全基于公开数据训练 ,而 GPT-3、PaLM 等模型使用了大量无法公开的数据资源。同时,LLaMA 在模型架构中采用了诸如 RoPE 位置编码、SwiGLU 激活函数、RMSNorm 等优化策略,在不增加模型规模的情况下提升了性能。此外,LLaMA 更加注重推理效率和训练可复现性。
2. LLaMA 是如何做到"小模型高性能"的?
LLaMA 遵循了 Chinchilla scaling laws 的原则,即:与其一味增大模型参数,不如在固定算力预算下训练更多 token 数 。例如,LLaMA-13B 在训练中使用了高达 1T token,使得它能以远小于 GPT-3 的参数量,实现更好的性能表现。这种训练数据优先于参数堆叠的策略,是其成功的关键。
3. LLaMA 在模型开源和数据使用方面解决了哪些实际问题?
LLaMA 所有训练数据都来源于公开可获取的数据集(如 CommonCrawl、Wikipedia、GitHub、ArXiv 等),避免了私有数据版权与伦理问题 ,极大降低了再训练和应用的门槛。同时,其小型号(如 7B、13B)支持单卡运行,为学术界和中小企业提供了公平参与大模型研究的机会,真正推动了 AI 开放与民主化的发展。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!