🌟 各位看官好,我是!****
🌍 Linux == Linux is not Unix !
🚀 今天来学习Linux的指令知识,并学会灵活使用这些指令。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦!

目录
[return 0](#return 0)
进程创建
在linux中fork函数是非常重要的函数,它从已存在进程中创建⼀个新进程。新进程为⼦进程,⽽原进程为⽗进程。(上几个章节中,我们也对fork有了简单的认识)
include <unistd.h>
pid_t fork ( void );
返回值:子进程中返回 0 ,⽗进程返回⼦进程 id ,出错返回 -1
进程调⽤fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将⽗进程部分数据结构内容拷贝⾄子进程
- 添加⼦进程到系统进程列表当中
- fork返回,开始调度器调度
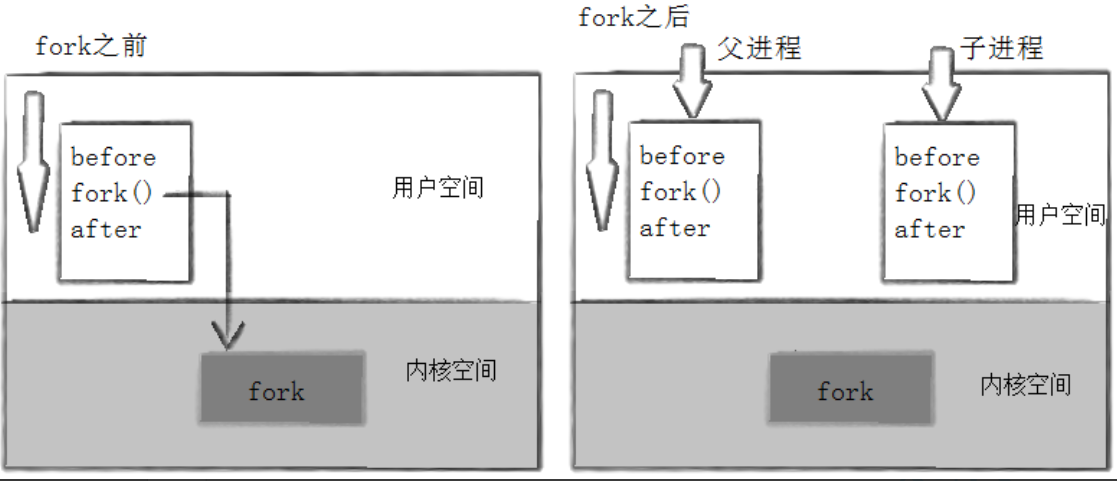
当⼀个进程调⽤fork之后,就有两个⼆进制代码相同的进程。⽽且它们都运⾏到相同的地⽅,但每个进程都将可以开始它们自己的旅程。(注意: fork之后,谁先执⾏完 全由调度器决定。 )
写时拷贝
通常,父子代码共享,⽗⼦再不写入时,数据也是共享的,当任意⼀⽅试图写⼊,便以写时拷贝的⽅式各⾃⼀份副本。(因为有 写时拷贝技术的存在,所以⽗⼦进程得以彻底分离! 完成了 进程独立 性的技术保证!)
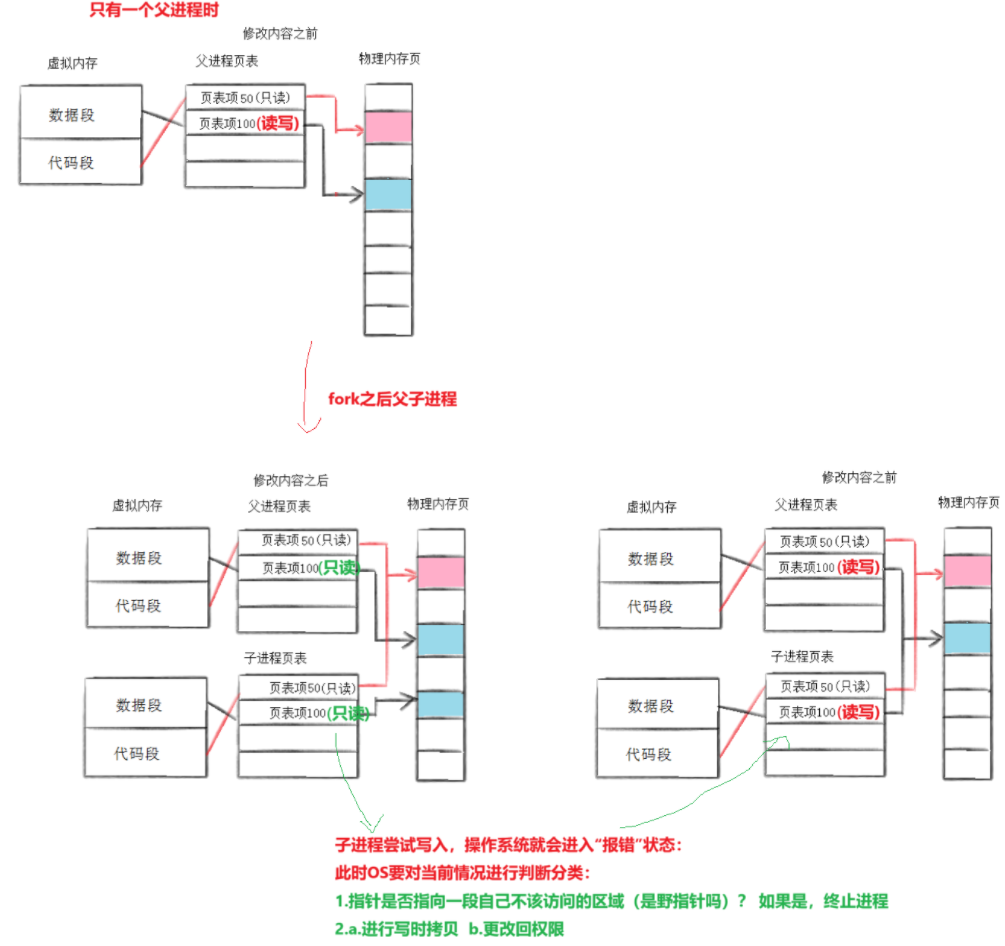
为什么要写时拷贝
但是仔细一想会有两点疑惑:
问题1:为什么创建子进程后,不直接将数据进行分开,直接拷贝不就好了?为什么要写时拷贝?
数据分开的本质是"按需获取",节省内存。而写时拷贝是一种"惰性"申请,等需要写入时再进行写时,也是为了节省内存。
问题2:为什么要拷贝?直接开辟对应的空间不就好了?
- 减少内存占用 :当
fork系统调用创建子进程时,子进程会复制父进程的地址空间。如果直接开辟新的内存空间并将父进程的数据全部复制过去,在很多情况下,子进程并不会修改父进程的大部分数据。 - 加速
fork操作 :直接开辟空间并复制数据会增加fork操作的时间开销。
实际上我们之前所使用的C/C++也用到了"惰性"申请: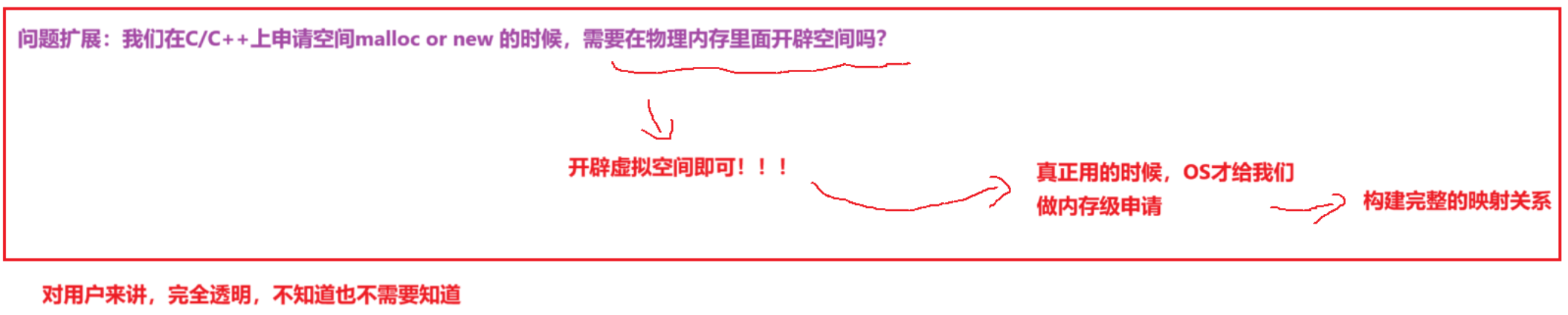
进程终止
进程终止是什么?一个进程既然被创建出来,那么自然也要对它进行负责,因此需要回收子进程的资源。(创建进程的反方向)
进程终⽌的本质是释放系统资源,就是 释放进程申请的相关内核数据结构和对应的数据和代码。
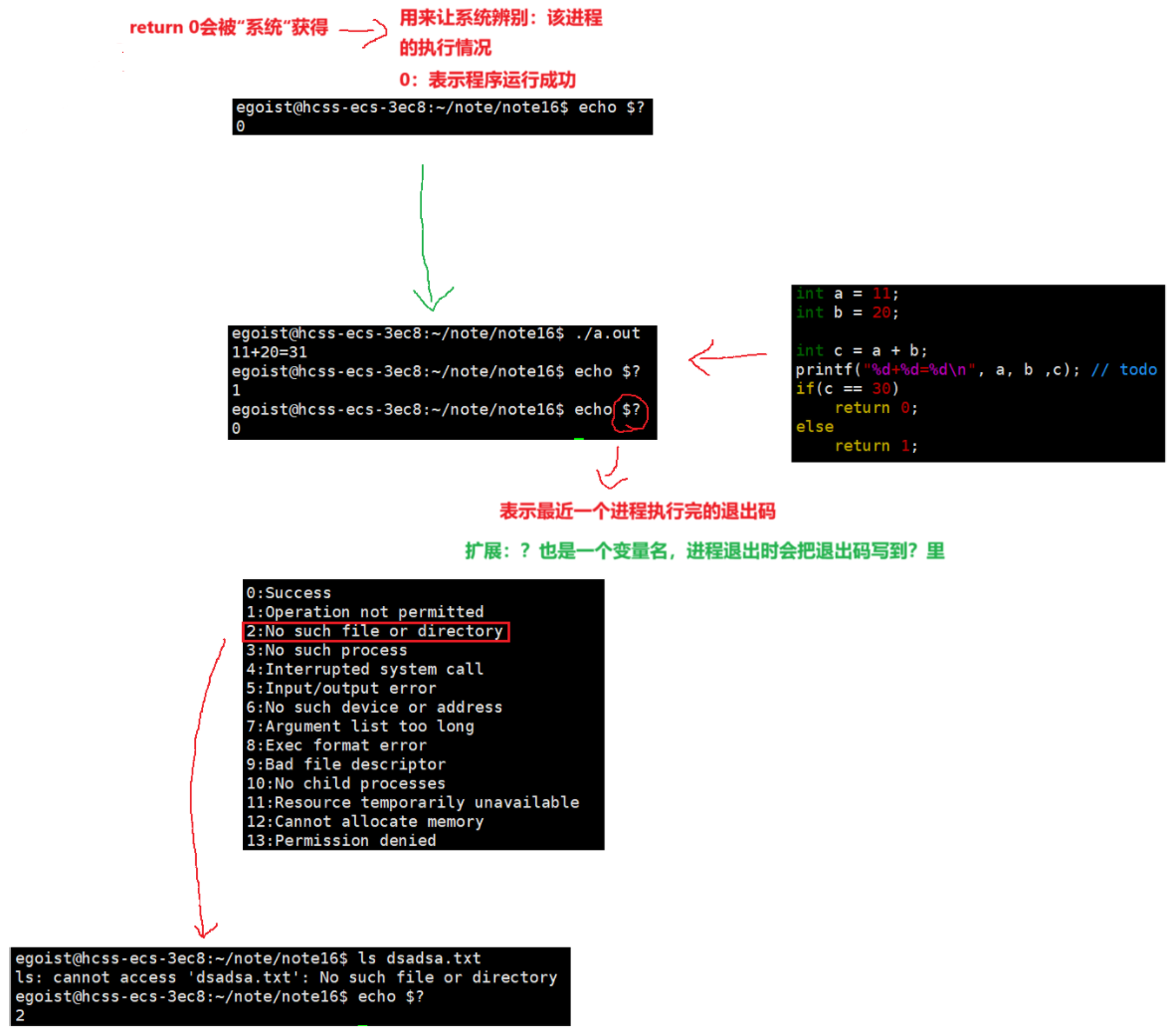
return 0
这里对我们之前的C/C++中main函数为什么要返回return 0 进行解惑。我们都清楚我们的程序是由bash创建子进程来运行的,那么bash之后肯定要回收子进程,因此可以确定的是子进程的return 0的退出码是给父进程的。return 0 会被"系统"获得 --> 它被用来让系统辨别:该进程的执行情况!!!因此,0表示该进程执行成功。
那退出码是否可以被我们人为获取呢?答案是可以的。
退出场景
进程退出无非就三种情景:
- 代码跑完了,结果正确;
- 代码跑完了,结果错误;
- 代码没跑完,结果异常。(代码异常了,退出码本身就没意义了! --> 意义在为什么会出现异常,管理者OS要知道:一般都是发出进程信号来杀掉这个进程)
前两种场景:
前两种场景是由退出码来决定!!! --> exit(code)
查看退出码有三种方法:
- main函数进行return n,n表示该进程的退出码;
- 直接调用exit(n),n表示该进程的退出码;
- 直接调用_exit(n)
那么这三种方法有什么区别呢?
return vs exit
return 表示函数调用结束,main函数return,表示进程退出;exit表示的是进程结束,在代码中任何地方调用,都会导致进程退出,即exit引起一个进程结束(会刷新缓冲区)。
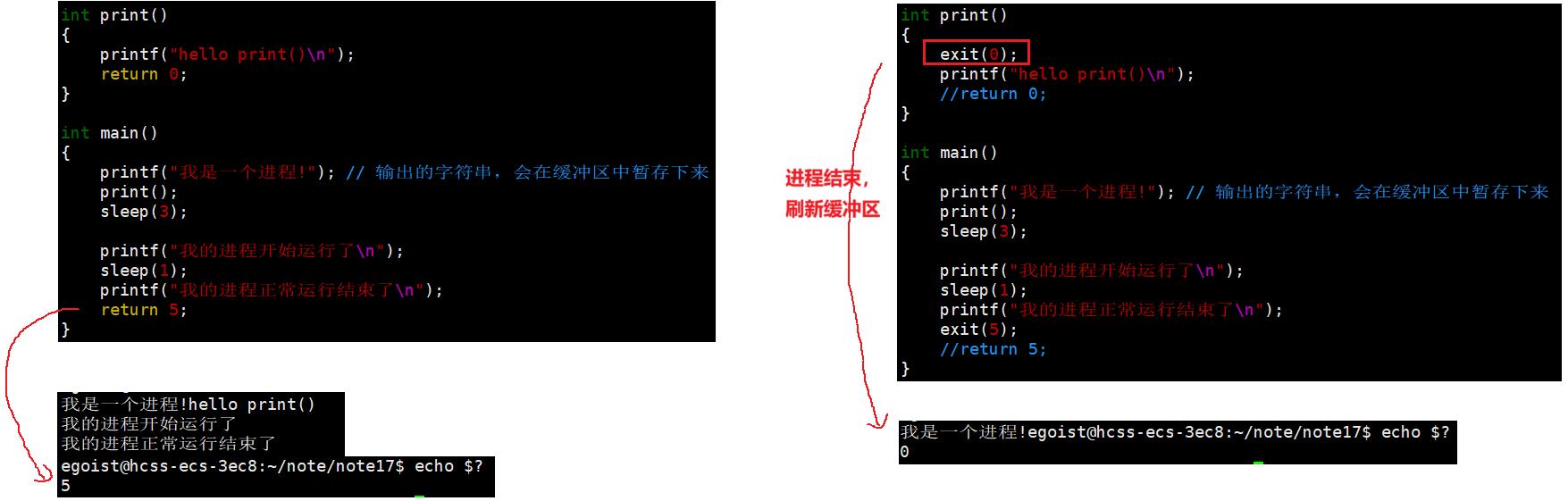
exit vs _exite
exit属于库函数,终止进程时会主动刷新缓冲区 ;_exit属于系统调用,直接终止进程但不会刷新缓冲区。

它们两的区别就在于是否刷新缓冲区,而我们知道进程主动请求终止的路径是要通过系统调用来完成,由此我们可以猜测exit接口在内部会调用_exit系统调用,即exit底层封装了_exit。

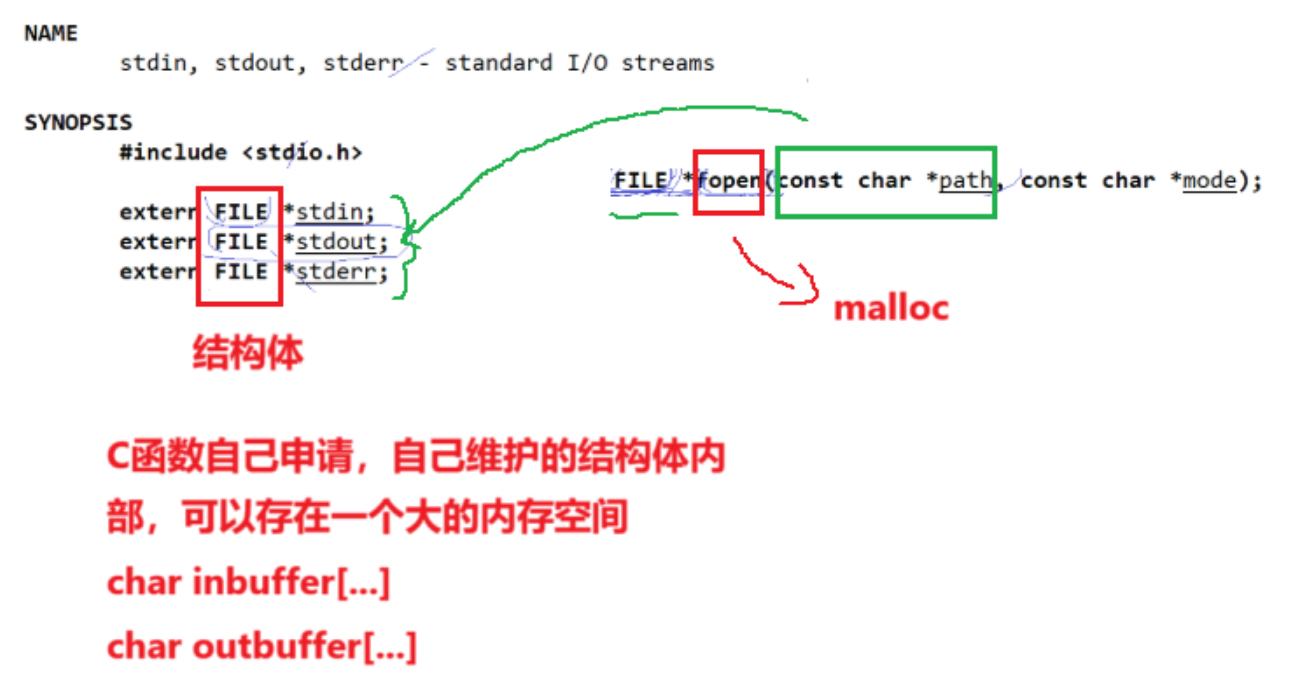
FILE结构体