HumanPCR: Probing MLLM Capabilities in Diverse Human-Centric Scenes
Authors: Keliang Li, Hongze Shen, Hao Shi, Ruibing Hou, Hong Chang, Jie Huang, Chenghao Jia, Wen Wang, Yiling Wu, Dongmei Jiang, Shiguang Shan, Xilin Chen
Deep-Dive Summary:
1 引言
多模态大语言模型(MLLMs)的快速发展在理解多样化情境方面展现了惊人的潜力 1-6。这一进步推动了朝向人工通用智能的渴望,并提高了对 MLLMs 在现实世界中像人类一样有效运作的期望 7-9。一个关键前提在于能够在多样化、复杂和动态的情境中理解人类,因为人类行为本质上反映了世界的复杂性以及现实世界的互动 10-14。在本文中,我们从这一视角出发,系统性地研究 MLLMs 在不同场景中对人类的理解能力,重点关注以人为中心的视觉理解中的感知、理解和推理等关键方面。
以人为中心的视觉理解 15, 16 仍然是人工智能领域的一个基本挑战。
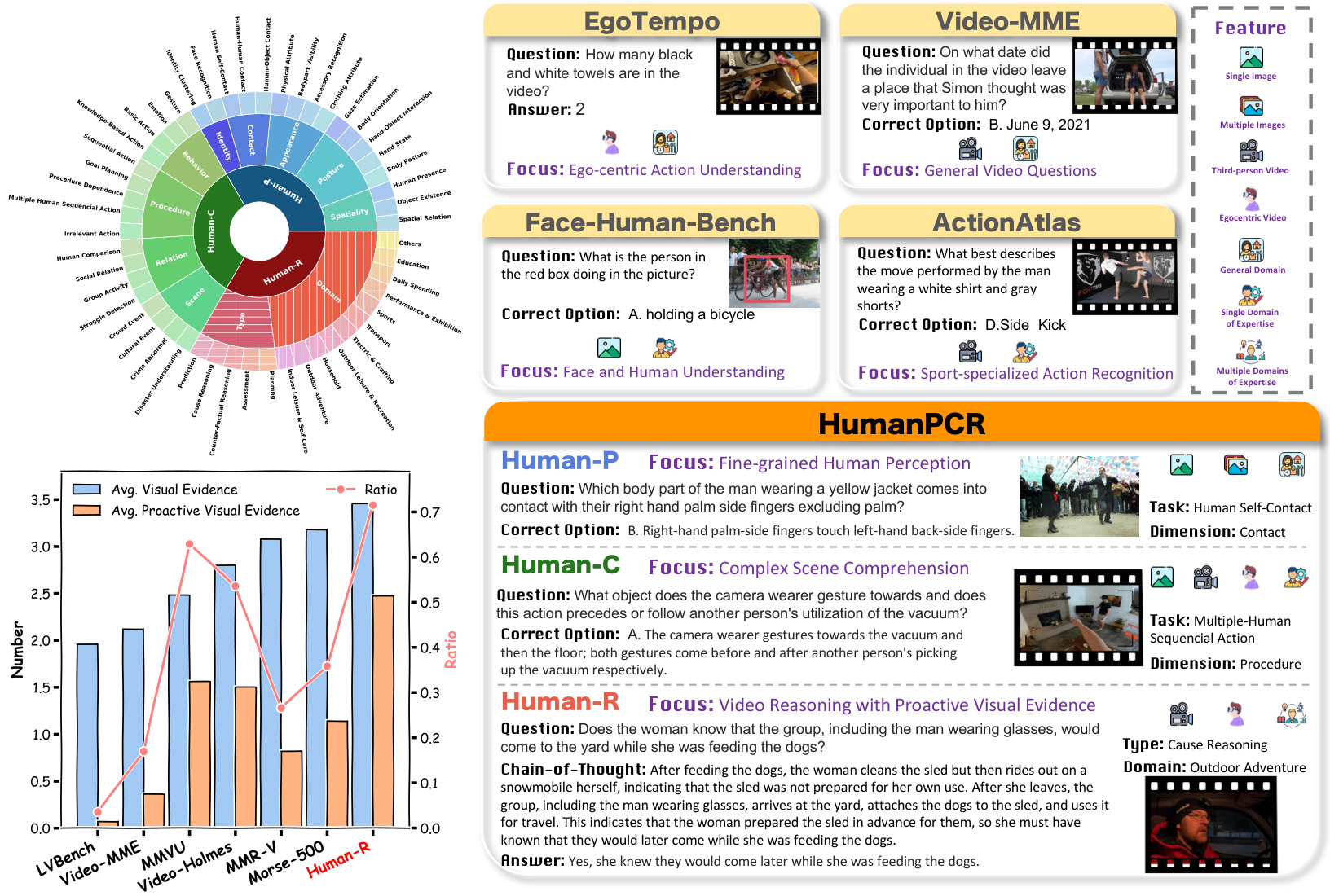
虽然这些专门的数据集在诸如自我中心动作或面部理解等子领域中推动了我们的知识进步,但它们的范围本质上有限,无法捕捉人类活动的广泛复杂性。同时,通用的 MLLM 基准 9, 24-27 涵盖了更广泛的主题,但往往缺乏对以人为中心的细粒度评估所需的深度,忽略了诸如视线或身体方向估计等复杂任务 28, 29。随着推理专门模型的快速发展 30-32,近期基准 9, 33-36, 24, 37 试图增加评估复杂性以更好地测试模型应对现实世界挑战的能力,但它们在视觉中心的复杂性方面仍然不足。如图 1(左下方的条形图)和图 2 所示,当前基准 38-40 通常需要的视觉证据较少,且很少评估模型主动寻找并推理超出问题中明确表述的隐性视觉线索的能力。相比之下,现实世界中密集且动态的人类活动------这些是智能的丰富来源 41-43------在很大程度上被忽视,因为现有基准很少在这些真正复杂的、以人为中心的场景中挑战模型的推理能力 33, 35, 44。
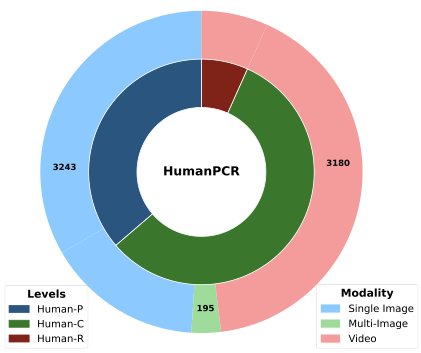
为了解决上述差距,本研究贡献了一个评估套件 HumanPCR,用于基准测试以人为中心的视觉理解。HumanPCR 结构化为三个层次的分类体系:Human-P(感知)、Human-C(理解)和 Human-R(推理),如图 1 左上方所示。对于 Human-P 和 Human-C,我们整理了一个大规模的多选问答(QA)数据集,包含超过 6000 个经过人工验证的图像和视频 QA 对,沿 9 个维度评估感知和理解能力,涵盖总共 34 个不同任务。Human-R 提供了一个具有挑战性的人工整理的开放式视频推理数据集。Human-R 来源于 11 个不同的人类相关领域,要求模型通过整合多个视觉证据、主动提取问题中明确线索之外的上下文,并应用类似人类的领域专长来解决复杂问题。为了支持进一步研究,Human-R 中的每个问题都附带了人工标注的思维链(Chain-of-Thought, CoT)45 推理,涵盖所有关键视觉证据。
我们对 HumanPCR 上的一系列开源和专有模型进行了全面评估。我们的发现揭示了现有模型在以人为中心的视觉理解方面的重大挑战,以及在涉及详细空间感知 46 和时间理解等任务中的能力限制。
未批准的人类-R标注
以下是对论文中"未批准的人类-R标注"部分的中文总结,保留了原文中的图片部分及其格式:
问题与分析
-
问题2:女性执行了哪些任务?
多证据识别,无需推理。
-
问题3:雪橇犬能否被柴犬替代?
审查:X视觉独立性。
-
问题:女性是否知道包括戴眼镜的男人在内的小组会在她喂狗时来到院子里?
思维链:在她自己移动后,表明雪橇并非为她自己准备使用。在她离开后,小组(包括戴眼镜的男人)来到院子里。这表明她在喂狗时可能并未预料到他们的到来。
研究分析与结论
对人类-R的分析显示,模型在处理来自多样化人类场景的多个视觉证据时存在推理困难,并且错误地依赖于查询引导的线索(参考文献47-49)。因此,仅仅扩展视觉上下文(参考文献3-5, 50, 49)或增加测试时的思考时间(参考文献31, 51, 52)带来的益处有限。缺乏主动证据和识别错误在人类-R的错误案例中占据了很大比例。这些结果验证了我们基准测试的必要性,并暗示了多语言大模型(MLLMs)在解决现实世界问题时的关键缺陷。我们希望这一基准测试能够帮助MLLMs适应多样化的下游应用,并推动更通用、更具能力的MLLMs的发展。
2 相关工作总结
多模态大语言模型(MLLMs)
多模态大语言模型(MLLMs)是从大语言模型(LLMs)演变而来,能够处理多种模态数据,包括图像序列53, 1、视频54, 1, 55和音频56。最近的模型如Qwen2.5-VL5和InternVL351提供了动态分辨率处理能力,并支持超长上下文。在长视频理解方面,特别是在有限上下文窗口内,采用上下文提取策略57, 58,如帧采样59-61和token修剪50, 62, 49,以高效提取相关内容48, 58。此外,具有强大推理能力的模型32, 63, 30, 31的出现,激发了通过利用和增强模型推理过程来提升视觉理解的开创性努力64-67。
人类中心视觉理解的评估
人类中心视觉理解长期以来一直是人工智能的基石应用15, 16, 14。随着MLLMs的最新进展,越来越多的研究42, 20, 19, 68开始探索其在解码人类运动17、人脸识别18, 69, 23以及解释特定领域活动70, 21, 71方面的能力。然而,研究普遍得出结论:当前的MLLMs在人类中心视觉理解方面仍存在显著局限性。另一研究方向专注于将MLLMs应用于3D人类建模任务22, 72, 73,如运动生成74, 75和运动跟踪76。鉴于人类活动在现实场景中的普遍性,许多综合性基准25, 24, 77也纳入了人类中心任务,包括名人识别和动作识别。然而,这些基准通常缺乏结构化的分类体系和统一的评估协议,难以对人类中心视觉理解得出系统性见解。
多模态推理基准
随着MLLMs能力的提升,许多基准开始涉及越来越复杂的任务,以评估其推理能力36, 8, 46, 78, 37。早期研究通过跨多学科的标准化考试评估推理能力9,随后扩展到涉及自然图像36和多图像输入79的任务。在基于视频的推理方面,近期取得了进展80, 46, 81, 82, 39, 40, 34。综合性基准47如Video-MME24和MMBench-Video83包含预定义的推理任务,而MultiHop-EgoQA84则针对物体共现推理。MMWorld85和MMVU33引入了多学科视频推理问题,而VideoMMMU35则专注于从学科讲解视频中进行知识推理。近期的工作,如VideoEspresso86和VCR-Bench44,通过自动标注和重新利用现有问答对构建具有推理过程的视频问答。相比之下,我们提出的Human-R基准通过提供人工标注的问答对以及带有关键视觉证据的人工标注CoT(思维链)推理,强调多证据整合和在多样化人类中心情境下信息提取的挑战。
3 The HumanPCR Benchmark
3.1 HumanPCR 概述
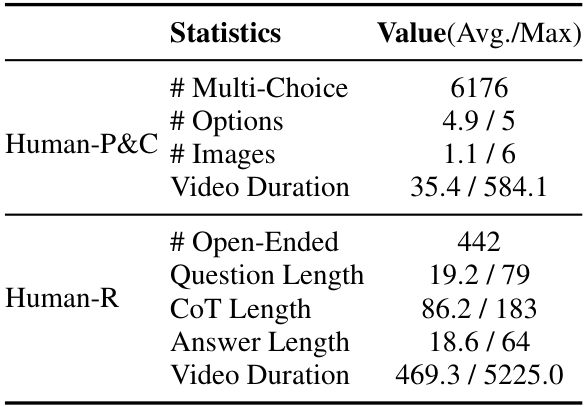
我们介绍了 HumanPCR 基准,用于评估多模态大语言模型(MLLMs)在现实世界场景中对人类的理解能力。HumanPCR 采用三级层次分类结构,包含全面的维度,形成了超过 6000 个多选题,覆盖 34 个任务,以及 442 个开放性问题,其中包括人工标注的思维链(CoT)推理依据。HumanPCR 的更多关键统计数据总结于表 1 中。每个任务的定义、详细实施以及标注元数据分别在附录 A、B 和 C 中提供。
HumanPCR 的分类结构简要介绍如下:
- 一级:感知(Perception) 评估对特定元素的识别能力。涵盖五个维度,共包括 17 个任务:(1) 空间性(Spatiality):感知人、物体及其空间关系的存在;(2) 姿势(Posture):识别身体部位、手部和目光的物理状态及方向;(3) 外观(Appearance):识别人类外貌,包括固有属性和穿着;(4) 接触(Contact):识别人与物体或自身之间的详细互动区域;(5) 身份(Identity):识别个人身份。
- 二级:理解(Comprehension) 评估整合常识或领域特定线索的基本视觉概念理解能力。涵盖四个维度,共包括 17 个任务:(1) 行为(Behavior):理解人类动作和身体运动,如手势和情感;(2) 程序(Procedure):深入理解长期活动,包括潜在意图和动作序列之间的依赖;(3) 关系(Relation):分析个体之间的关系、角色和差异;(4) 场景(Scene):在更广泛的背景下解释群体动态或人类活动。
- 三级:推理(Reasoning) 考察模型是否能在复杂场景中整合连续、紧密耦合的人类动态进行推理。我们认为评估应满足以下三个标准:(1) 视觉复杂性(Visual Complexity):问题应需要足够的视觉证据,并排除冗余视觉内容,超越简单的概念检索;(2) 推理必要性和多样性(Reasoning Necessity and Diversity):问题应涉及多样的推理链,而不仅限于少数推理模式;(3) 主动性(Proactivity):问题应要求在连续上下文中主动提取视觉证据,而不仅仅依赖问题中明确指定的证据。
基于这些标准,我们开展了推理层面的评估,要求整合视频上下文中的多重视觉证据,并鼓励设计只能通过从视频中主动提取证据来解决的问题,而不是在问题中直接披露所有必要信息。如图 2 所示,这种设计系统性地、可靠地测试了模型在真实视频理解和复杂多模态推理方面的能力,而依赖孤立证据或完全指定问题的测试往往允许基于单帧匹配或对象先验的捷径解决方案,从而绕过了真正的视频理解和充分推理的需求。
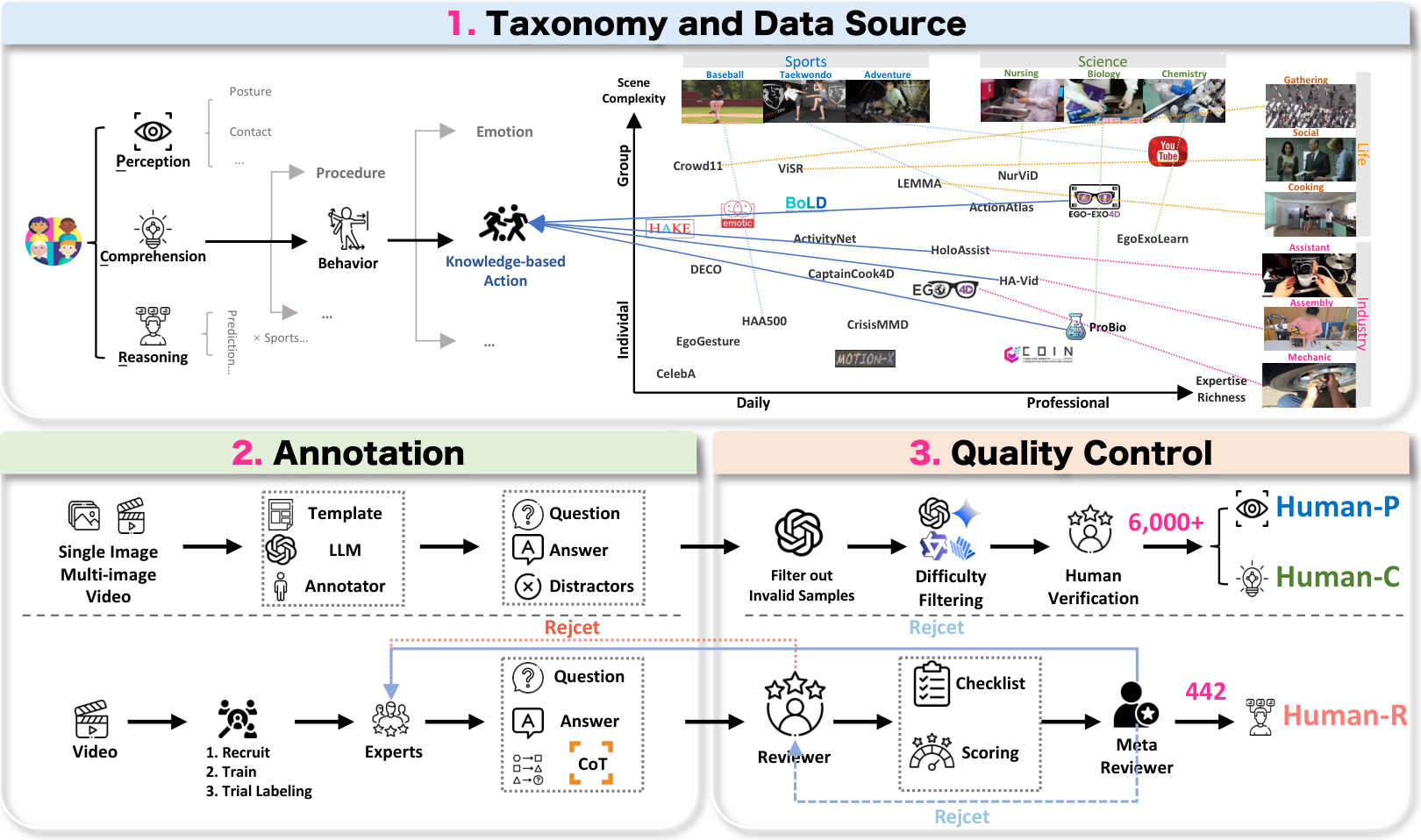
3.2 HumanPCR 的构建
正如图3所示,HumanPCR 的构建遵循一个详细的三阶段流程,包括任务驱动的数据收集(第3.2.1节)、适应性级别的问答标注(第3.2.2节)以及严格的多阶段质量控制过程(第3.2.3节)。源数据集的详细信息在附录B中提供,标注和审查协议在附录C中描述。
3.2.1 任务定义与数据收集协议
我们采用任务驱动的数据收集方法,数据来源于多样化的精选数据集和互联网视频,如图3的上方面板所示。对于 Human-P 和 Human-C,任务设计和数据选择由系统性调查指导。现有的人类中心数据源涵盖多个领域和不同的场景复杂度,通过对相似任务进行整合并提取独特方面作为独立任务进行重组。这使我们能够策划一组多样化的任务,每个任务都得到丰富且多样的数据集支持。对于 Human-R,视频来源于学术数据集和 YouTube 视频。YouTube 子集通过与领域相关的标签进行预过滤,然后在标注前进行人工审查,以确保内容的丰富性和安全性。
3.2.2 问答标注协议
Human-P 和 Human-C:得益于数据收集,我们通过利用现有数据集的标注,高效地扩展了问答对的数量,同时不影响数据质量或多样性。如图3的左下方面板所示,基于数据集标注,结合任务特定的模板和基于大语言模型(LLM)的生成方法,共同创建问题和选项。此外,为了解决现有数据集中未充分探索的任务,我们通过引入特定领域的专家标注者,手动生成额外的问答对和补充标注。
Human-R:从每个源领域招募专家,根据详细的指导方针,标注涵盖五种不同推理类型的问题:因果推理、预测、反事实推理、评估和规划。专家被要求创建具有直接答案的问题,并明确列出涉及的推理步骤。标注者还被允许灵活选择与每个问题相关的视频片段,从而增强上下文多样性,并确保挑战基于真实的视频情境。他们还可以从审查阶段获得在线反馈,并有一次修改提交内容的机会。如果修改后的提交仍未达到要求,则该标注将被丢弃。
4.1 评估设置
模型:在 HumanPCR 数据集上,我们对支持视频和图像输入的多种最先进的 MLLM(多模态大语言模型)进行了基准测试。具体来说,我们评估了九个专有模型,其中包括 Gemini-2.5-Flash 30 和 o4-mini 31j。我们还评估了 30 个具有代表性的开源 MLLM,特别是 Qwen-VL 系列 5, 6 和 InternVL 系列 54, 51。在 Human-R 数据集上,我们进一步纳入了最近在视频理解方面取得进展的方法,特别是在上下文提取和增强推理方面 50, 64。此外,还包括专为在严格速率限制下进行推理设计的专有模型,如 o3 31 和 Gemini-2.5-Pro 30。
提示策略与帧采样:除非另有说明,我们对多选题采用直接回答(Direct Answer)提示策略,对开放性问题采用思维链(Chain-of-Thought, CoT)提示策略。对于基于视频的问题,我们对多选题统一采样 32 帧,而对于开放性问题,我们通过输入每个模型上下文窗口和我们计算资源允许的最大帧数来最大化帧的利用率。所评估 MLLM 的详细配置见附录 D。
评估指标:对于多选题,通过将回答与正确选项匹配来测量准确率。我们报告每个任务的平均准确率,以及每个维度或级别的任务宏观平均准确率。遵循之前的基准测试 83, 33, 81,我们使用一个快速的专有模型 o3-mini 102 作为开放性问题的评判者。通过比较提取的最终答案与真实答案来评估回答的正确性。更多评估细节见附录 D。
4.2 主要结果
表2展示了在HumanPCR上三个层面的主要评估结果。我们的主要发现总结如下。
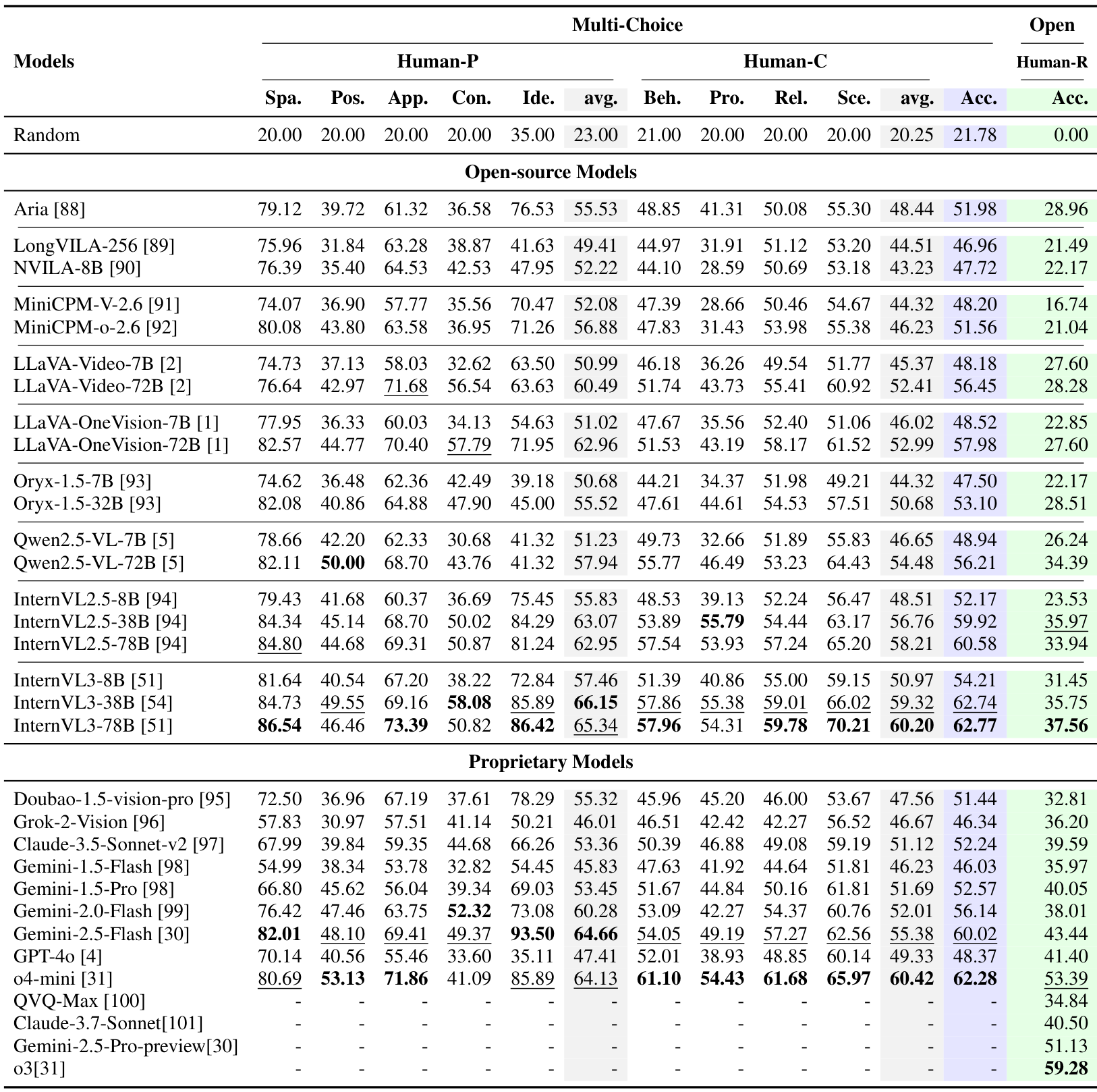
当前的多模态大语言模型(MLLMs)在以人为中心的视觉理解方面仍存在显著局限性。如表2所示,HumanPCR中的任务对当前模型来说大多尚未解决。大多数模型在Human-P和Human-C上的准确率低于60%。领先模型如04-mini和InternVL3-78B的总体准确率分别为64.56%和63.66%,但仍显示出特定的弱点,例如InternVL3-78B在姿势(Posture)方面的表现较差,而o4-mini在接触(Contact)方面表现不佳。在Human-R上,o4-mini取得了最高的准确率58.60%,而其他大多数模型的准确率低于40%。这些结果凸显了在现实世界中以人为中心的视觉理解方面的重大挑战,并强调了HumanPCR的贡献。
开源模型在感知和理解方面与专有模型不相上下,但在推理方面落后。在Human-P和Human-C上,开源模型与专有模型的表现相当。值得注意的是,InternVL3-78B甚至超过了顶级专有模型o4-mini。然而,在推理方面,它们的表现不佳------大多数模型在Human-R上的准确率低于30%,而所有专有模型均超过这一数值。像o4-mini和Gemini-2.5-Flash这样的模型展示了专有设计在推理方面的优势。虽然开源模型在感知和理解上与专有模型相当,但它们在涉及复杂视觉证据的推理任务上表现挣扎。
理解以人为中心的场景反映了一般能力。从所有维度的结果来看,姿势(Posture)、接触(Contact)、行为(Behavior)、程序(Procedure)和推理方面的持续弱点表现明显,准确率均在50%左右或以下。初步观察表明,这些结果指向了细粒度感知和空间性方面的缺陷,特别是在识别遮挡下的身体部位和接触区域时,这与之前的发现一致。行为和程序方面的较差结果进一步暴露了时间理解和心智建模方面的局限性,这两者对于解释人类活动和长期事件至关重要。总体而言,HumanPCR中的挑战不仅揭示了以人为中心的差距,也暴露了当前MLLMs的一般不足。
4.3 进一步分析
为了更深入地理解前沿模型的能力和局限性,我们进行了全面分析,重点关注影响 HumanPCR 性能的关键因素。
模型规模的影响
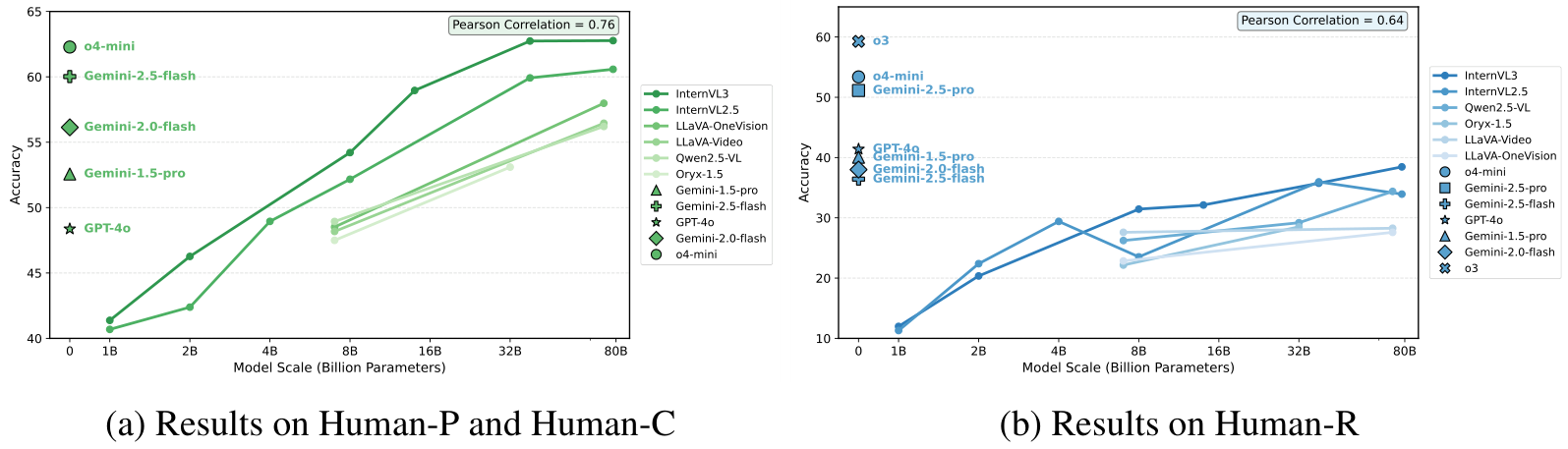
在表 2 中,模型规模的扩展在 MLLMs 系列的各种模型尺寸中持续提高了准确性。如图 6 所示,InternVL2.5 和 InternVL3 的性能表明,复杂的推理任务对模型规模的扩展更为敏感,规模增加带来了稳定的改进。然而,在 Human-P 和 Human-C 上的性能在大约 38B 参数后趋于平稳。我们推测,复杂任务更能有效评估模型的基本能力,如世界知识和逻辑推理。
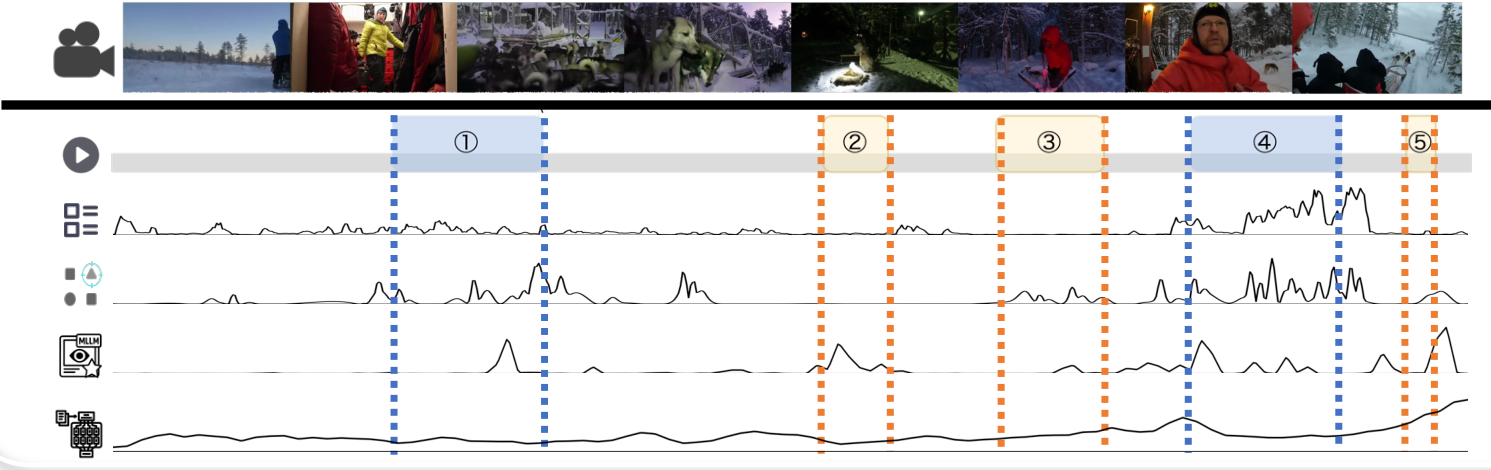
帧采样的影响
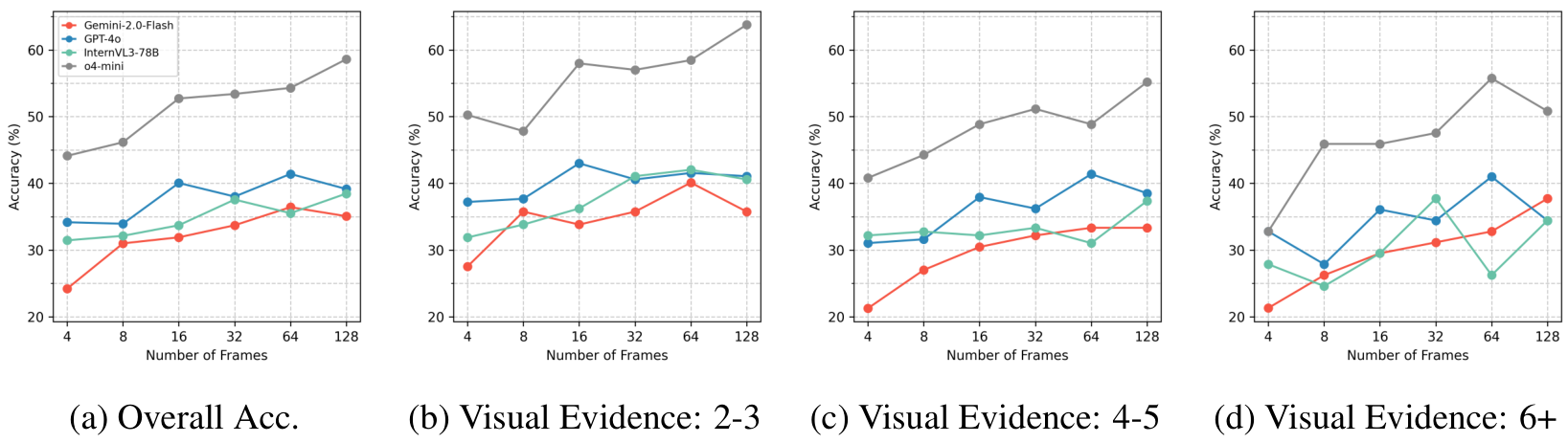
如图 8 所示,帧采样对 Human-R 的影响:(a) 总体准确性;(b-d) 按问题所需视觉证据数量分组的准确性:(b) 2-3 个证据,© 4-5 个证据,(d) 6 个或更多证据。增加帧数的影响因视觉复杂性而异。
混合 CoT 对模型和任务的影响
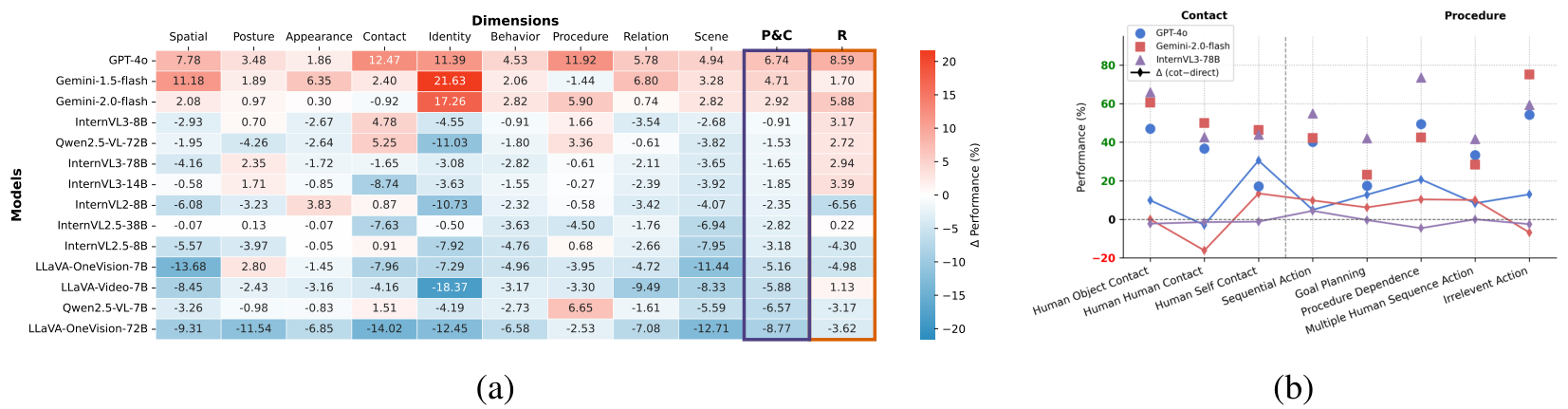
如图 7a 所示,CoT 提示的有效性在不同模型和评估维度上呈现出不同的模式。具体而言,CoT 持续提升了专有模型(如 GPT-4o 和 Gemini-2.0-Flash)的性能,而对开源模型的性能往往产生负面影响。此外,CoT 的益处与维度相关,改进更多集中在需要详细感知或整合多个视觉证据的复杂任务上。图 7b 显示了任务特定准确性和 CoT 改进的显著差异。这一观察结果突显了我们分类法的非冗余性,并强调了评估多样化任务的必要性,而不仅仅是粗粒度的类别。
4.4 深入探讨基于多证据的视觉推理
基于 Human-R,我们对领先的开源和专有 MLLM(多模态大语言模型)进行了全面分析,以深入了解其推理能力的特点和局限性。
帧数缩放对多证据推理的影响
在图 8 中,我们研究了模型在不同帧数下的表现,并根据视觉证据的数量对结果进行分组。主要观察如下:
- 帧数并非瓶颈。增加帧数并不会显著提高推理准确性,这表明 Human-R 的挑战超出了简单的时序证据检索。
- 视觉证据增加会加剧挑战。随着所需视觉证据数量的增加,准确性下降。对于需要 6 个以上证据的问题,增加帧数后性能趋于饱和甚至恶化。我们推测,多重视觉证据的需求使得额外的上下文无效,同时增加了复杂性,阻碍了证据提取,并干扰模型的注意力。
先进的视频理解配置是否有帮助?
我们评估了 MLLM 在先进视频理解配置下的表现,包括解决视觉冗余的上下文提取 49 和测试时计算扩展 45, 32。主要发现如下:
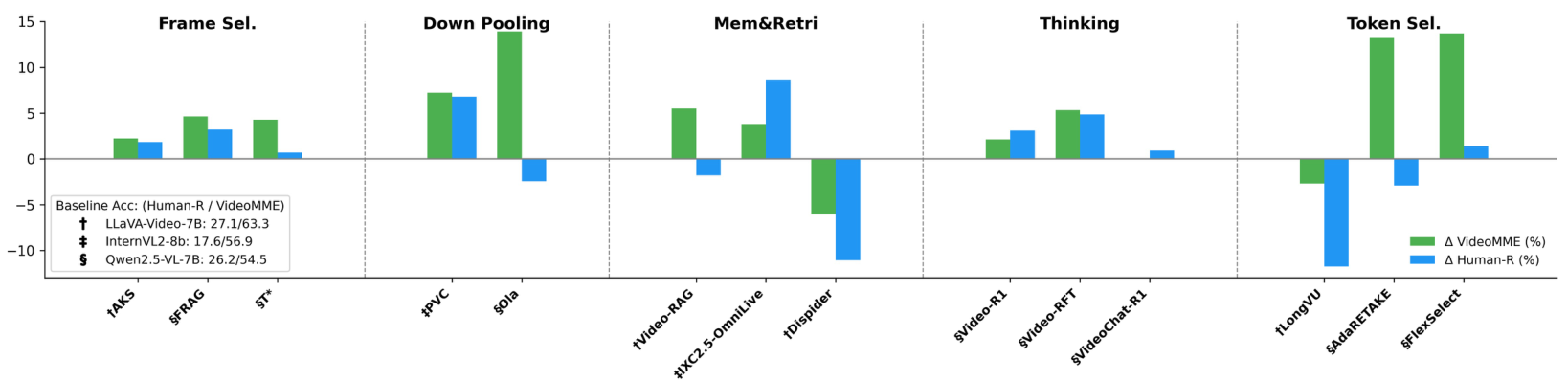
- 视觉上下文提取。图 9 比较了上下文提取方法与 Human-R 和 Video-MME 上的均匀采样基线。在 Video-MME 上验证的大多数方法在 Human-R 上仅获得边际或负收益。特别是,token 选择和基于记忆的检索策略在这两个数据集上的性能差距明显,而帧选择和池化方法则带来了持续的改进。我们认为,token 和检索方法依赖于文本引导的 token 级过滤,容易错过问题未提及的主动证据,而帧级选择和池化方法则更为稳健。这表明 Human-R 无法完全通过查询引导或启发式方法解决,为视频推理提出了新的挑战。
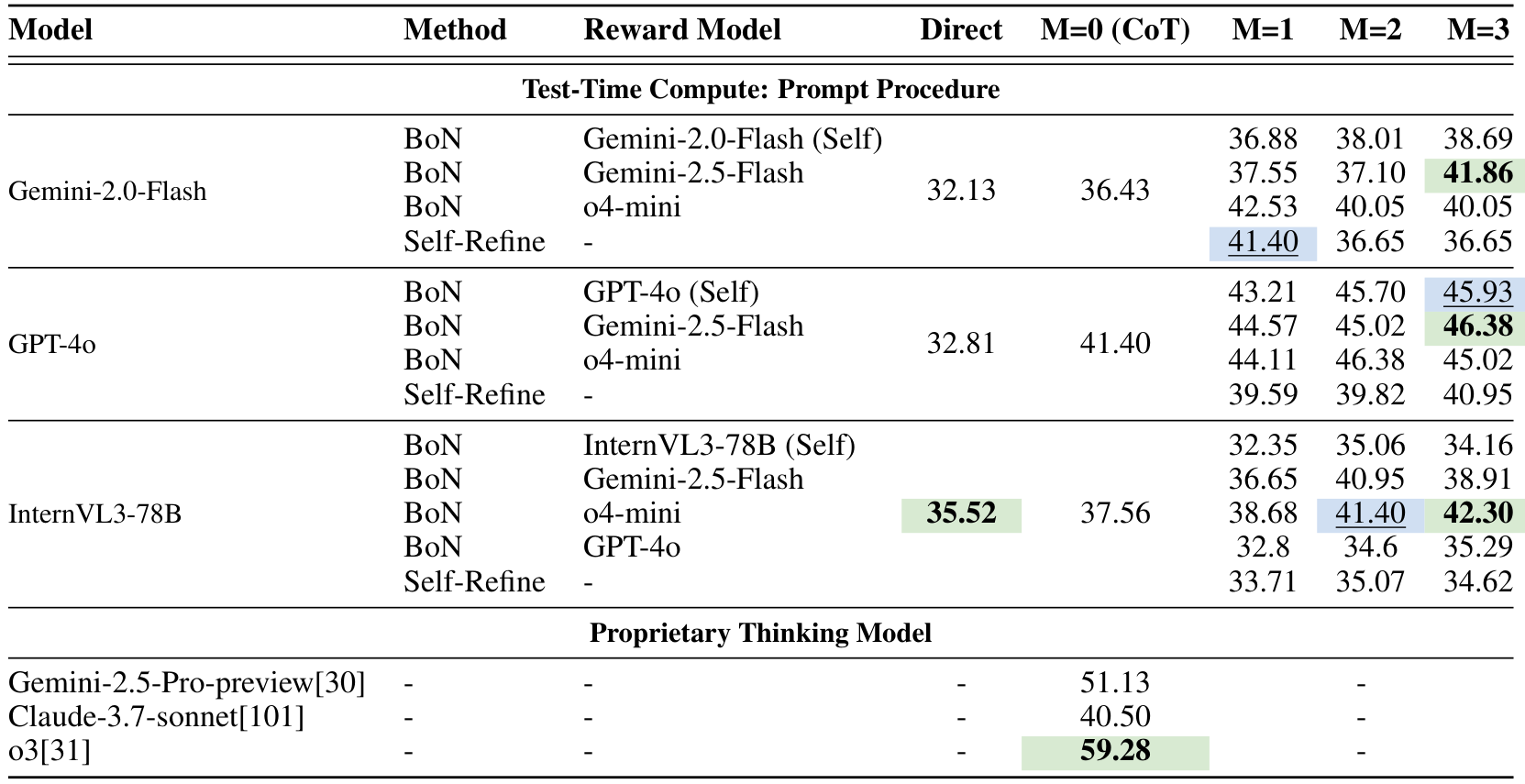
- 推理时的测试时计算。图 9 和表 3 显示了超越普通 CoT(Chain of Thought)的测试时扩展策略的效果。Best-of-N (BoN) 在所有三个模型上均带来了超过 5% 的提升,且随着更强的奖励模型或更多候选者的加入,性能逐步提高。Self-Refine 仅提供边际收益,且随着迭代次数增加性能下降。开源思维模型 Video-R1 使基线提高了 3.07%,而专有模型 o3 达到了最佳性能 59.28%,与其他模型有较大差距。总体而言,测试时扩展策略通常是有效的。
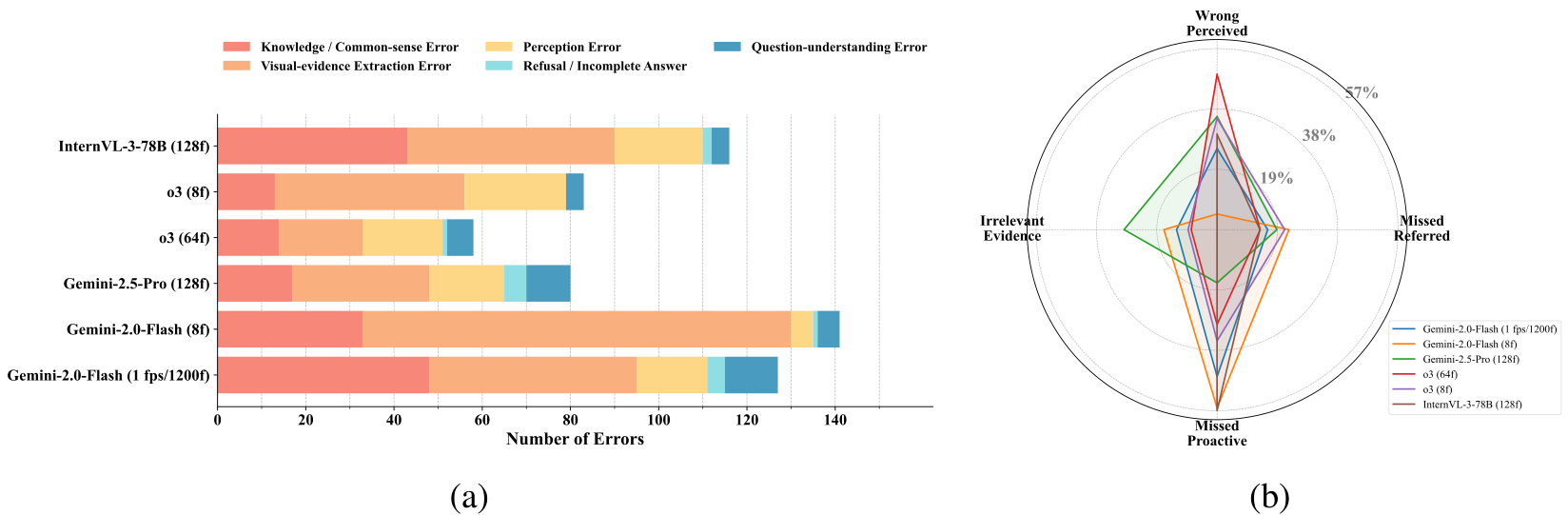
错误分析
如图 10a 所示,我们分析了 200 个随机采样的问题,并将表现最好的模型所犯错误分类为五个类别:知识/常识错误、视觉证据提取错误、感知错误、拒绝/不完整回答以及问题理解错误。此外,视觉证据提取错误进一步细分为三个子类型。连同感知错误,四种视觉相关错误如图 10b 所示。
- 视觉证据提取错误占主导地位,尤其是错过问题中未提及的主动证据,即使通过扩展上下文也难以解决(例如,o3 和 Gemini-2.5-Pro 在较少帧数下表现优于 Gemini-2.0-Flash 在 1200 帧下的表现)。
- 模型严重依赖查询引导的检索,因为问题中提到的证据较少被错过,而对主动上下文的理解仍然较弱。
- 不同模型表现出不同的提取倾向,例如 Gemini-2.5-Pro 减少了主动证据的遗漏,但相比 o3 引入了更多无关证据。
这些结果表明,当前 MLLM 在视频推理中的瓶颈不在于事实知识的差距,而在于无法全面建模和提取超出问题线索的相关信息------这是以往评估中很大程度上被忽视的关键方面。
5 结论 5
我们提出了 HumanPCR,这是一个全面的多层次基准测试,旨在严格评估多模态大型语言模型(MLLMs)在多样化现实世界场景中理解人类的能力。该基准测试具有来自混合来源的系统化、细粒度分类法,以及一个以整合多重视觉证据为核心的具有挑战性的视频推理测试。HumanPCR 揭示了持续存在的挑战,特别是在详细感知、时间理解和复杂推理方面。MLLMs 往往无法在推理中主动提取关键视觉证据,而是依赖于查询引导的检索,并且通过扩展视觉上下文或测试时配置获得的收益有限。因此,HumanPCR 为诊断差距和推进强大的人类级多模态理解奠定了基础。HumanPCR 目前的局限性包括在感知和理解层面依赖学术数据集,以及在推理方面使用基于 LLM 的度量标准。为了解决这些问题,我们计划在未来工作中扩展到更多专业领域,并开发保留推理难度的客观评估协议。
Original Abstract: The aspiration for artificial general intelligence, fueled by the rapid
progress of multimodal models, demands human-comparable performance across
diverse environments. We propose HumanPCR, an evaluation suite for probing
MLLMs' capacity about human-related visual contexts across three hierarchical
levels: Perception, Comprehension, and Reasoning (denoted by Human-P, Human-C,
and Human-R, respectively). Human-P and Human-C feature over 6,000
human-verified multiple choice questions, assessing massive tasks of 9
dimensions, including but not limited to essential skills frequently overlooked
by existing benchmarks. Human-R offers a challenging manually curated video
reasoning test that requires integrating multiple visual evidences, proactively
extracting context beyond question cues, and applying human-like expertise.
Each question includes human-annotated Chain-of-Thought (CoT) rationales with
key visual evidence to support further research. Extensive evaluations on over
30 state-of-the-art models exhibit significant challenges in human-centric
visual understanding, particularly in tasks involving detailed space
perception, temporal understanding, and mind modeling. Moreover, analysis of
Human-R reveals the struggle of models in extracting essential proactive visual
evidence from diverse human scenes and their faulty reliance on query-guided
retrieval. Even with advanced techniques like scaling visual contexts and
test-time thinking yield only limited benefits. We hope HumanPCR and our
findings will advance the development, evaluation, and human-centric
application of multimodal models.
PDF Link: 2508.13692v1
部分平台可能图片显示异常,请以我的博客内容为准
