📚 DeepSeek系列文章
尽管大语言模型已经具备了强大的语言生成能力,但它们在推理(reasoning)任务上仍有明显不足。预训练数据中缺乏结构化推理的明确信号,导致模型难以习得连贯、逻辑严谨的思维链条。
为此,DeepSeek 团队提出了新的范式:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning。该工作以 DeepSeek-V3 为基座,通过强化学习(RL)方式对模型推理能力进行定向优化,在多个基准推理任务上取得显著提升。
建议带着以下三个问题阅读本文:
- 为什么需要用强化学习来提升推理能力,而不是继续做监督微调?
- DeepSeek-R1 是如何构建奖励函数来鼓励"更好推理"的?
- 相比常规 RLHF 微调,DeepSeek-R1 的训练流程有哪些新颖设计?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、出发点:从通用语言理解到精准推理
基础语言模型虽然对语言建模表现出色,但在处理逻辑推理、数学计算、多跳问答等任务时,往往缺乏稳定性和连贯性。
这主要源于两个因素:
- 监督数据难以全面覆盖复杂推理流程
- 预训练损失(如 cross-entropy)不会显式惩罚"逻辑错误"
为此,DeepSeek-R1 引入强化学习机制,以推理能力为优化目标,在原始模型基础上进一步"对齐"。
二、强化学习驱动的训练范式
DeepSeek-R1 在整体上分为两个阶段:
冷启动策略(Bootstrapping)
为了防止 RL 初期探索过度震荡,先使用一个 生成式评分器(Reward Model) 对推理质量进行打分,并通过 supervised fine-tuning(SFT)微调模型。
强化学习微调(RL Fine-tuning)
正式进入强化学习阶段:
- 使用 PPO(Proximal Policy Optimization)作为优化算法;
- 模型输出多个 reasoning chain(思维链);
- 每个输出根据 reward model 获得得分,作为 PPO 的训练信号;
- 目标是最大化"高质量推理路径"的概率。
三、奖励函数设计:如何"定义好推理"?
DeepSeek-R1 并非只看最终答案对错,而是从推理路径的质量入手评估:
| 奖励维度 | 说明 |
|---|---|
| 答案正确性 | 最终答案是否准确 |
| 逻辑一致性 | 中间步骤是否存在前后矛盾 |
| 语言可读性 | 推理链是否通顺自然 |
| 步骤合理性 | 每一步推理是否有意义、有因果 |
构建这些奖励的核心,是一个基于 DeepSeek-V3 的 reward model,对输出进行多维打分。
四、多阶段训练流程的价值
相比常规 RLHF(如 InstructGPT 的三阶段训练:SFT + RM + PPO),DeepSeek-R1 的流程更加丰富:
- 收集并构造 思维链数据集(chain-of-thought)
- 微调 reward model,学习如何"评判推理好坏"
- 使用 reward model 过滤或打分初始样本(Bootstrapping)
- 再通过 PPO 强化学习,反复优化 reasoning policy
这种"预训练 → SFT → RM → RL"的闭环流程,更像是在模拟一个会教推理的老师。
五、效果评估:推理任务性能全面突破
在多个标准推理基准上,DeepSeek-R1 明显优于同尺寸开源模型:
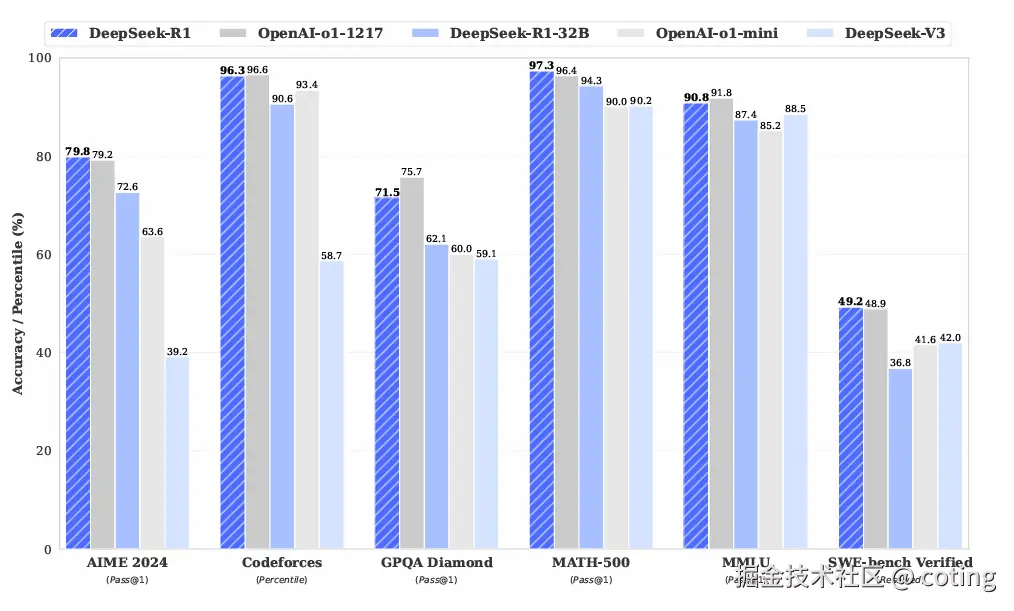
此外,推理输出的可读性与连贯性也显著提升,有效解决了"对是对,但中间步骤全乱写"的问题。
📌 结语
DeepSeek-R1 展示了一个新方向:不仅要对齐输出内容,更要对齐模型的思维过程。通过强化学习对 reasoning path 的激励优化,它为开源模型打开了一条推理能力快速跃升的路径。
对于希望将大模型用于复杂决策、数学推导、工具调用等场景的开发者而言,DeepSeek-R1 提供了极具参考价值的实践范式。
最后我们回答一下文章开头提出的三个问题:
1. 为什么强化学习是提升推理能力的有效方式?
因为预训练和监督微调更关注语言流畅性,而 RL 可以"奖励正确推理路径",让模型从试错中学习更强的逻辑能力。
2. DeepSeek-R1 如何构建奖励函数来优化推理?
通过训练 reward model,从答案准确性、逻辑一致性、语言清晰度等维度综合评估 reasoning chain,并将得分作为强化学习的优化目标。
3. 与传统 RLHF 有何不同?
DeepSeek-R1 增加了冷启动、奖励引导、CoT 评分等机制,强化对"中间推理路径"的关注,构建出更精细化的推理训练流程。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!