导读:
本研究基于BERT模型与DeepSeek大模型,构建了一个智能舆情监测系统。该系统总体架构分为数据采集层、情感分析层、可视化交互层和智能报告层,技术实现上融合了微调BERT模型、Tkinter图形界面以及多源API集成。数据流程涵盖从光明网、Coze等多平台舆情信息采集,到基于公司金融领域微调BERT模型的情感自动标注,再到多维度数据可视化与DeepSeek生成的智能舆情分析报告。系统功能集成舆情动态抓取、情感分类、可视化展示与报告生成四大模块,实现了从数据获取到决策建议的全流程自动化。该系统的建设为舆情监控与风险应对提供了基于深度学习的智能支持,有助于提升企业对突发舆情的响应速度与决策科学性。
作者信息:
韦玉荣*, 刘小满#, 熊圣昊, 吴 桢:广西民族师范学院数学与计算机科学学院,广西 崇左
论文详情
数据采集模块
爬取的网站:光明网;采用基于Selenium的自动化数据爬取技术;在Coze中设置爬取各方网址的新闻工作流如上图1所示。
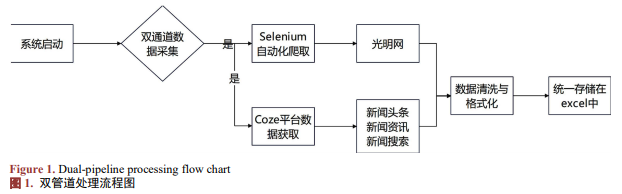
系统通过两个渠道进行采集舆情数据,将光明网和Coze平台获取的新闻内容、来源及时间等关键信息统一整合至DataFrame数据结构中,并最终导出为Excel文件(如表1)。均能稳定获取舆情监测所需的核心字段(内容、来源、时间),完全满足目前的舆情监控工作的基础需求。爬取的新闻数据可以自主地选择下载的路径。

情感分析模块
该数据集来源于飞桨AI Studio平台的公开情感分析语料库,已由平台进行了初步的情感标注。尽管源数据集已包含基础的情感标注,为确保标注质量的可靠性及其与本研究任务的一致性,执行系统的质量控制。经过质量检验后的最终数据集统计特征如下表2所示。

原始社交媒体文本包含大量噪声,必须经过严格的清洗和标准化流程才能用于模型训练。我们采用了多步骤预处理,经过预处理后,我们得到了一个包含约3.1万条的评论文本的数据集。所有样本被按72%:8%:20%的比例随机划分为。
本研究采用"bert-base-Chinese"版本作为基础预训练模型 (由Google Research发布)。
处理完成之后进行数据的标签映射将中文情感标签("积极"、"中性"、"消极")映射为数字标签(0, 1, 2)。针对金融舆情数据中常见的类别不平衡问题(本数据集分布约为54%:24%:22%),采用了代价敏感学习策略,自动计算类别权重,在训练过程中赋予少数类别更高的损失权重,从而迫使模型更加关注难以分类的样本,缓解模型偏见。
为确保预训练BERT模型在金融舆情情感分析任务上的最优性能,本研究通过多轮实验确定了关键超参数的配置。具体流程见图2。
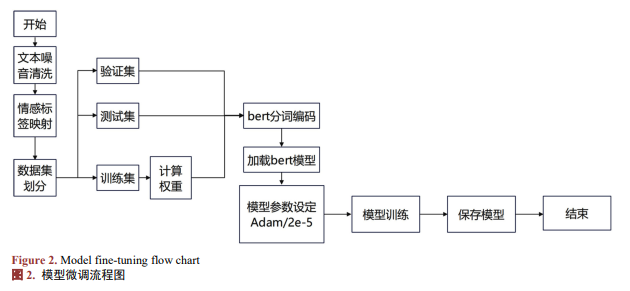
最终测试集上的79.76%准确率与验证集性能高度一致,证明了模型的良好泛化能力。
舆情分析及报告下载功能
在可视化分析中我们采用了基本的饼图和堆积柱形图,进行数据的统计计算占比以及展现排名。词云图能够直观地展示新闻报道中的高频词汇,帮助读者快速捕捉到当前热点话题或事件的核心内容。
舆情分析报告导出功能通过自动化技术将复杂的舆论数据转化为结构化报告,帮助用户快速掌握舆论趋势。通过自定义分析需求、自动化数据处理和AI智能生成,系统实现了高效、精准的舆情分析。报告采用标准化Markdown格式和时间戳命名,确保内容清晰且可追溯。
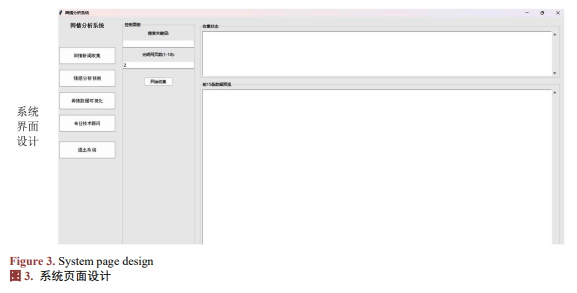
系统页面设计
系统页面设计如下图3。
结语
首先,项目开发了动态交互式可视化系统,通过情感卡片流、实时词云还有多维统计图表,直观查看到了舆情分布态势,大幅提升了数据可解释性;其次,针对舆情特点对BERT模型进行公司领域的微调,引入公司领域语料和优化损失函数,提升情感分类准确率;最后,创造性接入DeepSeek大模型还有Coze平台,构建了AI驱动的智能报告生成模块,能够自动产出包含趋势分析、风险预警和应对建议的结构化报告,将传统人工分析8小时的工作量压缩至3分钟内完成。这三个创新点形成"数据可视化--智能分析--决策支持"的完整技术闭环,既体现了对深度学习前沿技术的应用,又充分考虑了实际业务场景的需求,为舆情监测领域提供了可落地的智能化解决方案。
原文链接: