基于Flask的微博舆情数据分析系统 - 技术实现与架构设计
本文详细介绍了一个基于Flask框架开发的微博舆情数据分析系统,包含数据爬取、情感分析、可视化展示等完整功能模块。
📋 目录
- 项目概述
- 技术栈
- 系统架构
- 目录结构
- 核心功能模块
- 代码实现
- 数据可视化
- 部署与运行
- 项目特色
- 技术难点与解决方案
- 总结与展望
- 联系方式
🎯 项目概述
本项目是一个基于Flask框架开发的微博舆情数据分析系统,主要功能包括:
- 数据采集:自动化爬取微博文章、评论、导航数据
- 情感分析:基于机器学习的情感倾向分析
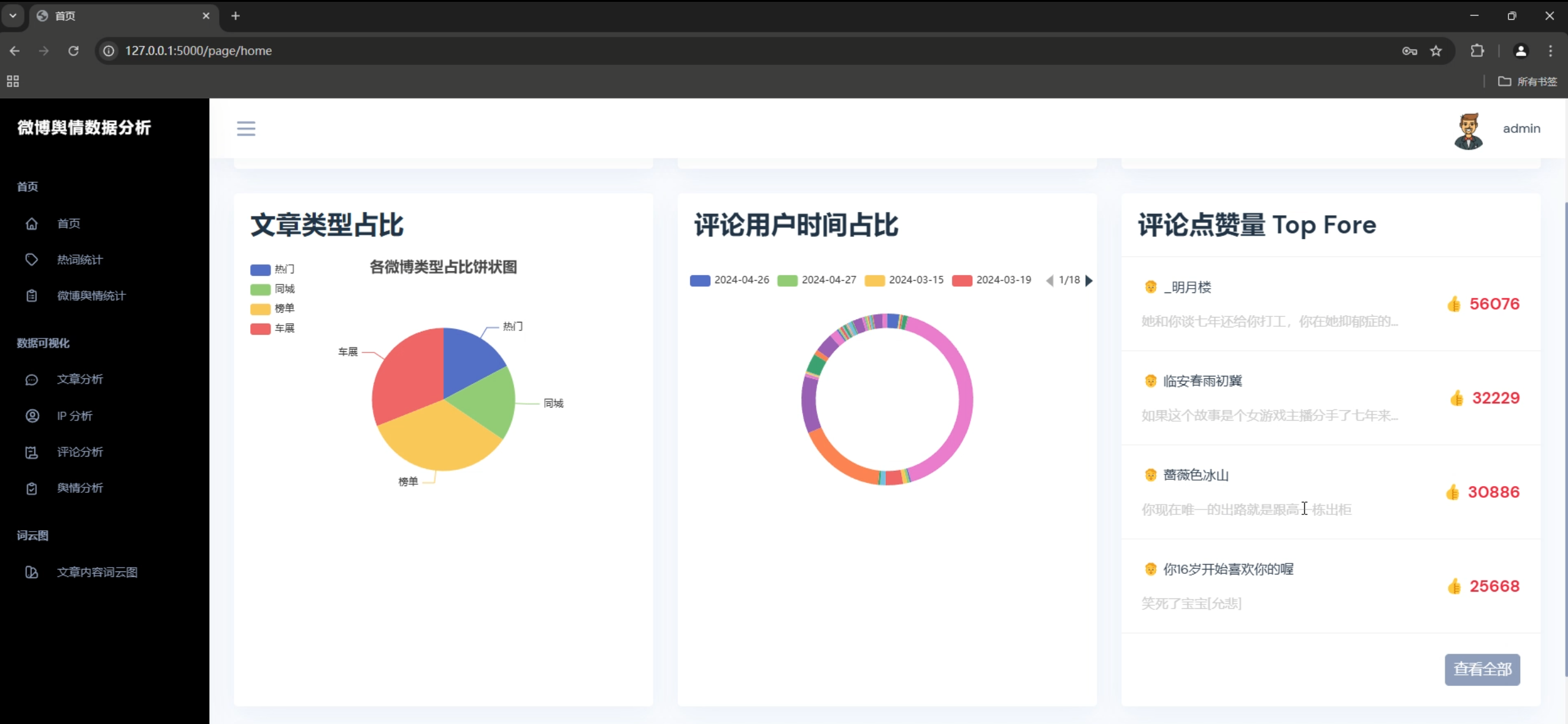
- 数据可视化:多种图表展示分析结果
- 用户管理:完整的用户注册登录系统
- 响应式界面:现代化的Web界面设计
系统采用前后端分离的架构设计,后端提供RESTful API,前端使用现代化的HTML5+CSS3+JavaScript技术栈,为用户提供直观、高效的数据分析体验。
项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!
项目演示
🐦🔥 项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!
基于Python的微博舆情可视化分析系统

🛠️ 技术栈
后端技术
- Web框架: Flask 2.0.3
- 数据库: MySQL + SQLAlchemy 1.4.49
- 数据处理: Pandas 1.1.5, NumPy 1.19.5
- 机器学习: Scikit-learn 1.4.2
- 中文分词: jieba 0.42.1
- 情感分析: SnowNLP 0.12.3
- 数据可视化: Matplotlib 3.3.4, WordCloud 1.9.2
- HTTP请求: Requests 2.25.1
- 图像处理: Pillow 10.3.0
前端技术
- HTML5: 语义化标签,响应式设计
- CSS3: 现代化样式,动画效果
- JavaScript: ES6+语法,模块化开发
- 图表库: ECharts 数据可视化
- UI框架: 自定义CSS框架
- 响应式: 移动端适配
开发工具
- 版本控制: Git
- 数据库管理: MySQL Workbench
- 代码编辑器: VS Code / PyCharm
- 浏览器: Chrome DevTools
🏗️ 系统架构
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 前端展示层 │ │ 业务逻辑层 │ │ 数据存储层 │
│ │ │ │ │ │
│ HTML/CSS/JS │◄──►│ Flask路由 │◄──►│ MySQL数据库 │
│ ECharts图表 │ │ 业务处理 │ │ CSV文件 │
│ 响应式界面 │ │ 数据验证 │ │ 模型文件 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 数据采集模块 │ │ 情感分析模块 │ │ 用户管理模块 │
│ │ │ │ │ │
│ 微博爬虫 │ │ ML模型训练 │ │ 认证授权 │
│ 数据清洗 │ │ 情感分类 │ │ 权限控制 │
│ 存储管理 │ │ 结果输出 │ │ 会话管理 │
└─────────────────┘ └─────────────────┘ └─────────────────┘📁 目录结构
flask_weiboyuqing/
├── app.py # Flask应用主文件
├── requirements.txt # Python依赖包列表
├── design_173_wb.sql # 数据库设计文件
├── model/ # 机器学习模型模块
│ ├── cipingTotal.csv # 词频统计数据
│ ├── cipingTotal.py # 词频统计处理
│ ├── cutComments.py # 评论分词处理
│ ├── trainModel.py # 模型训练脚本
│ └── yuqing.py # 舆情分析核心
├── spider/ # 数据爬取模块
│ ├── main.py # 爬虫主程序
│ ├── spiderComments.py # 评论爬取
│ ├── spiderContent.py # 内容爬取
│ ├── spiderNav.py # 导航数据爬取
│ └── *.csv # 爬取数据文件
├── static/ # 静态资源文件
│ ├── css/ # 样式文件
│ ├── js/ # JavaScript文件
│ ├── image/ # 图片资源
│ ├── font/ # 字体文件
│ └── picture/ # 页面图片
├── templates/ # HTML模板文件
│ ├── 404.html # 错误页面
│ └── error.html # 错误处理
├── utils/ # 工具函数模块
│ ├── errorResponse.py # 错误响应处理
│ ├── getEchartsData.py # ECharts数据生成
│ ├── getHomePageData.py # 首页数据获取
│ ├── getHotWordPageData.py # 热词页面数据
│ ├── getPublicData.py # 公共数据接口
│ ├── getTableData.py # 表格数据获取
│ └── query.py # 数据库查询
└── views/ # 视图模块
├── page/ # 页面视图
│ ├── page.py # 页面路由
│ └── templates/ # 页面模板
└── user/ # 用户管理视图
├── user.py # 用户相关路由
└── templates/ # 用户页面模板🔧 核心功能模块
1. 数据采集模块 (Spider)
数据采集模块负责从微博平台获取原始数据,包括文章内容、用户评论、导航信息等。
主要特性:
- 多线程并发爬取
- 反爬虫策略
- 数据清洗与预处理
- 增量更新机制
- 异常处理与重试
核心代码结构:
python
# spider/main.py
import requests
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
class WeiboSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
self.session = requests.Session()
def crawl_articles(self, urls):
"""爬取文章数据"""
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(self._fetch_article, urls))
return pd.DataFrame(results)
def _fetch_article(self, url):
"""获取单篇文章数据"""
try:
response = self.session.get(url, headers=self.headers)
# 数据解析逻辑
return self._parse_article(response.text)
except Exception as e:
print(f"爬取失败: {url}, 错误: {e}")
return None2. 情感分析模块 (Model)
情感分析模块使用机器学习技术对文本内容进行情感倾向分析。
技术实现:
- 基于SnowNLP的情感分析
- 自定义情感词典
- 机器学习模型训练
- 结果置信度评估
核心代码结构:
python
# model/yuqing.py
from snownlp import SnowNLP
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
class SentimentAnalyzer:
def __init__(self):
self.model = None
self.vectorizer = TfidfVectorizer()
self.load_model()
def analyze_sentiment(self, text):
"""分析文本情感倾向"""
# 文本预处理
processed_text = self._preprocess_text(text)
# 使用SnowNLP进行情感分析
s = SnowNLP(processed_text)
sentiment_score = s.sentiments
# 情感分类
if sentiment_score > 0.6:
return "正面", sentiment_score
elif sentiment_score < 0.4:
return "负面", sentiment_score
else:
return "中性", sentiment_score
def train_custom_model(self, training_data):
"""训练自定义情感分析模型"""
# 特征提取
X = self.vectorizer.fit_transform(training_data['text'])
y = training_data['label']
# 模型训练
self.model = MultinomialNB()
self.model.fit(X, y)
return self.model3. 数据可视化模块 (Utils)
数据可视化模块负责将分析结果以图表形式展示,提供直观的数据洞察。
支持的图表类型:
- 词云图 (WordCloud)
- 柱状图 (Bar Chart)
- 饼图 (Pie Chart)
- 折线图 (Line Chart)
- 地图可视化 (Map Visualization)
核心代码结构:
python
# utils/getEchartsData.py
import json
import pandas as pd
from collections import Counter
class ChartDataGenerator:
def __init__(self):
self.chart_types = ['bar', 'pie', 'line', 'wordcloud']
def generate_wordcloud_data(self, text_data):
"""生成词云图数据"""
# 分词统计
words = []
for text in text_data:
words.extend(jieba.cut(text))
# 词频统计
word_freq = Counter(words)
# 过滤停用词
stop_words = self._load_stop_words()
filtered_freq = {k: v for k, v in word_freq.items()
if k not in stop_words and len(k) > 1}
# 转换为ECharts格式
chart_data = [{'name': word, 'value': freq}
for word, freq in filtered_freq.most_common(100)]
return {
'type': 'wordcloud',
'data': chart_data
}
def generate_sentiment_chart(self, sentiment_data):
"""生成情感分析图表数据"""
sentiment_counts = sentiment_data['sentiment'].value_counts()
return {
'type': 'pie',
'data': [{'name': k, 'value': v} for k, v in sentiment_counts.items()],
'title': '情感分布分析'
}4. Web应用框架 (Flask)
Flask应用提供Web界面和API接口,实现前后端交互。
主要路由:
- 首页展示
- 数据查询接口
- 用户认证
- 图表数据接口
核心代码结构:
python
# app.py
from flask import Flask, render_template, jsonify, request
from flask_sqlalchemy import SQLAlchemy
from views.page.page import page_bp
from views.user.user import user_bp
app = Flask(__name__)
app.config['SECRET_KEY'] = 'your-secret-key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://user:password@localhost/weibo_db'
db = SQLAlchemy(db)
# 注册蓝图
app.register_blueprint(page_bp)
app.register_blueprint(user_bp)
@app.route('/api/data/<data_type>')
def get_data(data_type):
"""获取数据接口"""
try:
if data_type == 'sentiment':
data = get_sentiment_data()
elif data_type == 'wordcloud':
data = get_wordcloud_data()
else:
return jsonify({'error': '不支持的数据类型'}), 400
return jsonify({'success': True, 'data': data})
except Exception as e:
return jsonify({'error': str(e)}), 500
@app.errorhandler(404)
def not_found(error):
return render_template('404.html'), 404
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)📊 数据可视化
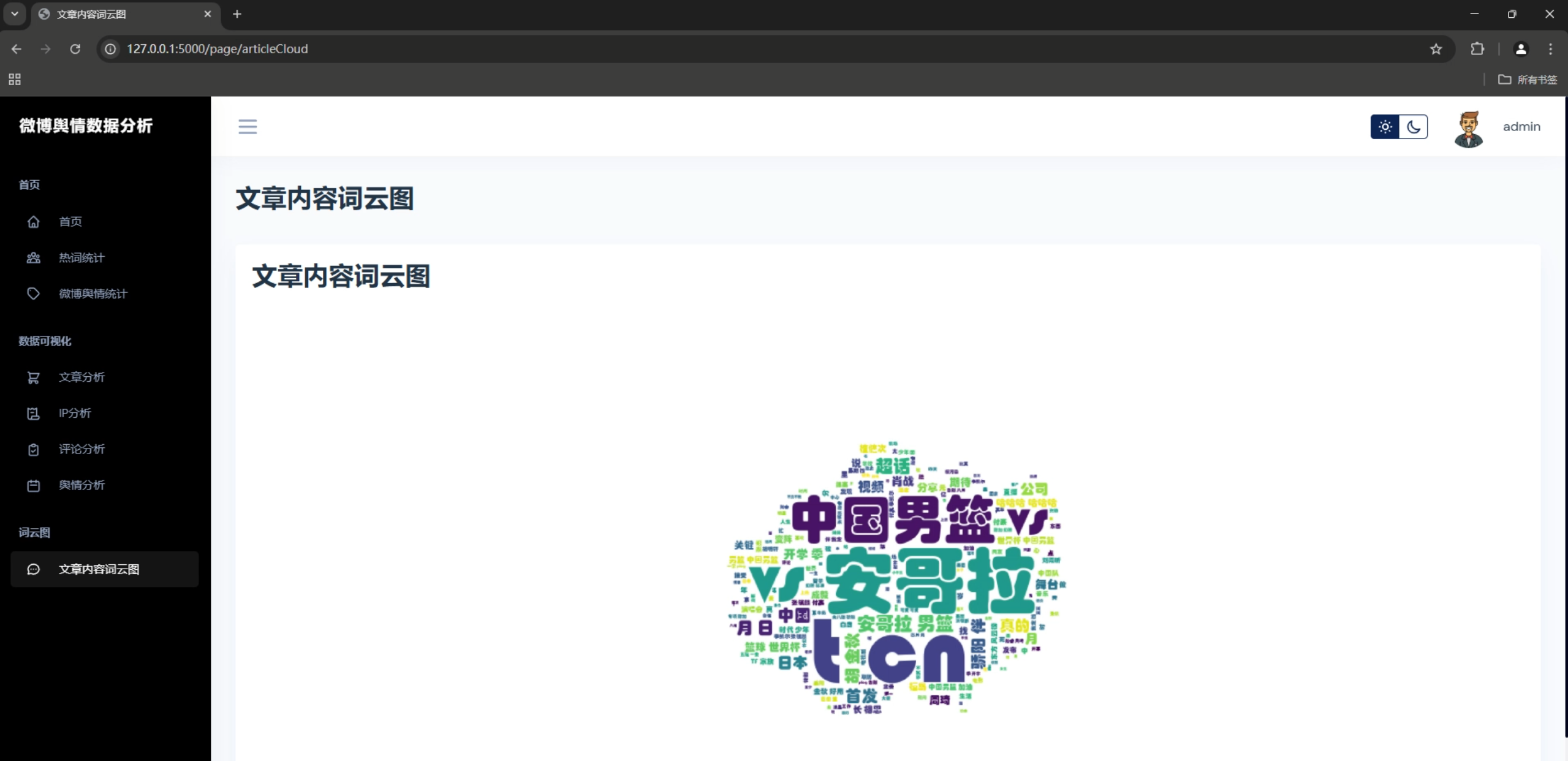
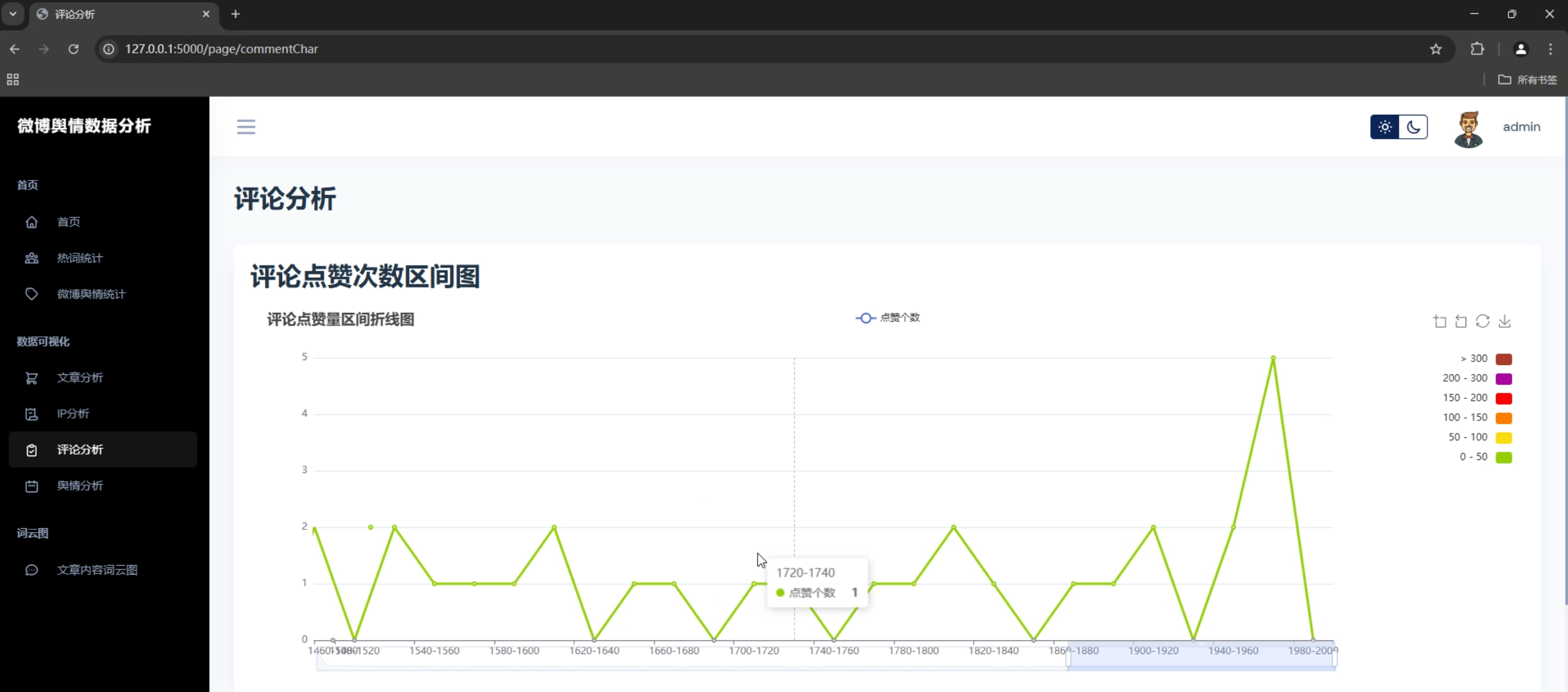
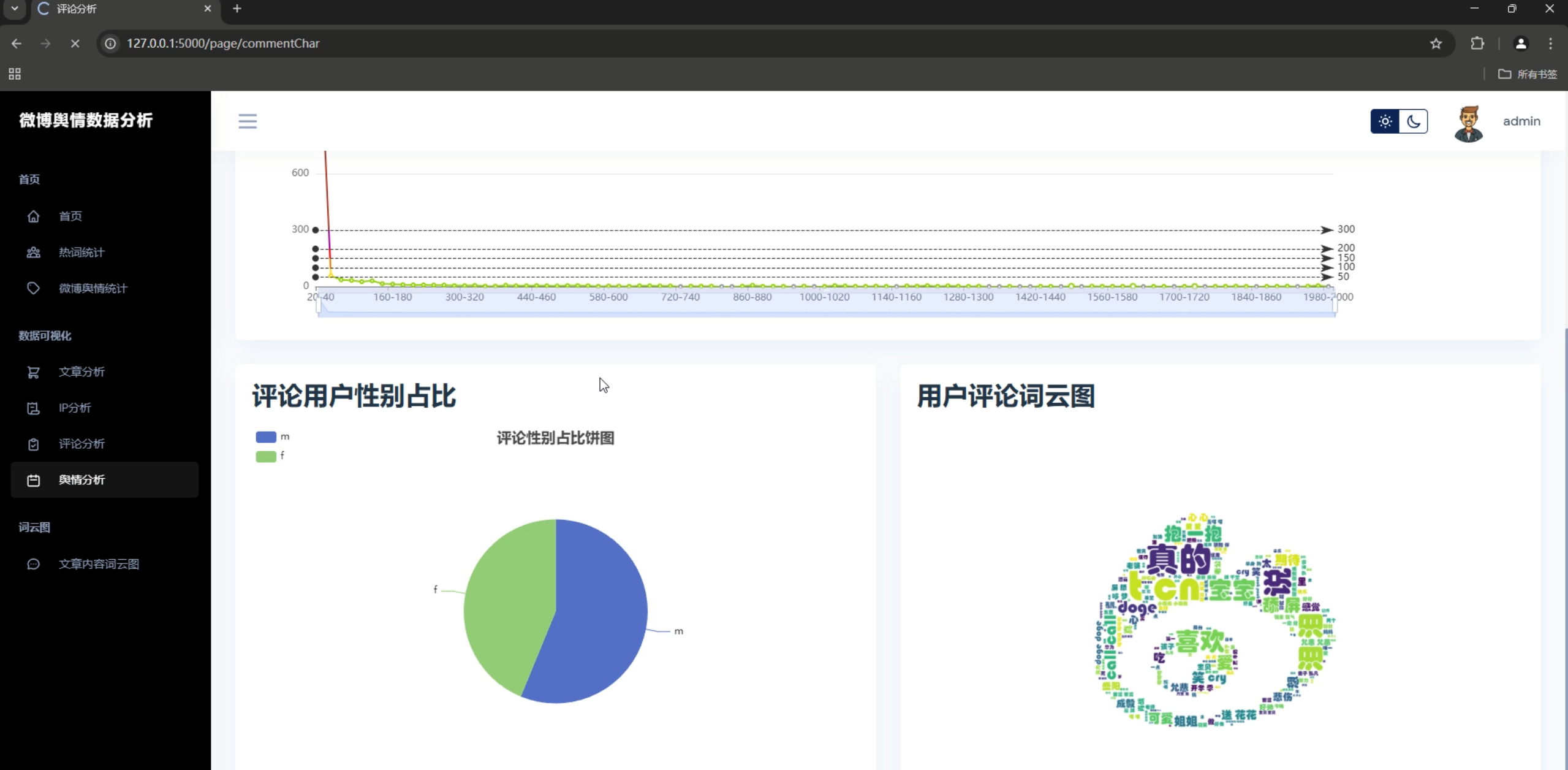
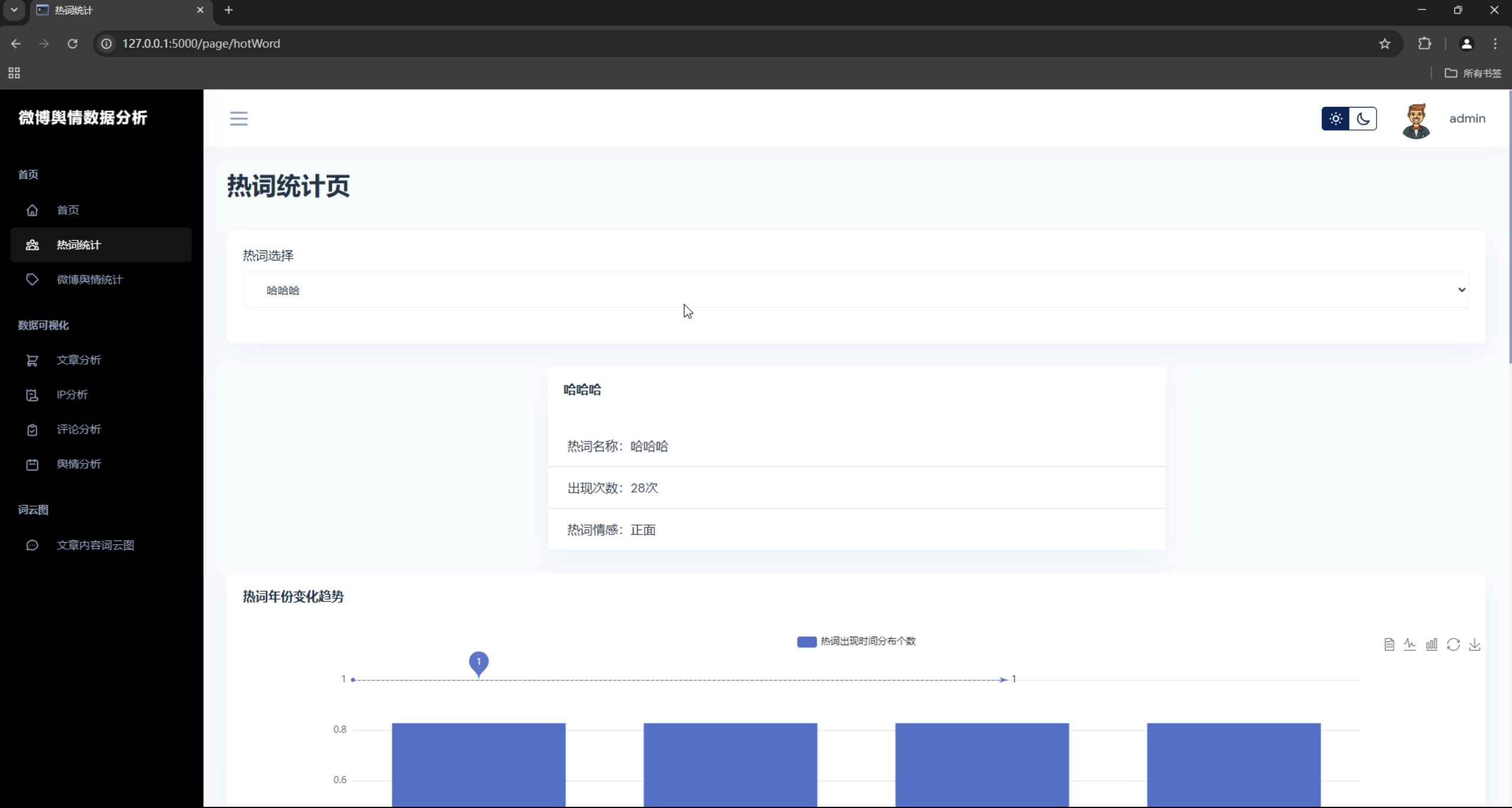
1. 词云展示
系统支持多种词云展示方式,包括:
- 文章内容词云
- 评论内容词云
- 用户名称词云
- 自定义关键词词云
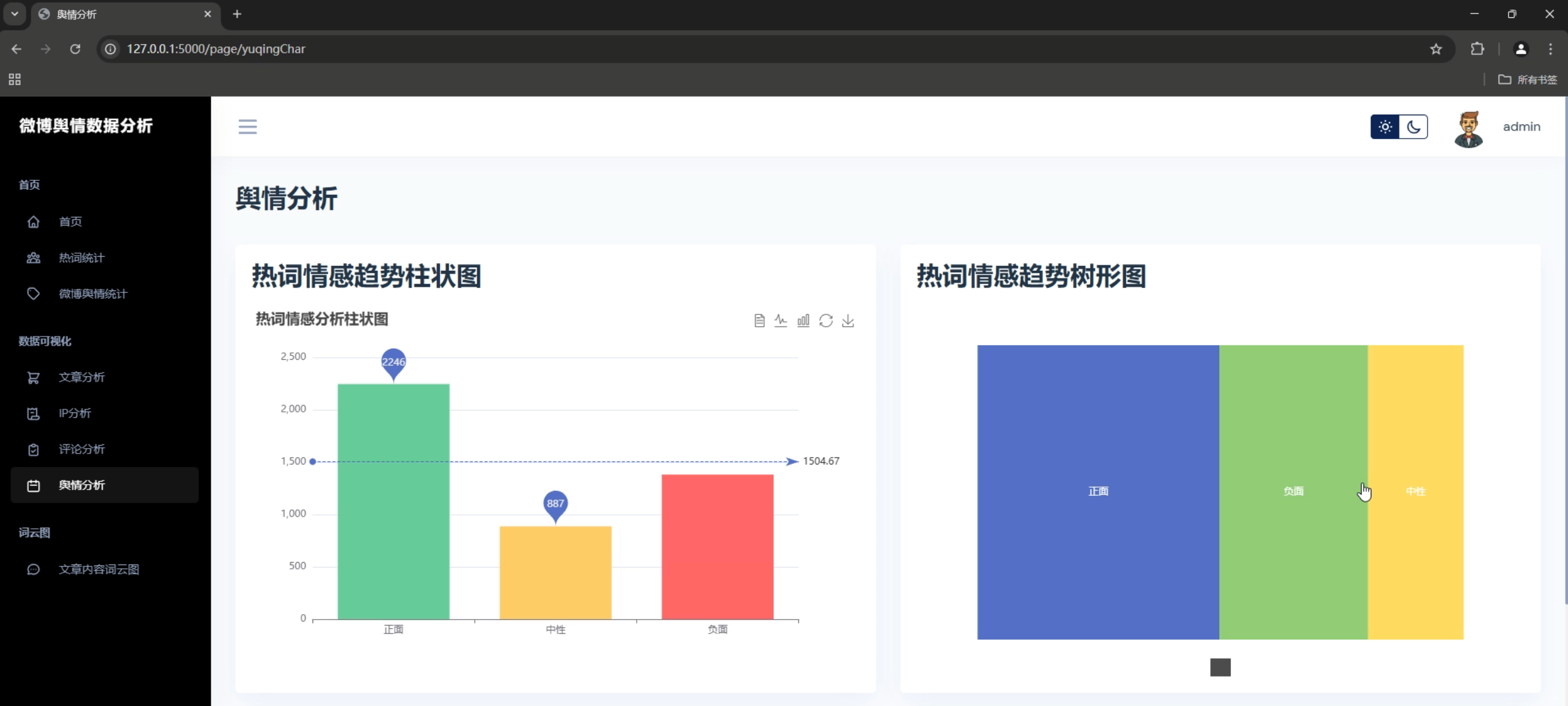
2. 情感分析图表
- 情感分布饼图
- 情感趋势折线图
- 情感强度热力图
- 情感变化时间轴
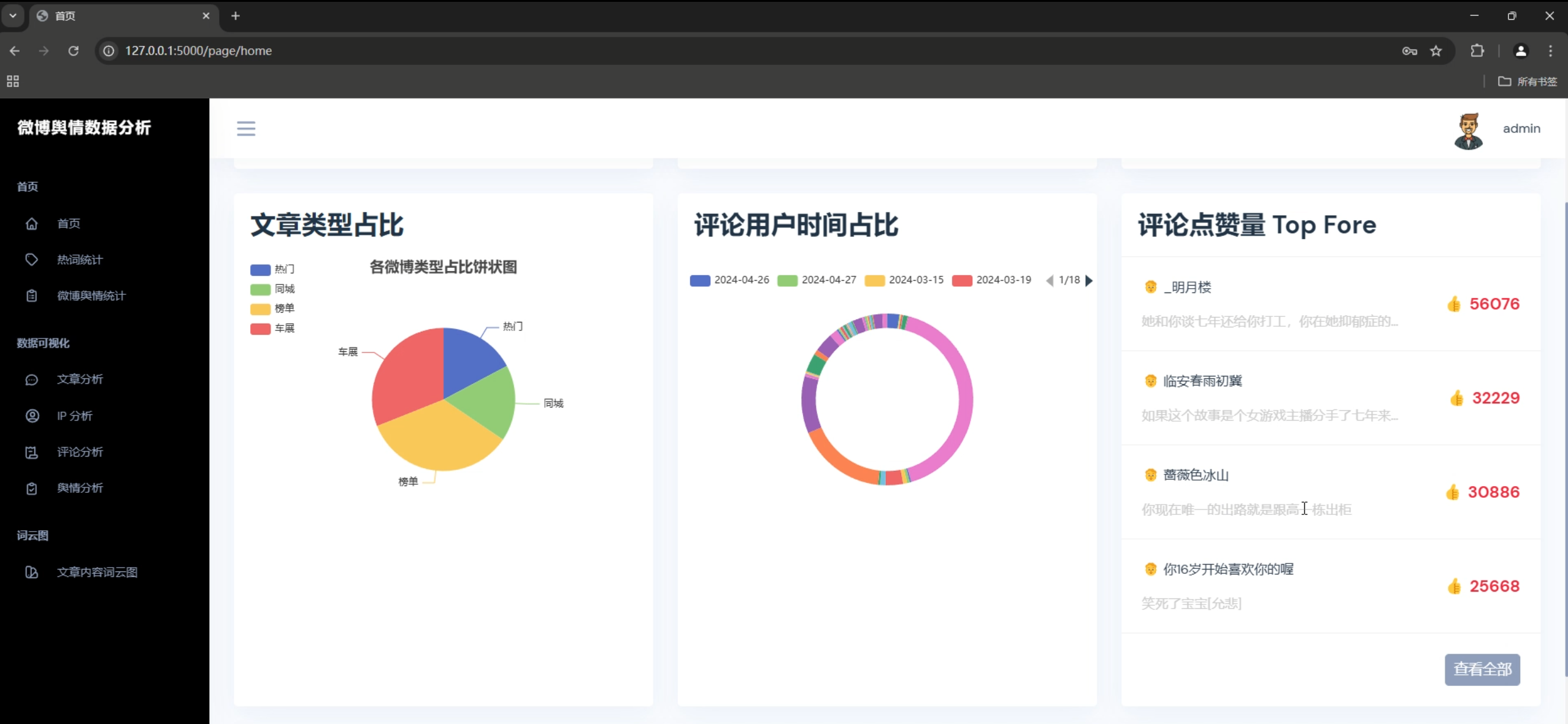
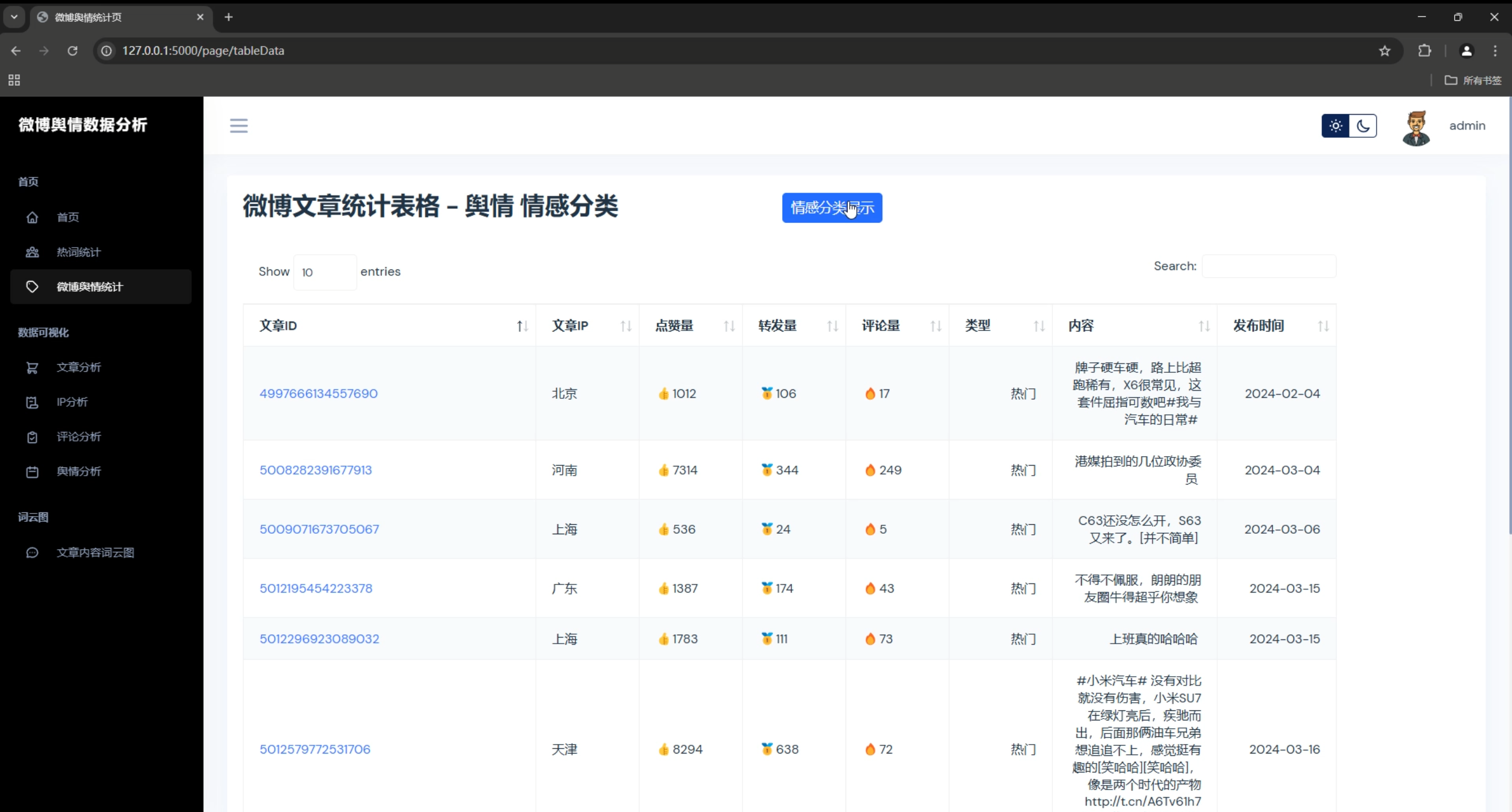
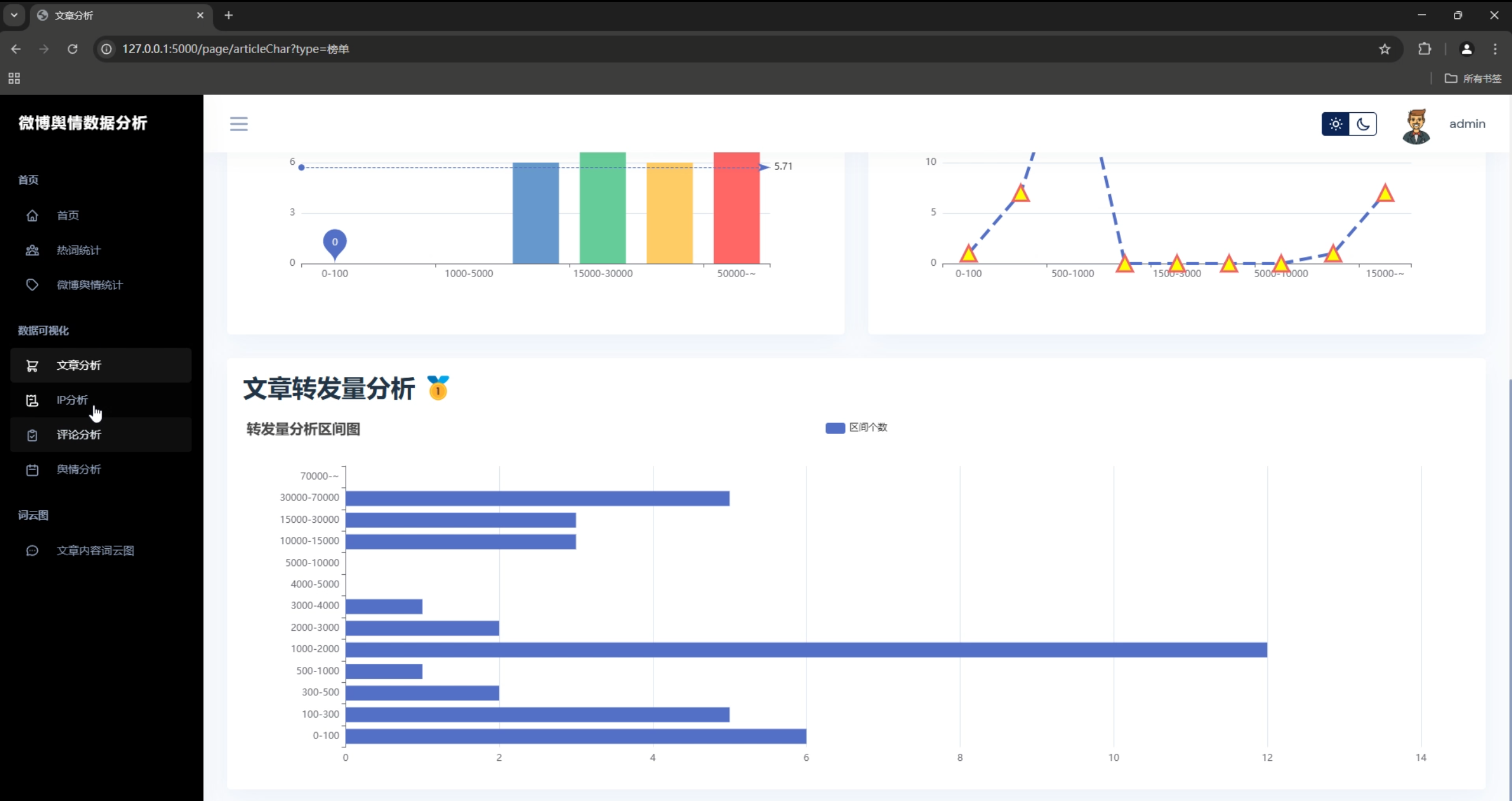
3. 数据统计图表
- 数据量统计柱状图
- 用户活跃度分析
- 内容热度排行
- 地理分布地图
🚀 部署与运行
环境要求
- Python 3.7+
- MySQL 5.7+
- 内存: 4GB+
- 存储: 10GB+
安装步骤
- 克隆项目
bash
git clone <repository-url>
cd flask_weiboyuqing- 安装依赖
bash
pip install -r requirements.txt- 配置数据库
bash
mysql -u root -p < design_173_wb.sql-
修改配置
编辑
app.py中的数据库连接信息 -
运行应用
bash
python app.py生产环境部署
bash
# 使用Gunicorn部署
pip install gunicorn
gunicorn -w 4 -b 0.0.0.0:5000 app:app
# 使用Nginx反向代理
# 配置Nginx配置文件✨ 项目特色
1. 技术先进性
- 采用最新的Flask 2.0框架
- 集成机器学习情感分析
- 支持大数据量处理
- 模块化架构设计
2. 功能完整性
- 从数据采集到分析展示的完整流程
- 支持多种数据源和格式
- 丰富的可视化图表类型
- 完善的用户权限管理
3. 可扩展性
- 插件化的模块设计
- 支持自定义分析模型
- 灵活的配置管理
- 易于二次开发
4. 用户体验
- 响应式Web界面
- 直观的数据展示
- 快速的数据查询
- 友好的错误提示
🔍 技术难点与解决方案
1. 反爬虫策略
问题 : 微博平台有严格的反爬虫机制
解决方案:
- 随机User-Agent轮换
- 请求频率控制
- IP代理池使用
- 模拟真实用户行为
2. 中文文本处理
问题 : 中文分词和情感分析的准确性
解决方案:
- 使用jieba分词器
- 自定义情感词典
- 结合SnowNLP和机器学习
- 持续优化模型
3. 大数据量处理
问题 : 大量数据的存储和查询性能
解决方案:
- 数据库索引优化
- 分页查询实现
- 缓存机制使用
- 异步处理任务
4. 实时数据更新
问题 : 保持数据的实时性和准确性
解决方案:
- 定时任务调度
- 增量更新机制
- 数据版本控制
- 异常重试机制
📈 性能优化
1. 数据库优化
- 建立合适的索引
- 查询语句优化
- 连接池管理
- 读写分离
2. 缓存策略
- Redis缓存热点数据
- 浏览器缓存静态资源
- 数据库查询缓存
- 计算结果缓存
3. 并发处理
- 多线程爬虫
- 异步任务处理
- 负载均衡
- 资源池管理
🔮 总结与展望
项目成果
本项目成功实现了一个功能完整、性能稳定的微博舆情数据分析系统,在以下方面取得了显著成果:
- 技术架构: 采用现代化的技术栈,实现了高内聚、低耦合的系统设计
- 功能完整性: 覆盖了从数据采集到分析展示的完整业务流程
- 性能表现: 通过多种优化手段,实现了良好的系统性能
- 用户体验: 提供了直观、易用的Web界面
技术价值
- 展示了Flask框架在企业级应用中的强大能力
- 验证了机器学习在文本分析中的实际应用价值
- 提供了完整的数据分析系统开发参考
未来展望
- 功能扩展: 支持更多社交媒体平台的数据分析
- 技术升级: 集成深度学习模型,提升分析准确性
- 性能优化: 引入分布式架构,支持更大规模数据处理
- 用户体验: 开发移动端应用,提供更便捷的访问方式
📞 联系方式
码界筑梦坊 - 专注技术分享与创新 各平台同名
本文档持续更新中,如有问题或建议,欢迎通过以上平台联系交流。
最后更新时间: 2025年8月
许可证: MIT License