在人工智能飞速发展的今天,各种"大模型"概念层出不穷。你是否经常看到LLM、MLLM、LMM、VLM这些缩写,却搞不清楚它们之间的区别与联系?今天我们就来彻底理清这些概念,带你走进大语言模型的多模态世界。
基础核心:大语言模型(LLM)
大型语言模型是基于深度神经网络构建的先进人工智能系统,专门处理、理解和生成类人文本。这些模型通过海量文本数据的训练,掌握了语言的深层次规律和上下文逻辑。
- 核心技术架构
LLM的核心架构基于Transformer系列网络,特别是其中的自注意力机制。这一突破性设计使得模型能够同时处理文本序列中的多个部分,捕捉长距离依赖关系。目前主流的参数规模已达数百亿甚至数千亿级别。
OpenAI的《Improving Language Understanding by Generative Pre-Training》(2018)开启了预训练语言模型的新时代。

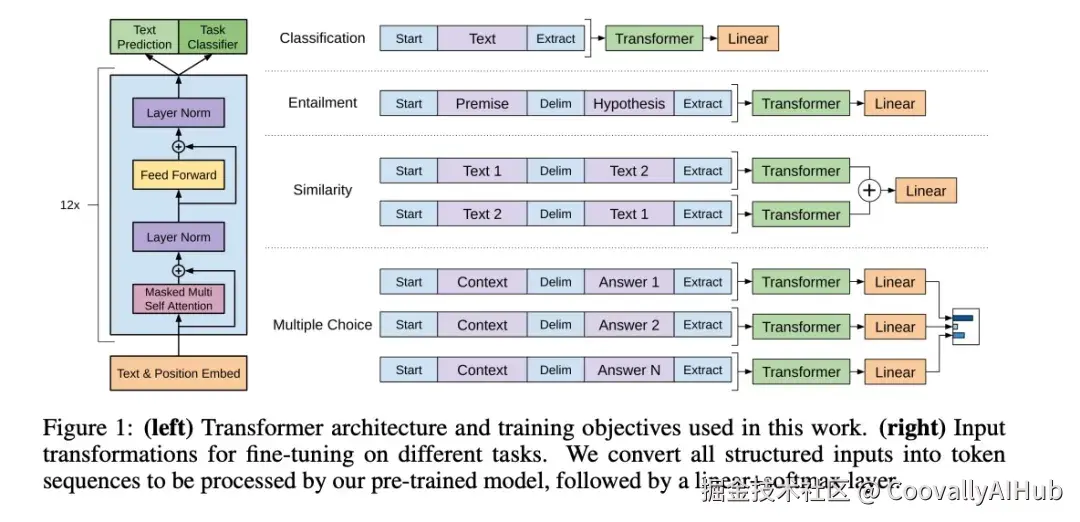
- 主流代表模型
- ChatGPT (OpenAI) - 对话式AI的里程碑
- 谷歌Gemini - 多任务处理的强者
- 文心一言 (百度) - 中文场景优化的代表
- DeepSeek - 专注代码和逻辑推理
- 通义千问 (阿里) - 全面能力型选手
视觉增强:视觉语言模型(VLM)
视觉语言模型是连接视觉与语言理解的桥梁,它能够同时处理图像和文本输入,生成与视觉内容相关的文本输出。
- 三阶段处理流程
- 视觉编码器: 将图像转换为数值表示(视觉标记)
- 投影层: 将视觉标记映射到语言模型的嵌入空间
- LLM解码器: 融合视觉和文本信息,生成自然语言响应
- 核心能力矩阵
- 图像描述生成: 为复杂场景生成准确、丰富的文字描述
- 视觉问答(VQA): 回答与图像内容相关的具体问题
- 图文互搜: 实现文本到图像、图像到文本的双向检索
- 多模态内容创作: 融合视觉元素生成创新内容
- 场景理解与目标检测: 识别并描述图像中的物体、关系和场景
论文参考:OpenAI的《CLIP: Learning Transferable Visual Models From Natural Language Supervision》(2021)开创了视觉-语言对齐的新范式,而谷歌的《Flamingo: A Visual Language Model for Few-Shot Learning》(2022)则在少样本学习上取得了突破。



多模态融合:多模态大语言模型(MLLM)
多模态大语言模型能够处理多种类型的数据输入,每种"模态"代表特定类型的数据:文本、图像、音频、视频等。其核心价值在于跨模态的理解和生成能力。
- 典型应用示例
- 图像标题生成: 输入图像,输出精确描述
- 多模态对话: 结合图像和文本进行自然对话
- 跨模态推理: 基于视觉信息进行逻辑推理和问题解决
- 技术特点
MLLM通常建立在强大的LLM基础上,通过扩展输入处理能力和调整模型架构,实现对多种模态数据的统一处理。这种统一处理使得模型能够捕捉不同模态之间的关联性和互补信息。
论文参考:微软的《Language Is Not All You Need: Aligning Perception with Language Models》(2023)展示了语言与多模态对齐的潜力,而《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models》(2023)则提供了一种高效的多模态训练方法。



全面进阶:大型多模态模型(LMM)
大型多模态模型是MLLM的更高级形式,不仅能够处理多种输入模态,还能够生成多种类型的输出,如文本、图像、音频等。
- 核心特征
- 多模态输入理解: 同时处理文本、图像、音频等多种数据类型
- 多模态输出生成: 根据需求生成文本描述、合成图像或音频
- 跨模态关联学习: 深度理解不同模态数据之间的内在联系
- 与MLLM的关系
LMM本质上与MLLM类似,但通常指代能力更全面、规模更大的模型。可以理解为LMM是MLLM的"完全体",在多模态理解和生成方面都达到了更高水平。
论文参考:Google的《PaLM-E: An Embodied Multimodal Language Model》(2023)在机器人控制等具身智能任务上展现了多模态模型的潜力,而《GPT-4V(ision) System Card》(2023)则详细描述了当前最先进多模态模型的能力边界。

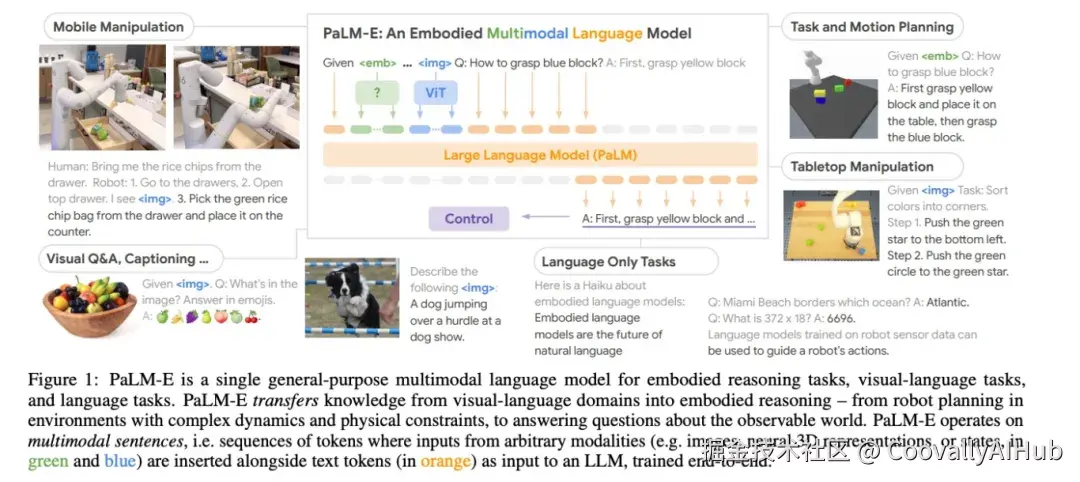

技术演进脉络与应用前景
- 发展路径
纯文本LLM → 视觉增强VLM → 多模态MLLM → 全面多模态LMM
这一演进路径反映了AI从单一模态处理向多模态综合智能的发展趋势。每一次跃迁都意味着模型对现实世界理解能力的显著提升。
- 热门研究方向
- 跨模态对齐技术:如何更好地将不同模态的信息在统一语义空间中表示
- 少样本/零样本学习:让模型在少量或无需样本的情况下理解新概念
- 多模态推理:基于多种信息源进行复杂逻辑推理
- 具身智能:将多模态模型与物理世界交互结合
- 伦理与安全:确保多模态内容的可靠性和安全性
- 行业应用前景
- 智能教育:结合图文音视频,提供个性化学习体验
- 医疗诊断:综合分析医疗影像和病历文本,辅助医生决策
- 内容创作:自动化生成多模态营销材料、教育内容
- 机器人交互:让机器人更好地理解和响应人类指令
- 无障碍技术:为视障、听障人士提供更好的信息获取方式
结语
从专注文本的LLM到融合多感官信息的LMM,人工智能正在以前所未有的速度逼近人类的综合认知能力。理解这些概念的区别与联系,不仅有助于我们把握技术发展趋势,更能为实际应用场景的选择提供理论指导。
随着技术的不断成熟,多模态大模型将在更多领域发挥关键作用,真正实现"看、听、说、想"的全面智能。对于开发者和研究者而言,现在正是深入探索这一领域的黄金时期。