学习笔记(AI总结):Chapter 7 Classification Advanced Methods
一 特征选择与特征工程
目标:从p个初始特征中选出有效子集;基于原始特征构造更强的新特征
动机:去除无关与冗余特征;利用领域知识或深度学习自动表示
方法分类:
Filter:与模型无关,依赖统计度量
Wrapper:在训练模型与选特征间迭代,用模型性能评估子集
Embedded:在训练过程中同时完成选择,典型为LASSO
LASSO与坐标下降:单变量二次目标加L1正则,解为软阈值;可拓展为Elastic Net Group Lasso Fused Lasso
二 朴素贝叶斯与贝叶斯网络
朴素贝叶斯假设条件独立,过于强
贝叶斯网络是概率图模型,以DAG表示变量及条件依赖;通过CPT给出条件概率
训练情形:
结构与变量已知:估计CPT
结构已知部分隐变量:梯度下降或爬山搜索
结构未知可观测:在模型空间搜索拓扑
结构未知全隐:无很好算法
板块表示:用plate表达可重复子结构
三 SVM 支持向量机
核心思想:在映射后的高维空间寻找最大间隔超平面
线性可分:约束yi(wx+b)≥1 最大化间隔等价于最小化||w||²
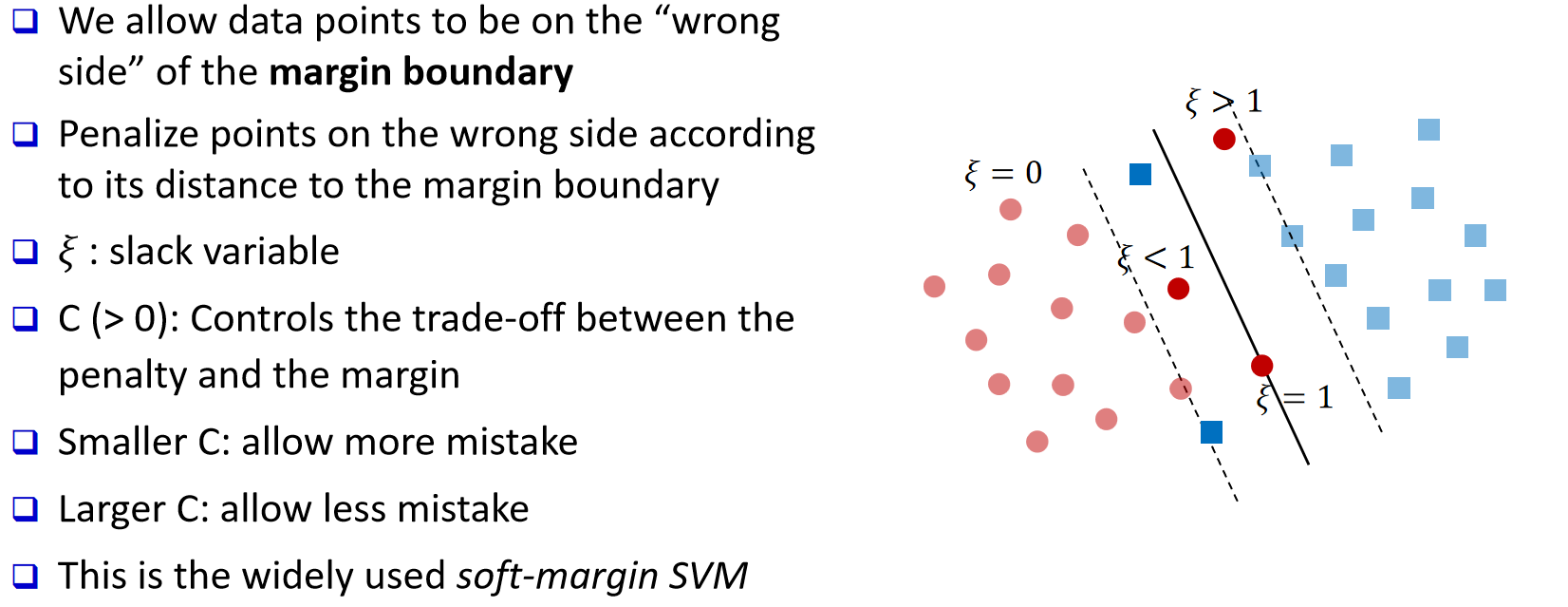
线性不可分:加入松弛变量与惩罚C形成软间隔
核技巧:多项式 RBF Sigmoid 将非线性问题转为线性分离
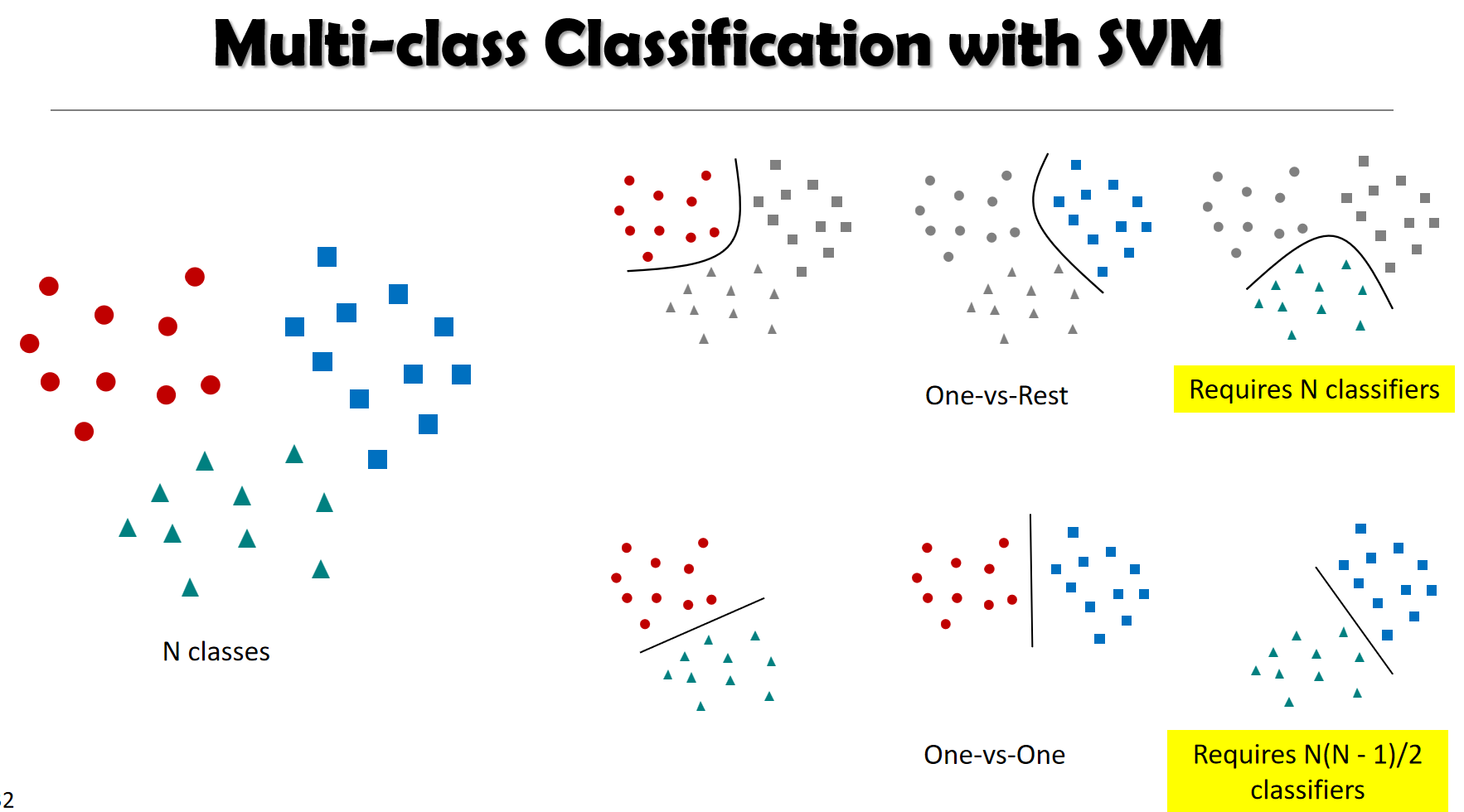
多分类:一对其余 一对一 纠错编码
可扩展性:性能随支持向量数而非维度;对超大样本训练与内存不易扩展
应用:分类 回归 多类 手写体 目标识别 说话人识别等
四 基于规则与基于模式的分类
IF THEN规则:用覆盖率与准确率评价;多规则冲突需按复杂度 类别代价 或决策表排序
从决策树抽取规则:每条根到叶路径对应一条互斥完备规则
顺序覆盖法:循环学习一条规则 移除已覆盖样本 直至终止
基于模式分类动机:高阶紧凑且判别的特征;适配图 序列 半结构化数据
CBA方法:挖掘高支持高置信的类别关联规则 按置信与支持排序并按首条匹配分类
五 弱监督学习
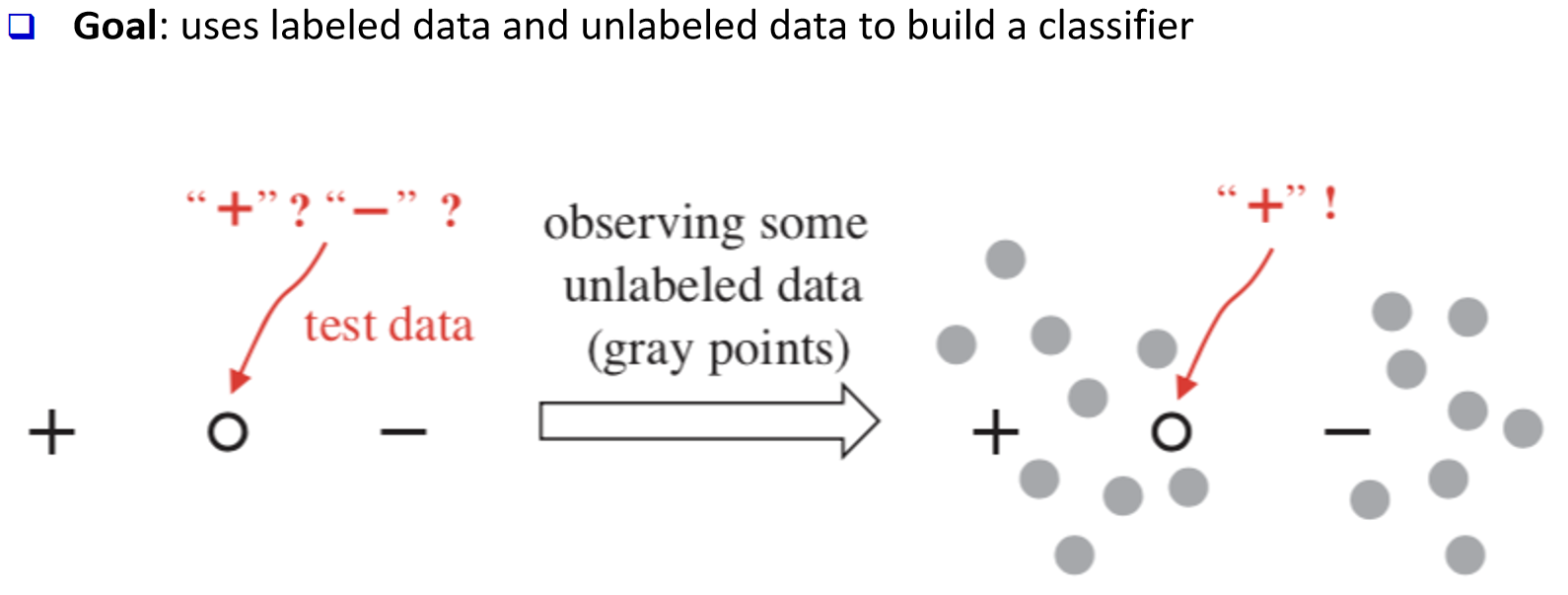
半监督:利用有标注与无标注数据
自训练:用当前模型给无标注打分 选择高置信加入再训练
协同训练:将特征划分两视角 互相给对方提供高置信样本
有效性假设:聚类假设 决策边界穿过低密度;流形假设 标签在相似图上平滑
主动学习:从未标注集中选择最有价值样本,如不确定性 委员会 版本空间 决策理论
传导学习:只针对给定未标注集做预测
迁移学习:从源任务迁移知识到目标任务 示例情感跨域
TrAdaBoost:对源域样本重加权 减弱不相关样本权重 关注负迁移检测
远程监督:用启发式或外部信号自动标注 数据量大但有噪声
零样本学习:借助外部语义或属性在未见类上预测 广义设置需同时识别已见与新类
语义属性分类器:先预测属性向量 再根据属性到类别的映射识别新类
六 丰富数据类型上的分类
流数据:高到达速率 无限长度 单次遍历 概念漂移;集成与权重自适应;VFDT与滑动窗口
序列分类:整体序列判别与逐时刻标注;特征工程n元语法或离散化;DTW与字符串核;深度模型RNN等
图数据分类:节点级与图级;基于特征工程与GNN自动表示;基于相似度的KNN式方法
七 其它技术
多类别分类与多标签分类:OVA OVO ECOC
距离度量学习:学习半正定矩阵M 使相似近不相似远 等价线性变换加欧氏距离
可解释性:决策树与线性模型友好;LIME在局部用可解释替代模型;反事实与影响函数
遗传算法:规则编码 适者生存 交叉变异 用于搜索与评估
强化学习与分类的区别:监督给指导标签 强化给评价型奖励;多臂老虎机 ε贪心与UCB
八 总结
本章系统覆盖特征选择 贝叶斯网络 SVM 规则与模式方法 弱监督与迁移 以及在流数据 序列 图上的分类扩展 并讨论度量学习 可解释性 遗传算法与强化学习等相关主题
特征选择
p2 Feature Selection & Feature Engineering
特征选择(Feature Selection)
给定一组 pp 个初始特征,如何只选择少量且最有效的特征?
为什么需要这样做?
无关特征(例如:用学号来预测 GPA)
冗余特征(例如:月收入 与 年收入)
特征工程(Feature Engineering)
在已有初始特征的基础上,如何构造出更有效的新特征?
例如:每日阳性数、每日检测次数、每日住院人数 → 每周阳性率
(传统上)领域知识是关键
深度学习提供了一种自动化途径
p3 特征选择的方法
过滤法(Filter methods)
基于某种"优劣度量"来选择特征
与具体分类模型无关
包裹法(Wrapper methods)
将特征选择与分类模型构建两个步骤结合在一起
迭代式地进行:
用当前已选的特征子集来构建一个分类模型
再用当前模型来更新/调整所选特征子集
嵌入法(Embedded methods)
同时构建分类模型并选择相关特征
在模型构建过程中就把特征选择步骤嵌入进去
p4 过滤法

(流程示意:全部特征集 → 过滤法 → 已选择的特征子集 → 数据挖掘/建模)
一、通用流程(General Procedure)
-
基于某种**优劣度量(goodness measure)**来选择特征;
-
与具体的分类模型无关。
二、Fisher 分数(Fisher Scores)
直觉(Intuitions): 当满足以下条件时,特征 xxx(如:收入)与类别标签 yyy(是否购买电脑)相关性强:
-
购买电脑的顾客群体的平均收入 与未购买 的顾客群体的平均收入显著不同;
-
购买电脑 的顾客之间的收入相似;
-
未购买电脑 的顾客之间的收入也相似。
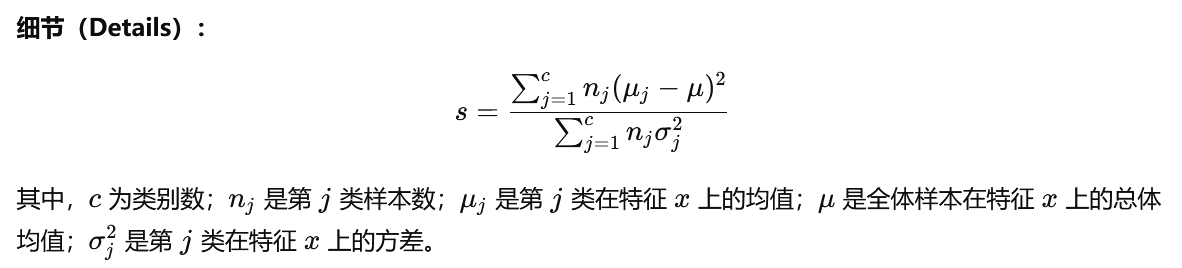
其他优劣度量(Other goodness measures)
-
卡方检验 (χ2\chi^2χ2,用于类别型特征);
-
信息增益(information gain);
-
互信息(mutual information)。
p5 包裹法(Wrapper Methods)
-
通用流程(General Procedure)
-
将特征选择 与分类模型构建 两个步骤结合起来
-
迭代式进行
-
使用当前已选特征子集训练一个分类模型
-
使用当前模型 来更新/调整所选特征子集
-
-
-
关键:如何搜索到最佳特征子集(Key)
-
穷举搜索:2p−1(指数级开销)
-
逐步前向选择(Stepwise forward selection)
-
从空特征子集开始
-
每次迭代加入最能提升性能的一个特征
-
-
逐步后向消除(Stepwise backward elimination)
-
从完整特征集开始
-
每次迭代删除一个最不重要的特征
-
-
混合方法(Hybrid method)
- 前向与后向策略的组合/变体
-
p6嵌入法(Embedded Methods)
-
通用流程(General Procedure)
-
同时 构建分类模型并选择相关特征
-
在模型构建步骤中嵌入特征选择
-
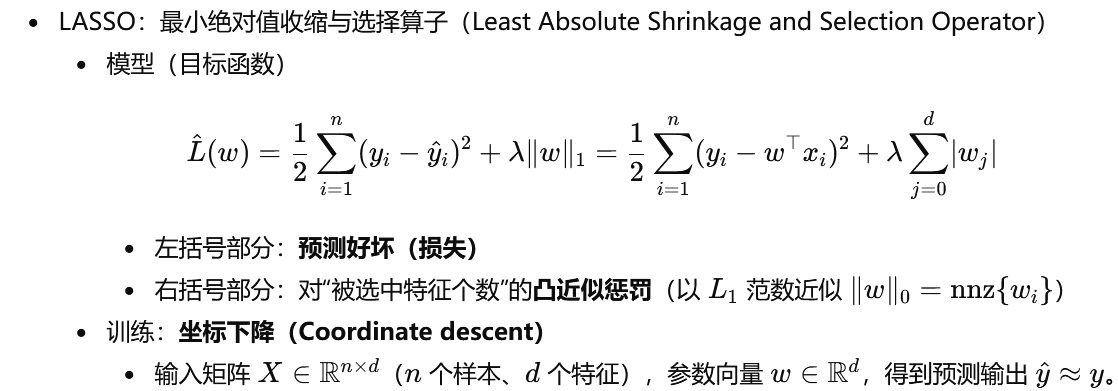
p7 坐标下降:最小化 f(x)
(Coordinate Descent: Minimizef(x))

p8 Coordinate Descent for LASSO

p9 Coordinate Descent for LASSO


p10 软阈值(Soft Thresholding)


p11 稀疏学习
(Beyond Lasso: Sparse Learning)

贝叶斯网络
p13 从朴素贝叶斯到贝叶斯网络
(From Naïve Bayes to Bayesian Networks)
朴素贝叶斯
假设:在给定类别变量的条件下,任一特征的取值与其他所有特征的取值彼此独立。
问题:这一独立性假设过于简单,往往难以很好地刻画真实世界。
贝叶斯网络
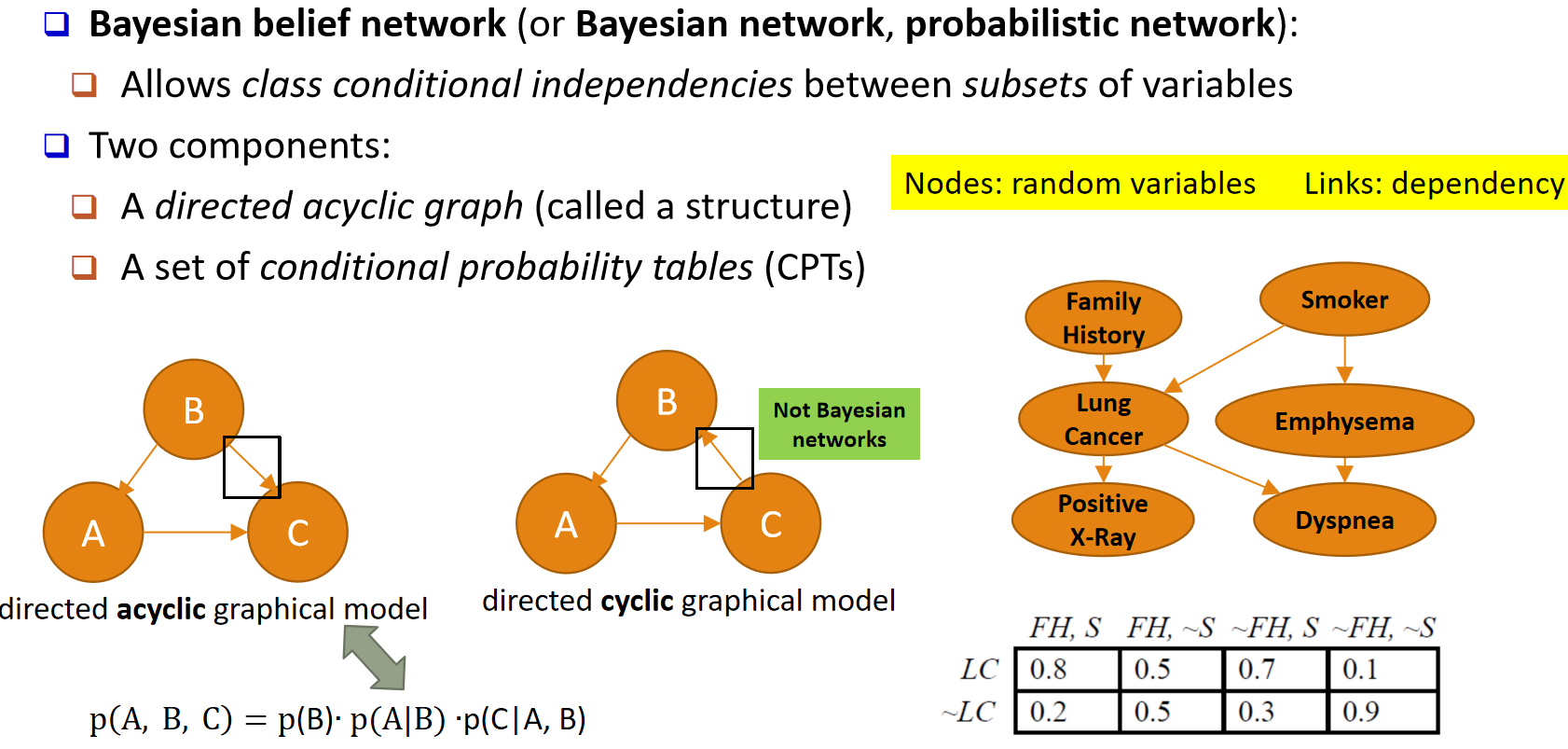
定义:一种概率图模型(probabilistic graphical model)。
表示方式:由一组随机变量以及它们之间的条件依赖关系组成,并用有向无环图(DAG)表示。
作用举例:给定一组症状时,可用网络计算各种疾病出现的概率(如图所示:SEASON、RAIN、SPRINKLER → WET → SLIPPERY)

p14 贝叶斯信念网络
定义(又称:Bayesian network,probabilistic network):
允许在"给定类别"的条件下,变量的某些子集之间存在条件独立关系(class conditional independencies)。
组成(Two components):
有向无环图(DAG,称为网络的结构 structure)。
一组条件概率表(CPTs, Conditional Probability Tables)。
语义提示 :
节点(Nodes):随机变量(random variables)。
边(Links):依赖关系(dependency)。
说明:
只有"有向无环图"才是贝叶斯网络;若图中存在环(directed cyclic graphical model),则不是贝叶斯网络。
例如三个节点 A、B、C 构成的 DAG,其联合分布可分解为
p(A, B, C) = p(B) · p(A | B) · p(C | A, B)。
示例(医学场景):
变量:Family History(家族史)、Smoker(是否吸烟)、Lung Cancer(肺癌)、
Emphysema(肺气肿)、Dyspnea(呼吸困难)、Positive X-Ray(X 光阳性)。
通过结构与对应的条件概率表(如 p(LC | FH, S) 等),计算任意事件或联合事件的概率。
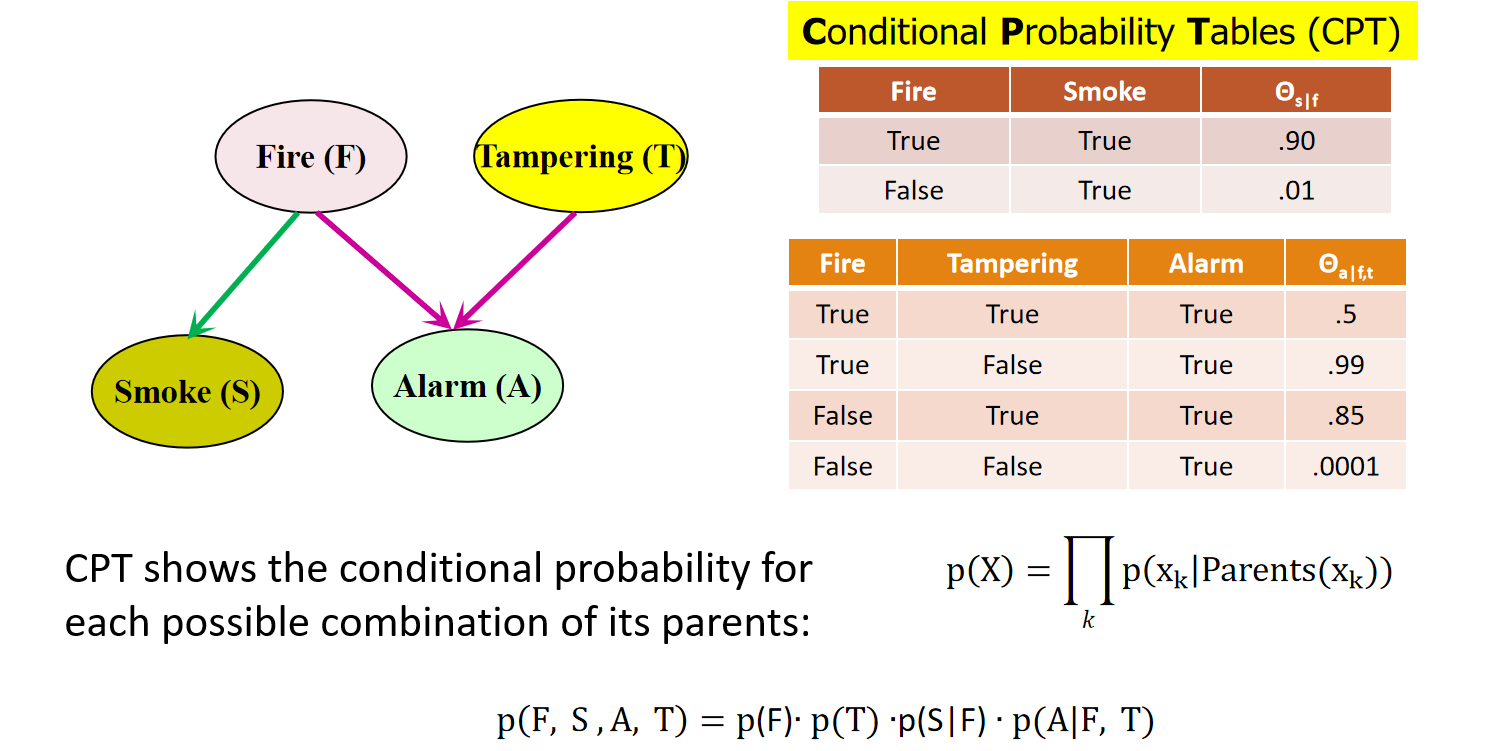
p15 贝叶斯网络及其条件概率表
(CPT)

p16 训练贝叶斯网络:几种情形
情形 1
已知网络结构,且所有变量都可观测:只需求出各节点的**条件概率表(CPT)**条目即可。
情形 2
已知网络结构,但有些变量不可观测:采用梯度下降 (贪心爬山)方法,即沿着某个准则函数的最陡下降方向 寻找解。
参数(权重/概率)通常先随机初始化 ;
每次迭代都朝当前看来最优 的方向前进,不回溯 ;
每轮更新参数,最终收敛到局部最优。
p17 训练贝叶斯网络:其余情形
**情形 3:**网络结构未知、但所有变量都可观测。做法是在模型空间中搜索,以重建网络拓扑。
情形 4:网络结构未知、且所有变量都是隐变量。目前没有好的算法能够解决这一情形
p18 概率图模型:板块表示(Plate Notations)


p19 板块表示示例
(An Example of Plate Notation)

支持向量积
p21 一种数学映射
(Classification: A Mathematical Mapping)

p22 支持向量机(SVM)
SVM 可以是线性的,也可以是非线性的。Vapnik 及其同事于 1992 年提出了 SVM 的框架,其理论基础可追溯到 20 世纪 60 年代 Vapnik 与 Chervonenkis 的统计学习理论。
SVM 通过非线性映射 把原始训练数据变换到更高维空间;在这个新空间里,去寻找一个线性的最优分离超平面 (即"决策边界")。
当采用合适的非线性映射并把维度提升得足够高时,来自两个类别的数据总可以被某个超平面分开。
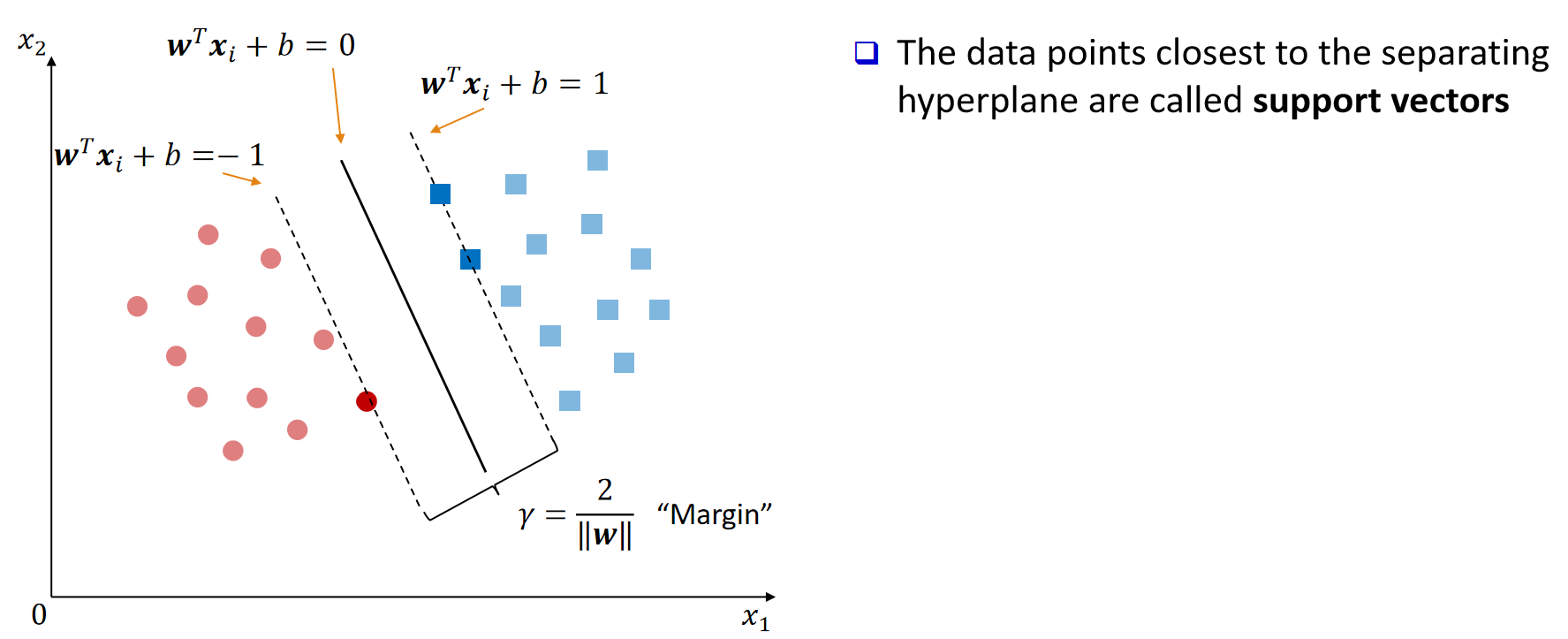
SVM 正是利用支持向量(最关键的训练样本)以及由它们确定的**间隔(margin)**来找到这个超平面
p23 SVM------总体思想
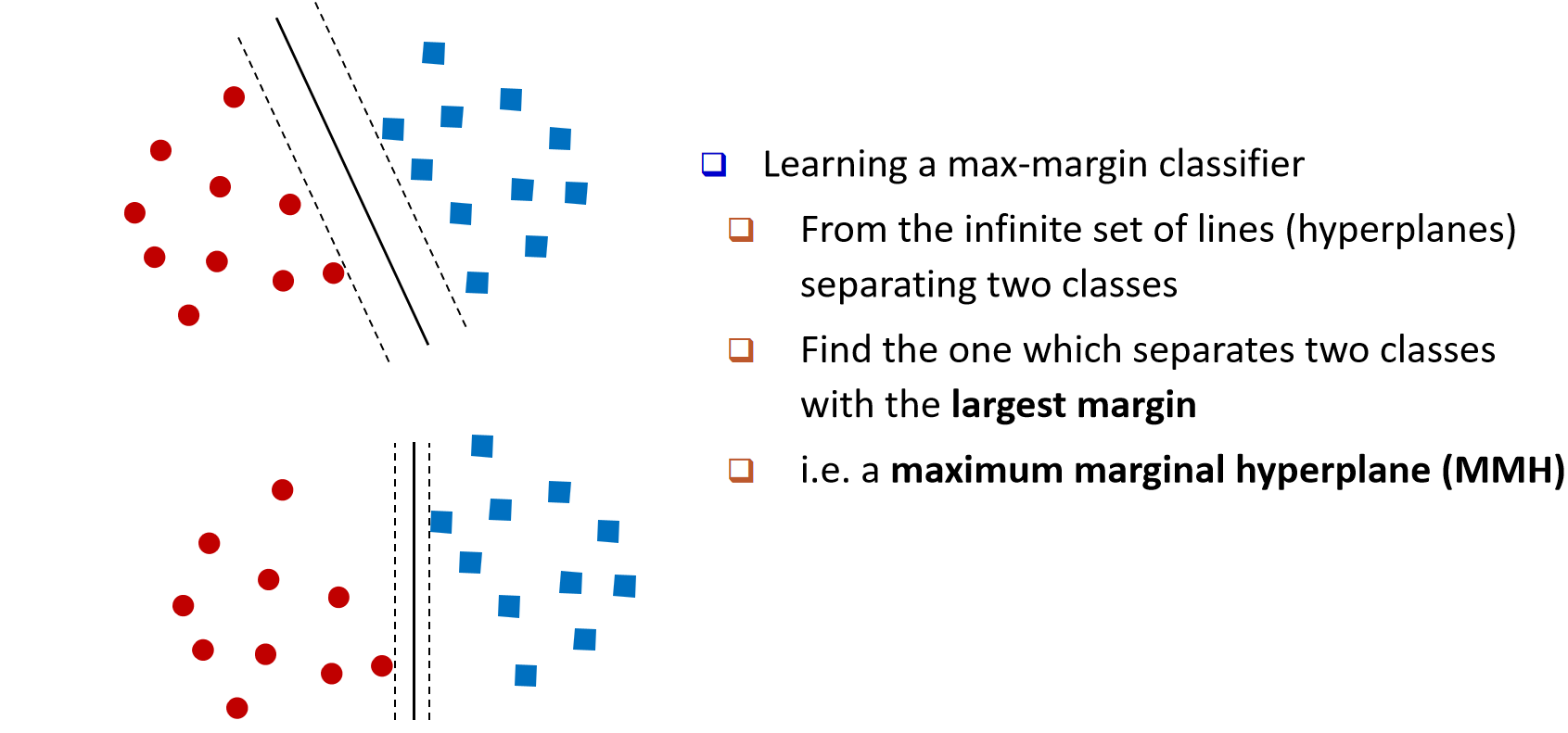
学习一个"最大间隔"的分类器。
在能把两类样本分开的无穷多条直线(或高维中的超平面)中,选择那条间隔(margin)最大 的。
这条超平面称为最大间隔超平面 (MMH, Maximum Marginal Hyperplane)。
(图示:虚线表示由支持向量确定的两条间隔边界,实线为居中的最优分离超平面。)
p24 SVM------当数据线性可分时
最简单的情形是:数据是线性可分 的。
如果一个数据集可以被线性决策面 精确地把两类分开,那么就称该数据集线性可分 。
(左图:线性可分;右图:线性不可分,需要非线性边界或核映射。)

p25 线性可分数据的线性 SVM

p26 线性可分数据的线性 SVM
(间隔最大化的等价形式)

p27 线性可分数据的线性 SVM
几何解释

p28 线性不可分数据的 SVM
(软间隔 SVM)

p29
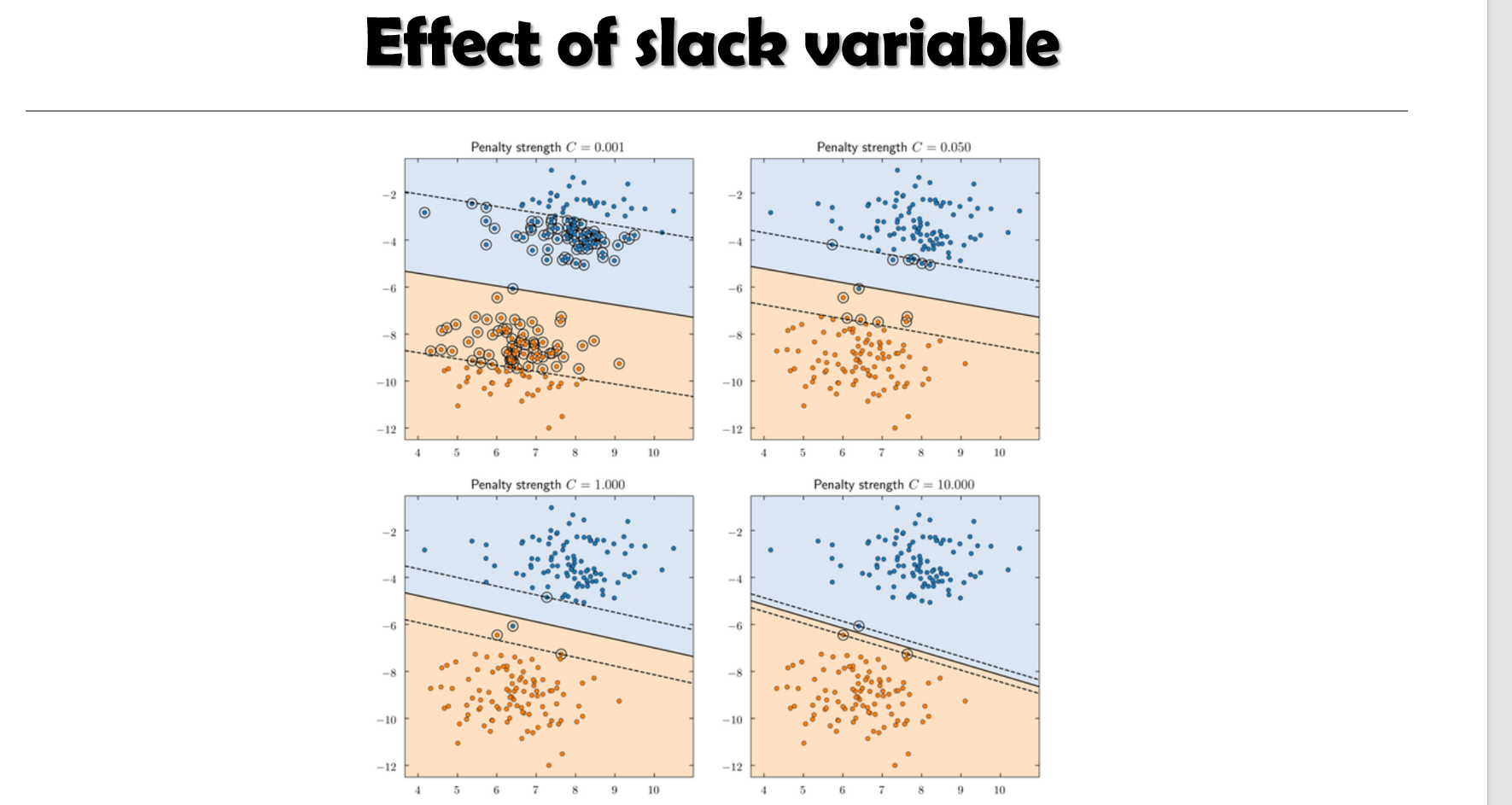
p30 线性不可分数据的 SVM
核映射思路
当数据在原空间线性不可分时,可以先把样本通过非线性映射 x↦ϕ(x)x\mapsto \phi(x)x↦ϕ(x) 投到更高维空间;然后在该新空间中再寻找一个线性的分离超平面。
典型示例是 XOR(异或)问题:在二维空间线性不可分,经适当映射到三维后,可被一个平面线性分开。
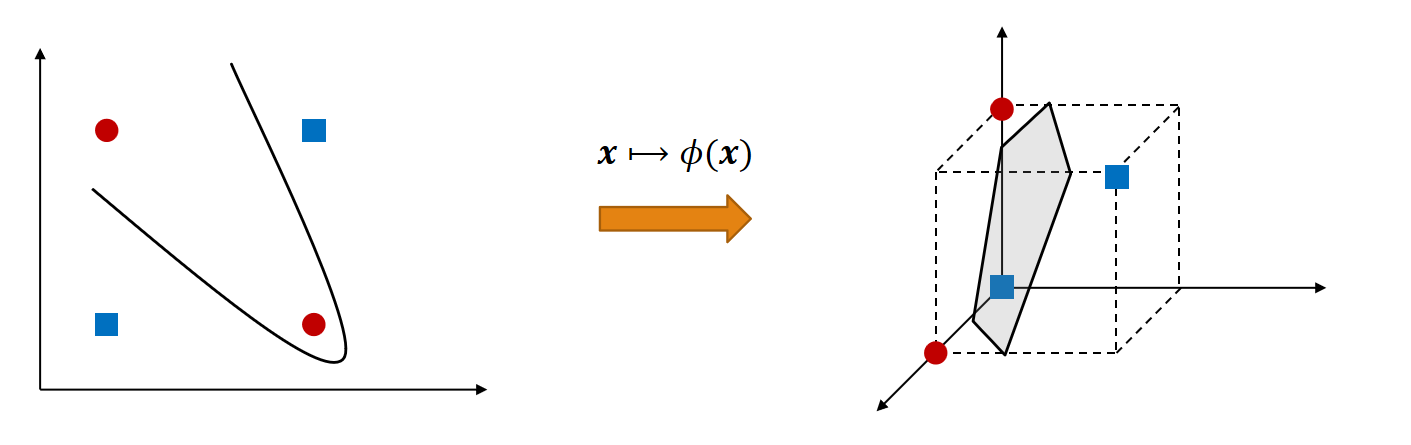
p31 非线性分类的核函数
(Kernel Functions for Nonlinear Classification)

p32
p33 SVM 在海量数据上是否可扩展?
SVM 在高维数据上通常表现良好。已训练分类器的复杂度更多取决于支持向量的数量,而不是数据的维度。支持向量是最关键的训练样本,它们位于最接近决策边界(最大间隔超平面)的地方。因此,即使数据维度很高,只要支持向量数量不多,SVM 也能获得较好的泛化性能。
但从训练时间与内存占用 来看,SVM 对于**数据量(样本数)**并不具备良好的可扩展性。
一种扩展思路是采用**层次化微簇(hierarchical micro-clustering)**来缩放 SVM。参考:H. Yu, J. Yang, J. Han, "Classifying Large Data Sets Using SVM with Hierarchical Clusters", KDD 2003
p34 SVM:应用
特性:训练可能较慢,但准确率往往较高,因为 SVM 通过最大化间隔,能够刻画复杂的非线性决策边界。
用途:既可做分类,也可做数值预测。通过引入额外参数,SVM 还能扩展到多分类(>2 类)以及回归任务。
应用场景举例:手写数字识别、目标/物体识别、说话人识别,以及作为时间序列预测测试的基准方法。
p35 SVM 回顾
优点:
(1)数学形式优雅,经过优化可保证全局最优;
(2)在小数据集上训练效果好;
(3)借助核函数具有很强的灵活性;
(4)可与半监督训练相结合。
缺点:
(1)对超大规模数据集不具备天然的可扩展性。
p39 用 IF--THEN 规则做分类
以 IF--THEN 规则来表示知识。
示例规则 R₁:IF age = youth AND student = yes THEN buys_computer = yes。
规则评估包含"覆盖率(coverage)"与"准确率(accuracy)"。
coverage(R₁):被 R₁ 的 IF 条件部分 覆盖的样本占比(不看 THEN 部分)。
accuracy(R₁):在被覆盖的样本中,被 R₁ 正确分类的比例(计入 IF 与 THEN 的匹配)。
当同时触发多条规则时,需要"冲突消解":
Size ordering:优先级给"条件最严格"的规则(即包含最多属性测试的那条)。
Class-based ordering:按类别的普遍性 或误分类代价 由高到低排序。
Rule-based ordering(decision list):根据某种规则质量度量 或专家经验,把规则组织成一条从高到低的优先级列表。
p40 从决策树抽取规则
(Rule Extraction from a Decision Tree)
规则通常比庞大的树更易于理解。
从根到叶子的每一条路径 都可生成一条规则 。
路径上出现的属性=取值 依次相与(形成合取条件),叶节点给出类别预测 。
这些规则之间互斥且完备(覆盖全部情况且互不重叠)。

示例:从 buys_computer 决策树抽取的规则
-
IF age = young AND student = no THEN buys_computer = no
-
IF age = young AND student = yes THEN buys_computer = yes
-
IF age = mid-age THEN buys_computer = yes
-
IF age = old AND credit_rating = excellent THEN buys_computer = no
-
IF age = old AND credit_rating = fair THEN buys_computer = yes
p41-p44 规则归纳:顺序覆盖法
(Sequential Covering Method)
定义
顺序覆盖算法直接从训练数据中抽取规则。规则按"顺序"学习:针对某个类别 CiC_iCi 学到的一条规则,应尽量覆盖该类中的许多样本,同时几乎不覆盖其他类别的样本。与决策树一次性学出整套规则不同,顺序覆盖是逐条生成。
Step 0
从空的规则列表开始。
Step 1
学习一条规则 rrr:在当前数据上寻找能很好覆盖目标类、且尽量排除其他类的规则(图中黑框示意)。
Step 2
删除已被规则覆盖的样本,把它们从训练集移除。
Step 3
在剩余样本上重复 上述过程,直到满足终止条件:例如不再有训练样本,或新学到规则的质量(覆盖率/准确率等指标)低于阈值。
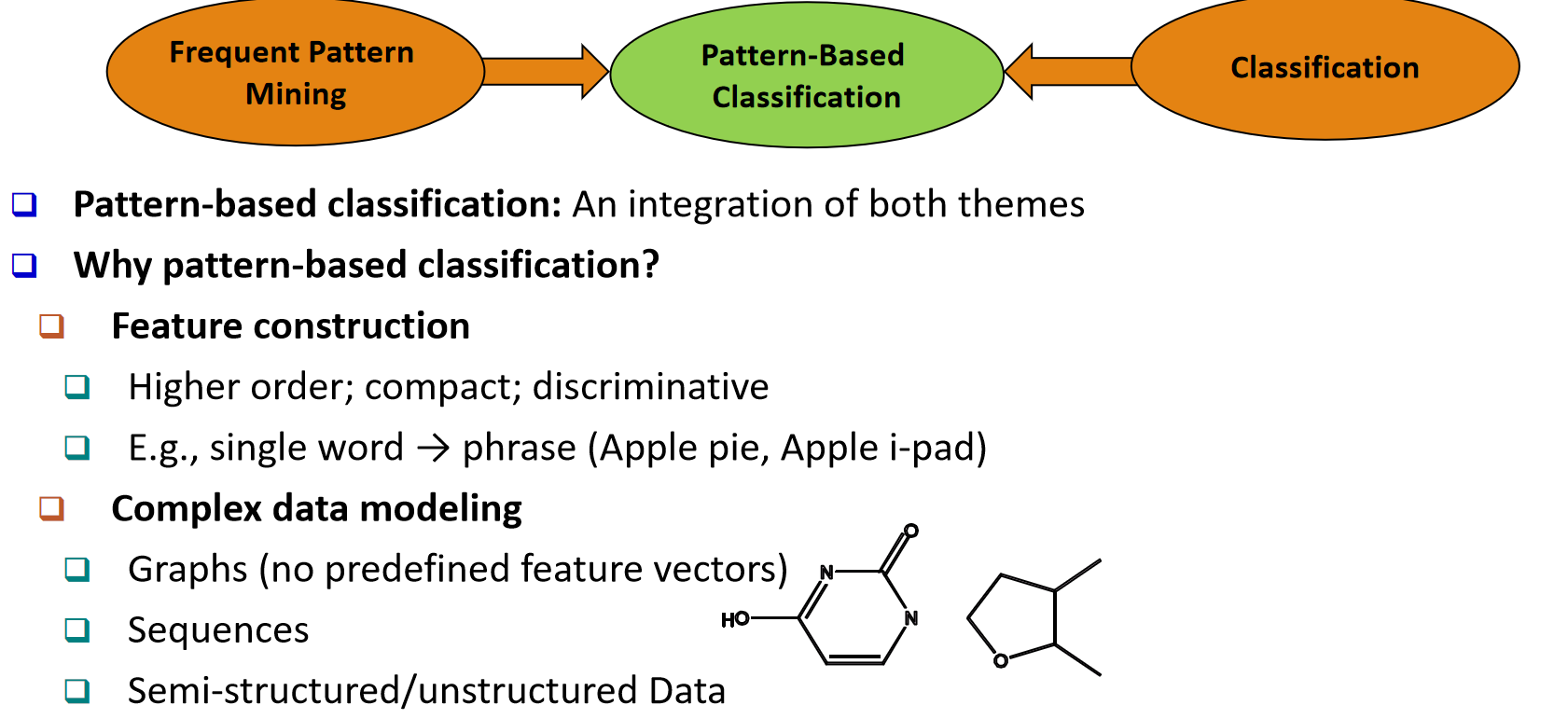
p45 基于模式的分类:为什么?
(Pattern-Based Classification, Why?)
定义
基于模式的分类=把频繁模式挖掘 与分类两类主题进行融合。
为何采用基于模式的分类
-
特征构造
更高阶、更紧凑、区分性更强。
例:由单词提升到短语(如 "Apple pie"、"Apple i-pad"),作为判别性更强的模式特征。
-
复杂数据建模
适用于图数据 (无预定义特征向量)、序列数据 、以及半结构化/非结构化数据等场景。
p46 CBA:基于关联的分类
(Classification Based on Associations)
方法概要
挖掘"高置信度、高支持度"的类别关联规则 。
左部(LHS):多个"属性=取值"的合取;右部(RHS):类别标签。
形式:p1∧p2∧⋯∧pℓ⇒Aclass-label=Cp_1 \land p_2 \land \cdots \land p_\ell \Rightarrow A_{\text{class-label}}=Cp1∧p2∧⋯∧pℓ⇒Aclass-label=C(同时给出 confidence、support)。
按置信度优先,其次支持度 对规则降序排序。
分类时:对测试样本应用第一条匹配的规则 ;若都不匹配,则使用默认规则。
效果
在多项实验中,CBA往往比 某些传统分类方法(如 C4.5)更准确。
原因
同时挖掘多个属性之间的高置信度关联,可弥补只按"单属性逐一考察"的分类器所带来的限制。
弱监督学习
p48 弱监督学习
(Weakly Supervised Learning)
-
半监督学习(Semi-supervised learning)
-
主动学习(Active learning)
-
迁移学习(Transfer learning)
-
远程监督 / 远程标注(Distant supervision)
-
零样本学习(Zero-shot learning)
p49 半监督学习:目标
p50 半监督学习:自训练
(Self-training)
-
一般流程
-
选择一种学习方法(如贝叶斯分类)。
-
用有标注数据训练初始分类器。
-
用该分类器去给无标注数据打标签。
-
从无标注样本中选出置信度最高的一条/一批。
-
将它们及其预测标签并入标注集。
-
重复以上过程。
-
p51 半监督学习:协同训练
(Co-training)
一般流程
-
为有标注数据划分两组彼此不重叠的特征。
-
分别在这两组特征上训练两个分类器 f1f_1f1 与 f2f_2f2(各自只看一组特征)。
-
用 f1f_1f1 与 f2f_2f2 各自去预测无标注样本。
-
由 f1f_1f1 选出置信度最高 的无标注样本,把它及其预测标签加入到 f2f_2f2 的标注集。
-
由 f2f_2f2 选出置信度最高 的无标注样本,把它及其预测标签加入到 f1f_1f1 的标注集。
-
重复步骤 3--5。
p52 半监督学习何时有效?聚类假设
(Clustering Assumption)
-
同一簇中的样本更可能拥有相同标签。
-
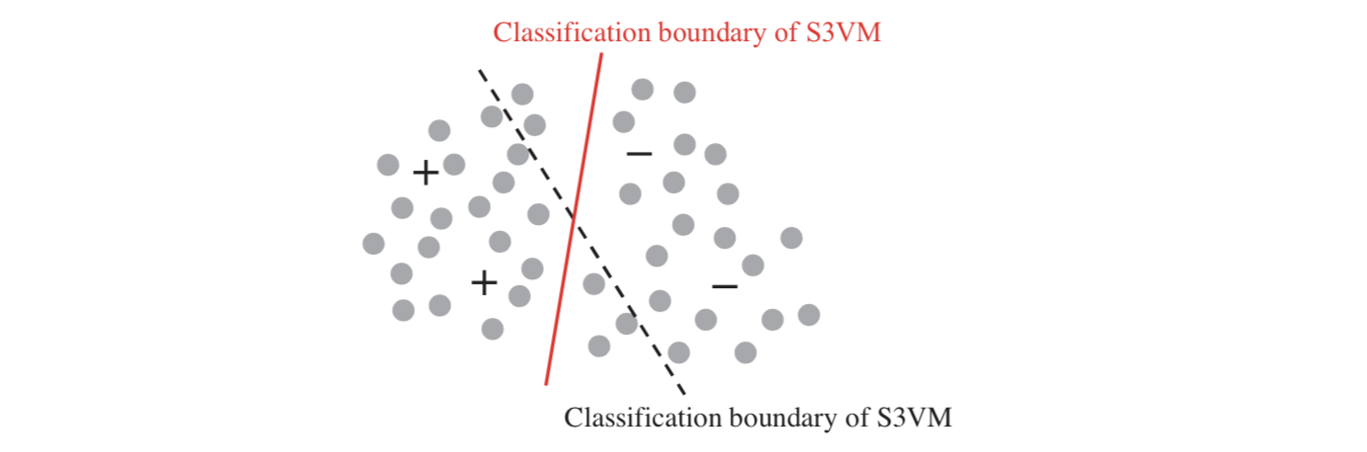
示例:S3VM(半监督 SVM)
-
目标同 SVM:寻找最大间隔超平面;
-
但同时要尽量不破坏无标注数据的簇结构;
-
做法直观上是让决策边界穿过无标注数据的低密度区域(如图所示,红色边界优于虚线边界)
-
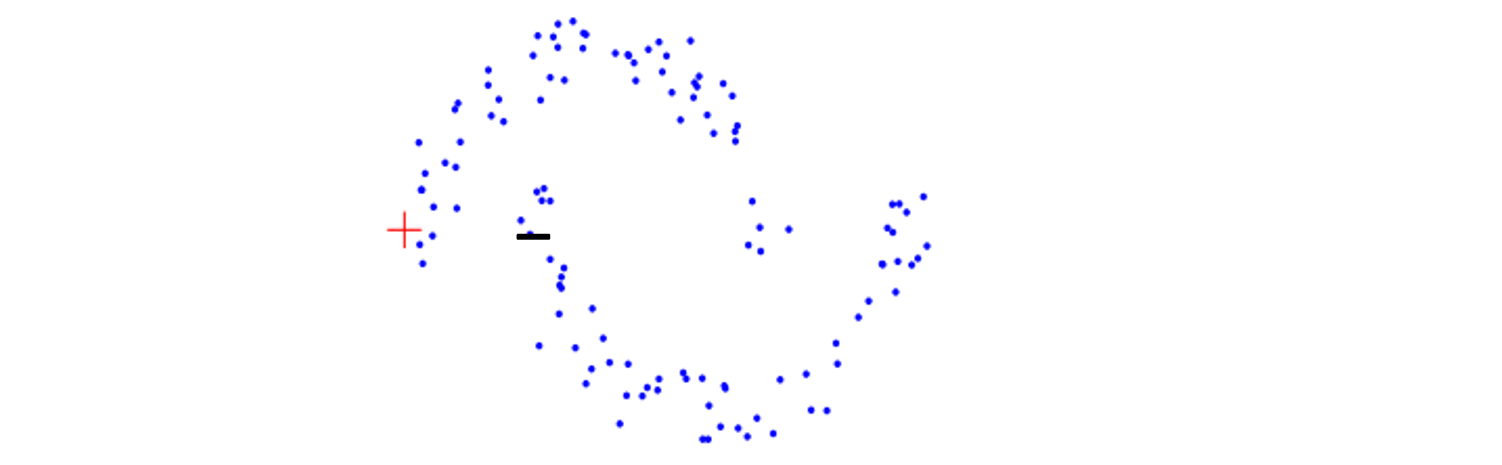
p53 半监督学习何时有效?流形假设
(Manifold Assumption)
-
相近 的样本对更可能拥有相同的类别标签。
-
例子:基于图的半监督学习 (graph-based SSL)。
思想是样本位于低维流形上,利用邻接图/相似度图,使标签在图上平滑传播:彼此"靠近"的点倾向被赋予相同标签。
p54 主动学习(Active Learning)
目标:从无标签样本中挑选"最有价值"的那些,请标注者(oracle)给出标签,以最大化提升分类性能。
池式主动学习(Pool-based active learning):维护一个未标注样本池 U,模型根据策略从 U 中选取样本,请人类标注;将新标注加入训练集 L,重新训练模型,如此循环。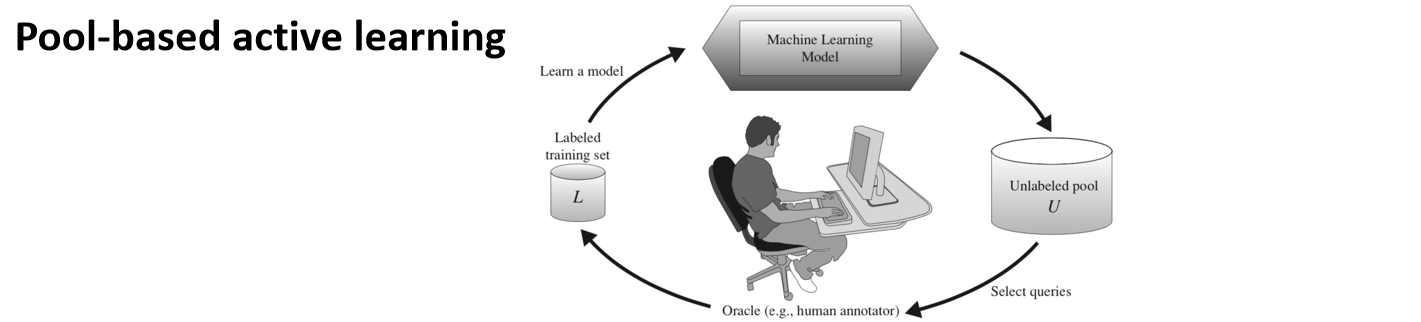
关键:如何选择要查询的样本
--- 不确定性采样(Uncertainty sampling):选模型最不确定的样本
--- 委员会查询(Query-by-committee):多个模型分歧最大的样本
--- 版本空间(Version space):能最大缩小假设空间的样本
--- 决策理论方法(Decision-theoretic approach):选取期望效用最大或期望风险最小的样本
p55 主动学习 vs. 半监督学习(SSL)vs. 传导学习(Transductive Learning)
主动学习:模型在训练过程中向标注者询问 无标签样本的标签(从未标注池中挑选样本 → 人工给真值 → 加入标注集 → 继续训练),最终对测试集做预测。
纯半监督学习:训练阶段同时利用 有标注数据与无标注数据(不询问人工标签),学到的模型用于任意测试集的预测。
传导学习:训练时利用有标注数据与特定那批无标注数据 ,目标是只对这批无标注数据本身给出预测(不追求对未来未知测试集的泛化)。
p56 迁移学习
(Transfer Learning)
目标:从一个或多个源任务中提取可迁移的知识,并将其应用到目标任务上,以提升目标任务的表现。
示例:
源任务:电子产品评论的情感分类。
目标任务:电影评论的情感分类。
对比说明:
传统学习:每个不同任务各自独立训练,一个任务的知识不会用于另一个任务。
迁移学习:先在源任务上学到知识/表征,再把这些知识迁移到目标任务,在较少目标数据的情况下也能取得更好的效果

p57 TrAdaBoost
General strategy(总体策略)
基于实例的迁移学习:对源任务 中的一部分样本重新加权 ,并用它们来学习目标任务 。直觉:把与目标最相关/相似的源数据"迁"过来、权重更高;不相关的权重更低。
Details(细节)
Boosting:每个基学习器更关注"难样本"(例如被上一个基学习器误分类的样本)。
TrAdaBoost:若某个源域样本 被误分类,就降低 它的权重(说明它与目标任务不太相关)。
Key challenge in transfer learning(关键挑战)
负迁移(negative transfer)。需要量化源域与目标域/任务的差异 :如定义迁移间隔(transfer margin)、**分歧/散度度量(divergence metric)**等来控制或检测负迁移。
Related problems(相关问题)
多任务学习;"预训练 + 微调"范式等。
p58 远程监督
(Distant Supervision)
目标:自动生成大量带标签的样本。
生成标签的特点:噪声较大,但规模很大。
示例一(情感分类:正/负):若一条推文包含 ":-)" 则视为正样本;若包含 ":-(" 则视为负样本。
示例二(主题分类:如新闻、健康、科学、游戏等):若推文包含网址,使用该网址在 ODP(Open Directory Project)中的类别作为推文的标签;若包含 YouTube 视频链接,则将该视频的类别作为推文的标签。
p59 远程监督
应用
--- 社交媒体帖子分类
--- 自然语言处理中的关系抽取
活跃研究方向
--- 如何设计并获取标注函数(labeling function)
主要挑战
--- 噪声标签:例如推文里的 ":)" 可能表达中性,甚至负面情绪
p60 零样本学习
(Zero-shot Learning)
动机示例:
--- 已训练的分类器只能在 owl / dog / fish 间分类,但测试图像其实是 cat。
目标:
--- 预测训练阶段从未见过的类别的样本标签。
一般策略:
--- 利用外部知识或辅助信息(如属性描述、文本语义、知识图谱、词向量等)把未见类与已见类建立联系。
应用:
--- 图像识别
--- 神经活动识别
--- 图(网络)异常检测
广义零样本学习(GZSL):
--- 测试样本可能来自已见类或新类,模型需同时识别两者。
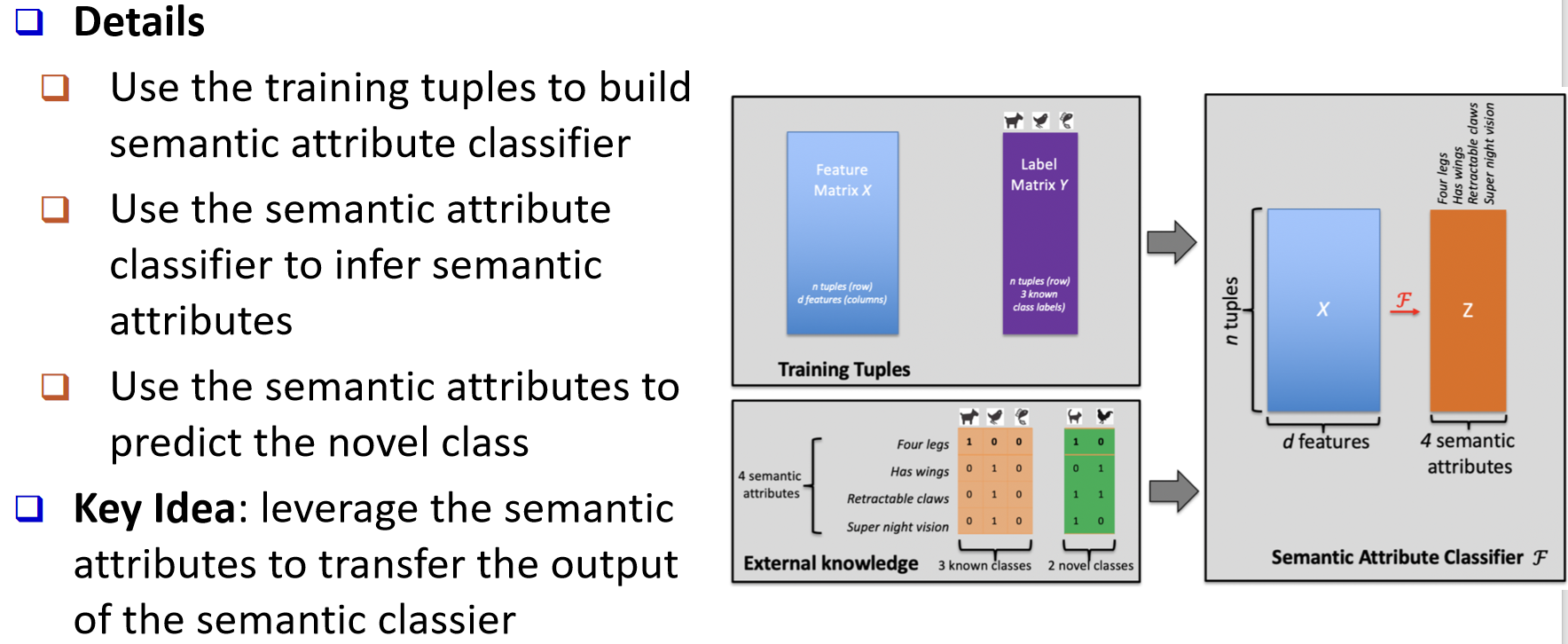
p61 语义属性分类器
(Semantic attribute classifier)
Details
--- 用训练样本训练一个语义属性分类器 。
--- 用该分类器为样本推断语义属性 (如"四条腿、会飞、可伸缩爪、夜视强"等)。
--- 基于得到的语义属性,再去预测未见类别。
Key Idea
--- 借助语义属性 把已学到的表示迁移 到新类:先从特征矩阵 XXX 预测属性向量 ZZZ,再依据"外部知识"给出的属性---类别表,完成对新类别的判别
富数据类型的分类
p63 富数据类型的分类
(Classification with Rich Data Type)
流数据分类(Stream Data Classification)
序列分类(Sequence Classification)
图数据分类(Graph Data Classification)
p64 流数据分类
(Stream Data Classification)
动机示例
--- 用数据挖掘工具检测欺诈交易 。
--- 交易记录以数据流 形式、在不同时间点顺序到达 。
--- 典型流程:先用当前训练集建模 → 持续接收新数据 → 反复增量更新/再训练。
挑战
--- 到达速度高 :需要实时或近实时处理。
--- 长度无界 :数据流理论上无限长 。
--- 仅一次遍历约束 :通常只能对数据一遍扫描 、难以多次回放。
--- 概念漂移 :数据分布与目标概念会随时间变化,模型需自适应。
p65 基于集成的流数据分类
(Stream Data Classification via Ensemble)
关键思想
--- 只用最新到达的分块(chunk)来训练新的分类器,以适应数据流的高到达速率 。
--- 对每个到来的样本仅访问一次 :既用于训练当前分类器,也用于更新已有分类器的权重 (满足"一次遍历"约束)。
--- 动态调整各基分类器的权重 ,让模型更关注与当前分布最相关的分块 ,从而逐步捕捉概念漂移 。
(图示:随着时间推移,基于历史的若干分类器与当前分块上的分类器组成一个加权集成。

p66 流数据分类(补充)
其他应用
营销
网络监控
传感器网络
VFDT(Very Fast Decision Tree)
Hoeffding 树:利用训练样本的抽样子集 (基于 Hoeffding 界做分裂决策)来在线增量地构建决策树。
滑动窗口机制:让分类器聚焦最新的数据流分块,适应概念漂移。
p67 序列分类
定义
序列:按顺序排列的取值列表 (x1,x2,...,xT)(x1,x2,...,xT)。
例子:一句话、一个 DNA 片段、某位客户随时间的交易序列等。
任务
训练一个分类器来预测整个序列的标签。
示例:
--- NLP 中判断句子情感的正/负;
--- 基因组分析中区分编码区与非编码区;
--- 营销中区分高价值客户与普通客户。
其他形式
对每个时间点都进行标注/分类(序列标注),如词性标注、命名实体识别、时间序列的逐步状态分类等。
p68 通过特征工程做序列分类
(Sequence Classification via Feature Engineering)
General ideas
将输入序列转换为一个特征向量 ;
用常规分类器进行训练。
Symbolic sequence:n-gram
输入 DNA 片段:ACCCCCGT;
输出:用N-gram 构造候选特征(如 unigram、bigram),再得到
--- 二值特征向量(是否出现);
--- 频次特征向量(出现次数)。

Numerical sequence
先离散化为符号序列,再按上面的方法做特征化并分类。
More recent approaches
RNN 及其相关方法(如 LSTM/GRU、Transformer 等)直接对序列建模。
p69 基于距离 / 核函数的序列分类
(Sequence Classification via Distance/Kernel Function)
观察
K-NN 分类器依赖距离或相似度度量 ;
非线性 SVM 依赖核函数。
一般策略
为序列设计合适的距离度量或核函数。
序列上的距离度量
欧氏距离(Euclidean);
动态时间规整(DTW),用于处理时间轴上的拉伸/压缩等对齐偏差。
序列上的核函数
字符串核(String kernel)等,可将序列相似度嵌入到核方法中
p70 图数据分类
(Graph Data Classification)
图数据(又称网络数据):由节点 与其间的边 组成的集合。
示例:社交网络、电力网络、交易网络、生物网络等。
节点级 vs 图级 分类:
--- 节点级分类 :给单个节点打标签(例:网页分类)。
--- 图级分类 :给整个图打标签(例:分子/化合物毒性分类)。
p71 图数据分类的方法
(Graph Data Classification Methods)
基于特征工程的图分类
--- 为每个节点或每个图提取一组描述性特征
--- 将特征送入常规分类器,训练节点级或图级分类器
--- 节点级特征:度、三角形数量、中心性、PageRank 等
--- 图级特征:规模(节点/边数)、直径、三角形数量等
--- 另一思路:用**深度学习(GNN)**自动学习节点/图级表征
基于相似度/近邻度的图分类
--- 度量节点或图之间的相似度/近邻度
--- 基于该度量构建KNN 类分类器
其他相关技术
p73 多类别分类
(Multiclass Classification)
二分类 vs 多分类
--- 二分类:标签只有两类。
--- 多分类:标签为 c>2c>2 个类别。
多分类的常见方法
--- 一对其余(OVA):训练 mm 个二分类器;第 jj 个分类器区分"类别 jj"与"剩余所有类别"。
--- 两两对比(AVA / one-vs-one):为任意两类各训练一个二分类器,共 c(c−1)/2c(c−1)/2 个。
--- 纠错编码(Error-correcting coding, ECOC):
为每个类别分配一个纠错码字(如右表)。
训练若干二分类器对应码字的每一位。
预测时把各位的输出拼成码字,选与某类码字距离最近的类别。
这样能提升多分类的鲁棒性与准确率(具有纠错能力)。
相关问题
--- 多标签分类:一个样本可同时属于一个或多个类别(与多分类"互斥单标签"不同)

p74 距离度量学习
(Distance Metric Learning)
Setting
自动为给定分类任务学习最优距离度量(如用于 kNN)



p75 分类的可解释性
(Interpretability of Classification)
Setting
--- 指模型用用户可理解的方式解释其分类结果或决策过程的能力。
易于解释的分类器
--- 决策树、线性分类器等。
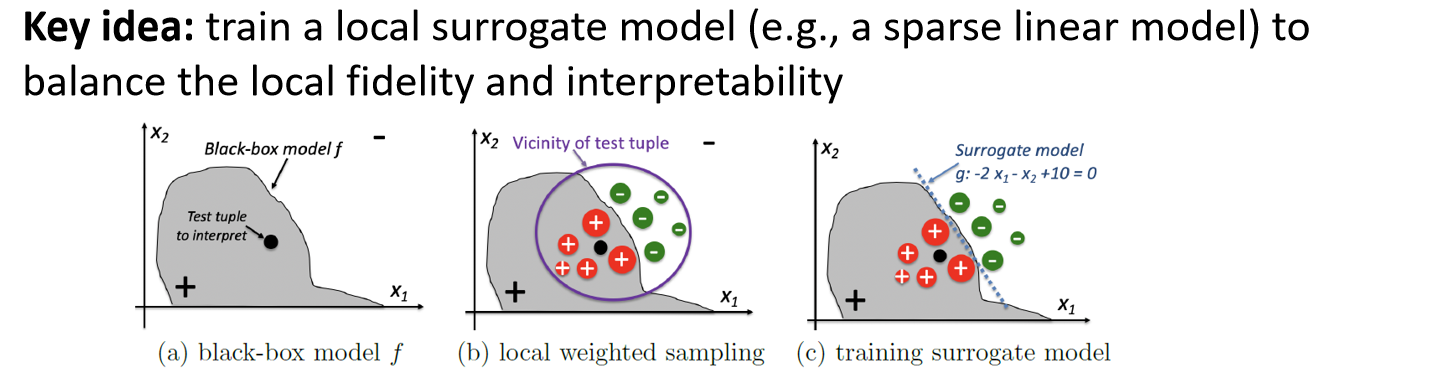
LIME:局部、可解释、与模型无关的解释
--- 关键思想:在待解释样本的局部邻域 里,用采样得到的带权数据训练一个简单的替代模型 (如稀疏线性模型),在局部逼近原黑箱模型 ,权衡"局部拟合度"与"可解释性"。
(图示:a 黑箱模型;b 在测试点附近加权采样;c 训练得到替代模型 g:−2x1−x2+10=0g: -2x_1 - x_2 + 10 = 0g:−2x1−x2+10=0 作为局部解释。)
其他方法
--- 反事实解释(counterfactual explanation)
--- 影响函数(influence function)
p76 遗传算法
(Genetic Algorithms)
关键思想:引入自然进化的理念。
一般流程:
生成由随机规则组成的初始种群;
用比特串表示每条规则;
例:规则 "IF A1 AND NOT A2 THEN C2" 可编码为比特串 "100";
按"适者生存"形成新一代种群;
用分类准确率评估每条规则的适应度;
通过遗传算子产生后代(如交叉、变异);
不断进化,直到种群中每条规则都达到预设适应度阈值。
在数据挖掘中的应用:用于评估/优化其他算法的适应度或直接搜索规则集。
p77 强化学习
(Reinforcement Learning)
关系与分类
--- 分类:收到指导型反馈 (真实类别标签),用来训练出最优分类器。
--- 强化学习:收到评价型反馈(如执行动作后的即时奖励),用来寻找最优动作策略。
多臂老虎机问题
--- 场景:一台有多只拉杆的老虎机;每个拉杆对应一个动作 (如给用户展示哪条广告),其回报未知;目标是决定每次应选择哪个动作。
--- 常见算法:ε\varepsilonε-greedy、UCB(Upper Confidence Bound,上置信界)。
应用
--- 在线广告投放
--- 机器人控制
--- 博弈(如国际象棋等)
总结
-
特征选择:过滤法、包裹法、嵌入法
-
贝叶斯信念网络:概率图模型、有向无环图(DAG)
-
支持向量机:最大间隔思想、核技巧
-
基于模式的分类:基于规则的分类、基于模式的分类
-
弱监督学习:半监督学习、主动学习、迁移学习、远程监督、零样本学习
-
富数据类型上的分类:流数据、序列、图数据