技术栈
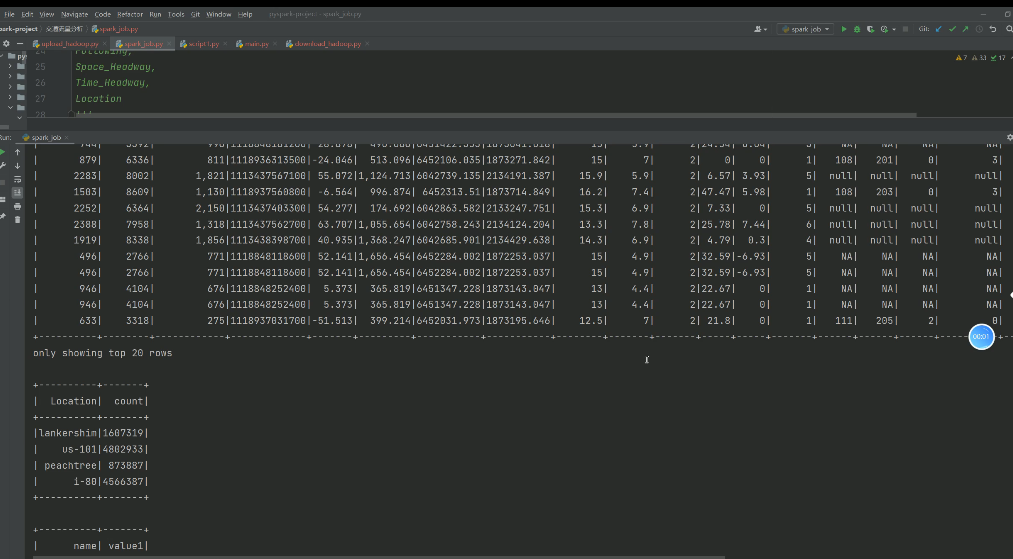
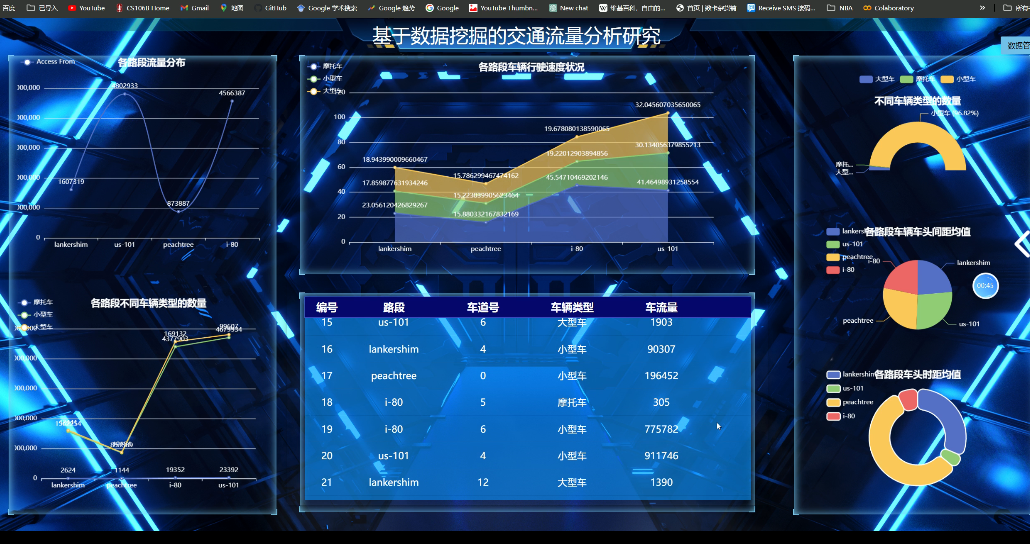
大数据、hadoop、爬虫、spark项目开发设计之基于数据挖掘的交通流量分析研究
一枚小小程序员哈
2025-08-25 13:48
大数据、hadoop、爬虫、spark项目开发设计之基于数据挖掘的交通流量分析研究
大数据
hadoop
爬虫
上一篇:
深度学习:CUDA、PyTorch下载安装
下一篇:
【前沿解析】JavaScript 的未来,将迎来哪些新特性?
相关推荐
boppu
8 小时前
布草特殊污渍去渍剂的种类及作用
大数据
·
人工智能
Achou.Wang
9 小时前
深入理解go语言-第5章 并发编程——Go的灵魂
大数据
·
算法
·
golang
hyf326633
11 小时前
泛程序:从零开始搭建稳定程序项目框架
运维
·
服务器
·
爬虫
·
百度
·
seo
事变天下
12 小时前
迈瑞的足球之夏:从一次救援到全球守护
大数据
·
科技
中微极客
12 小时前
多智能体编排实战:CrewAI vs AutoGen(2026版)
大数据
·
网络
·
人工智能
西邮彭于晏
13 小时前
图文详解:Git分支创建、合并与冲突解决|新手零门槛完整教程
大数据
·
git
·
elasticsearch
IanSkunk
14 小时前
企业AI办公落地技术拆解:从WorkBuddy任务引擎到JOTO实施路径
大数据
·
人工智能
上海心泾国际物流有限公司
14 小时前
2024-2026年进出口报关政策五大变化
大数据
·
经验分享
·
交通物流
Xvisio诠视科技
15 小时前
从“感知”到“理解”:空间计算如何成为具身智能世界模型的“数据底座”?
大数据
·
空间计算
jerryinwuhan
16 小时前
数据预处理技术 2026-2027-1 开篇-课程介绍
大数据
·
python
热门推荐
01
如何新建文件夹? 电脑新建文件夹的4种方法
02
GitHub 镜像站点
03
国内可直接用、免费额度/永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)
04
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
05
微信历史版本含下载地址( Windows PC | 安卓 | MAC )及设置微信不更新
06
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
07
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
08
AI科技热点日报 | 2026年07月01日
09
Agnes AI 免费 API 接入指南:文本、生图、生视频,一套接口全免费
10
2026 年 AI 大模型 & AI 编程工具实战全总结