🌈个人主页: Aileen_0v0
🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|SpringBoot|MySQL
**💫个人格言:"没有罗马,那就自己创造罗马~"**

文章目录
- Redis
- 分布式系统:
- 微服务架构
- 分布式系统中的一些名词解释:
-
- 基本概念
-
- [应⽤(Application)/ 系统(System)](#应⽤(Application)/ 系统(System))
- [模块(Module)/ 组件(Component)](#模块(Module)/ 组件(Component))
- 分布式(Distributed)
- 集群(Cluster)
- [主(Master)/ 从(Slave)](#主(Master)/ 从(Slave))
- 中间件(Middleware)
- 分布式系统的评价指标(Metric):
-
- 可⽤性(Availability) (一个系统的第一要务)
- [响应时⻓(Response Time RT) (衡量服务器性能)](#响应时⻓(Response Time RT) (衡量服务器性能))
- [吞吐(Throughput)vs 并发(Concurrent)](#吞吐(Throughput)vs 并发(Concurrent))
- 分布式系统(引入更多的硬件资源)小结:
Redis
- Redis:实现在内存中存储数据 并实现快速访问的存储系统。它适用于**分布式系统**,分布式系统设计多个进程,每个进程都在不同的主机上,(如果是单机程序想要存储数据到内存中,直接定义一个变量即可 )
- 想要多个服务器共享同一个数据
- 又想让数据存储在内存中
- 就可以使用 Redis
- 如果是使用变量,只能将数据存储在内存中。
- 此外,进存之间具有隔离性,如果想实现进程之间的通信,需要使用**网络**
- Redis 就是基于网络,可以将自己内存中的变量给别的进程或别的主机的进程进行使用。
- MySql:低成本,大存储
- Cache:实现又大又快的存储方式,将Redis和MySQL结合在一起【"二八原则":20%的热点数据,满足80%的访问需求->代价:系统复杂度提升,若数据发生修改,还涉及Redis 和 MySQL 之间数据同步的问题】
- 热点数据(经常访问的数据),使用Redis存储
- 全量数据:使用MySQL存储
- Streaming engine:Redis 的初心:作为消息中间件(也叫:消息队列)->分布式系统下的生产者消费者模型
- Redis 适应->分布式系统
分布式系统:
- 单机架构:只有一台服务器,这个服务器负责所有的工作,结构如下所示:
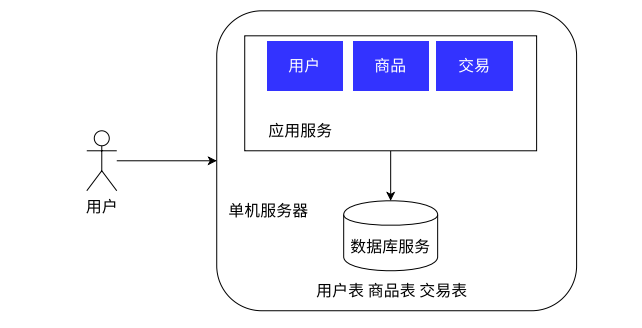
- 右侧方框内就表示一台服务器,用户可以通过网络直接访问到服务器
- 假定服务器是一个电商网站
* 包括两部分:
+ 应用服务:就是我们用程序(eg:C++,Java,HTTP,Spring 写的服务器程序)
+ 服务器服务:就是用数据库来存储数据(eg:MySQL,Redis)
- MySQL:是一个 客户端-服务器 的程序- 绝大多数公司使用的都是单机架构,但是随着业务增长,用户量增加,一台主机难以应付时,就需要多台主机
- 引入多台主机,我们就可以称为:分布式系统
应用服务器和存储服务器
- 对于数据量较大,用户量多的场景我们可以引入多台服务器来解决:
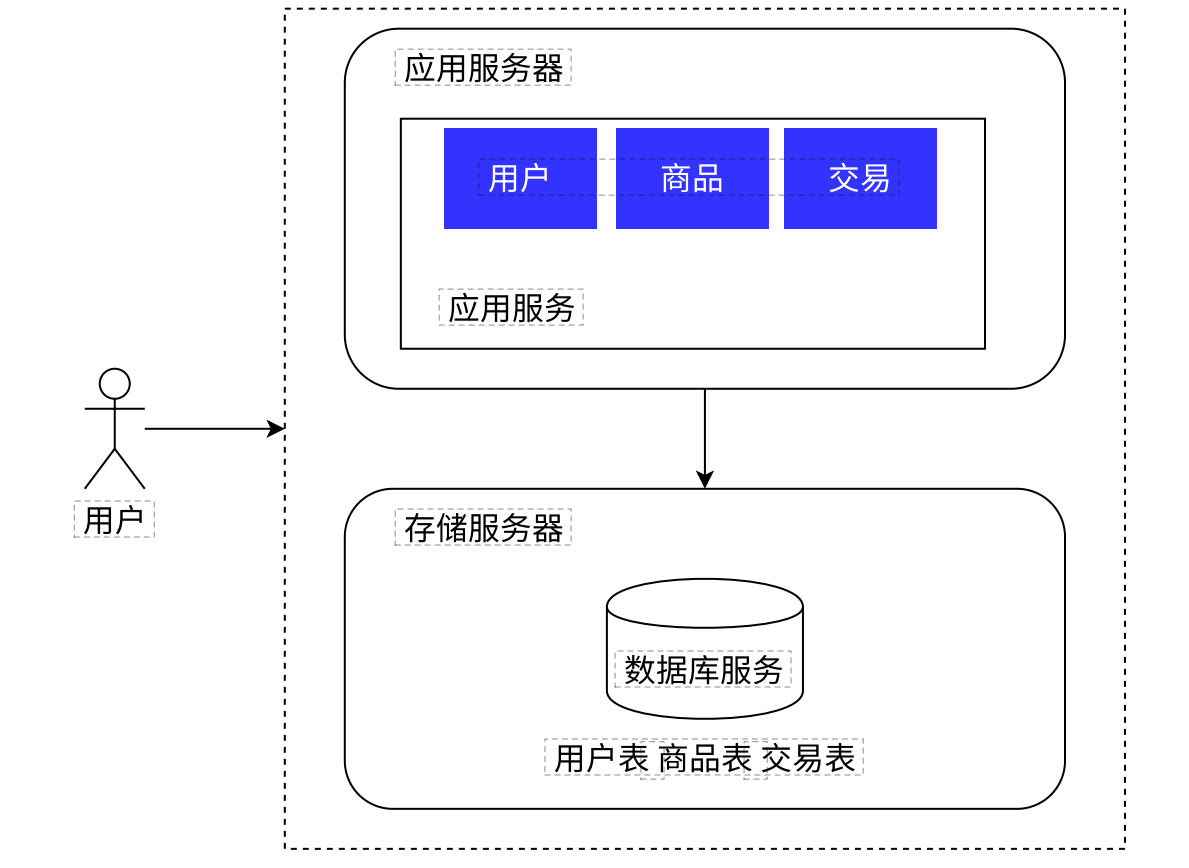
- 应用服务器:里面包含很多的业务逻辑, 吃 CPU&内存
- 数据库服务器:需要更大的硬盘空间,更快的数据访问速度
- 但是,随着请求量的增加,我们需要进一步的调整我们服务器的结构:
应用服务器的集群架构:
- 负载均衡:相当于项目经理,它需要将任务分配给相应的人员**,引入负载均衡可以解决大请求量的问题**。
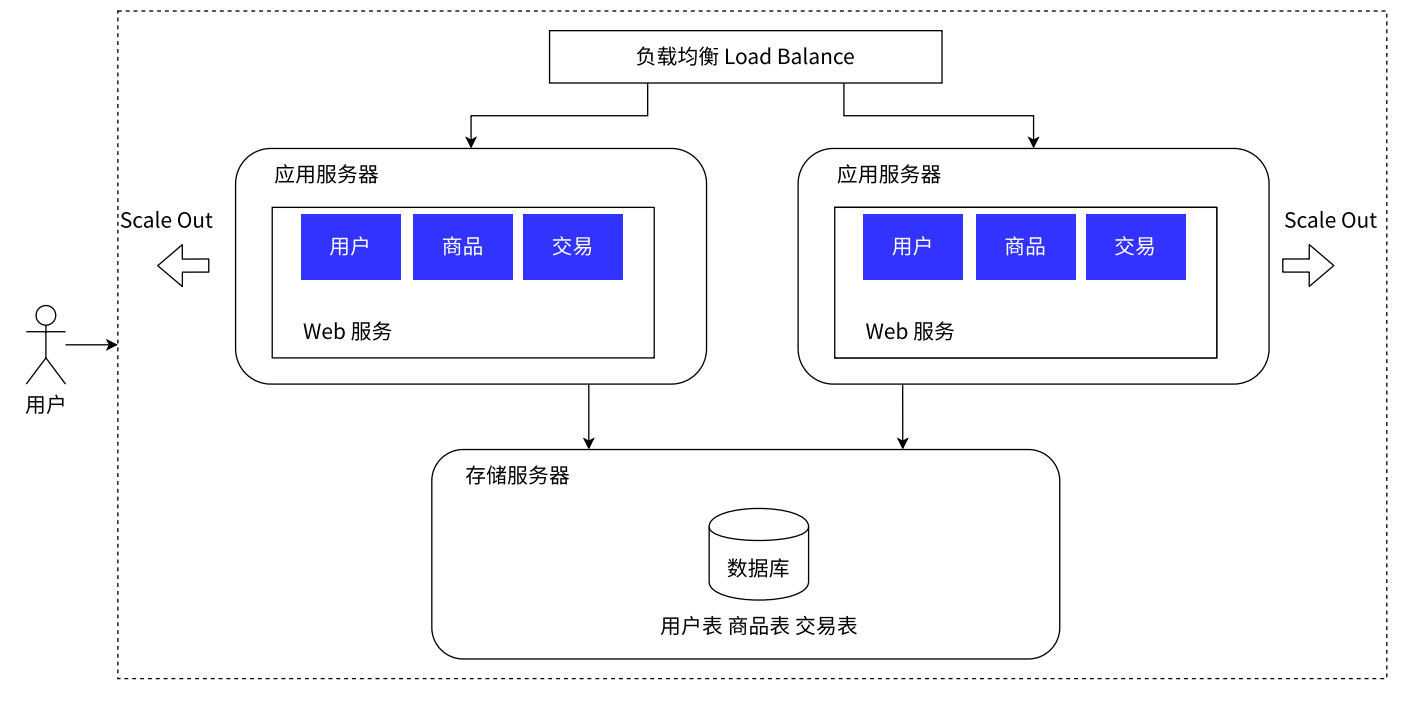
- 虽然我们可以通过上述,增加应用服务器的操作来处理高请求量的问题,但是对于存储服务器来说,要承担的请求量也就更多了。
- 解决方案:开源+节流
- 开源:就是将数据库的读写分开操作
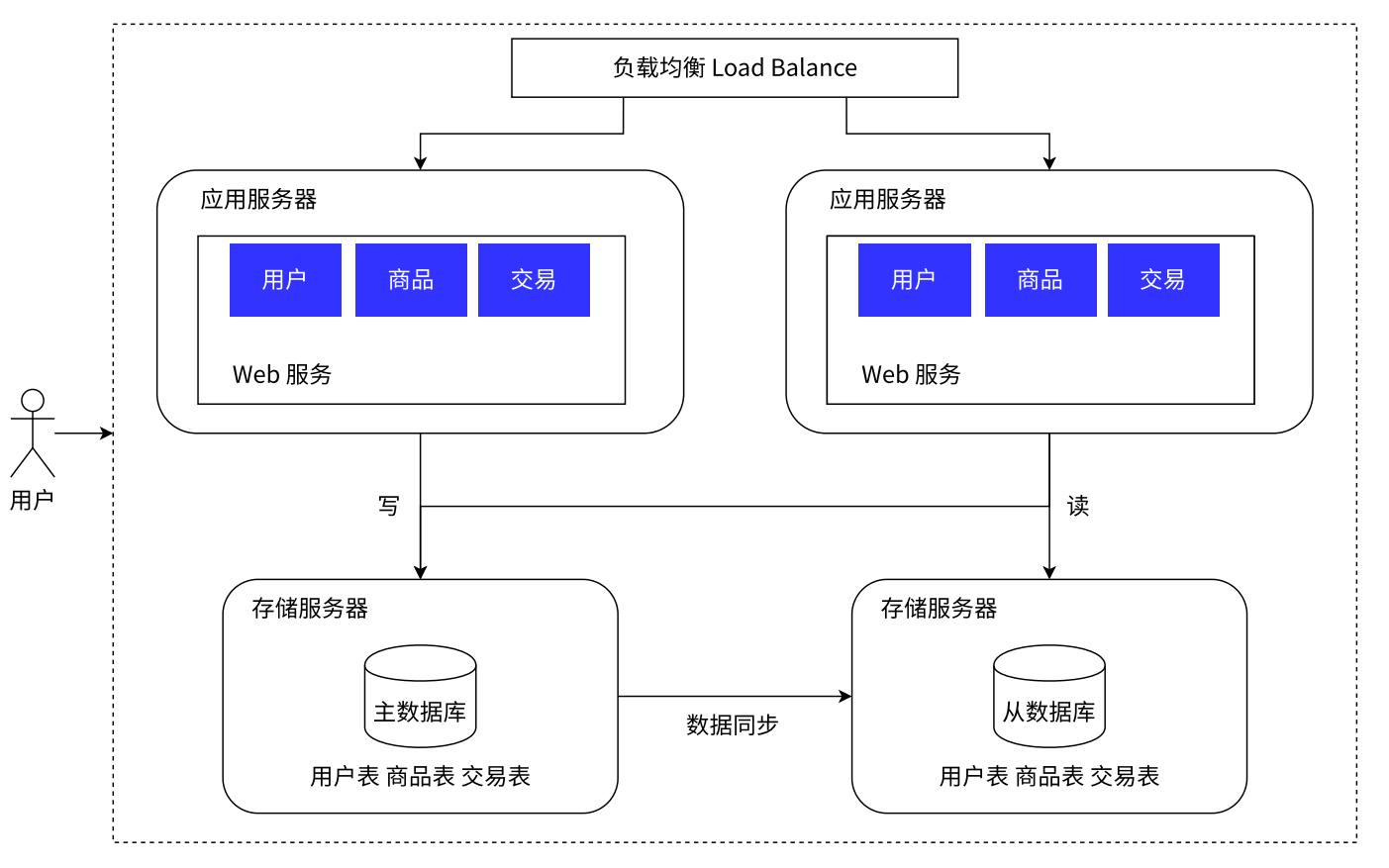
* **数据库分开操作:引入主数据库和从数据库即可实现,主数据库负责写操作,从数据库负责读操作。**(对于数据库进一步划分)缓存服务器
- 虽然我们引入了服务器解决数据库压力的问题,但是在对于数据库的访问操作一直都有个弱点,就是访问速度慢.
- 为了解决数据库访问速度慢的问题 ,我们引入了缓存服务器(其实就是 Redis)
- 缓存服务器:专门将分开的冷热数据中的热数据存储到缓存中,缓存的访问速度比数据库访问速度快很多。
- 20%的数据支持 80%的访问量.
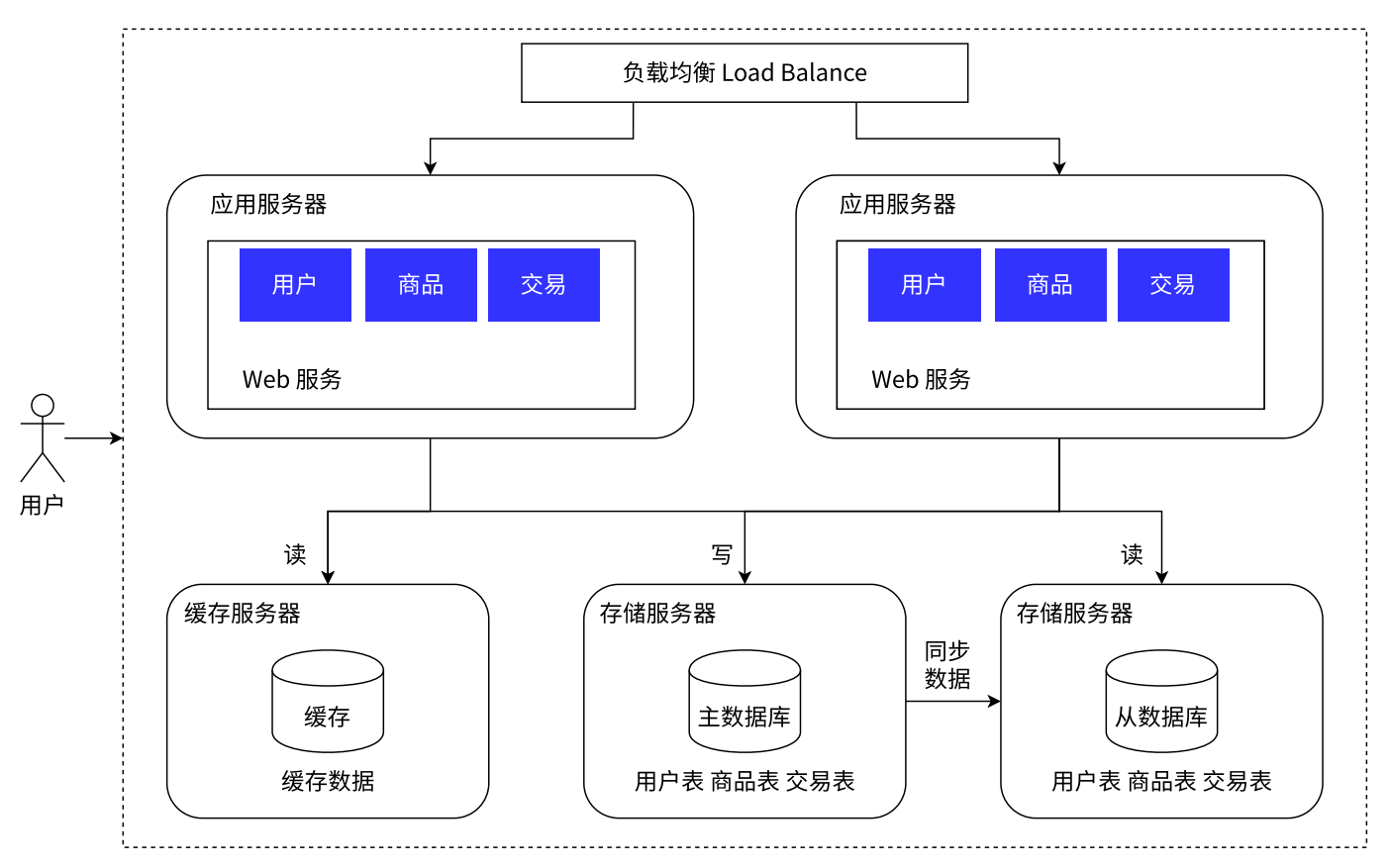
- 通过缓存我们就能帮数据库负重前行
- 业务决定技术~
小结:
:::info
- 负载均衡:解决请求量过大的问题
- 分库分表:解决存储空间不足问题
- 缓存服务器:解决访问速度过慢的问题
:::
微服务架构
- 随着⼈员增加,业务发展,我们将业务分给不同的开发团队去维护,每个团队独⽴实现⾃⼰的微
服务,然后互相之间对数据的直接访问进⾏隔离,可以利⽤ Gateway、消息总线等技术,实现相互之
间的调⽤关联。甚⾄可以把⼀些类似⽤⼾管理、安全管理、数据采集等业务提成公共服务。
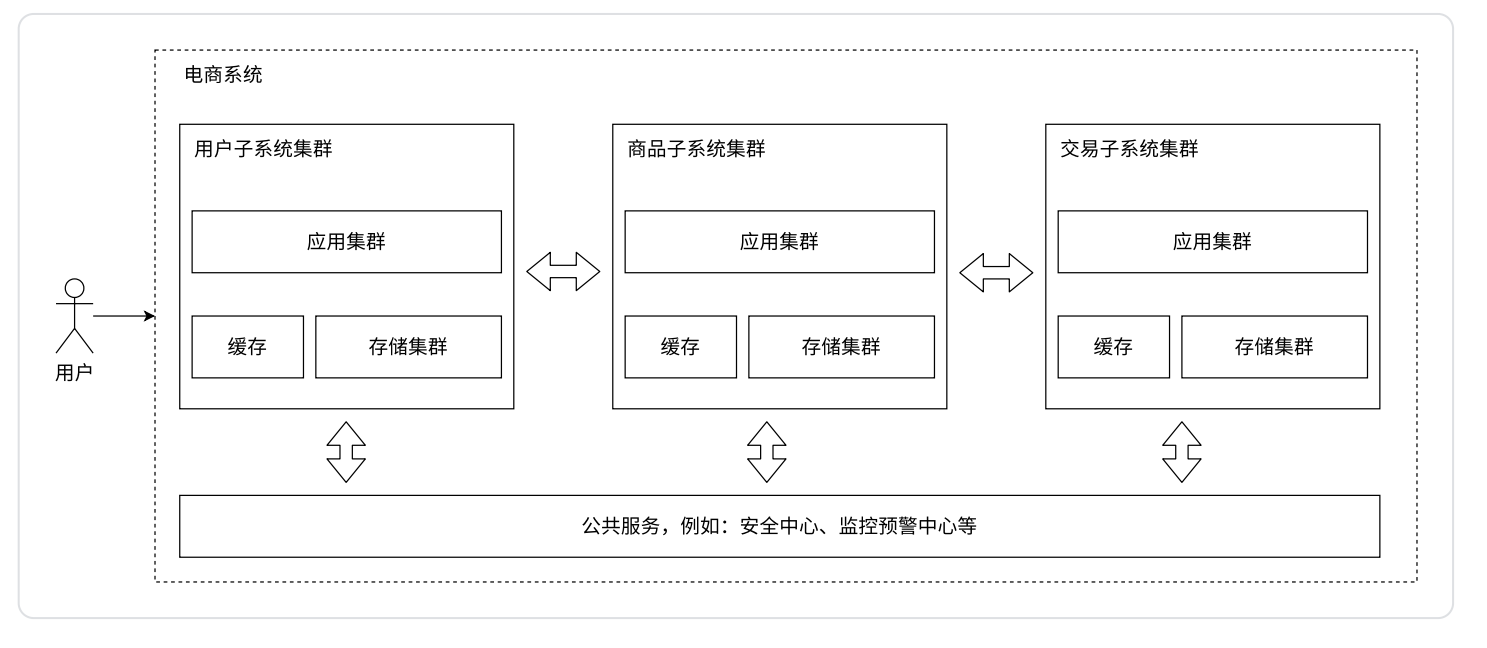
- 之前一个服务器程序里面做了很多的业务,这会导致一个服务器的代码变得越来越复杂,为了便于代码的维护,我们可以将复杂的服务器拆分成更多的,功能更单一,但是更小的服务器
- 按照功能,我们可以将一个服务器,拆分成多组微服务,如上所示,就可以将将人员的组织结构进行相应的分配了。
微服务的问题
- 1.系统的性能下降(解决方案:花钱买更多的硬件资源)
- 拆出来更多的服务,多个功能之间要更依赖网络通信,网络通信可能会比硬盘还慢。
- 2.系统复杂程度提高,可用性收到影响
- 服务器更多了,出现问题的概率就更大了,这就需要一系列的手段(监控警报,以及配套的运维人员)来保证系统的可用性。
微服务的优势
- 1.解决了人的问题
- 2.使用微服务,更方便于功能的复用
- 3.可以给不同的服务进行不同的部署
分布式系统中的一些名词解释:
基本概念
应⽤(Application)/ 系统(System)
- 为了完成⼀整套服务的⼀个程序或者⼀组相互配合的程序群。
- ⽣活例⼦类⽐:为了完成⼀项任务,⽽搭建的由⼀个⼈或者⼀群相互配的⼈组成的团队。
模块(Module)/ 组件(Component)
- 一个应用,里面有很多个功能,每个独立的功能就可以称为是一个:模块/组件。
分布式(Distributed)
- 引入多个主机/服务器,协同配合完成一系列工作。
- ⽣活例⼦类⽐:为了更好的满⾜现实需要,⼀个在同⼀个办公场地的⼯作⼩组被分散到多个城市的不同⼯作场地中进⾏远程配合⼯作完成⽬标。跨主机之间的模块之间的通信基本要借助⽹络⽀撑完成。
集群(Cluster)
- 引入多个主机/服务器,协同配合完成一系列工作。
- 通常不⽤太严格区分两者的细微概念,细究的话,分布式强调的是物理形态,即⼯作在不同服务器上并且通过⽹络通信配合完成任务;⽽集群更在意逻辑形态,即是否为了完成特定服务⽬标。
主(Master)/ 从(Slave)
- 主从结构是分布式系统中一种比较典型的结构。多个服务器节点,其中一个是主,另外的是从,从节点的数据要从主节点这里同步过来。
- ⽐如 :MySQL 集群中,只有其中⼀台服务器上数据库允许进⾏数据的写⼊(增/删/改),其他数据库的数据修改全部要从这台数据库同步⽽来,则把那台数据库称为主库,其他数据库称为从库。
中间件(Middleware)
- 跟业务无关的服务。类提供不同应⽤程序⽤于相互通信的软件,即处于不同技术、⼯具和数据库之间的桥梁。
- ⽣活例⼦类⽐:⼀家饭店开始时,会每天去市场挑选买菜,但随着饭店业务量变⼤,成⽴⼀个采购部,由采购部专职于采买业务,称为厨房和菜市场之间的桥梁。
- 和业务无关的服务:
- 1.数据库
- 2.缓存
- 3.消息队列
- ...
分布式系统的评价指标(Metric):
可⽤性(Availability) (一个系统的第一要务)
- 考察单位时间段内,系统可以正常提供服务的概率/期望。
- 例如: 年化系统可⽤性 = 系统正常提供服务时⻓ / ⼀年总时⻓。这⾥暗含着⼀个指标,即如何评价系统提供⽆法是否正常,我们就不深⼊了。平时我们常说的 4 个 9 即系统可以提供 99.99% 的可⽤性,5 个 9 是 99.999% 的可⽤性,以此类推。我们平时只是⽤⾼可⽤(High Availability HA)这个⾮量化⽬标简要表达我们系统的追求。
响应时⻓(Response Time RT) (衡量服务器性能)
- 指⽤⼾完成输⼊到系统给出⽤⼾反应的时⻓。
- 例如点外卖业务的响应时⻓ = 拿到外卖的时刻 - 完成点单的时刻。通常我们需要衡量的是最⻓响应时⻓、平均响应时⻓和中位数响应时⻓。这个指标原则上是越⼩越好,但很多情况下由于实现的限制,需要根据实际情况具体判断
吞吐(Throughput)vs 并发(Concurrent)
- 吞吐量:系统处理请求的能力
- 并发:同一时刻支持请求的最大数量
- 例如⼀条辆⻋道⾼速公路,⼀分钟可以通过 20 辆⻋,则并发是 2,⼀分钟的吞吐量是 20。实践 中,并发量往往⽆法直接获取,很多时候都是⽤极短的时间段(⽐如 1 秒)的吞吐量做代替。我们平时⽤⾼并发(Hight Concurrnet)这个⾮量化⽬标简要表达系统的追求。
分布式系统(引入更多的硬件资源)小结:
- 1.单机架构(应用程序+数据库服务器)
- 2.数据库和应用程序分离
- 应用程序和数据库服务器分别放到不同的主机上部署
- 3.引入负载均衡,应用服务器集群
- 通过负载均衡,比较均匀地将请求分发给集群中的引用服务器
- 4.引入读写分离,数据库主从结构
- 一个数据库节点作为主节点,其它 N 个数据库节点作为从节点.
- 主节点负责写数据;
- 从节点,负责读数据.
- 主节点需要将修改过的数据同步给从节点
- 一个数据库节点作为主节点,其它 N 个数据库节点作为从节点.
- 5.引入缓存,将冷热数据分离
- 二八原则,进一步提升服务器针对请求的处理能力,Redis 在分布式系统中,通常扮演着缓存这样的角色。
- **引入缓存,可能会出现的问题:**数据库和缓存的数据不一致。
-
- 引入分库分表,数据库能够进一步扩展存储空间。
- 7.引入微服务,从业务上进一步拆分应用服务器。
- 从业务功能的角度,将引用服务器拆分成更多功能更加单一的,更简单,更小的服务器。