一、RAG最佳实践和调优
只记录一些我个人认为比较常用的,完整笔记链接:www.codefather.cn/course/1915...
文档收集与切割环节
元数据标注
(1)可以手动添加单个文档的元信息
java
documents.add(new Document(
"案例编号:LR-2023-001\n" +
"项目概述:180平米大平层现代简约风格客厅改造\n" +
"设计要点:\n" +
"1. 采用5.2米挑高的落地窗,最大化自然采光\n" +
"2. 主色调:云雾白(哑光,NCS S0500-N)配合莫兰迪灰\n" +
"3. 家具选择:意大利B&B品牌真皮沙发,北欧白橡木茶几\n" +
"空间效果:通透大气,适合商务接待和家庭日常起居",
Map.of(
"type", "interior", // 文档类型
"year", "2025", // 年份
"month", "05", // 月份
"style", "modern", // 装修风格
)));(2)利用DocumentReader批量添加
java
// 提取文档倒数第 3 和第 2 个字作为标签
String status = fileName.substring(fileName.length() - 6, fileName.length() - 4);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.withAdditionalMetadata("status", status)
.build();效果如图
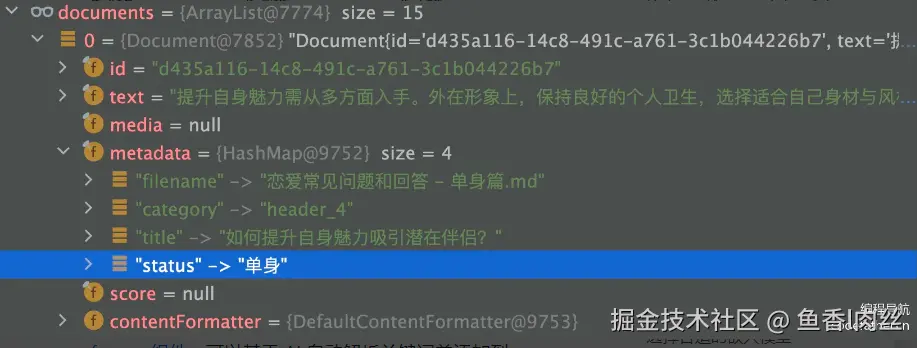
(3)利用AI自动生成元信息的Transformer组件,可以基于AI自动解析关键词并添加到元信息中 大致流程为:
- new一个KeywordMetadataEnricher对象,指定AI大模型和要添加的元信息个数KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.dashscopeChatModel, 5);
- 调用apply方法,传入原始文档return enricher.apply(documents);
java
@Component
class MyKeywordEnricher {
@Resource
private ChatModel dashscopeChatModel;
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.dashscopeChatModel, 5);
return enricher.apply(documents);
}
}
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
// 自动补充关键词元信息
List<Document> enrichedDocuments = myKeywordEnricher.enrichDocuments(documents);
simpleVectorStore.add(enrichedDocuments);
return simpleVectorStore;
}效果如下:
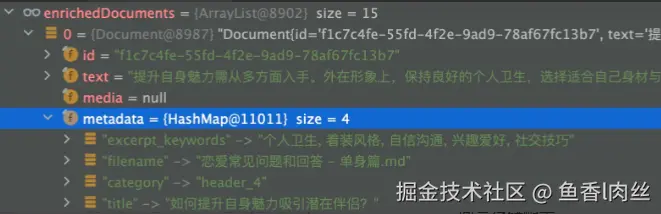
文档过滤和检索环节
多查询扩展
在多轮对话中,用户的输入提示词可能不完整或有歧义,多查询扩展技术可扩大检索范围,提高相关文档召回率,但是要注意:
- 设置查询扩展数量不宜过多,否则将影响性能增加成本
- 保留原始查询核心语义,确保召回文档相关
在编程中的实现如下:
java
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("谁是程序员鱼皮啊?"));
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("genre", "fairytale")
.build())
.build();
// 直接用扩展后的查询来获取文档
List<Document> retrievedDocuments = documentRetriever.retrieve(query);
// 输出扩展后的查询文本
System.out.println(query.text());多查询扩展的完整使用流程可以包括三个步骤 1.使用扩展后的查询召回文档:遍历扩展后的查询列表,对每个查询使用 DocumentRetriever来召回相 关文档。 2.整合召回的文档:将每个查询召回的文档进行整合,形成一个包含所有相关信息的文档集合。(也可以使用 文档合并器 去重) 3.使用召回的文档改写 Prompt:将整合后的文档内容添加到原始 Prompt 中,为大语言模型提供更丰富的上下文信息。 需要注意,多查询扩展会增加查询次数和计算成本,效果也不易量化评估,所以个人建议慎用这种优化方式。
查询重写和翻译
该技术可以使查询更精确和专业,但是要注意保持查询语义完整 主要应用: - 使用RewriteQueryTransformer优化查询结构 - 配置TranslationQueryTransformer支持多语言 参考官方文档实现查询重写
大致流程:
- 用ChatModel构建一个查询重写器
- 调用查询重写器的transform方法,参数是一个Query类对象
java
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel) {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
// 创建查询重写转换器
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}应用查询重写器
java
@Resource
private QueryRewriter queryRewriter;
public String doChatWithRag(String message, String chatId) {
// 查询重写
String rewrittenMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
.user(rewrittenMessage)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}错误处理机制
经过前面的文档检索,系统已经获取了与用户查询相关的文档。此时,大模型需要根据用户提示词和检索内容生成最终回答。然而,返回结果可能仍未达到预期效果,需要进一步优化。 在实际应用中,可能出现多种异常情况,如找不到相关文档、相似度过低、查询超时等。良好的错误处理机制可以提升用户体验。 异常处理主要包括:
- 允许空上下文查询(即处理边界情况)
- 提供友好的错误提示
- 引导用户提供必要信息
边界情况可使用SpringAI的ContexualQueryAugmenter上下文查询增强器:
java
RetrievalAugmentationAdvisor.builder()
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.build()
)如果不使用自定义处理器,或者未启用"允许空上下文选项,系统在找不到相关文档时会默认改写用户查询 userText :The user query is outside your knowledge base.Politely inform the user that you can't answer it. 效果如图:
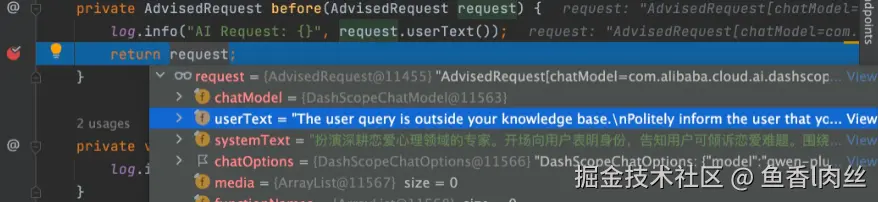 如果启用了"允许空上下文"系统会自动处理空Prompt不会改写用户提示词 也可以自定义错误逻辑处理,这里运用工厂模式创建自定义的ContexualQueryAugmenter:
如果启用了"允许空上下文"系统会自动处理空Prompt不会改写用户提示词 也可以自定义错误逻辑处理,这里运用工厂模式创建自定义的ContexualQueryAugmenter:
java
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回答恋爱相关的问题,别的没办法帮到您哦,
有问题可以联系编程导航客服 https://codefather.cn
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}为什么要用工厂模式?因为我们可能要有许多上下文查询增强器,每个增强器的用处可能不同,如有的进行错误处理有的进行查询改写,这时候运用工厂模式可以创建许多不同的实例,实现代码解耦,提高复用性。 该工厂类的createInstance方法返回了一个ContexualQueryAugmenter对象,关键在于这行代码.emptyContextPromptTemplate(emptyContextPromptTemplate),这里定义了用户提供空提示词时的回复模板
接下来给检索增强Advisor应用该下文查询增强器(上下文查询增强是检索增强方法中的其中一个)
java
RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
.build();