一、负载均衡四大层级架构
现代应用流量调度全景图
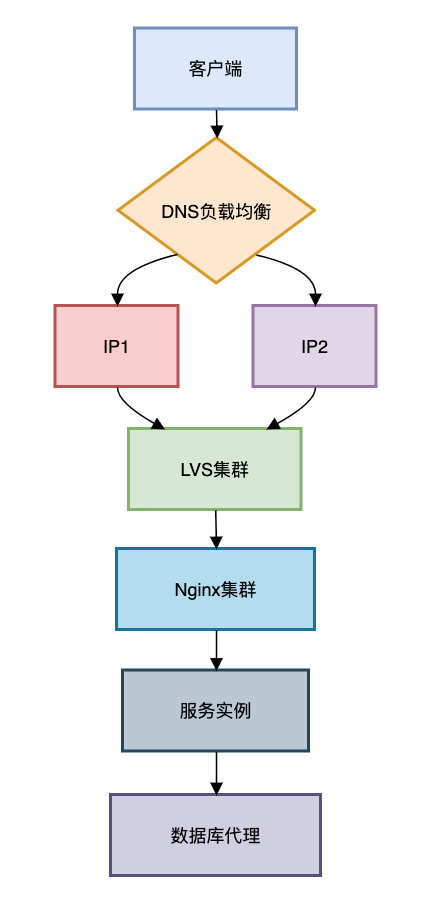
各层核心作用:
- DNS层:实现地域级流量调度(如智能解析)
- LVS层:基于IP的4层负载,千万级并发支撑
- Nginx层:7层应用路由,支持HTTPS卸载
- 服务层:客户端负载均衡(如Ribbon)
- 数据层:数据库读写分离(如MyCAT)
二、五大负载算法
轮询算法(Round Robin)
实现原理:
public class RoundRobinLoadBalancer {
privatefinal List<String> endpoints;
privatefinal AtomicInteger counter = new AtomicInteger(0);
public String next() {
int index = counter.getAndIncrement() % endpoints.size();
if (index < 0) {
counter.set(0);
index = 0;
}
return endpoints.get(index);
}
}致命缺陷:未考虑服务器性能差异 → 低配服务器先过载
加权轮询(Weighted Round Robin)
动态权重配置:
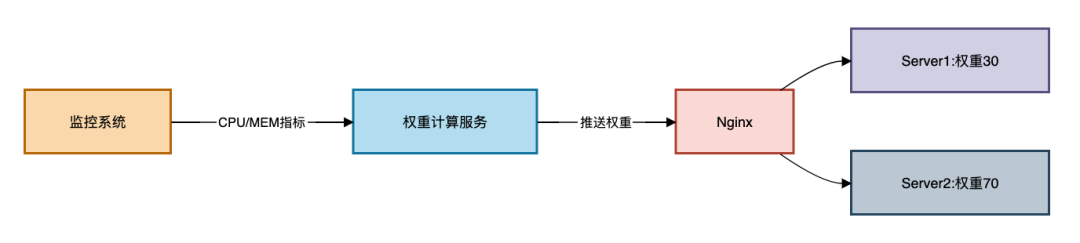
Nginx配置示例:
upstream backend {
server 192.168.1.10 weight=3; # 30%流量
server 192.168.1.11 weight=7; # 70%流量
server 192.168.1.12 backup; # 备用节点
}最少连接算法(Least Connections)
核心思想:将新请求分配给当前连接数最少的服务器
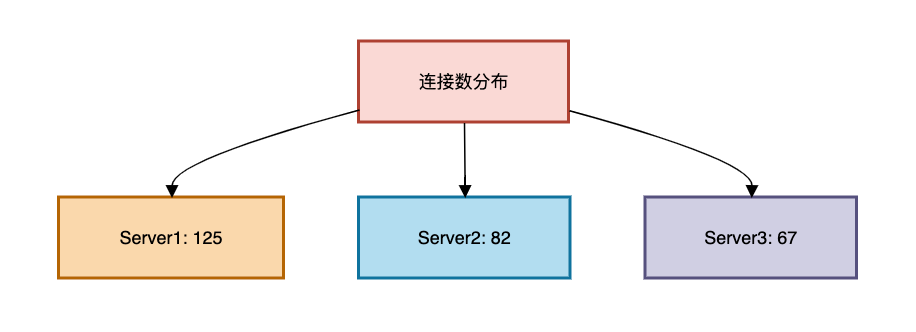
Java实现:
public String leastConnections() {
return endpoints.stream()
.min(Comparator.comparingInt(this::getActiveConnections))
.orElseThrow();
}
// 模拟获取连接数(真实场景从监控获取)
private int getActiveConnections(String endpoint) {
return connectionStats.getOrDefault(endpoint, 0);
}一致性哈希(Consistent Hashing)
解决痛点:分布式缓存扩容时大量缓存失效
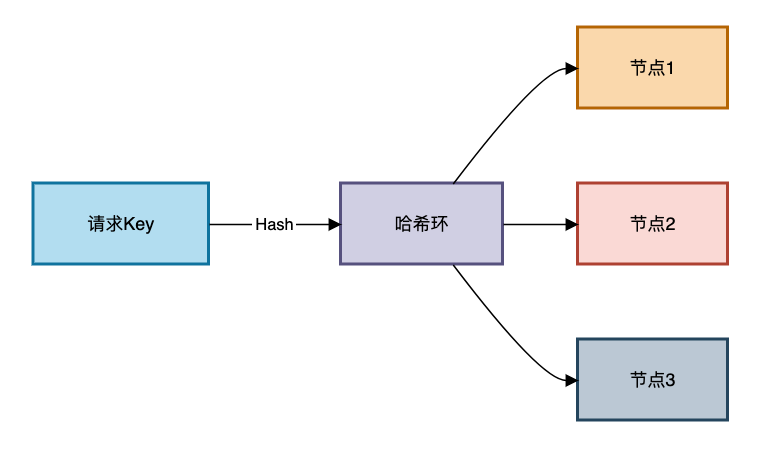
虚拟节点实现:
public class ConsistentHash {
privatefinal SortedMap<Integer, String> circle = new TreeMap<>();
privatefinalint virtualNodes;
public void addNode(String node) {
for (int i = 0; i < virtualNodes; i++) {
String vNode = node + "#" + i;
int hash = hash(vNode);
circle.put(hash, node);
}
}
public String getNode(String key) {
if (circle.isEmpty()) returnnull;
int hash = hash(key);
SortedMap<Integer, String> tailMap = circle.tailMap(hash);
int nodeHash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
return circle.get(nodeHash);
}
}自适应负载算法(AI预测)
动态预测模型:
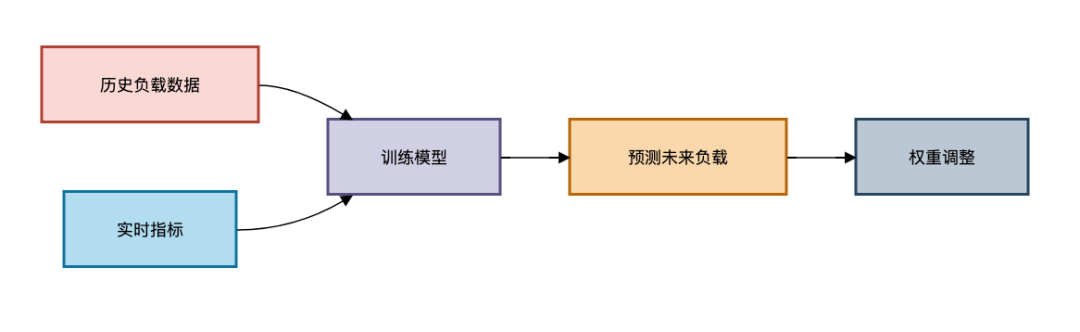
关键指标:
# 使用简单线性回归预测
def predict_load(historical):
# 输入: [(time, cpu, mem, conns)]
X = [t[0] for t in historical]
y = [t[1] * 0.6 + t[2] * 0.3 + t[3] * 0.1 for t in historical]
model = LinearRegression().fit(X, y)
return model.predict([[next_time]])三、高可用负载架构设计
双活数据中心流量调度
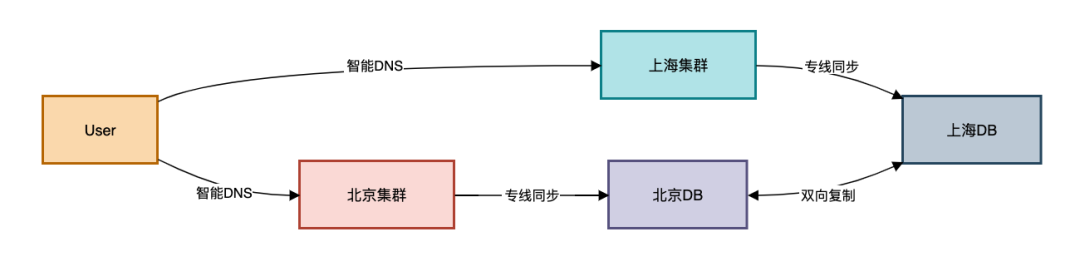
故障切换策略:
-
网络层:BGP Anycast实现IP级切换
-
应用层:Nginx主动健康检查
server 192.168.1.10 max_fails=3 fail_timeout=30s;
-
服务层:Spring Cloud熔断降级
@HystrixCommand(fallbackMethod = "defaultResult")
public String service() { /* ... */ }
四、深度避坑指南
陷阱1:缓存穿透引发雪崩
场景:某热点Key失效导致流量直击数据库
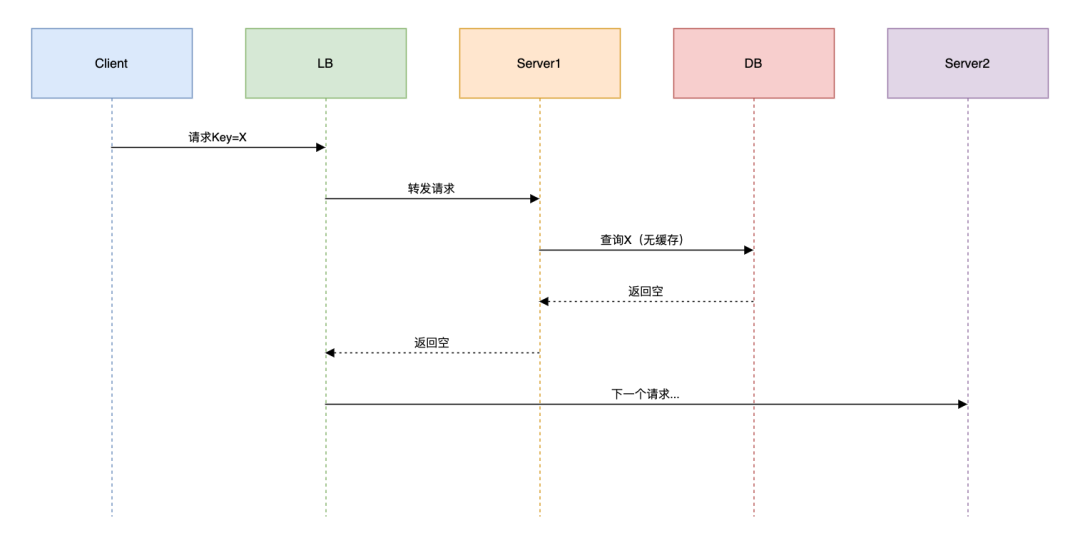
解决方案:
// 使用Google Guava缓存空值
LoadingCache<String, Object> cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(30, TimeUnit.SECONDS)
.build(new CacheLoader<>() {
public Object load(String key) {
Object value = db.query(key);
return value != null ? value : NULL_OBJ; // 空对象占位
}
});陷阱2:TCP连接复用失衡
现象:长连接导致流量倾斜
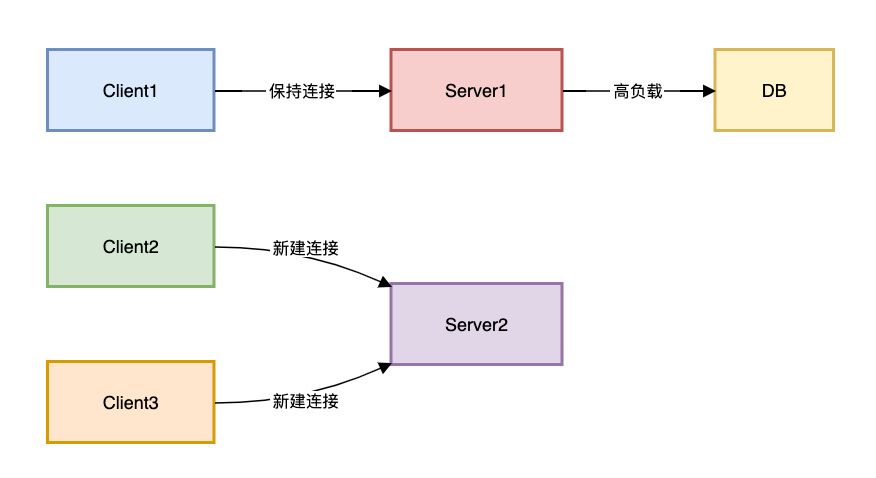
解决方案:
# Nginx配置短连接
upstream backend {
server 192.168.1.10;
keepalive 50; # 每worker最大连接数
keepalive_timeout 60s;
}陷阱3:跨机房延迟导致超时
案例:北京调用上海服务频繁超时

优化方案:
-
路由策略:优先同机房调用
-
超时配置:
feign:
client:
config:
default:
connectTimeout: 500
readTimeout: 1000 -
降级策略:
// 上海服务不可用时使用本地缓存
@Fallback(fallbackClass = LocalCacheService.class)
public interface RemoteService {}
五、自研负载均衡器核心设计
架构设计
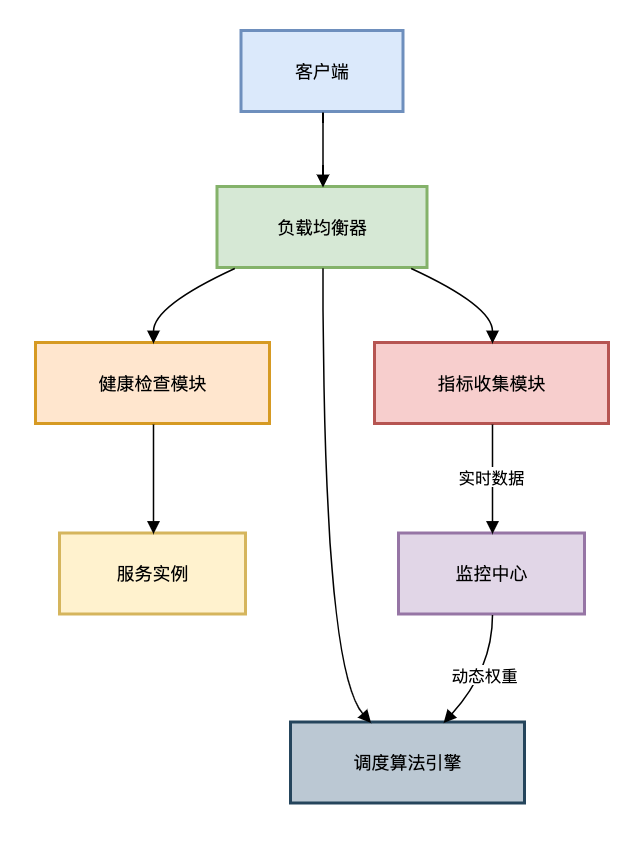
健康检查实现
public class HealthChecker implements Runnable {
privatefinal List<ServerNode> nodes;
public void run() {
for (ServerNode node : nodes) {
boolean alive = checkNode(node);
node.setAlive(alive);
}
}
private boolean checkNode(ServerNode node) {
try (Socket socket = new Socket()) {
socket.connect(new InetSocketAddress(node.getIp(), node.getPort()), 500);
returntrue;
} catch (IOException e) {
returnfalse;
}
}
}总结
三层设计原则:
五大核心原则:
- 冗余设计:至少2个负载均衡节点形成集群
- 多级分流:DNS+LVS+Nginx+服务层分级调度
- 动态调整:基于实时指标自动更新权重
- 故障隔离:快速剔除异常节点
- 灰度发布:权重式流量切换
负载均衡的本质不是平均分配流量,而是让合适的请求到达合适的节点。
当你能从流量调度中看到业务特征,从算法选择中预见系统瓶颈,才算真正掌握了高并发架构的精髓。