翻译:掘金安东尼
前端周刊更多文章:加群
上周四,我买了 Claude Max 。要知道,我之前的时间几乎被 GPT-5 淹没,GPT-5 比 Claude Max 便宜足足 12 倍。
接着,我用 Claude Code 疯狂地对比了几个模型:Horizon Beta、Qwen3-Coder、GPT-OSS,当然还有 GPT-5。
结果让我发现了一个大多数人忽略的点:Claude Code 有一条"隐藏护城河",哪怕 GPT-5 再聪明、再便宜,也跨不过去。

下面就是我这场测试全记录。
谁能跑完全程?
我测试了不同模型接入 Claude Code 的表现。试了各种路由方案和 OpenRouter 集成,跑过的配置包括:
- GPT-5 走 Claude Code 路由
- GPT-OSS(20B、120B)
- Qwen3-Coder 480B
- DeepSeek Reasoner
- Horizon Beta
结果非常统一:
非 Anthropic 系列的回答普遍就是------"修 bug""加错误处理""优化函数"......一句话糊弄过去。
而 Claude 给的却是:可直接跑的生产级代码 + 详细解释。这才是开发者真正需要的。
硬数据也说明了一切:Claude Opus 4.1 在 SWE-bench(真实世界代码任务基准)上的表现稳压全场。
这个差距,放到现实开发里,就是几个小时的调 bug,和一个能不能上线的分水岭。
GPT-5 的"路由机制"
当然,GPT-5 也不是没有亮点。正如 Simon Willison 说的,它的价格几乎是"屠杀级":
1.25刀/百万输入 token,而 Claude Opus 4.1 要 15刀。
便宜 12 倍,这谁看了不心动?
但坑也在这里。Artificial Analysis 的数据揭示:GPT-5 的表现取决于你被分配到哪个模型。具体看:
- GPT-5(高配):智能分 69
- GPT-5(中配):智能分 68
- GPT-5(低配):智能分 44 ------比 GPT-4o 还惨
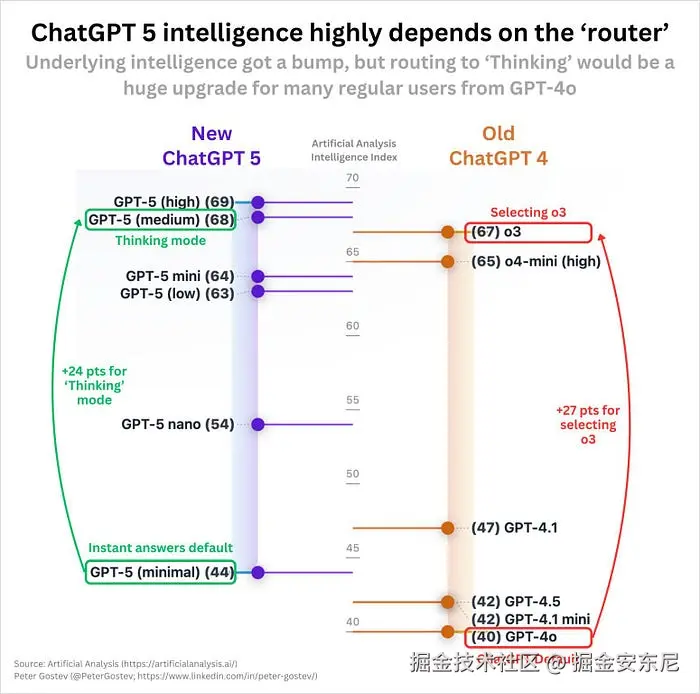
说白了,你买的是一张"彩票"。如果运气好,能拿到"思考模式",答案很不错;但一旦掉到低配通道,产出甚至还不如旧一代。
这种波动让 GPT-5 在关键生产任务里很难放心。
对比之下,Claude 的稳定性就是它的底气。没有随机降级,没有抽奖。
真正的护城河:提示工程
重点来了。
为什么 Claude Code 能这么稳?
秘诀不在模型本身,而在于 针对 Claude 架构深度调优的提示工程。
Yifan 的分析把核心扒了出来:
- 提示 = 秘制调料:Claude Code 的威力来自极度细致的提示,而不是隐藏版模型
- 代理式工作流:逻辑写在提示里,用自然语言定义,而不是死代码
- 模型特定优化:同样的指令,换到 GPT-5 上基本报废
- 重复强化:关键信号在提示里多次强调,确保 Claude 确实执行
你可以把这比作赛车。GPT-5 是豪华 SUV:均衡、便宜、跑得也不慢。Claude Code 就是 F1 赛车:为一条赛道彻底优化。
贵,但要赢比赛,它就是唯一选项。
在 Claude 的提示设计里能看到一堆"小花活":
- XML 标签分层结构
- 上下文注入系统提醒
- 工具使用示例(明确对比好 vs 坏)
- 把任务管理作为主线持续强化
开发者现实检验
对开发者来说,这意味着:
- 如果你追求 极致性价比,GPT-5 的确是聪明的选择。
- 但如果你要 稳定 + 可交付的代码,Claude Code 的优化才是真正的护城河。
想自己测试?很简单:
- 在 Claude Code 路由下跑不同模型
- 再用 OpenRouter 测 GPT-5
- 看看谁更稳定地产出可用结果
- 关注一致性,而不只是偶尔的高光
我们正在进入一个"模型商品化+价格战"的时代,但最后赢的不是最便宜的,而是最懂特定场景的产品。
这就是为什么,最终,哪怕贵 12 倍,我还是选了 Claude Max。