ODPS 十五周年实录 | Data + AI,MaxCompute 下一个15年的新增长引擎
本文根据 ODPS 十五周年·年度升级发布实录整理而成,演讲信息如下:
于得水(得水):阿里云智能集团计算平台事业部资深技术专家
活动:【数据进化·AI启航】ODPS 年度升级发布
此次演讲内容共分为三个部分:
第一部分,介绍 MaxCompute 面向 Python 和 AI 生态计算的演进历史。从最初的 SDK Library 到表示层计算,再到面向 AI 场景的新一代原生 Python 引擎。
第二部分,介绍 MaxCompute 多年构建起来的 Data + AI 领域的核心能力,包括分布式计算框架 MaxFrame 以及面向 SQL 和 Python 引擎的 AI Function 功能。
第三部分,分享 MaxCompute 在 Data + AI 核心能力构建后,在该领域的核心应用及客户成功案例,包括在大模型预训练领域的海量数据处理场景以及在自动驾驶领域的数据预处理场景。
MaxCompute 面向 Python & AI 计算的演进
MaxCompute 面向Python&AI计算的演进历程
MaxCompute 于 2010 年对外发布。2015 年,随着 Python 生态的用户群体越来越多,我们正式发布了 PyODPS 组件。最初,它是一个 Python SDK Library,用户可以在 Python 的接口上对 MaxCompute 对象进行操作并提交作业,满足了 Python 生态用户提交 MaxCompute 作业的需求。
2017 年,由于社区中 DataFrame 表示层越来越流行,也有类似于 Pandas 的社区版数据处理库在发布,所以 PyODPS 也提供了类似于 Pandas 接口的 DataFrame 表示层。用户可以在 DataFrame 表示层上调用算子执行作业,底层也会变成 MaxCompute SQL 作业提交。
2019 年,我们开源并发布了分布式计算框架 Mars,它支持 NumPy、Pandas、Scikit-learn 的分布式计算。在发布之后,Mars 在开源社区得到了普遍的好评和热烈的反响,特别是在蚂蚁内部的 MaxCompute 集群,Mars 在大规模金融领域得到了广泛应用。
2023 年,随着生成式 AI 的热潮到来,MaxCompute 推出了新一代分布式计算框架 MaxFrame,并在 2023 年云栖大会上正式对外发布。MaxFrame 是面向 Data +AI 领域的新一代分布式计算方案,全面兼容 Pandas 接口的 DataFrame 语义,支持模型开发、离线推理等场景的 Data + AI 计算,满足了用户对 Data + AI 领域分布式计算的需求。
2025 年,也就是今年,MaxCompute 推出了 Python 原生计算引擎 DPE(Distributed Python Engine)。它是面向 AI 场景的新一代 MaxCompute 引擎,支持原生的 Python UDF 运行,支持异构资源调度和计算,还支持基于开源大模型部署的 AI Function 能力。同时支持进行多模态数据计算。 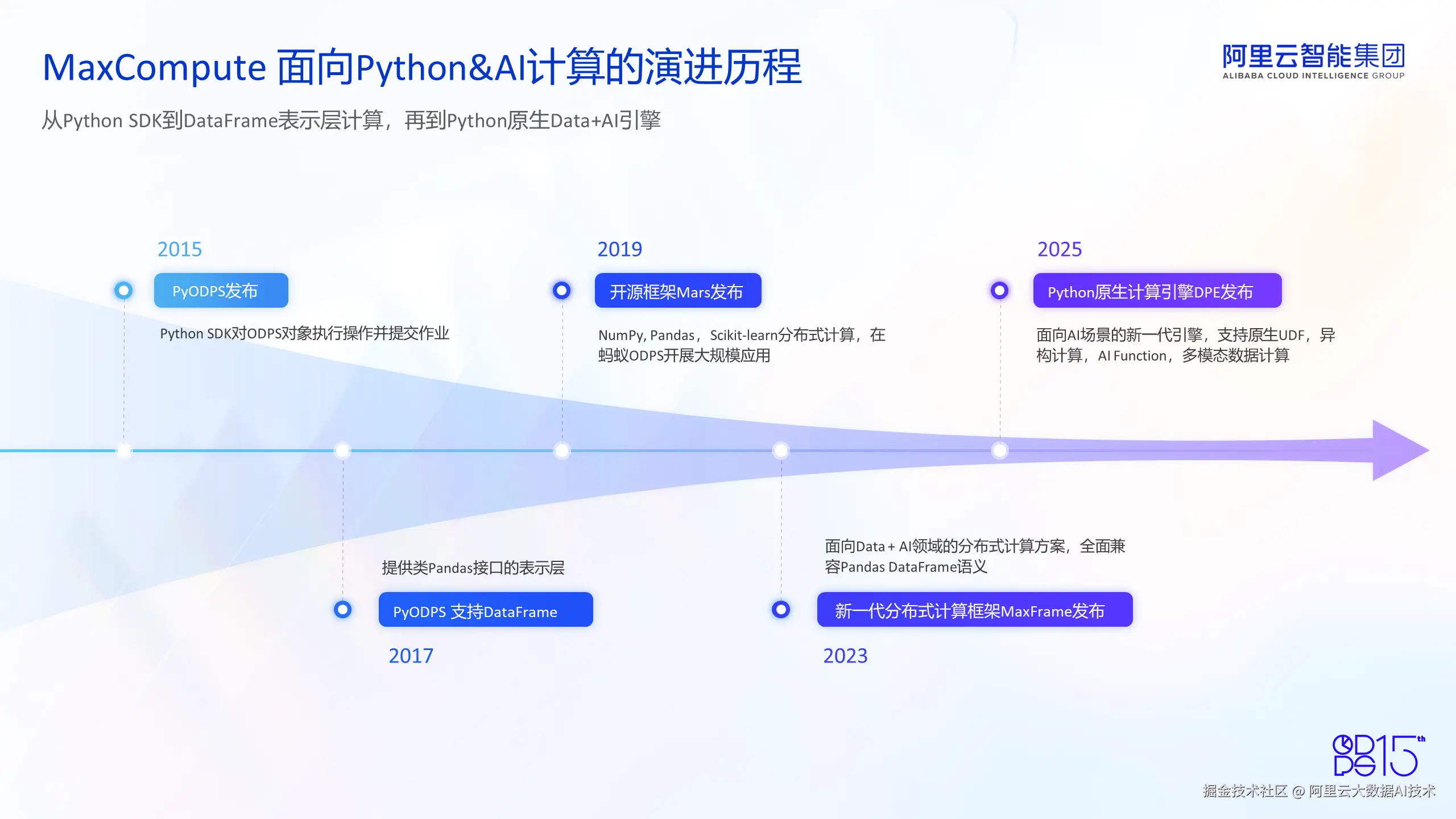
大数据平台在 AI 时代面临的挑战
近年来,生成式 AI 的井喷式发展给传统大数据平台带来了一系列挑战,同时也为我们提供了前所未有的面向客户场景和大规模计算的发展机遇。
首先,由于大模型能力不断增强,生成式 AI 能力成为大数据领域客户的普遍诉求,并且推理成本不断降低,我们观察到每一个组织和客户都希望可以把生成式 AI 能力快速应用到他们的生产环境中,对商业数据进行更智能化的洞察和分析。
其次,随着大模型预训练的兴起,数据处理的计算规模越来越大,对 Data For AI 领域的计算要求也越来越高。数仓平台需要能够很好地支撑大模型预训练场景中的数据预处理需求,包括海量弹性计算能力和对多种数据类型(结构化、半结构化、非结构化)的一体化处理能力。
第三,随着 AI 能力越来越强,传统大数据平台需要借用 AI 能力来增强自身的数据治理能力,即 AI For Data。这包括通过 AI 优化查询计划生成和执行,提供更智能的作业诊断和改进建议,以及使用更智能的物化视图帮助用户进行作业调优。
最后,随着 AI 能力的增强,如 AI Coding 在开发者中的广泛应用,开发者对开发节奏和效率有了更高的要求。这就要求大数据平台在 AI 时代提供更敏捷的开发体验,从开发到测试,再到评估和部署,都需要提供更便捷、友好和高效的开发体验和平台。 
MaxCompute 在 Data+AI 场景的解决方案
基于以上挑战,MaxCompute 在 Data + AI 场景下提供了一系列解决方案。首先,提供了分布式计算框架 MaxFrame,它兼容社区 Pandas 接口,以用户友好的方式提供框架计算。用户可以用熟悉的语言,统一 Python 接口提交作业。此外,内置的高效数据处理算子和模型开发算子,支持用户一站式进行数据和 AI 开发。
其次,针对开发体验提升的需求,我们提供了交互式开发环境,包括开箱即用的 MaxCompute Notebook 产品和集成好的 Dataworks Notebook 产品。用户可以基于云端 Studio 进行交互式脚本开发和作业调试。
第三,我们提供了自定义镜像能力和管理功能。基于我们对客户的调研和走访,客户普遍对于使用自定义镜像启动容器进行作业执行有着需求。比如,用户希望可以把第三方依赖包打到镜像里,也可以把自己的私有包、模型文件和其他数据文件打到镜像里。因此,MaxCompute 提供了自定义镜像的管理和运行功能,用户可以提前把自己需要的依赖打到镜像里,就可以在 MaxCompute 的分布式环境中进行类似本地开发环境、类似依赖的执行,极大地提升了开发和部署的效率。
最后,针对 AI 时代数据模式和形态越来越复杂的现状,MaxCompute 也提供了多模态数据管理和运行的能力。我们可以在 MaxCompute 平台中对结构化、半结构化和非结构化数据进行统一管理,并用统一的计算引擎进行对接,满足用户对多模态数据处理的需求。 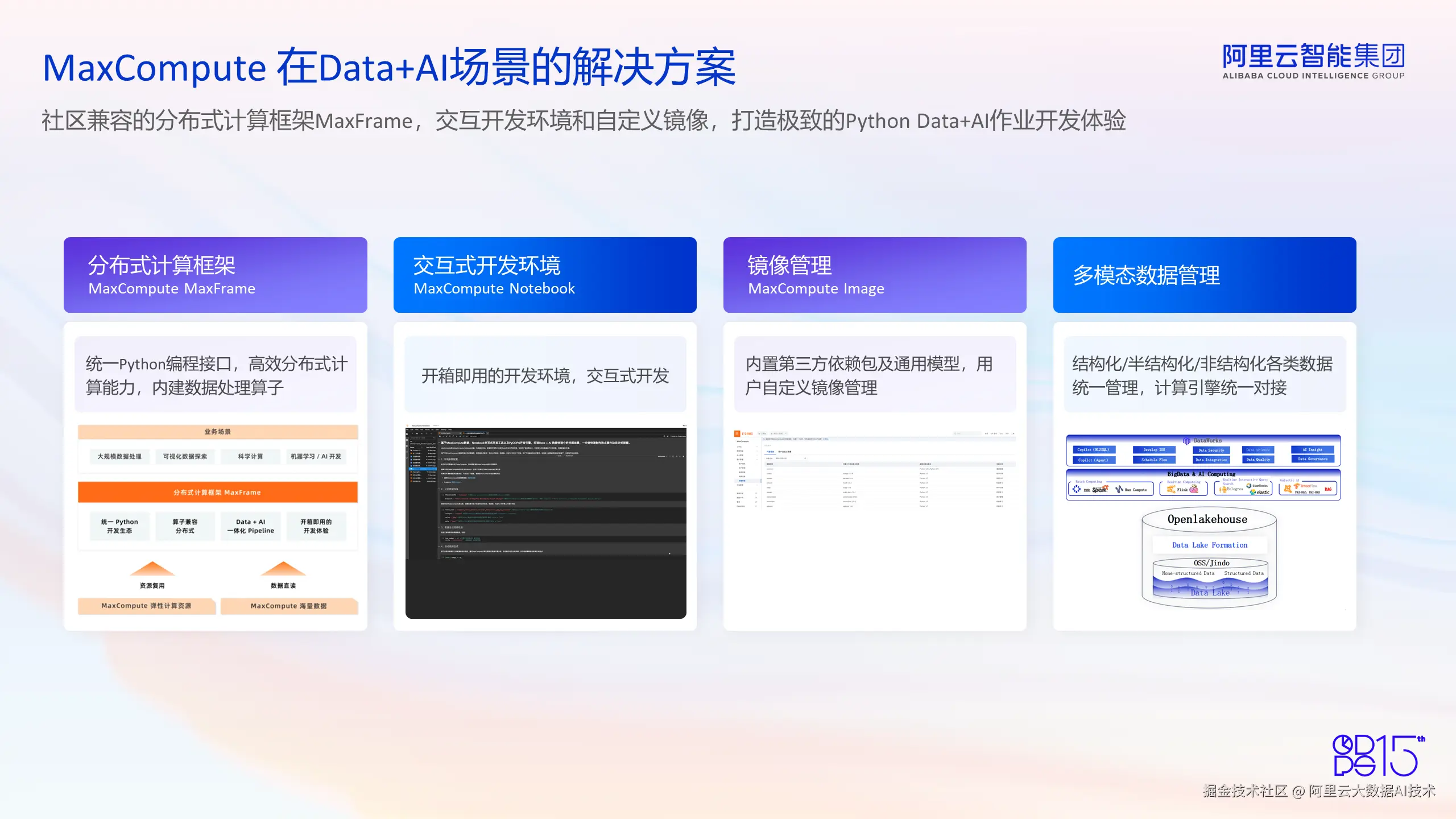
MaxCompute Data+AI 核心能力
MaxCompute 发布的新一代分布式计算框架 MaxFrame ,可以显著提高用户的作业运行处理性能。由于 MaxFrame 框架是直接运行在 MaxCompute 的集群内部,可以直读 MaxCompute 内表的数据,避免了无效的数据移动和数据泄露风险,极大地提高了用户作业的执行效率。
因为 MaxFrame 运行在 MaxCompute 集群内部,可以利用 MaxCompute 海量弹性计算资源的能力,在短时间内快速拉起几十万 core 规模的计算资源来执行用户大规模的数据处理作业,极大地缩短了用户等待资源的时间,并且提升了作业处理的效率。
此外,MaxFrame 提供了更完善、用户更熟悉的算子支持。如刚才描述,MaxFrame 提供了社区兼容版的 Pandas 接口,用户可以以类似于本地编写 Pandas 作业的体验来去调用 MaxFrame 的 Pandas 兼容接口进行分布式数据处理,比如 DataFrame 和 Tensor 结构的数据处理,以本地开发的体验进行云端大数据操作来提交作业,满足用户使用一份 Python 脚本进行数据处理和 AI 开发的完整流程。
最后,MaxFrame 提供了更加便捷的开发体验。刚才也提到,我们提供了 MaxCompute Notebook 产品,也与 Dataworks Notebook 进行了集成。使用云端 Studio,用户无需进行复杂繁琐的本地开发环境配置,所有配置保存在云端,可以一站式地启动开发环境进行作业开发。同时,我们支持用户的脚本运行在自定义镜像启动的容器中,确保用户本地开发环境和云端生产环境运行时的依赖管理一致,方便用户进行作业提交和开发。 
除此之外,面向传统数据分析师和数据工程师,我们也提供了低成本的 AI Function 能力。用户既可以通过熟悉的 Python 脚本调用 AI Function 执行数据分析,也可以使用 MaxFrame 提供的 Python 接口调用 AI Function 进行数据分析。正如之前提到的,随着生成式 AI 的迅速发展,越来越多的用户希望利用大模型的智能化能力处理海量数据。然而,由于大模型的部署、运行和调试存在一定的门槛,许多用户在实际应用中受到了限制。为了解决这个问题,MaxCompute 提供了 AI Function 功能。我们在 MaxCompute 平台内部部署了很多内置模型,比如通义千问 3 系列的文本模型、Deepseek-R1 系列的蒸馏模型等。用户无需进行复杂的模型配置、部署和运行,只需要调用 AI Function 接口,就能以非常低的成本使用我们的 AI 能力进行推理,从而对数据进行洞察分析和内容生成。
AI Function可以处理多种形态的数据。用户可以使用 AI Function 来处理存储在 MaxCompute 表中的结构化数据,也可以处理存储在数据湖上的非结构化数据,通过外表和 Object Table 方式进行读取。在执行端,用户只需进行简单的接口调用,比如 ML_GENERATE 和 PREDICT 接口,就可以进行 AI Function 执行。依赖于我们内置的通义千问 3 和 Deepseek-R1 蒸馏模型,以及用户自己训练好的传统机器学习模型,比如 Xgboost、Sklearn 和 Lightgbm 等框架训练好的模型,用户可以使用模型能力对数据进行处理。应用场景包括传统的文本生成、文本分类、结构化信息抽取、情感分析、风控,以及针对多模态数据领域的图文解析、图片物体识别等,具有广泛的应用场景和生产价值。 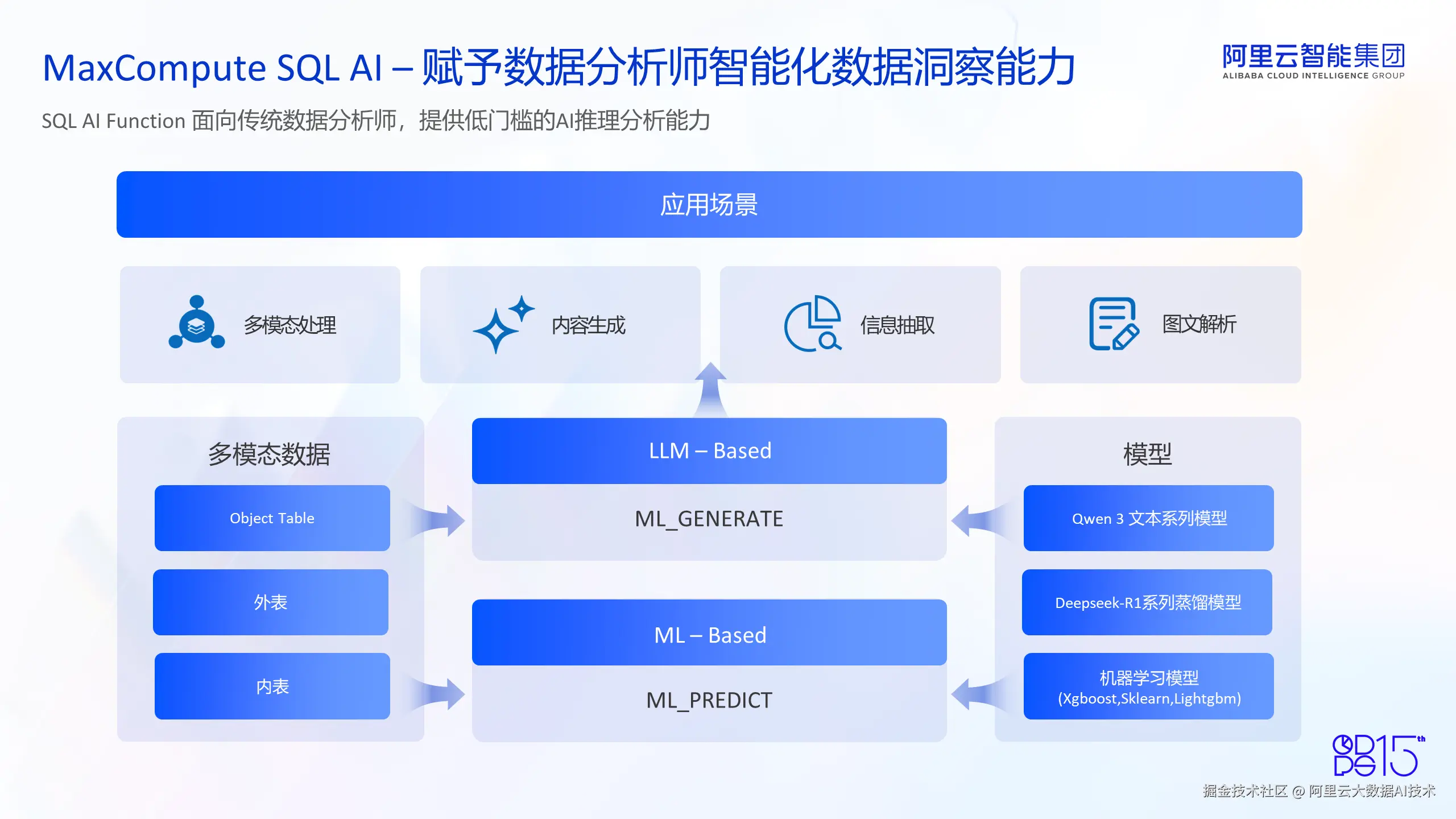
MaxCompute 在Data + AI领域的应用
目前, MaxCompute 在 Data + AI 领域构建的各种能力和提供的产品及解决方案,已在多个关键行业成功应用,积累了很多成功的客户故事。接下来,我将分享三个我们在关键行业支撑的应用和客户案例。
多模态数据处理
第一个应用场景是多模态数据处理。我们的客户通义团队,使用 MaxCompute 的 Data + AI 能力进行多模态数据处理。众所周知,在多模态的大模型预训练中需要处理海量的多模态数据。比如,可以把海量的视频文件抽帧转换成图片文件,并保存在数据湖中(如 OSS) 。利用 MaxCompute Data + AI 能力,通义团队借助 MaxCompute 海量弹性计算资源以及 MaxFrame 提供的 Python 原生开发的运行体验和接口,在很短时间内就完成了作业的编写、调试和部署,得益于 MaxCompute 的弹性能力,可以在短时间内调动数十万核的 CPU 资源进行视频抽帧的作业执行。依赖于 MaxCompute 多年构建的 Serverless 高可用的平台,通义团队提交的视频处理作业运行得非常稳定、流畅。
下图左侧图表展示了整个作业执行流程。首先,多模态数据(比如视频数据)存储在数据湖 OSS 中,通过用户编写的 MaxCompute 作业提交到 MaxCompute 集群中,我们可以从 OSS 或者是 CPFS 中读取数据,通过调用 MaxCompute 提供的数据处理算子,用户可以非常高效地进行大模型预训练中需要的数据处理作业比如视频超帧、图片渲染、文本清洗等。并且,我们有海量的计算资源池,可以提供非常好的弹性能力,按需进行计算。同时,经过 MaxFrame 计算之后的数据可以再存回数据湖,或者是分布式文件系统 CPFS 中,供后续训练使用。在图中也显示了,在后续的训练中,我们可以利用阿里云计算平台提供的 PAI 灵骏大规模智算资源池进行大规模、高弹性的模型训练任务。经过应用了 MaxCompute 的 Data + AI 能力,客户取得了很明显的效率提升,比如客户的千万级视频文件,可以在几十小时内就完成全部的处理,相比于之前客户的方案,效率有了成倍的提升。 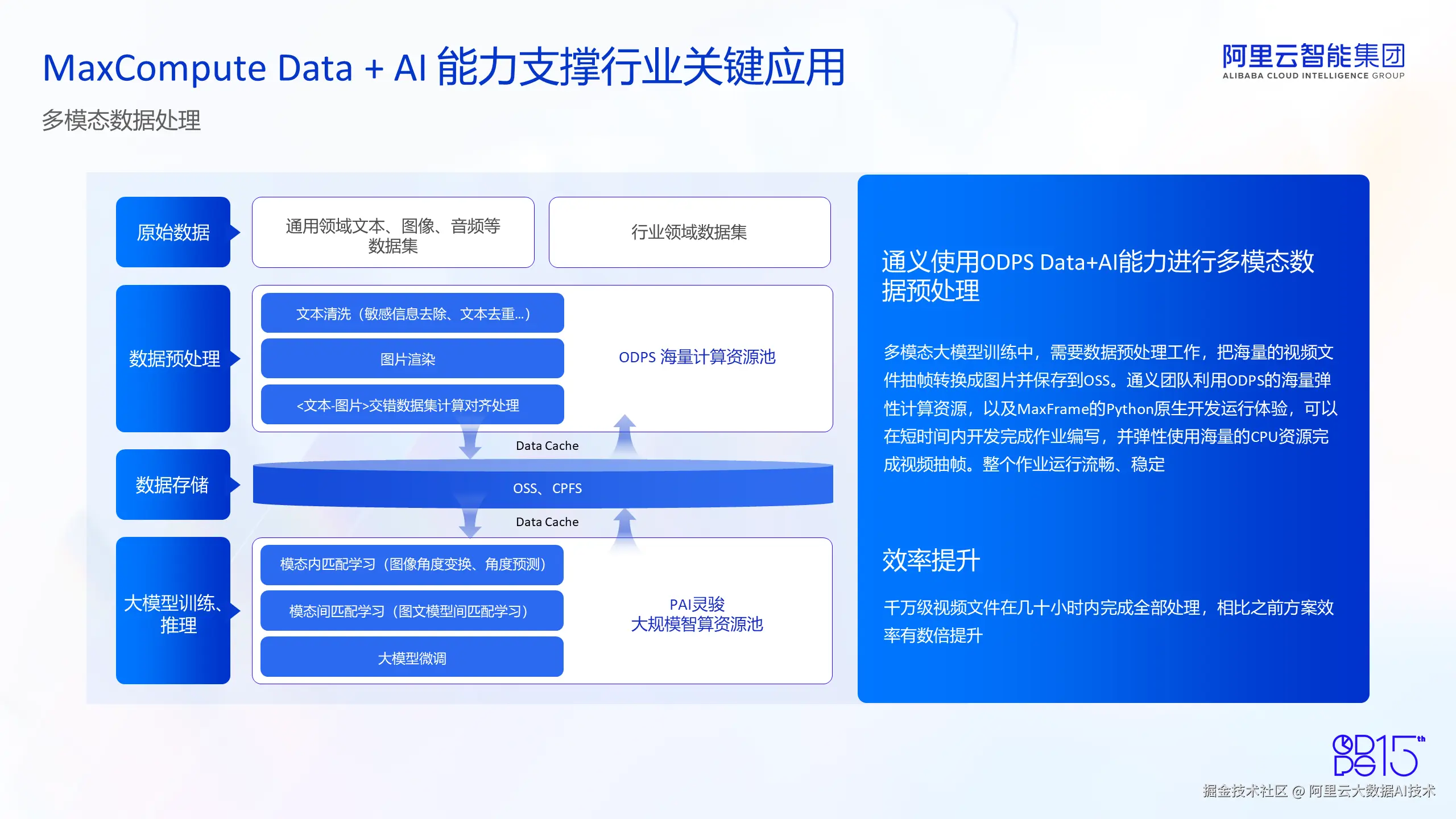
大模型预训练海量 Web 文本去重
第二个案例涉及大模型预训练的海量 Web 文本去重场景,也是 MaxCompute Data + AI 能力支撑的另外一个关键行业应用。在这个案例中,某大模型实验室,使用 MaxFrame 成功进行了海量 Web 文本的去重。众所周知,大模型训练的数据处理中,需要对训练语料中的相似文档进行语义去重,以提升训练的效率并提高模型训练的质量。因为过多的相似文本会导致处理效率很低。另外,过多的相似文本会严重干扰模型训练过程,造成模型泛化能力的降低以及很低的模型质量。所以在大模型预训练中,进行精确高效的语义文本去重是一个关键步骤。在这个过程中,包含大规模文本的 MinHash 生成、LSH Band 指纹计算以及非常复杂的联通图的构建、相似性传递和文本去重选择等过程。在传统方案中,用户往往需要搭建单独的计算集群,启动专门的作业来进行上述步骤的计算,造成的效果就是计算效率比较低。因为需要分成很多步骤和迭代,同时集成资源利用率也很低。
针对这些问题,MaxCompute 的 MaxFrame 产品提供了定制化的文本去重算子,用户可以以参数的形式传入一些关键参数,比如 MinHash 计算的参数、比如 LSH Band 的数量、比如在相似度计算中的相似度阈值的数值等等,可以高效率、更便捷地完成文本去重计算,不需要用户写复杂的文本去重逻辑和参数配置。最终达成计算规模更大、速度更快的效果。以公开数据集 FineWeb-edu 30 亿条数据、8 TB 数据规模的场景为例,我们使用 MaxCompute 4000 CU 可以在 3 小时内完成全部文本的去重计算,这是一个非常优秀的 Benchmark 结果。第二个效果是相比用户原有 IDC 自建方案,使用 MaxFrame 的文本去重算子,用户取得了两倍的性能提升,客户对此表示非常满意。 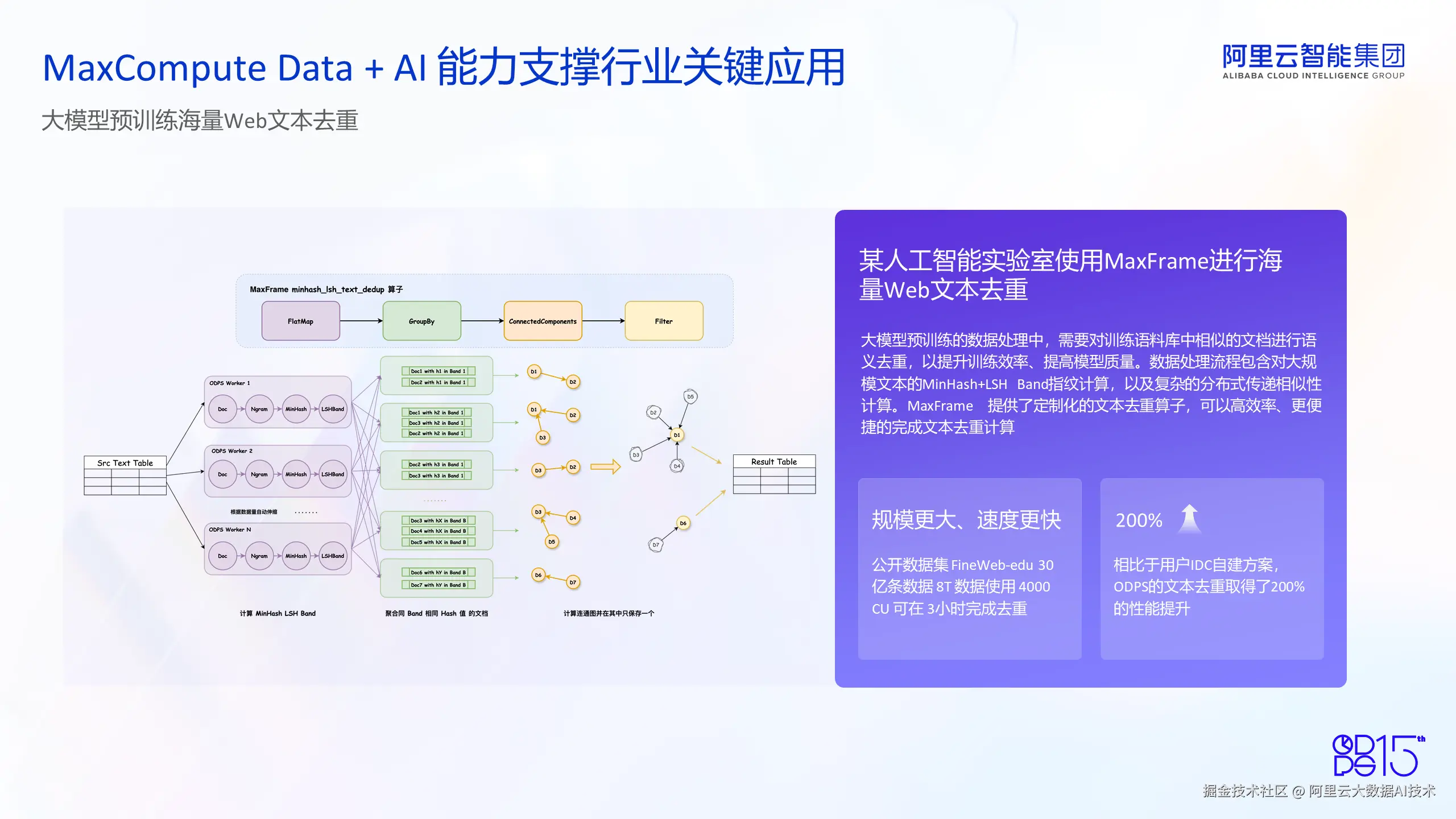
汽车自动驾驶数据预处理
最后一个案例展示了 MaxCompute Data + AI 能力如何支撑自动驾驶行业的数据预处理。某自动驾驶厂商,使用 MaxCompute MaxFrame 功能进行自动驾驶数据处理。在自动驾驶场景中,车端(比如量产车、研采车)会持续产生并采集海量数据,包括车载设备记录的图片、音视频数据,包括汽车运行中设备生成的雷达数据,包括汽车行驶中的 GPS 轨迹数据等等。这些数据通常以 BAG 包文件的形式在数据湖上存储。传统的处理解决方案中,用户往往需要构建一系列复杂的 Pipeline,写不同的脚本进行处理。基于 MaxFrame,客户对自己的 Pipeline 进行了改写升级,完成了对车端采集的大量 BAG 包的处理工作。
从下图中可以看到,使用 MaxFrame 脚本,用户不需要编写复杂的 Pipeline,只需要编写不同的逻辑,就可以完成对 BAG 包的解析、清洗、切包,以及最后训练样本的生成、切片和存储等步骤,避免了传统方式下要构建复杂的 Pipeline 才能完成的事情。经过使用 MaxFrame 进行的 Pipeline 改写,用户也可以把车端采集数据处理流程中的结果,存在我们的 MaxCompute meta 表中,便于后续对车端数据进行进一步的挖掘和跟踪。从客户侧感知到明显的效果提升。首先是海量的弹性计算规模,鉴于自动驾驶数据通常是按需产生的,用户往往需要进行数据补全和临时作业提交操作,使用 MaxCompute 可以快速拉起并提供数十万 CU 计算规模的弹性资源,满足用户按需进行作业提交处理的需求。另外就是作业运行效率的提升,相比于用户之前的开源处理方案,基于 MaxFrame 高效的内置算子和更便捷的 Pipeline 构建,整体性能提升了 40%,得到了客户的高度认可。 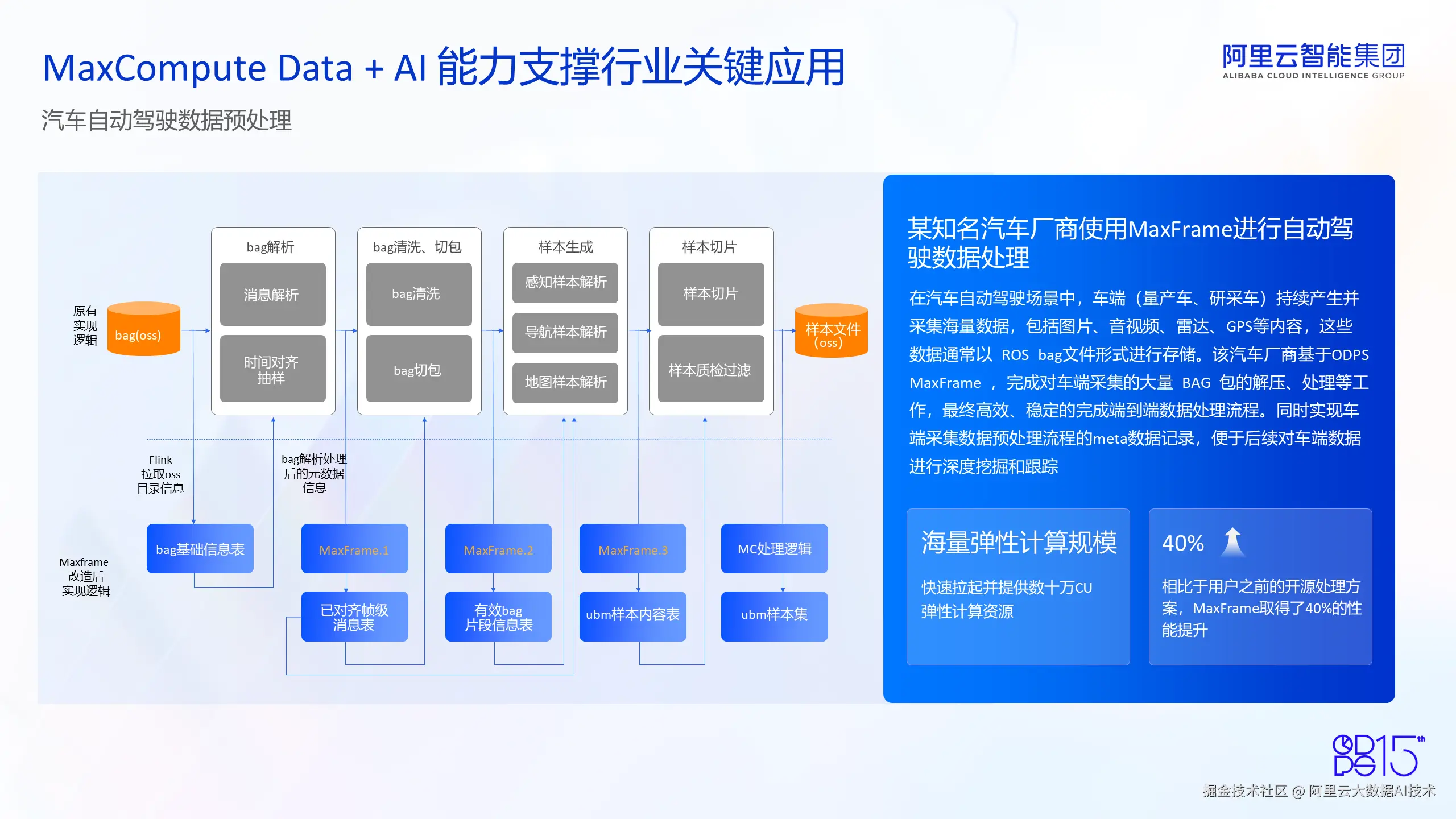 以上就是MaxCompute 在 Data + AI 领域所做工作的介绍,包括面向 Python 生态和 AI 计算场景的演进历史,包括 MaxCompute 在 Data + AI 领域构建的核心能力和相关解决方案,以及基于这些核心能力支撑的应用场景和成功客户案例。欢迎大家使用 MaxCompute Data + AI 产品。
以上就是MaxCompute 在 Data + AI 领域所做工作的介绍,包括面向 Python 生态和 AI 计算场景的演进历史,包括 MaxCompute 在 Data + AI 领域构建的核心能力和相关解决方案,以及基于这些核心能力支撑的应用场景和成功客户案例。欢迎大家使用 MaxCompute Data + AI 产品。