最近开始刷数据结构与算法题, 刷到数组的题感觉很难受很别扭, 体现在解决功能性问题的时候, 我总是太过于聚焦内存细节, 可能是因为我前段时间刚学习了一些变量内存的知识, 让我认识到了一个自己原先很模糊的地方, 导致我现在过度聚焦内存细节, 导致形象化逻辑被干扰, 现在刷题寸步难行, 我透了.
一. 认识问题
我本应优先通过 "形象化模型" (如二维数组 = 矩阵、对象 = 带属性和行为的个体、引用变量 = 指向实体的指针) 理解代码要实现的功能,但却不自觉地陷入"内存分块、栈堆存储、引用存地址"的底层细节中.
比如看到二维数组,脑子里先浮现"引用变量存数组地址, 内层数组由数组的每个元素(也是引用变量)存储", 而非 "矩阵的行与列",导致精力被分散,无法聚焦 "如何遍历、如何计算" 等核心解题逻辑,进而感到 "崩溃、迷茫".
二. 为什么我会产生这种问题?
原因一:
在于我没有明确区分 "刷题时的理解需求" 和 "理解语言特性时的需求":
- 刷题需要的是 "高效的逻辑映射" (比如把引用变量直接看作 "指向形象化实体的指针", 不用管他在堆还是栈中)
- 理解 "为什么会出现空指针、为什么修改一个变量会影响另一个" 才需要严谨的内存映射 (比如引用变量存地址、对象在堆里)
这种优先级的混淆,让我在该 "简化思考" 的时候强行 "复杂拆解",导致思考效率低下、逻辑混乱.
原因二:
对于基本数据类型和引用数据类型的变量本质缺乏从形象到底层的过渡认知, 导致一些数据结构在处理时理解断层.
总而言之, 脑子里没有将这些底层内存中的操作熟练的形象化.
三. 解决方案
一个自己能接受的内存模型是刷题时的 "思维基础建设"------ 它不需要和真实内存100%一致,但必须和现实内存能帮你快速预判代码行为、设计操作逻辑. 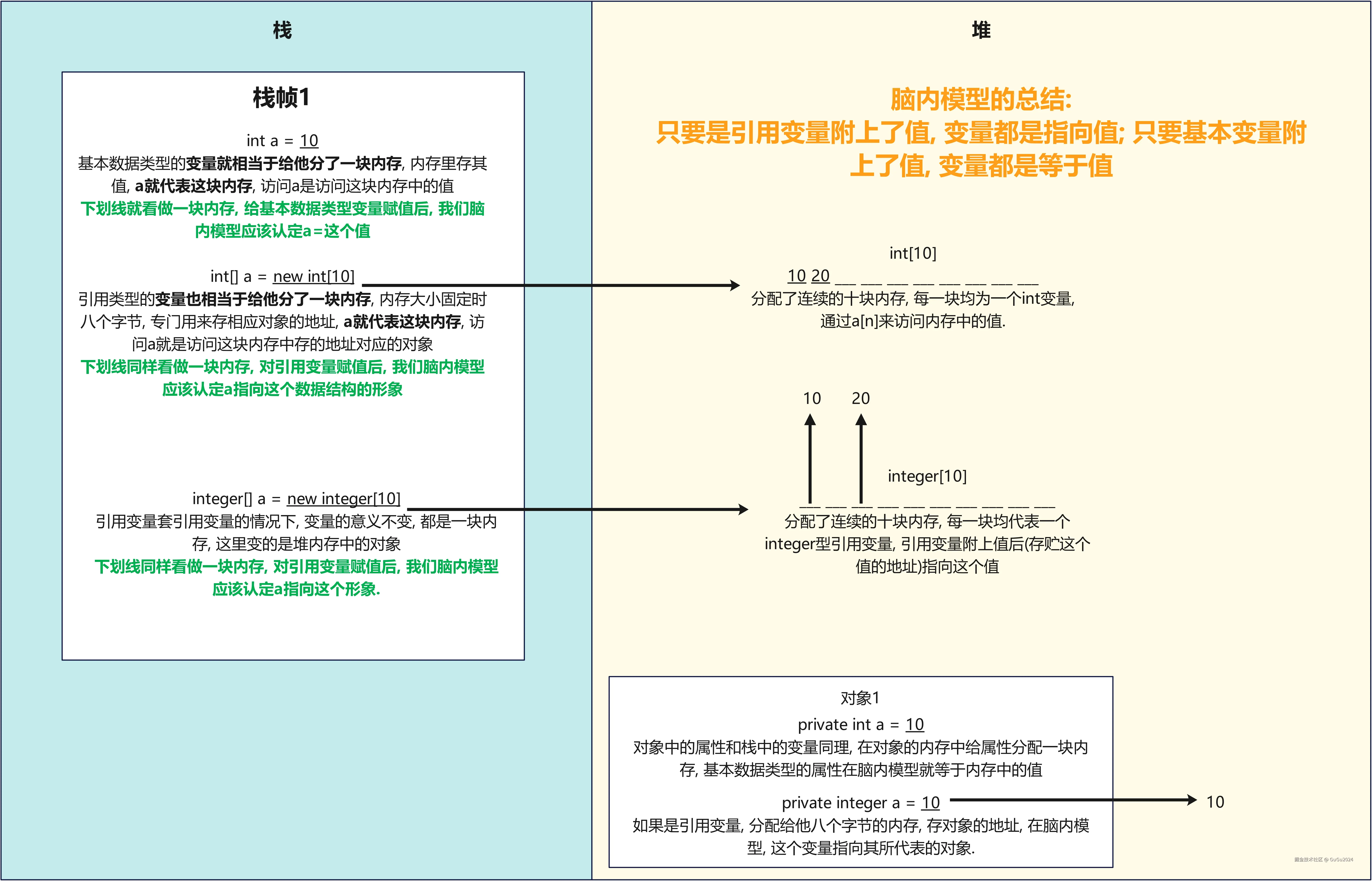
目前我抽象出的脑内模型的总结为:
变量和属性都是一块内存地址, 他们相当于给内存地址起了个名, 根据这个名字我们可以在相应的栈中找到这块地址. 只要是引用变量附上了值, 变量都是指向值; 只要基本变量附上了值, 变量都是等于值.