作者:_Naci Simsek
前言
在流处理领域,Apache Flink 已经成为企业级实时数据处理的首选框架。然而,在生产环境中,开发者和运维人员经常会遇到各种看似神秘的问题。基于过去两年中大量客户在真实场景中的使用案例,可以观察到一些反复出现的问题模式。
本文源自 2025 年数据科学峰会上的演讲《The Flink Mistake Playbook》,结合 Ververica 客户成功经理 Naci Simsek 的实践经验,总结了在生产环境中最容易踩的"三大坑"。这些问题并非理论推演,而是广泛存在于多个真实项目中的典型挑战。

背景与方法论
作者目前任职于 Ververica,担任客户成功经理,该角色使其能够深入了解客户在生产环境中遇到的真实技术难题。作为支持团队的一员,主要职责是协助客户将 Apache Flink 成功应用于关键业务系统。在过去两年中,接触并分析了数十个不同行业的 Flink 部署案例,积累了丰富的故障排查与性能调优经验。
职业背景涵盖多个技术领域:自 2023 年起专注于实时流处理技术支持;2016--2023 年在 Telefonica O2 负责大数据平台的现场技术管理,积累了平台运维与 BI 数据仓库建设经验;2010--2016 年于华为担任软件开发工程师、团队负责人、项目经理(PMP)及大数据解决方案架构师;早期在 Nortel Netas 担任技术支持工程师。十余年的分布式系统与大数据实践经验,为深入理解流处理系统的复杂性提供了坚实基础。


问题一:Kafka连接器迁移引发的状态管理问题
问题背景:从旧到新的必然迁移
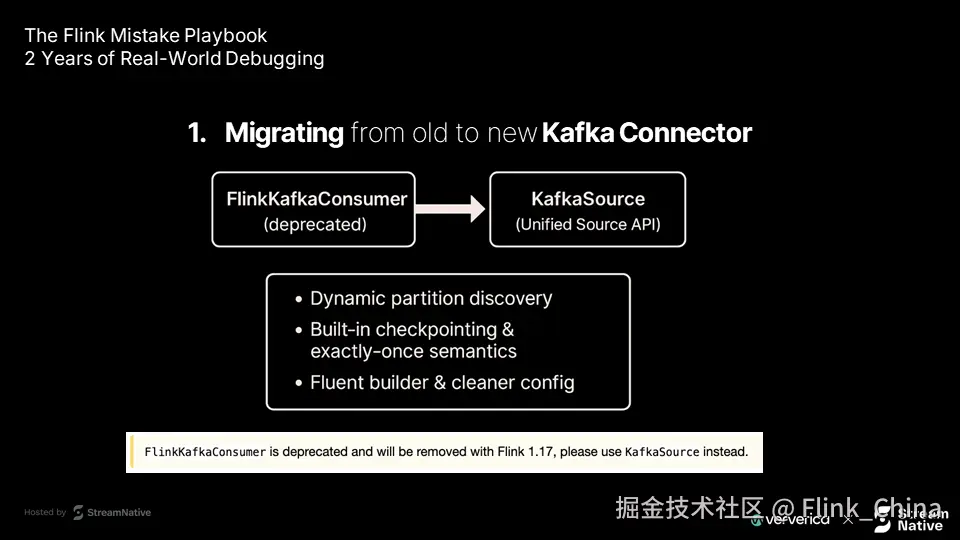
许多用户正在或将要将 Flink 作业从旧版 Kafka 连接器(如 FlinkKafkaConsumer)迁移到新版 KafkaSource API。这不是一个可选项,而是 Apache Flink 生态持续演进的必然趋势。
新版 KafkaSource 提供了多项关键优势:
-
动态分区发现(Dynamic Partition Discovery):自动感知新增 Kafka 分区
-
内置检查点机制:提升状态一致性保障能力
-
精确一次语义(Exactly-Once Semantics):有效避免数据重复处理
-
流式构建器接口(Fluent Builder):API 更直观、易维护
尽管新 API 功能强大,但在实际迁移过程中,不少团队遇到了严重的状态管理问题。
症状表现:从保存点恢复时的失败
最常见的问题是:尝试从现有保存点恢复作业时,作业启动失败。以下是两种典型错误表现:

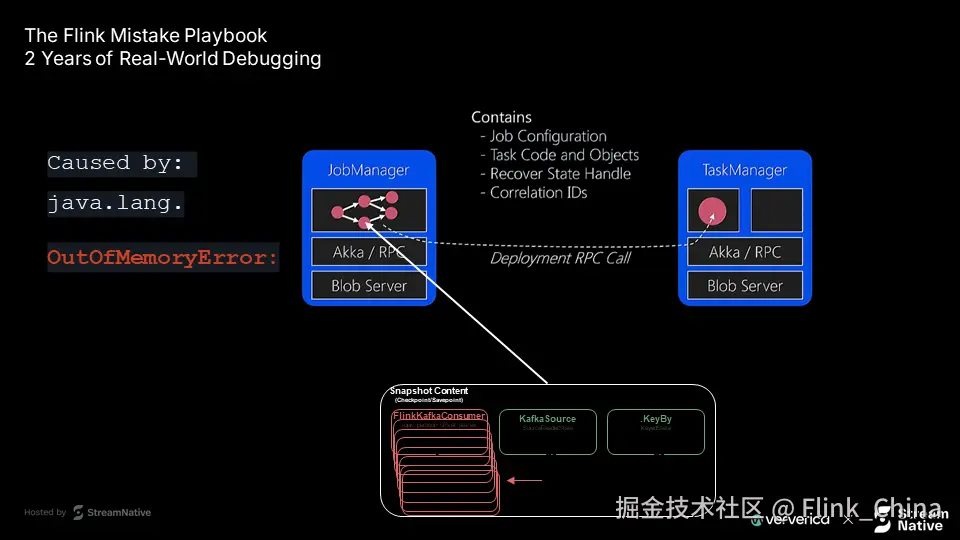
第一种错误 - RPC调用超限:
plaintext
org.apache.flink.runtime.JobException
Caused by: java.io.IOException:
The rpc invocation size 67158903 exceeds the maximum akka framesize.该错误中的数值 67,158,903 字节约等于 64MB,表明 JobManager 尝试通过 Akka 发送一个超出默认帧大小限制的巨大消息。
第二种错误 - JobManager 内存溢出:
plaintext
JobManager OutOfMemory当 JobManager 内存配置较低,却需加载过大的保存点时,极易触发此问题。表面上看,两种错误表现不同,但其根源高度一致。
技术原理深度解析
Flink 状态管理机制:理解问题背景
要理解该问题,需先掌握 Flink 的状态管理机制。
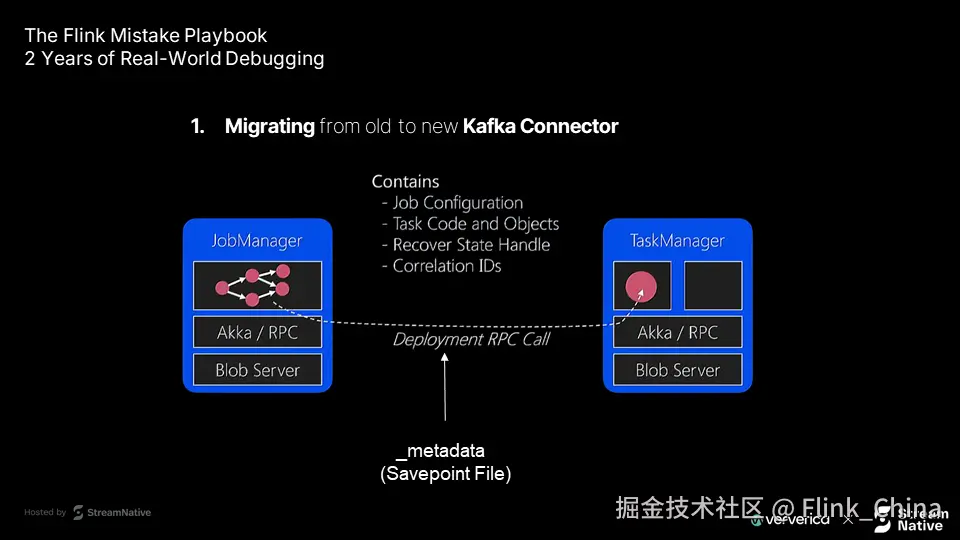
Flink 创建保存点时,JobManager 会从远程存储(如 S3、HDFS)读取保存点数据,其中包含一个名为 _metadata 的关键文件。
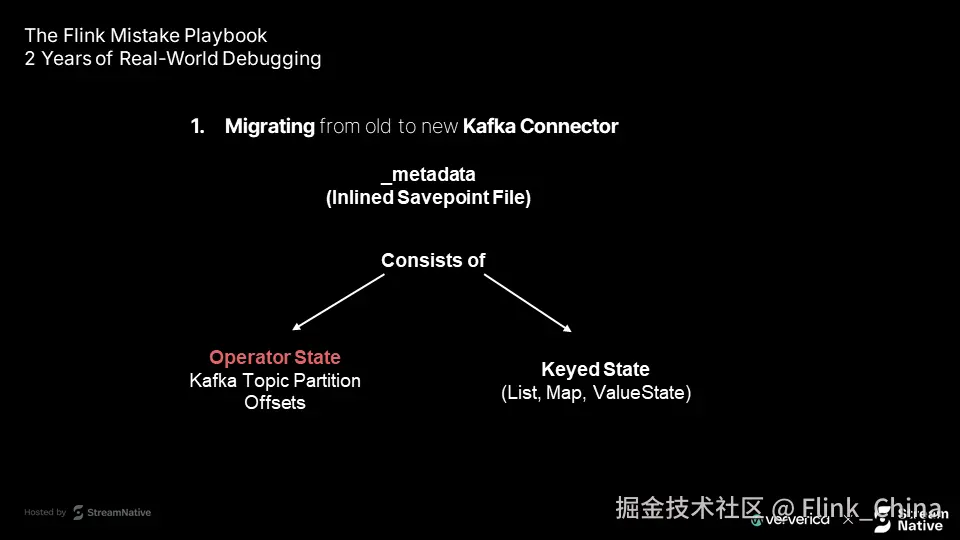

该文件的作用包括:
-
内联状态存储:可直接嵌入部分实际状态数据,而不仅是元信息
-
存储算子状态:如 Kafka 主题分区偏移量
-
存储键控状态:如 List、Map、ValueState 等
JobManager 在恢复作业时,会通过 RPC 将 _metadata 中的状态分发给各 TaskManager。一旦该文件过大,就可能触发 RPC 消息超限或内存溢出。
问题根因分析:UID 复用导致状态累积
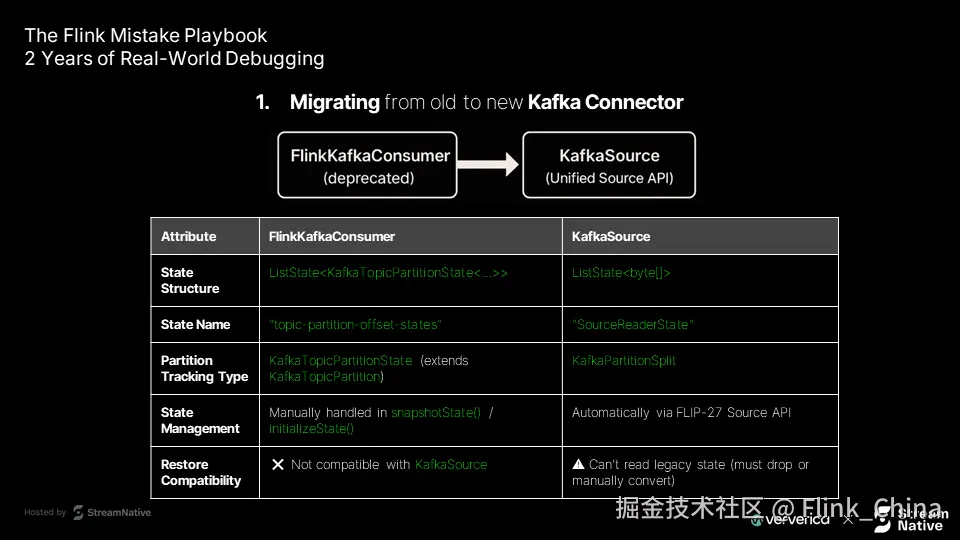
问题的核心在于 算子 UID 的复用 与 状态类型变更 之间的冲突。
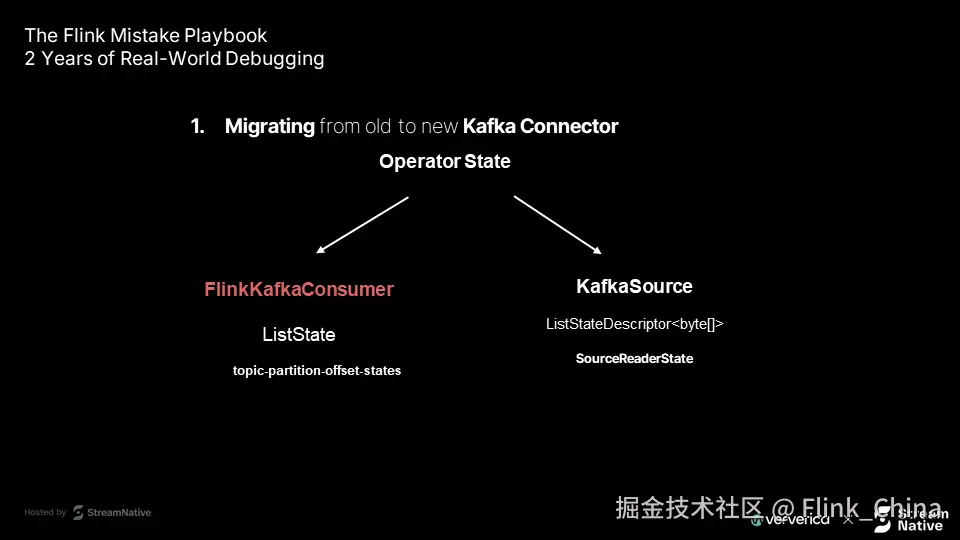
第一层原因:状态对象类型变化
-
旧连接器(FlinkKafkaConsumer) 使用
TopicPartitionOffsetState存储偏移量 -
新连接器(KafkaSource) 使用
SourceReaderState存储读取器状态
两者结构完全不同,但若迁移时保持相同 UID,Flink 会尝试复用旧状态。
第二层原因:UID 复用的陷阱
!slides10-14 图10-14:根因分析 - UID 复用问题详解

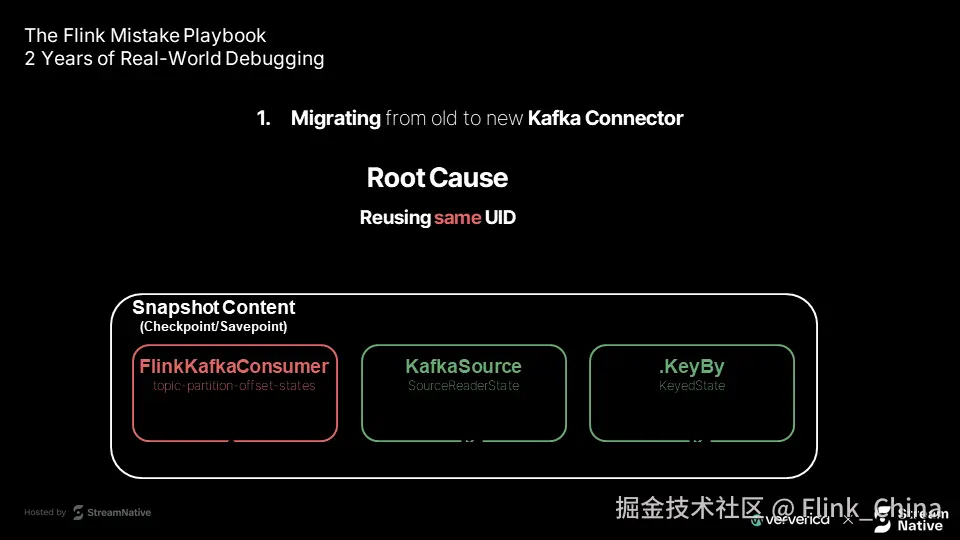
典型误操作是:认为"只是更换 API,功能未变",于是保留原有 UID。但 Flink 依赖 UID 关联算子与状态。当 UID 相同,系统会错误地将旧状态尝试恢复到新算子。
其行为逻辑如下:
-
Flink 使用 UID 匹配状态数据
-
无法识别新旧状态对象的不兼容性
-
每次检查点都会复制旧的废弃状态
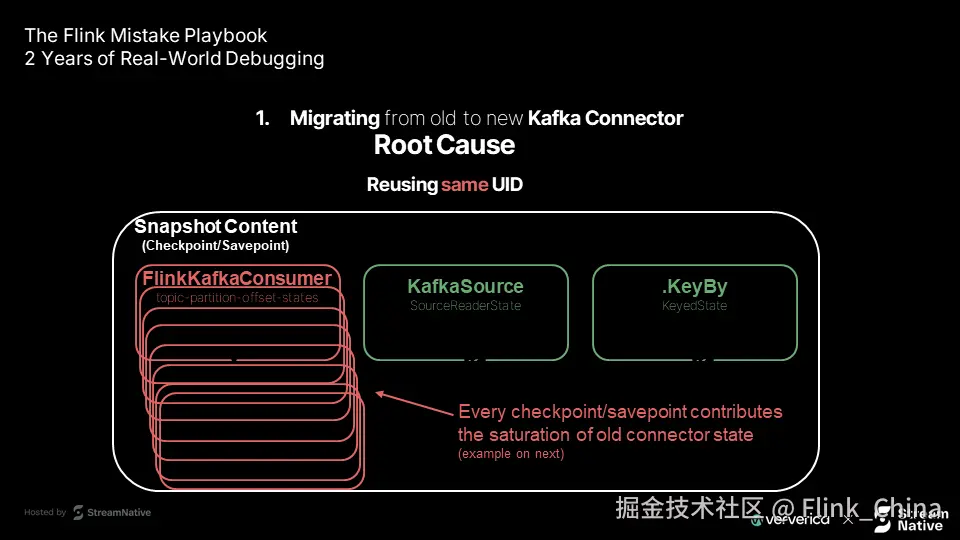
第三层原因:状态文件指数级膨胀
以 10 个 Kafka 分区为例:
-
正常情况:保存点中应有 10 条偏移记录
-
存在 UID 复用问题时:每次检查点都复制旧状态,导致记录数呈指数增长(10 → 20 → 40 → 80...)
最终 _metadata 文件急剧膨胀,超出 RPC 限制。
解决方案

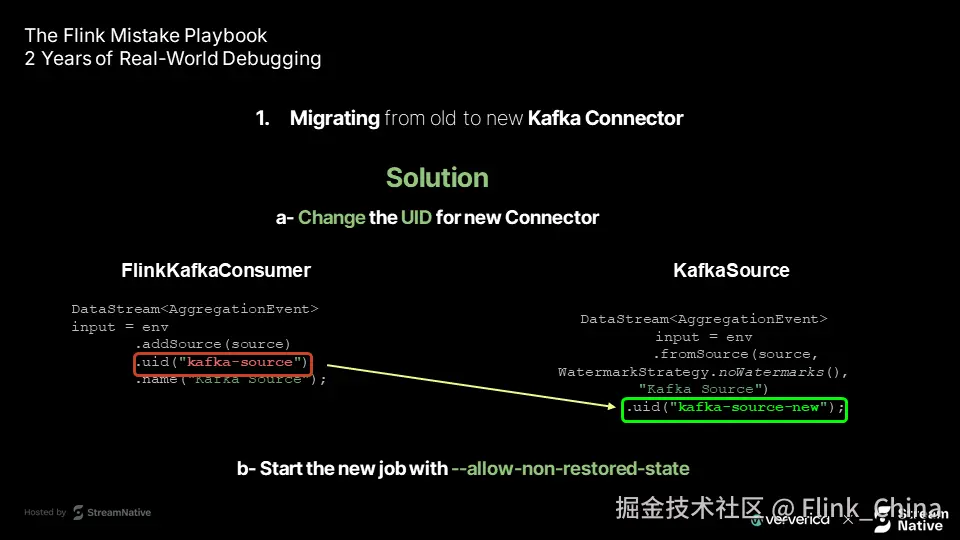
解决方案:断开状态关联,启用非恢复模式
关键在于明确告诉 Flink:这是一个新算子,不应恢复旧状态。可通过以下两步实现:

第一步:修改算子 UID
java
// 旧代码(FlinkKafkaConsumer)
DataStream<AggregationEvent> input = env
.addSource(source)
.uid("kafka-source")
.name("Kafka Source");
// 新代码(KafkaSource)
DataStream<AggregationEvent> input = env
.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
.uid("kafka-source-new"); // 显式使用新 UID通过更改 UID,Flink 将其识别为全新算子,不再尝试恢复旧状态。
第二步:启用非恢复状态选项
bash
flink run --fromSavepoint /path/to/savepoint \
--allow-non-restored-state \
your-job.jar--allow-non-restored-state 参数允许作业忽略无法匹配的状态。所有与旧 UID 关联的废弃状态将被安全丢弃。
效果:从下一次检查点开始,保存点仅包含新算子所需状态,文件大小迅速恢复正常。
最佳实践建议
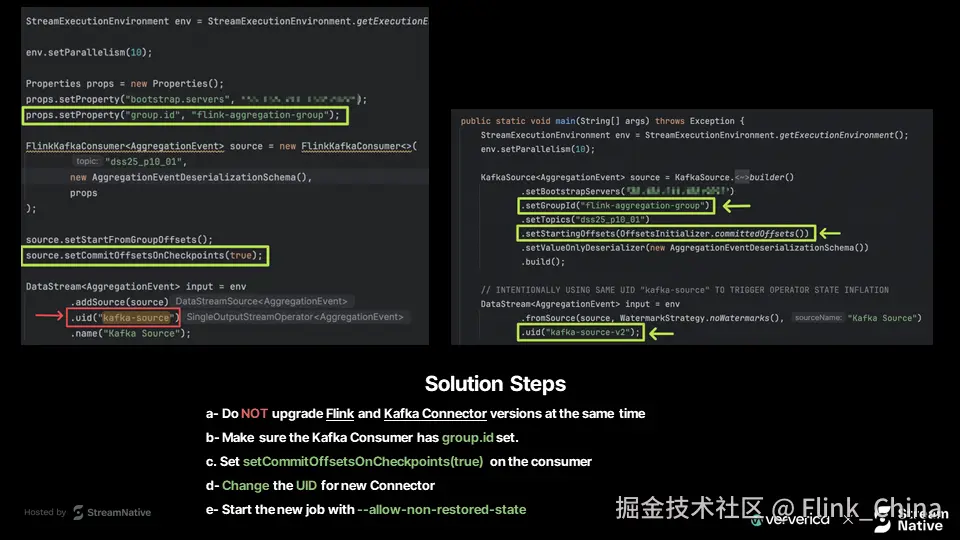
从多个案例中总结出以下建议:
-
建立 UID 命名规范 在项目初期定义算子 UID 策略,如加入版本号:
kafka-source-v1、kafka-source-v2 -
制定 API 升级检查清单 每次关键依赖升级前,评估状态兼容性、规划 UID 变更、准备回滚方案
-
实施状态监控 定期监控保存点大小。若发现异常增长,可能是状态累积的征兆
-
测试环境完整验证 所有迁移操作应在测试环境完整复现,包括从保存点恢复的全流程测试
问题二:任务槽负载分配不均问题
症状:资源利用不均衡

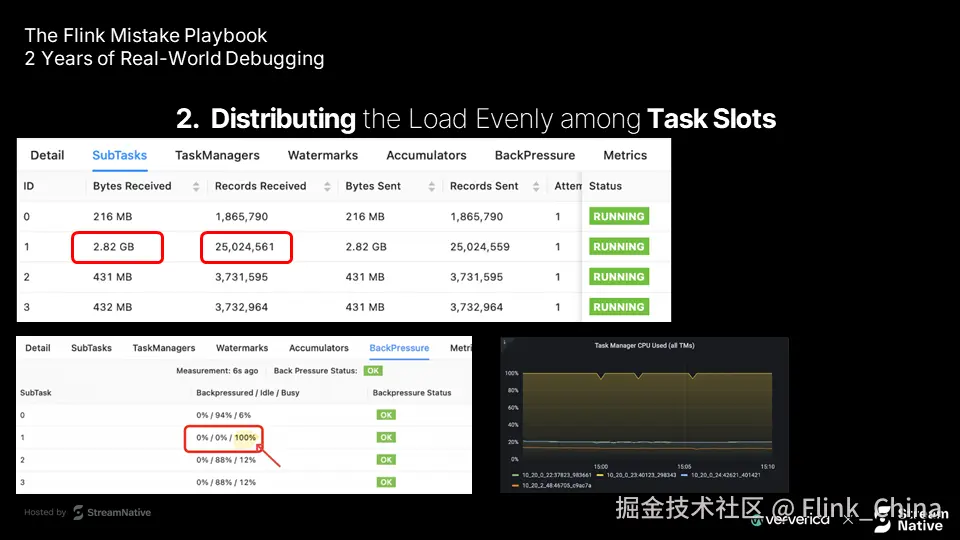

常见反馈是:虽然设置了并行度为 10,但部分 TaskManager CPU 达到 100%,而其他却接近空闲。
典型表现包括:
-
资源利用不均,存在明显热点
-
整体吞吐受限于最忙的任务槽
-
背压向上游传播,影响整体稳定性
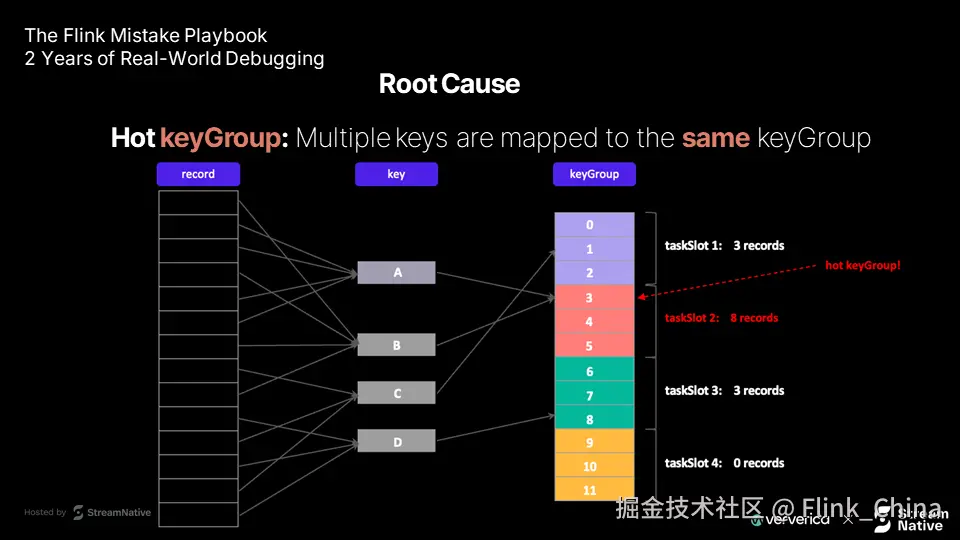
根本原因:数据分布倾斜
问题根源在于现实数据的非均匀性:
- 键控流天然倾斜 例如电商系统中,少数热门商品的访问量远高于冷门商品。若按商品 ID 分组(keyBy),处理热门键的任务槽将承受不成比例的负载。
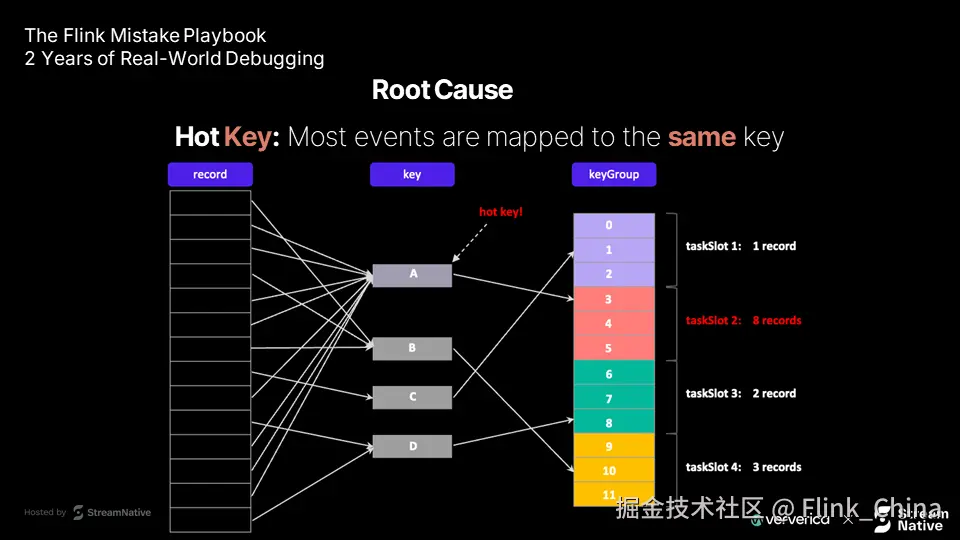
-
默认哈希分区的局限性 Flink 默认使用键的哈希值进行分区,对均匀键空间假设成立,但实际数据常不符合此假设。
-
并行度设置缺乏数据感知 许多团队仅凭经验设置并行度,未结合数据分布特征进行评估,导致资源分配失衡。
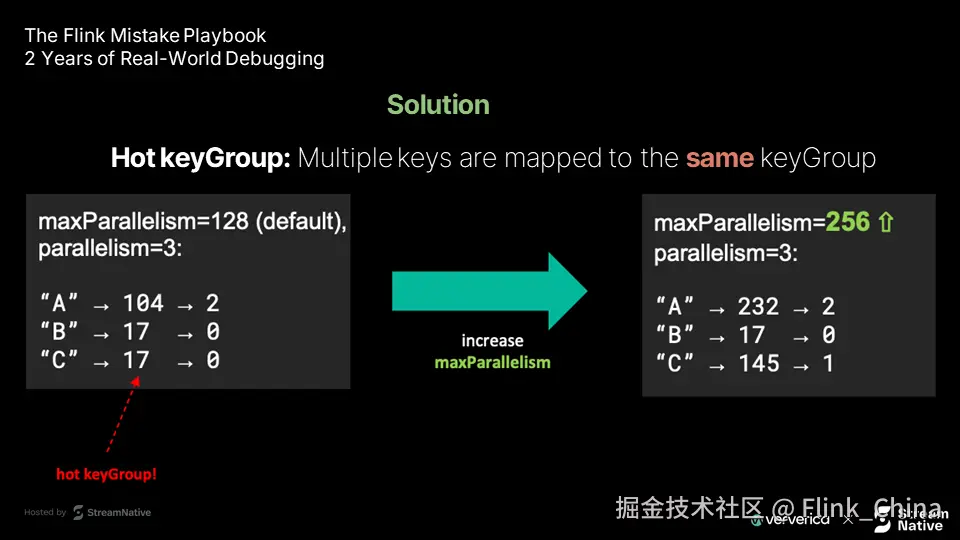
解决方案:智能负载均衡策略
- 数据预处理与重平衡 在 keyBy 前加入采样或数据打散步骤,提升负载均衡性。
-
自定义分区策略 实现
Partitioner接口,根据业务逻辑优化数据分布。例如对高频键添加随机后缀。 -
动态重平衡机制 利用 Flink 的动态资源管理能力,在运行时根据负载情况调整分区,实现更精细的调度。

问题三:Kryo 序列化后备机制的性能陷阱
症状:性能骤降
常见现象包括:
-
处理特定记录时出现延迟尖峰
-
高负载下吞吐量显著低于预期
-
CPU 占用高,但处理速度低
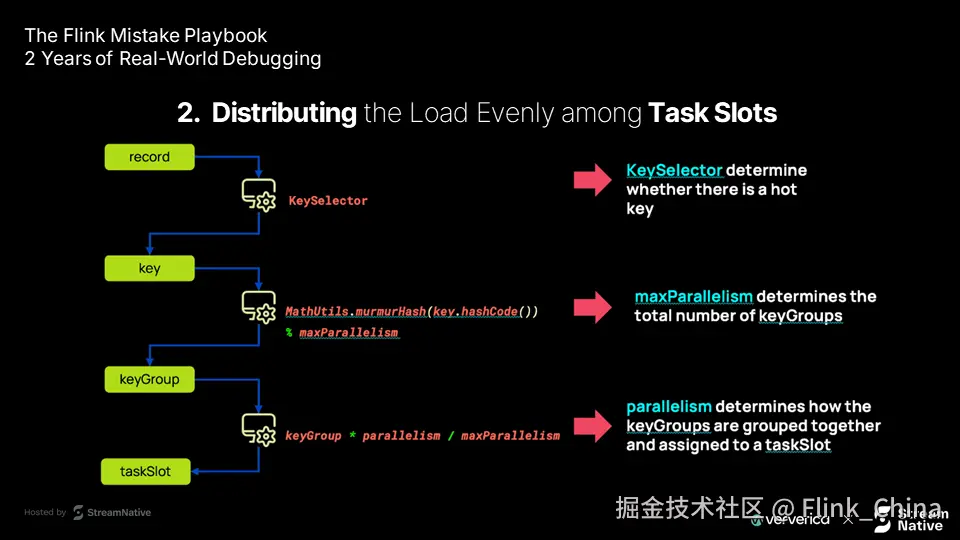
Flink 序列化机制:性能分水岭

Flink 的序列化优先级如下,性能逐层递减:
-
内置序列化器(String、Long 等)
-
数组序列化器
-
复合类型(Tuple、Case Class)
-
POJO 序列化器(推荐)
-
专用格式(Avro、Protobuf)
-
Kryo 回退机制(性能最低)
当无法使用前五类时,Flink 自动回退至 Kryo,可能引发严重性能问题。
性能影响:高达 75% 的性能损失
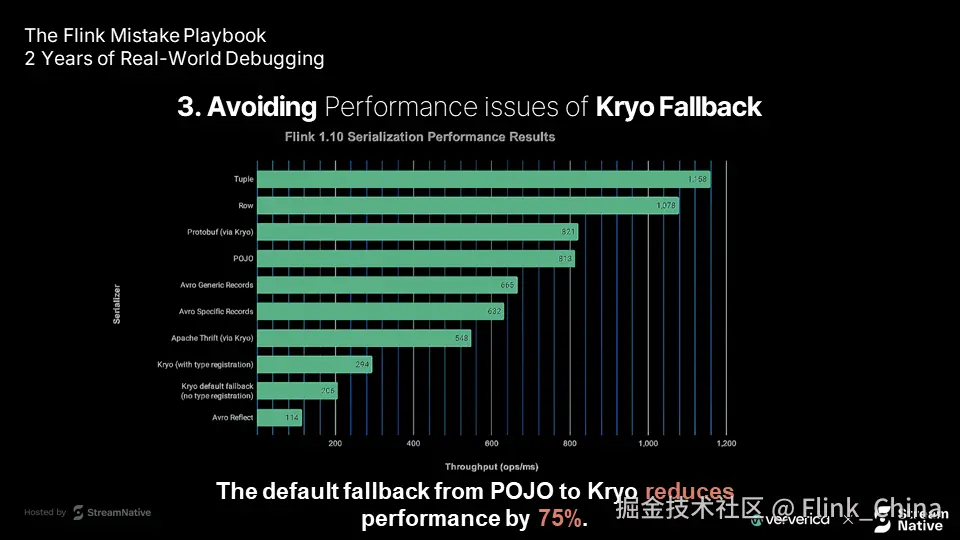
实测数据显示:从 POJO 切换到 Kryo 序列化,性能下降可达 75%。这不是微小差异,而是足以导致作业不可用的"性能悬崖"。
根本原因识别:日志中的线索
Flink 会在启动日志中提示为何启用 Kryo。关键是要关注 TypeExtractor 的 INFO 级日志。

典型日志示例:
1. 字段不符合 POJO 规范
plaintext
Class cannot be used as a POJO type because not all fields are valid POJO fields2. 缺少默认构造函数
plaintext
class is missing a default constructor so it cannot be used as a POJO type3. 泛型类型信息缺失
plaintext
contains generic type parameters, please specify them这些日志是性能问题的重要线索。
解决方案详解





完美 POJO 设计检查清单
| 要求 | 示例 | 说明 |
|---|---|---|
| ✅ 公共类 | public class MyPojo |
非 public 类无法作为 POJO |
| ✅ 无参构造函数 | public MyPojo() {} |
必须提供,即使已有有参构造 |
| ✅ 可访问字段 | 提供 getter/setter 或字段 public | Flink 需能读写所有字段 |
| ✅ 避免特殊修饰符 | 不使用 transient/static/final |
这些字段不会被序列化 |
| ✅ 使用具体集合类型 | ArrayList<String> 优于 List<String> |
Flink 更擅长处理具体类型 |
| ✅ 泛型类型注解 | @TypeInfo(...) |
对复杂泛型提供显式类型信息 |
终极建议:启用 fail-fast 模式
java
env.getConfig().disableGenericTypes();该配置会在作业启动时立即失败,若存在无法优化为高效序列化的类型。虽看似严格,但能强制在开发阶段暴露潜在性能问题,避免生产环境"雪崩"。
总结:从实战中提炼的洞察
基于多个客户案例的分析,可得出以下核心结论:
核心洞察
-
状态管理是架构设计的一部分 UID 不仅是标识符,更是状态生命周期的控制开关。理解其机制可避免大量"神秘"问题。
-
性能优化始于数据模型设计 75% 的性能差异源自序列化策略。优先使用 Flink 原生支持类型,避免无意中触发 Kryo。
-
负载均衡需面向真实数据分布 数据倾斜是常态。系统设计必须包含应对不均分布的策略。
-
版本升级需有章法 每次 API 升级都应伴随状态兼容性评估与测试验证,而非简单替换。
实战建议
-
建立主动监控体系 监控保存点大小、序列化类型分布、任务槽负载等关键指标。
-
沉淀团队知识 将最佳实践文档化,避免经验依赖个人。
-
理性对待技术更新 跟进新特性,但应理解其设计动机与适用场景。
-
参与社区交流 Flink 社区活跃,共享问题常能快速获得解决方案。
最后的思考
技术问题的背后,往往反映出对系统理解的深度、对变更的准备程度以及对复杂性的管理能力。每一个看似复杂的问题,通常都有清晰的解决路径------关键在于深入理解其本质。