本文首发【零一探秘】公众号
今天分享的主题是关于如何使用用 Spring AI 和 ElevenLabs 实现文本转语音(Text-to-Speech)的实时流式传输。即通过在 Spring Boot 中使用流式响应这种方式,来构建即时播放、响应迅速的音频应用。
通过流式响应(streaming responses) 的方式传输,音频数据一经生成就会立刻分块发送给客户端,用户可以马上开始收听,而剩余的部分则继续在后台处理。
什么是流式传输
我们平常在各种视频网站观看视频时,不需要等整个视频文件下载完才开始观看,它会边下载边播放。 在这里,可以把同样的流媒体技术应用到文本转语音(TTS)应用中。
服务器不再需要等待一个巨大的音频文件生成完毕,而是会一小块地接收音频数据,并立即转发给客户端。这种技术被称为 "分块传输编码"(chunked transfer encoding) ,可以极大地缩短用户感官上的等待时间。
我画了一个简单的流程图来便于大家理解,主要的流程包括:用户输入 → 构建prompt提示词 → spring AI流式调用 → ElevenLabs API流式传输 → 即时播放
 本文中主要介绍Spring AI 文本转语音流式处理方案,主要有以下3点好处:
本文中主要介绍Spring AI 文本转语音流式处理方案,主要有以下3点好处:
- 降低延迟: 用户几乎可以立刻听到声音,这对于聊天机器人或虚拟助手这类需要实时互动的应用来说至关重要;
- 提升用户体验: 即时反馈让应用感觉更灵敏、更快捷;
- 节省内存: 服务器无需在内存中保留整个庞大的音频文件,应用更容易扩展;
构建一个实时文本转语音流式 API 实践
在本文中,我将构建一个简单的Spring Boot 服务来进行演示; 它接收文本提示,将生成的音频以实时流的方式返回给客户端。
Spring Boot 应用结构:

简单介绍下项目里的关键文件还有它们的作用。
- TextToSpeechController.java 处理 /api/tts/stream 接口,负责音频流。
- TextToSpeechRequest.java 是请求参数的 DTO。定义了文本和语音设置。
- SpringAITextToSpeechElevenlabsStreamingResponseApplication.java: Spring Boot 主启动类。
- application.yml:配置 ElevenLabs API 密钥和 TTS 选项。
- static/index.html:前端页面-用来测试 TTS API。
第一步:添加 Maven 依赖
关于Maven 依赖部分,这里就不再赘述了,我之前发布的spring ai系列文章给出了参考的pom文件,这里只需额外添加以下依赖即可:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-elevenlabs</artifactId>
</dependency>需要注意的是:jdk必须使用17以上版本
第二步:配置应用属性
接下来,让我们配置应用的属性文件application.yaml
yaml
spring:
ai:
elevenlabs:
text-to-speech:
api-key: ${ELEVENLABS_API_KEY}
options:
model-id: eleven_multilingual_v2
output-format: mp3_44100_128
logging:
level:
org:
zalando:
logbook: TRACE在这里,我们使用的是支持多种语言的 eleven_multilingual_v2 模型。api-key可以在https://elevenlabs.io/app/developers/api-keys注册免费获取。
第三步:应用入口点
SpringAITextToSpeechElevenlabsStreamingResponseApplication.java是启动我们整个应用的主类。
typescript
@SpringBootApplication
public class SpringAITextToSpeechElevenlabsStreamingResponseApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAITextToSpeechElevenlabsStreamingResponseApplication.class, args);
}
@Bean
public ElevenLabsTextToSpeechAutoConfiguration.DefaultTextToSpeechRestClientBuilderCustomizer textToSpeechRestClientBuilderCustomizer(Logbook logbook) {
return new ElevenLabsTextToSpeechAutoConfiguration.DefaultTextToSpeechRestClientBuilderCustomizer(
new RestTemplateBuilder()
.additionalInterceptors(new LogbookClientHttpRequestInterceptor(logbook))
);
}
}运行这个类时,Spring Boot 会初始化所有组件并启动内嵌的服务器。
第四步:创建数据传输对象(DTOs)
用 Java 的 record 定义请求模型很简洁。举个例子:
arduino
public record TextToSpeechRequest(
String text,
String voiceId,
Float stability,
Float similarityBoost,
Float style,
Boolean useSpeakerBoost) {}每个字段都对应TTS生成时的参数。比如要转换的文本/声音ID。像Rachel的就是"21m00Tcm4TlvDq8ikWAM"。还有些可选的音色设置。这样一来结构就清晰多了。代码也更容易维护了。
第五步:控制器层:API 接口
TextToSpeechController 暴露我们的流式传输接口
less
@RestController
@RequestMapping("/api/tts")
public class TextToSpeechController {
@Autowired
private ElevenLabsTextToSpeechModel textToSpeechModel;
@PostMapping("/stream")
public ResponseEntity<StreamingResponseBody> ttsStream(@RequestBody TextToSpeechRequest textToSpeechRequest) {
var options = ElevenLabsTextToSpeechOptions.builder()
.withVoiceId(Objects.requireNonNullElse(textToSpeechRequest.voiceId(), "21m00Tcm4TlvDq8ikWAM"))
.withStability(textToSpeechRequest.stability())
.withSimilarityBoost(textToSpeechRequest.similarityBoost())
.withStyle(textToSpeechRequest.style())
.withSpeakerBoost(textToSpeechRequest.useSpeakerBoost())
.withModelId("eleven_multilingual_v2")
.withOutputFormat(ElevenLabsApi.OutputFormat.MP3_44100_128)
.build();
TextToSpeechPrompt textToSpeechPrompt = new TextToSpeechPrompt(textToSpeechRequest.text(), options);
Flux<TextToSpeechResponse> responseStream = textToSpeechModel.stream(textToSpeechPrompt);
StreamingResponseBody responseBody = new StreamingResponseBody() {
@Override
public void writeTo(OutputStream outputStream) throws IOException {
responseStream.toStream().forEach(speechResponse -> {
try {
outputStream.write(speechResponse.getOutput().getContentAsByteArray());
outputStream.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
});
}
};
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_TYPE, "audio/mpeg")
.body(responseBody);
}
}核心逻辑是这样的:
- 返回 ResponseEntity: 实现音频流式传输。
- 调用 textToSpeechModel.stream(): 获取 ElevenLabs 音频流。也就是 Flux。
- 用 lambda 把音频块写到响应的 OutputStream 里。并且实时刷新。
- 设置 Content-Type 为 audio/mpeg,返回流式音频响应。
这里我画了一张流式处理的流程图来便于大家理解:
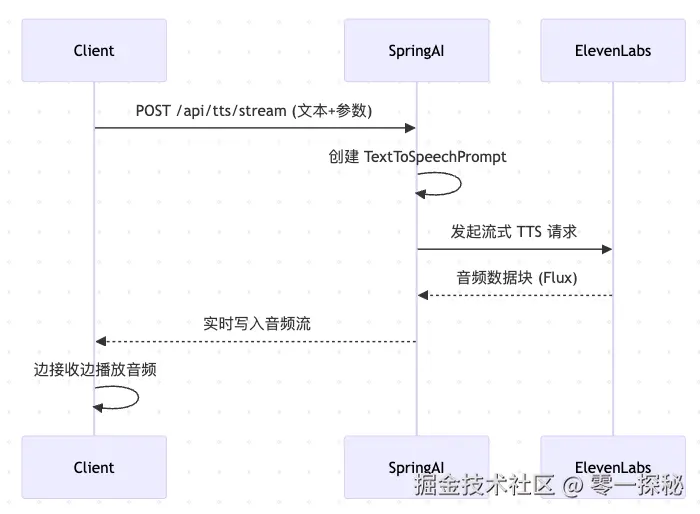
应用启动后,可以通过命令行或网页界面体验流式语音功能。
命令行测试(cURL)
cURL 是快速测试 API 的利器。加上 --no-buffer,可以实时看到流式传输效果:
css
curl --location --request POST 'http://localhost:8080/api/tts/stream' \
--header 'Content-Type: application/json' \
--data '{
"text": "Hello, this is a real-time streaming test from Spring AI!",
"voiceId": "21m00Tcm4TlvDq8ikWAM"
}' \
--output speech.mp3 --no-buffer执行后会得到一个 speech.mp3 文件,包含生成的语音。
如果想直接试听,可以用 ffplay 或 mpv 播放,没有 GUI,直接在终端运行,简单高效:
css
curl --location --request POST 'http://localhost:8080/api/tts/stream' \
--header 'Content-Type: application/json' \
--data '{
"text": "Hello, this is a real-time streaming test from Spring AI!",
"voiceId": "21m00Tcm4TlvDq8ikWAM"
}' | ffplay -网页测试体验
我还准备了一个简洁的 index.html 页面,方便你直接在浏览器里测试流式语音。你可以输入文本、选择声音,还能用滑块调整各项参数。
主要功能包括:
- 实时进度条和统计,清楚看到接收速度和数据块数量
- 音频流预览,支持十六进制和 ASCII 展示
- 基于 MSE 的流式播放,现代浏览器即刻试听
- 交互式参数控制,随时调整 ElevenLabs 的声音选项
- 控制台日志,方便调试和观察整个过程
用这个页面,你可以自由尝试不同的声音设置,感受低延迟的流式播放。
完整的 HTML 文件以及代码 demo 我已经上传到了github仓库中, 链接在文章底部。
Web UI 测试指南
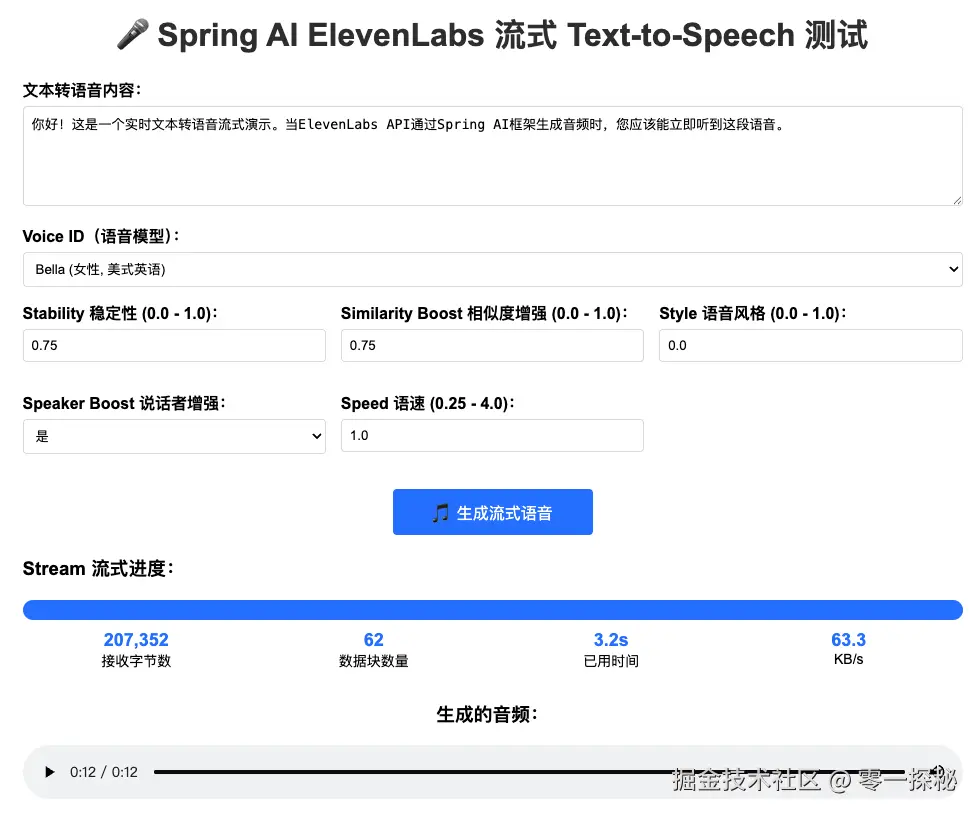
启动 Spring Boot 服务后,直接在浏览器访问 http://localhost:8080。
界面很直观:输入文本,选声音,调参数,点击"生成流式语音"就能实时听到语音。下方还能看到接收进度和流式数据日志,方便观察整个过程。
注意事项
实现流式 TTS 时,有几个坑需要注意:
- 网络要稳,断线要有错误处理和重试。
- 前端要兼容流式音频,主流浏览器没问题,老版本可能要特殊处理。
- 虽然服务端内存压力小了,客户端长时间播放还是得关注内存消耗。
- 流式过程中要细致处理各种错误,比如超时、API 限流等。
- 多用户并发时,建议加上队列或限流,避免资源被打爆。
- 音质和延迟要权衡,参数调太高可能有卡顿。
写在最后
用 Spring AI 的响应式流和 StreamingResponseBody,TTS 不再只是"生成完再播放",而是可以边生成边听。这样一来,用户体验更顺畅,语音应用也变得更好玩、更实用。
最后附上仓库地址: github.com/lskun/sprin...