在许多真实的机器学习项目中,数据集往往规模较小且存在类别不平衡 的问题。例如,在医学影像任务中,可能只有 5% 的扫描样本属于阳性类别。在这样的数据上训练的模型,只需始终预测多数类,就能轻松达到 95% 的准确率------但却完全无法识别出少数类。
这个问题非常关键,因为它会导致模型过拟合、预测偏差,并且对那些最重要的类别召回率极低。
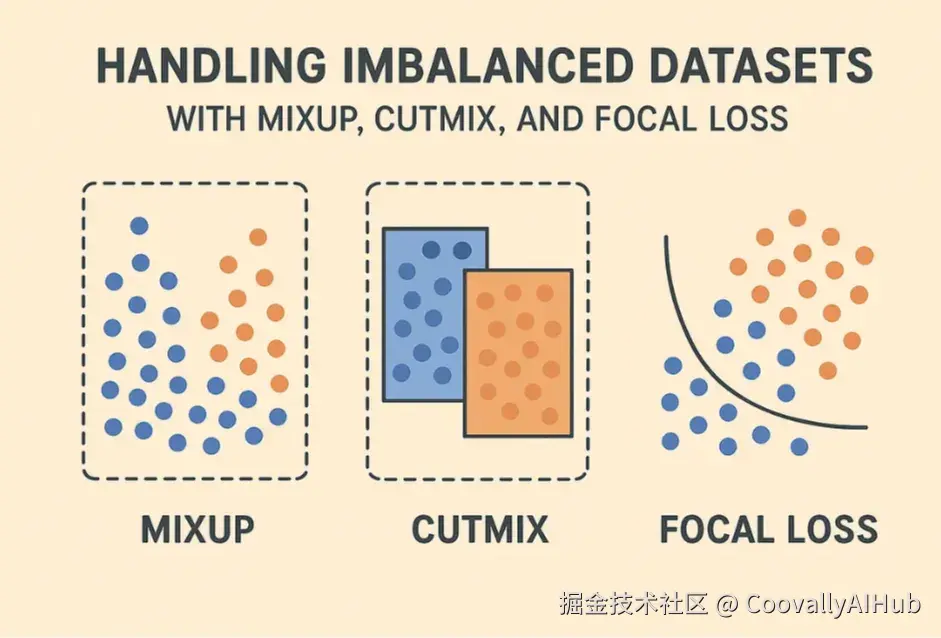
为解决这一挑战,研究者和实践者常常结合使用数据增强 和损失函数 优化技术。本文将重点介绍三种广泛应用的方法:MixUp、CutMix 和 Focal Loss。它们从不同角度发挥作用,共同构成了一种应对小规模和不平衡数据集的强大策略。
什么是不平衡数据集?为什么它们会带来问题?
不平衡数据集指的是各类别样本数量差异显著的数据集。比如在某个医学数据集中,只有 5% 的样本属于阳性类别,而 95% 属于阴性类别。
这种不平衡会在训练过程中引发严重问题。模型可能因为总是预测多数类而显得准确率高。例如,如果 95% 的数据都是阴性,那么一个始终预测"阴性"的模型也能达到 95% 的准确率------但它会完全漏掉所有阳性样本。
这种现象被称为 "准确率假象" :表面上指标很高,实际应用效果却很差。
一些传统的解决方法包括:
- 过采样: 复制少数类样本以平衡数据集。
- 欠采样: 减少多数类样本的数量。
虽然这些方法有一定效果,但它们也存在一些局限,比如过采样容易导致过拟合,欠采样则会损失信息。因此,更先进的方法如 MixUp、CutMix 和 Focal Loss 往往更受青睐。
💡值得一提的是,Coovally平台已经内置了丰富的数据增强方法,用户无需手动编写代码,即可在界面上轻松配置并使用这些增强策略。 同时,Coovally还提供强大的数据标注、管理与版本控制工具,让你的数据工作流清晰且可回溯,从根本上改善数据质量与管理效率。
MixUp
MixUp 是一种数据增强技术,通过将两个训练样本线性组合 来生成新样本。它不仅混合输入图像,还会按比例混合它们的标签。

- 优点:
- 减少过拟合
- 增强模型对噪声标签的鲁棒性
- 提升模型在小数据集上的泛化能力
- 缺点:
- 可能会丢失图像中的空间或位置信息
PyTorch 代码示例:
ini
def mixup_data(x, y, alpha=0.2):
lam = np.random.beta(alpha, alpha)
batch_size = x.size()[0]
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam该函数返回混合后的输入和标签,可直接用于 MixUp 训练。
CutMix
CutMix 是另一种数据增强方法。与 MixUp 整体混合图像不同,CutMix 是从一张图像中裁剪一个区域,粘贴到另一张图像上,并相应调整标签的比例。

- 优点:
- 保留图像的局部信息
- 比 MixUp 提供更强的正则化效果
- 有助于提升对局部特征的检测能力
- 缺点:
- 对非常小的目标效果不佳
- 有时贴片位置可能生成不真实的图像
代码示例:
ini
import torch
import numpy as np
def cutmix_data(x, y, alpha=1.0):
lam = np.random.beta(alpha, alpha)
batch_size, _, H, W = x.size()
index = torch.randperm(batch_size)
# Random patch coordinates
cut_rat = np.sqrt(1. - lam)
cut_w = int(W * cut_rat)
cut_h = int(H * cut_rat)
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
x[:, :, bby1:bby2, bbx1:bbx2] = x[index, :, bby1:bby2, bbx1:bbx2]
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (W * H))
y_a, y_b = y, y[index]
return x, y_a, y_b, lam该函数生成带有混合贴片的新图像和调整后的标签,帮助模型学习更丰富的样本组合。
Focal Loss
Focal Loss 是一种专门针对分类任务中类别不平衡问题设计的损失函数。标准的交叉熵损失容易被多数类中易分类的样本主导,导致模型忽略少数类。
Focal Loss 通过引入一个调节因子,更加关注难以分类的样本:

- 优点:
- 更关注少数类样本
- 在高度不平衡数据集中表现更好
- 缺点:
- 需要调整 γ 和 α 参数
- 如果参数选择不当,可能会减缓收敛速度
代码示例:
python
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
BCE_loss = nn.functional.cross_entropy(inputs, targets, reduction='none')
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1 - pt) ** self.gamma * BCE_loss
if self.reduction == 'mean':
return F_loss.mean()
elif self.reduction == 'sum':
return F_loss.sum()
else:
return F_loss该损失函数在少数类非常重要(如医疗诊断、欺诈检测或罕见事件预测)的任务中特别有用。
如何结合使用 MixUp、CutMix 和 Focal Loss?
这三种技术从不角度应对不平衡数据集的问题,结合使用可以带来更好的效果。以下是一个简单的指导:

- 关键点:
CutMix 保留局部信息,适用于每个对象都很重要的场景
MixUp 平滑决策边界,提升泛化能力,尤其适用于带噪声的数据集
Focal Loss 确保模型关注少数类
训练循环示例:
ini
for inputs, labels in dataloader:
# Apply CutMix
inputs, targets_a, targets_b, lam = cutmix_data(inputs, labels)
# Forward pass
outputs = model(inputs)
# Compute loss with Focal Loss
loss = lam * focal_loss(outputs, targets_a) + (1 - lam) * focal_loss(outputs, targets_b)
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()在实际应用中,人工组合这些方法并调试超参往往非常繁琐。Coovally平台集成了自动超参优化与损失函数推荐机制。 其多模态大模型能够根据任务类型、模型结构及训练结果,自动分析并推荐合适的损失函数(如Focal Loss)及对应超参数,大幅节省调参时间,让模型迭代事半功倍。
结语
小规模和类别不平衡的数据集在真实机器学习项目中非常常见。如果不加以恰当处理,模型很容易过拟合多数类,无法识别出关键的少数类样本。
MixUp、CutMix 和 Focal Loss 是三种从不同角度应对这一问题的技术:
- MixUp:通过混合样本提升泛化能力和抗噪声能力
- CutMix:在增强数据的同时保留局部特征
- Focal Loss:让模型更关注少数类或难分类样本
结合使用这些方法,可以显著提升模型在不平衡数据集上的性能,尤其是在小规模数据环境下。
不妨在你的下一个项目中尝试这些策略,看看模型是如何开始"认真对待"那些真正重要的数据的。