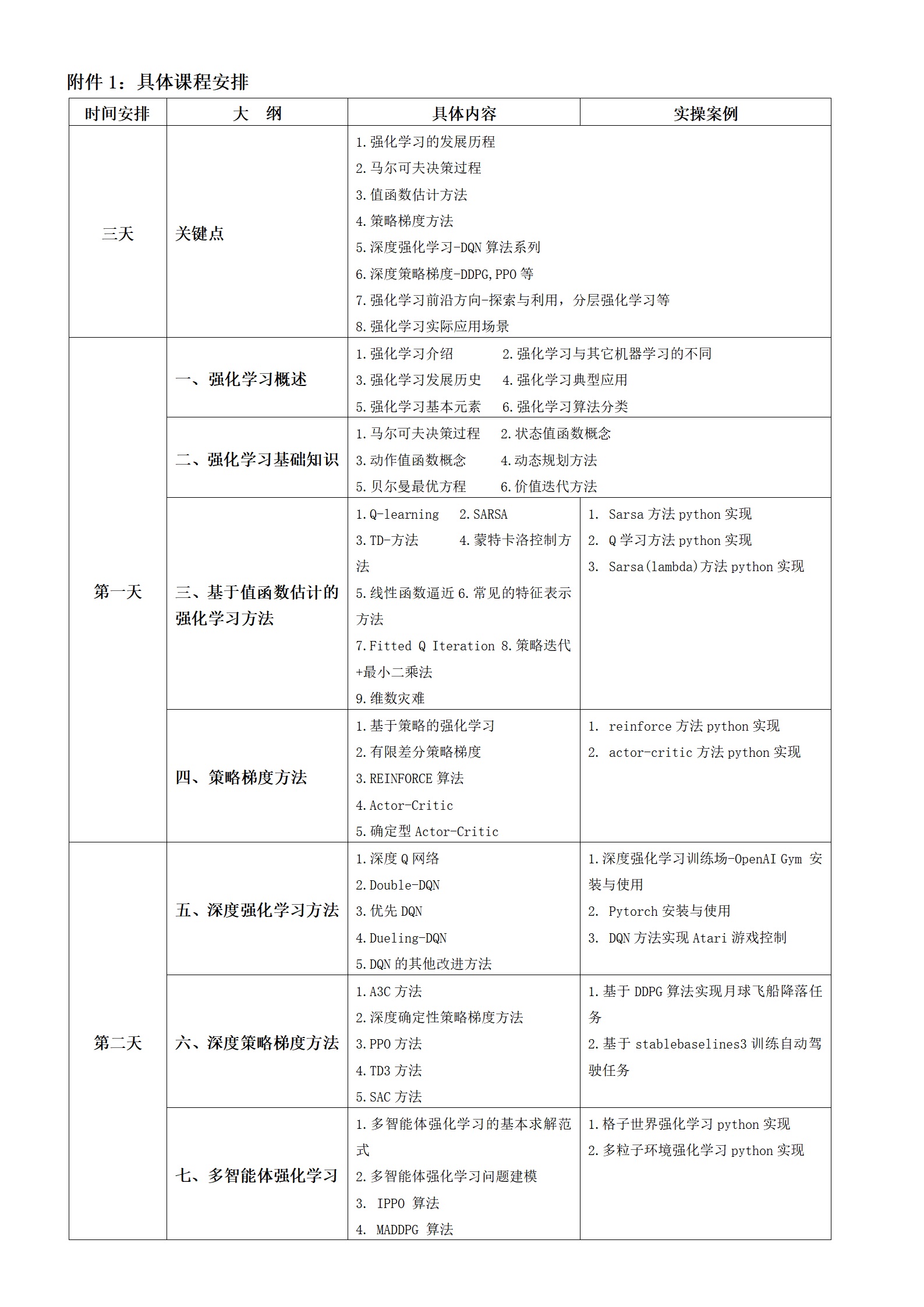
一、什么是马尔可夫决策过程(MDP)?
马尔可夫决策过程(Markov Decision Processes,简称MDP)是一种基于马尔可夫过程理论的数学框架,用于建模在部分随机、部分可由决策者控制的环境中,决策者如何通过序贯决策实现长期目标最优化的问题。它是马尔可夫过程与确定性动态规划相结合的产物,也被称为马尔可夫型随机动态规划,广泛应用于强化学习、运筹学、控制论等领域,是构建智能体与环境交互模型的核心基础。
MDP的核心逻辑是:决策者会周期性或连续性地观察具有马尔可夫性的随机动态系统,根据当前观察到的状态从可用动作集合中选择行动;系统接收动作后,会随机转移到下一个状态,并向决策者反馈即时奖励;决策者再基于新状态进行下一轮决策,如此循环往复。其最终目标是找到一套最优策略,使得决策者在整个交互过程中获得的长期累积奖励最大化。
一个完整的MDP通常由五元组(S, A, P, R, γ)来形式化定义,各要素含义如下:
- 状态集(S):表示系统所有可能所处的状态集合,可为有限或无限。例如在网格世界问题中,每个网格位置就是一个状态。
- 动作集(A):表示智能体(决策者)在任意状态下可采取的所有可能行动的集合。动作可分为离散型(如围棋落子位置)和连续型(如自动驾驶汽车的方向盘转角)。
- 状态转移概率(P):定义为在当前状态s下采取动作a后,系统转移到下一个状态s'的概率,记为P(s'|s,a)。这一概率仅依赖于当前状态和所选动作,是马尔可夫性的直接体现。
- 奖励函数(R):用于量化智能体行为的即时反馈,是一个标量值。常见形式包括R(s,a)(状态s下采取动作a的即时奖励)、R(s,a,s')(状态s采取动作a转移到s'的即时奖励)等,是引导智能体学习最优策略的核心"信号"。
- 折扣因子(γ):取值范围为0,1,用于衡量未来奖励相对于即时奖励的重要性。γ越接近1,说明未来奖励的权重越高;γ越接近0,智能体越倾向于追求即时奖励。
二、马尔可夫性的核心含义
马尔可夫性是马尔可夫决策过程的基础前提,也被称为"无后效性"或"无记忆性",其核心含义可概括为:系统未来状态的条件概率分布仅依赖于当前状态,而与当前状态之前的历史状态序列无关。
从数学角度,马尔可夫性可形式化表示为:对于任意时刻t,以及任意状态序列x₀, x₁, ..., xₜ, xₜ₊₁,满足:
P(Xₜ₊₁ = xₜ₊₁ | Xₜ = xₜ, Xₜ₋₁ = xₜ₋₁, ..., X₀ = x₀) = P(Xₜ₊₁ = xₜ₊₁ | Xₜ = xₜ)
这一公式表明,要预测系统下一时刻的状态,只需掌握当前时刻的状态信息即可,所有过去的状态信息都是冗余的,不会对预测结果产生额外影响。
为了更直观地理解,我们可以借助一个生活化的例子:假设一家餐厅每天供应的食物(汉堡、披萨、热狗)仅取决于前一天的供应品种,与更早之前的供应记录无关。如果已知今天供应汉堡,那么预测明天供应哪种食物只需基于今天的状态(汉堡)和对应的转移概率即可,无需知道昨天、前天的供应情况------这就是马尔可夫性的典型体现。
马尔可夫性的重要价值在于极大地简化了复杂系统的建模与决策难度。在没有马尔可夫性的情况下,决策者需要记忆整个历史状态序列才能预测未来并做出决策;而借助马尔可夫性,只需聚焦当前状态,就能实现对未来的有效预测和最优决策的推导,这也是MDP能够高效求解的关键原因。
|相关学习推荐:强化学习核心技术理论与应用课程