Fast and accurate object detector for autonomous driving based on improved YOLOv5
发表时间:2023年;期刊:scientific reports
论文地址
摘要
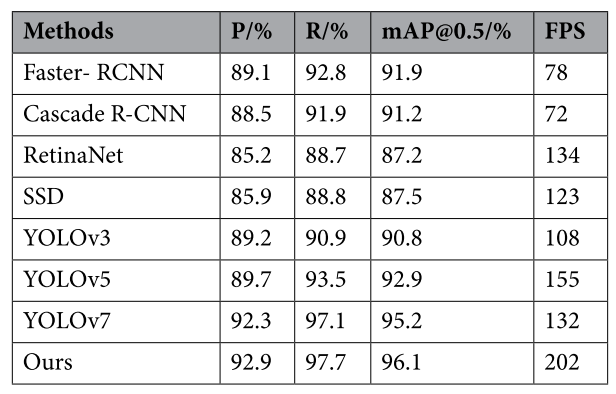
自动驾驶是人工智能的一个重要分支,实时准确的目标检测是保证自动驾驶车辆安全稳定运行的关键。为此,本文提出了一种基于改进的YOLOv5的快速准确的自动驾驶目标检测器。首先,对YOLOv5算法进行了改进,引入结构重参数(REP),通过训练-推理解耦提高了模型的精度和速度。此外,在训练阶段引入了神经架构搜索法对多分支再参数化模块中的冗余分支进行裁剪,提高了训练的效率和精度。最后,在网络中加入小目标检测层,并在各检测层加入协调注意机制,以提高模型对小型车辆和行人的识别率。实验结果表明,该方法在Kitti数据集上的检测准确率达到96.1%,FPS达到202,优于当前的许多主流算法,有效地提高了无人驾驶目标检测的准确性和实时性。
引言
近年来,机动车保有量大幅增加,极大地方便了人们的出行。然而,这一增长导致了日益拥挤的交通状况和交通事故频率的上升,这对安全出行构成了重大挑战。面对日益复杂的交通环境,往往需要个人凭自身经验选择合适的出行路线,应对路上可能出现的各种突发事件。即使是经验丰富的司机也不能幸免于遇到不可预测的危险。
随着大数据、人工智能等计算机技术的发展,智慧城市、自动驾驶等技术手段为缓解交通压力和交通安全问题提供了新的解决方案。无论是智能城市还是自动驾驶,都需要对交通场景进行分析,以获取有用的信息,即感知外部环境 。计算机视觉技术是现阶段感知外部环境最方便、最快捷的技术手段,而目标检测是计算机视觉中最基本、最关键的任务。目标检测识别图像中目标的类别和位置,为计算机视觉中的场景分析提供详细的基本环境信息 。因此,交通场景中的目标检测就成为一个不可或缺的研究方向。当目标检测算法应用于交通场景时,对算法有很高的要求。该算法不仅要求具有较高的识别精度,而且要求满足真实场景的要求。以往对目标检测的研究大多集中在如何通过增加网络层数来提高算法的检测精度 ,进一步优化现有网络。虽然模型的检测精度可以得到一定程度的提高,但由于模型较大,使得算法很难在计算能力较低的设备上运行,检测速度低得令人不快。在大多数交通场景中,设备都在户外使用,特别是在自动驾驶领域,用于运行算法的硬件设备不能具有强大的计算能力。(研究背景)
因此,如何在不影响算法精度性能 的情况下,使目标检测算法尽可能快地实现,从而将目标检测算法移植到车辆上的终端应用中,实现实时的自主驾驶目标检测 是一个棘手的挑战。高精度使得目标检测算法能够更准确地定位和识别前方的车辆或行人,而快速的速度使模型更快地获取外部对象的变化,从而辅助控制系统更合理地运行,确保车内乘员的安全。因此,设计一种精度高、速度快的目标检测算法是实现无人驾驶目标检测的关键。
对于普通的自动驾驶目标检测深度学习方法来说,准确率和速度是两个很难平衡的指标。提出了一种基于改进的YOLOv5算法的快速准确的目标检测算法,实现了检测精度和速度的双重提高。主要贡献概括如下:
1、采用YOLOv5算法作为基线算法,引入结构重参数化(Rep)模块 进行改进,通过训练推理解耦提高了模型的精度和速度。
2、将神经结构搜索(NAS)方法 应用于结构重参数化模块,并自动去除多分支模块中的冗余分支,提高了模型训练的效率和精度。
3、针对车辆和行人小目标检测精度低的问题,增加了一个小目标检测层,并在各检测层中加入协调注意(CA),提高了模型对小目标和不可辨认目标的识别精度。
方法
YOLOv5
YOLOv5是目前最主流的单级目标检测算法之一。YOLOv5算法由三个模块组成:CSP-DarkNet主干网络、FPN+PAN Neck和预测头。如图所示,将尺寸为3×640×640的图片输入到网络中。在骨干网部分,CBS层用于下采样,CSP模块用于特征提取。经过5次下采样后,特征图的大小达到512×20×20。最后,连接SPPF模块,实现不同感受野特征图的融合。在颈部网络部分,特征映射首先经过降维路径,然后再经过降维路径。大小分别为512×20×20、256×40×40、128×80×80的特征地图通过两条路径完全融合。在头网络部分,三种大小的特征映射进入探测头,然后通过1×1卷积层。大小保持不变,通道数变为3×(NC+5),其中3表示三种不同纵横比的锚框,NC表示类别数,5表示用于指示锚帧位置的4个参数加上1个锚帧前景概率。
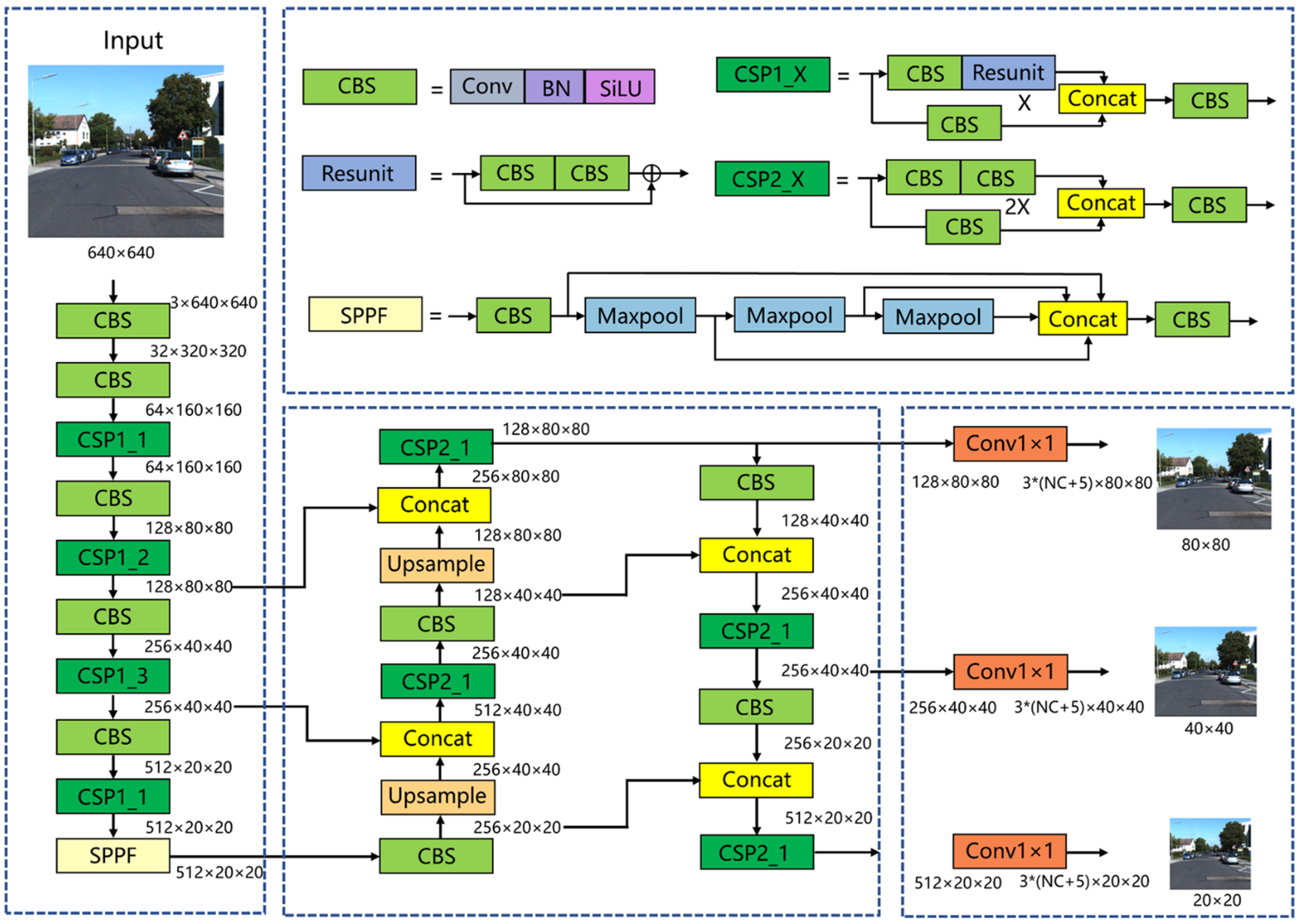
改进YOLOv5总体结构
首先将骨干网中的模块全部改为RepNAS模块,下采样的RepNAS模块数量为1个,未下采样的RepNAS模块数量分别为1、3、3、13个。在训练阶段,非下采样RepNAS模块包含7个分支,而下采样RepNAS模块包含6个分支,这是因为下采样RepNAS模块的输入和输出特征图大小不同,并且不存在标识分支。NAS在训练阶段判断每个模块不同分支的重要性,不断剔除不重要的分支,减少模型冗余,提高模型训练精度和训练效率。REP通过对训练后的参数进行等价变换,实现了RepNAS模块结构的简化。也就是说,将主干网络中的所有RepNAS模块转换为3×3卷积层,使主干网络在推理阶段成为VGG式的体系结构,使得推理速度显著加快,并保持了模型训练的高精度。其次,增加了×160×160的小目标特征检测层。如图所示,在颈部网络中,160×160特征映射利用骨干网络中的浅层信息进行特征融合。浅层网络特征图分辨率较高,包含的小目标信息较多,因此增加一个大小为160×160的检测层可以更好地实现对小目标的定位和识别。最后,在每个检测层之前都有CA注意机制。之所以在检测层之前添加CA,是因为检测层之前的特征映射已经被充分提取和融合,并且语义信息是完整的。因此,在这里加入注意机制可以使模型更多地关注语义丰富的通道。
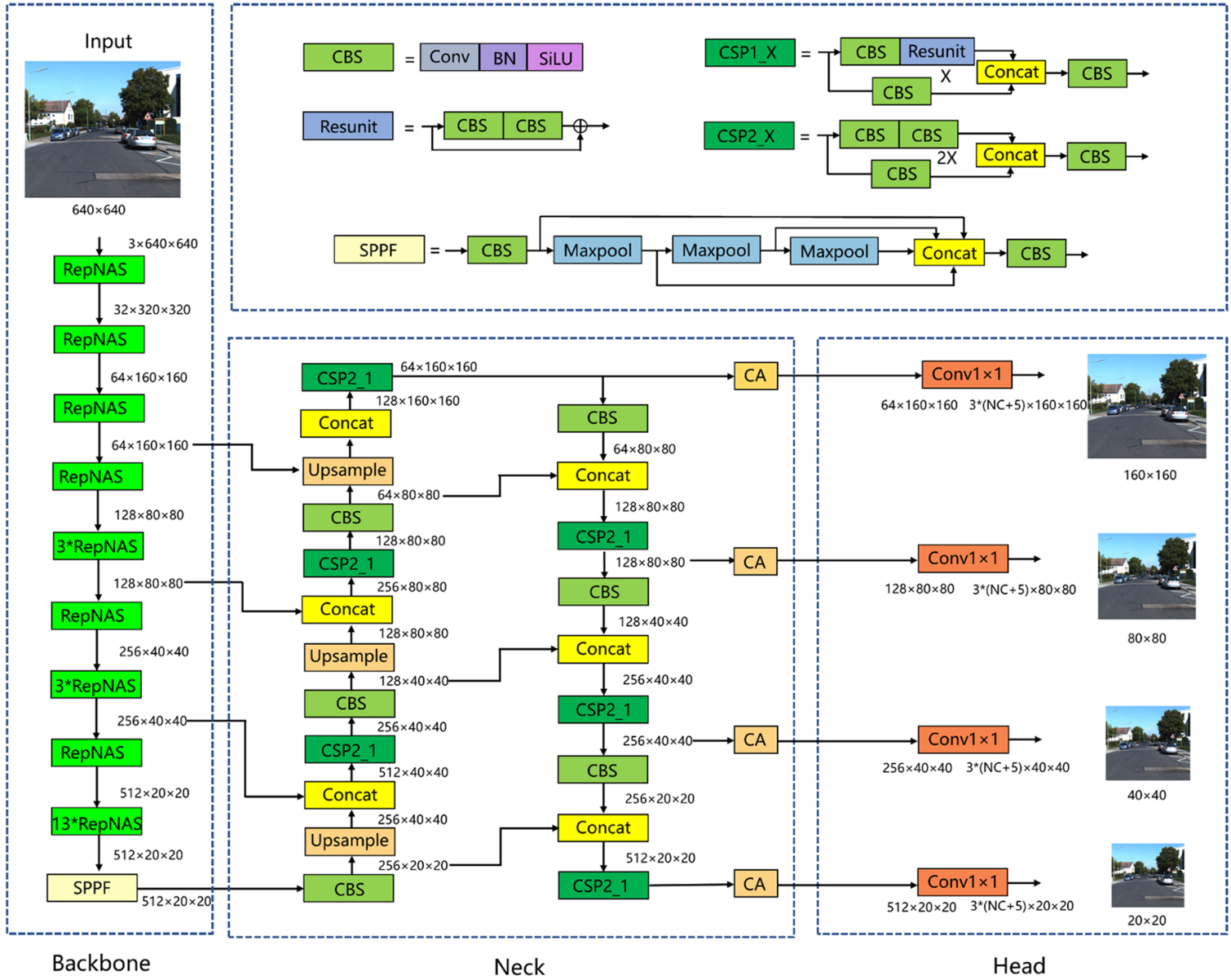
结构重参数化
结构重参数化 是一种利用训练-推理解耦的方法,使模型在训练阶段具有较高的精度,在推理阶段具有较高的速度。具体地说,在训练阶段首先构建多分支结构,训练后将多分支结构融合成单向结构进行模型推理和部署 。在当今实际的自动驾驶场景中,推理模型往往部署在边缘AI芯片上,并在边缘设备上实时检测捕获的画面。因此,模型需要在保证精度的前提下具有较快的推理速度,而结构再参数化可以很好地满足这一条件。结构重新参数化由以下基本融合模块组成:
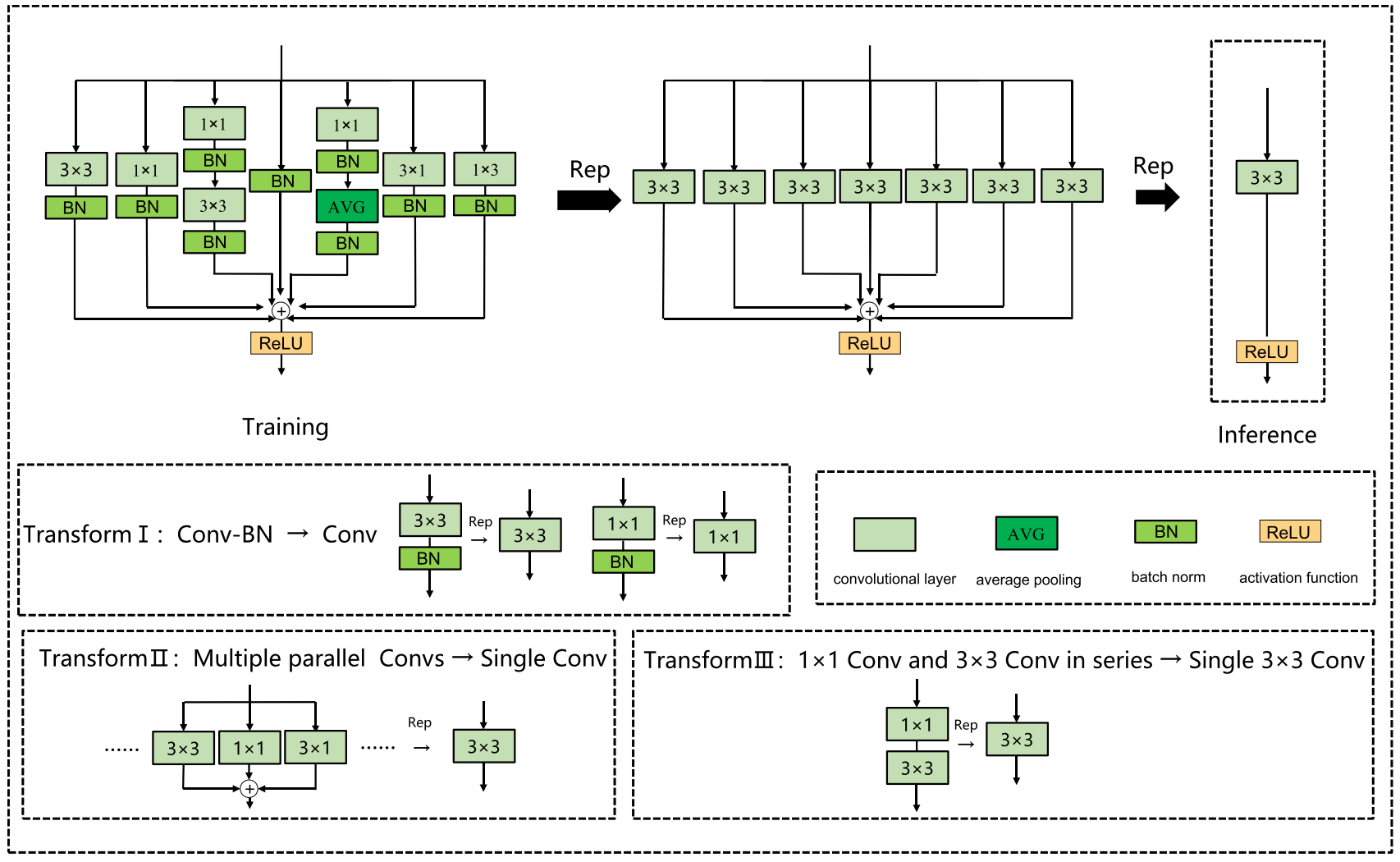
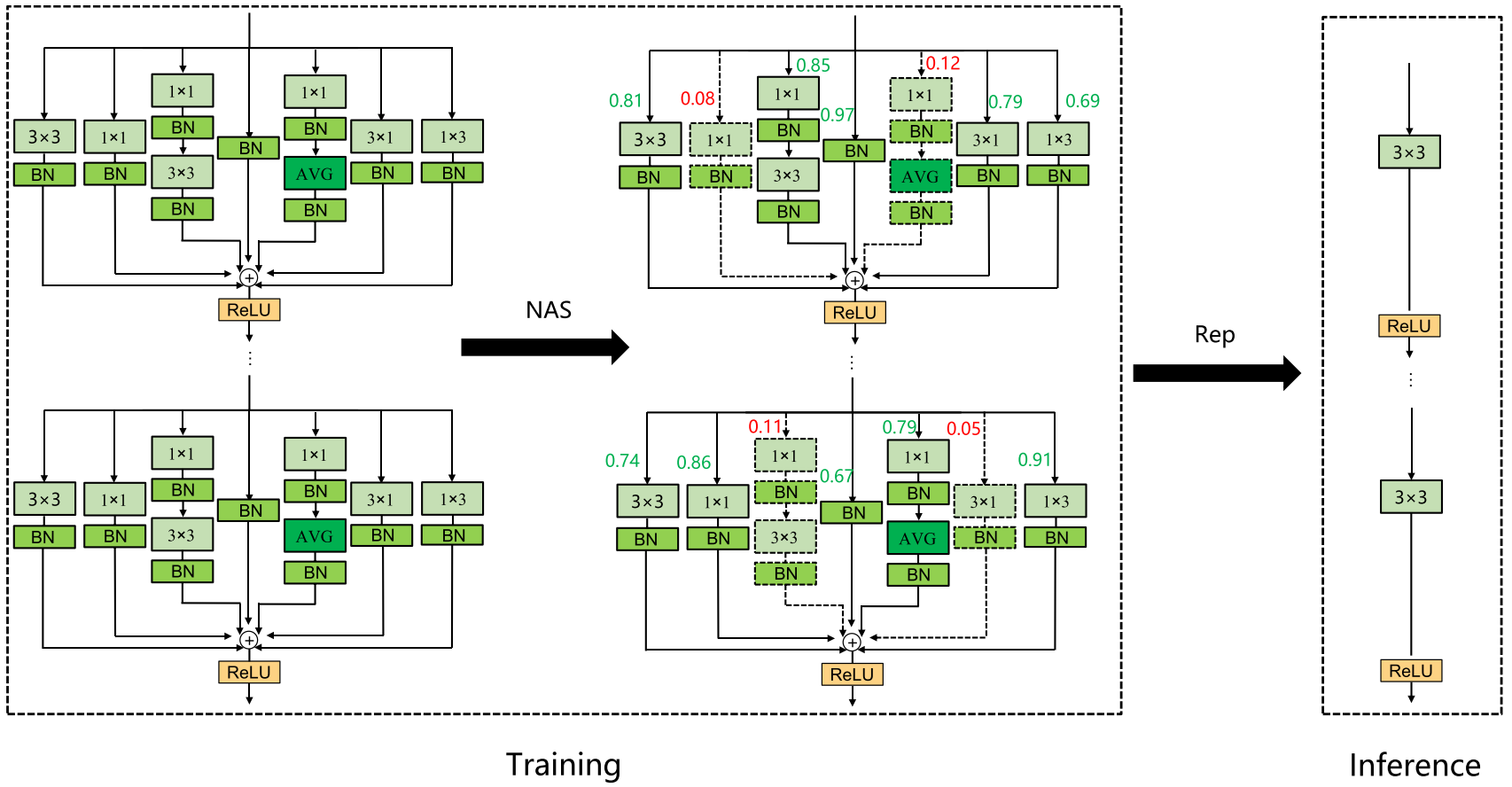
神经架构搜索(NAS)
神经结构搜索是当前计算机视觉领域的一个研究热点,它利用强化学习、进化算法、梯度方法等策略自动搜索网络的最优结构。受Zhang等人的启发25,本文将NAS技术与结构重参数化模块相结合,设计了RepNAS模块,如图所示。RepNAS通过判断多个分支中不同分支的重要性来自动裁剪一些冗余分支,从而达到减少模型训练时间和内存,提高模型精度的效果 。
小目标检测层
YOLOv5网络的探测头共包含三个检测层,规模分别为80×80、40×40、20×20。其中,80×80检测层的每平方面积最小,位置信息更准确,更适合检测小目标。同样,40×40的检测层适合检测中等物体,而20×20的检测层更适合检测大型物体。在车辆检测或行人检测中,许多目标只占原始图像的一小部分。为了提高小目标检测算法的检测精度,我们增加了一个160×160的检测层,用于对较小的车辆或行人进行精确定位和识别。
协调注意力机制(CA)
针对输入图像中某些车辆和行人所占比例较小,导致识别精度不高的问题,引入了协调注意机制 。它可以将水平和垂直位置信息编码到通道注意机制中,使网络能够更好地聚焦目标位置信息 。经典的SE注意机制只考虑通道之间的信息,而忽略位置信息。CBAM改进了SE,在减少特征地图通道的数量后使用卷积来提取位置注意信息。然而,卷积只能提取本地关系,很难关注远程信息。CA能够将水平和垂直位置信息编码为通道注意力,并同时捕获通道间信息和与方向相关的位置信息。它可以提高模型感知目标位置的能力,从而实现对汽车和行人的更准确的定位和识别。
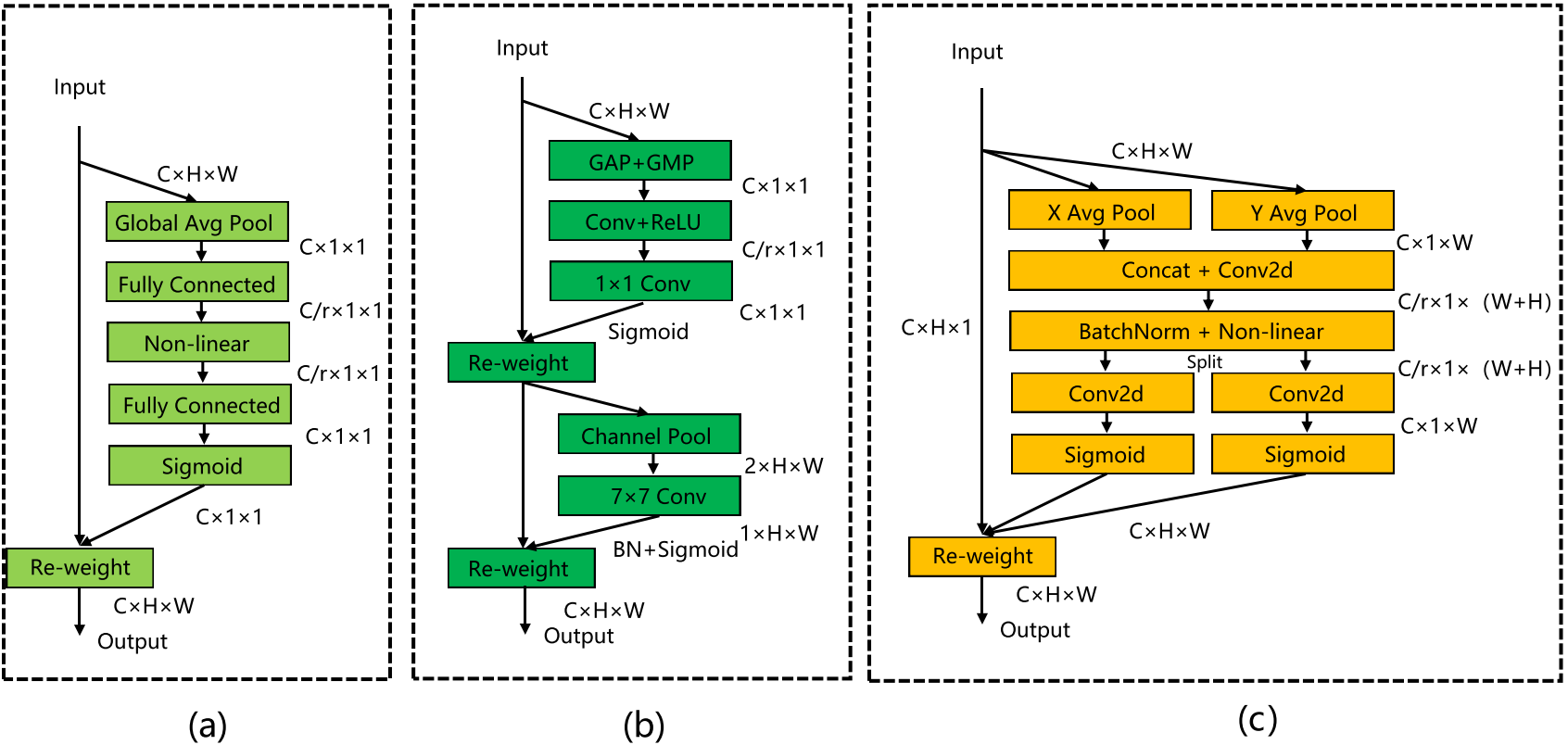
(a)SE;(b)CBAM;(c)CA
实验及结果分析
实验数据集
在自动驾驶领域应用最广泛的KITTI数据集 上进行了实验。KITTI训练集由7481张图像标记,包括农村、城市和高速公路等道路场景。每幅图像最多有15辆车,目标有不同程度的遮挡和截断。数据集共包含8个类别:轿车、货车、卡车、有轨电车、行人、人(坐)、骑自行车和其他。其中,将人合并为行人类别,另外选择轿车、货车、卡车和自行车手,取出五类对象进行训练和测试。
实验环境
实验环境是Ubuntu 21.04,Pytorch 1.8.0,第11代CPU英特尔®酷睿™i5-11,400@2.60 GHz,GPU型号NVIDIA GeForce RTX 3070,内存16G,CUDA 11.2,CUDNN 7.6,Python3.8。初始学习率为0.01,使用余弦退火法衰变,最终学习率为0.001,epoch设置为300时,批次大小设置为8。
评价指标
Precision、Recall、mAP、FPS
实验结果
消融实验
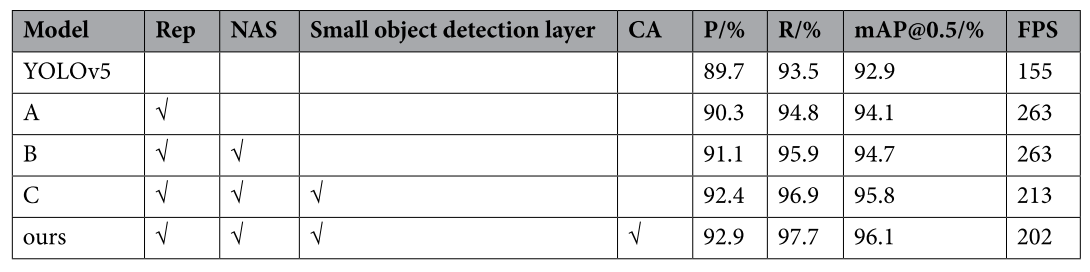
为了考察在重参数化模块中增加不同分支对模型的影响,以及不同分支组合下NAS的效果,进行了相关实验
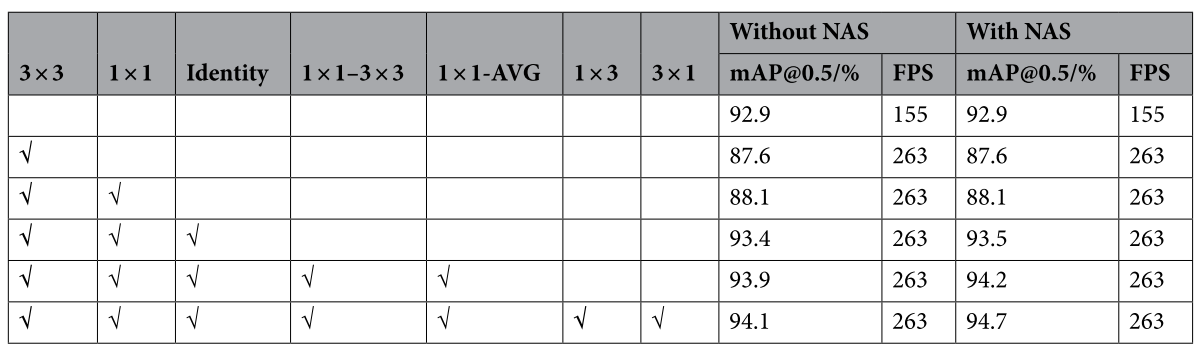
不同注意力机制
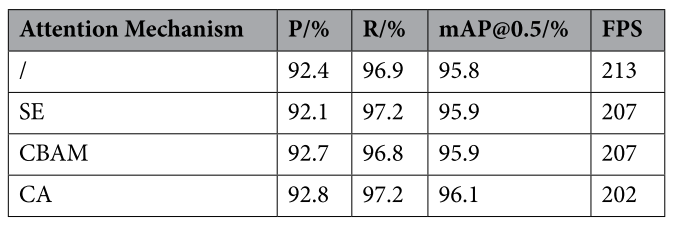
对比实验
检测结果(左边:YOLOv5;右边:改进的YOLOv5)
