前言
你有没有过这样的经历:在听一段AI生成的有声书时,哪怕音色再好听,几分钟后也开始感到一种难以言说的乏味和"假"?那种平铺直叙、毫无波澜的语调,仿佛一个没有灵魂的报幕员。又或者,你是一个播客主理人,幻想着能将精彩的文字脚本,直接变成一场嘉宾云集、讨论热烈的节目,却苦于录制的繁琐和高昂的成本。

长期以来,这就是文本转语音(TTS)技术留给我们的印象------它能"读",但不会"说"。
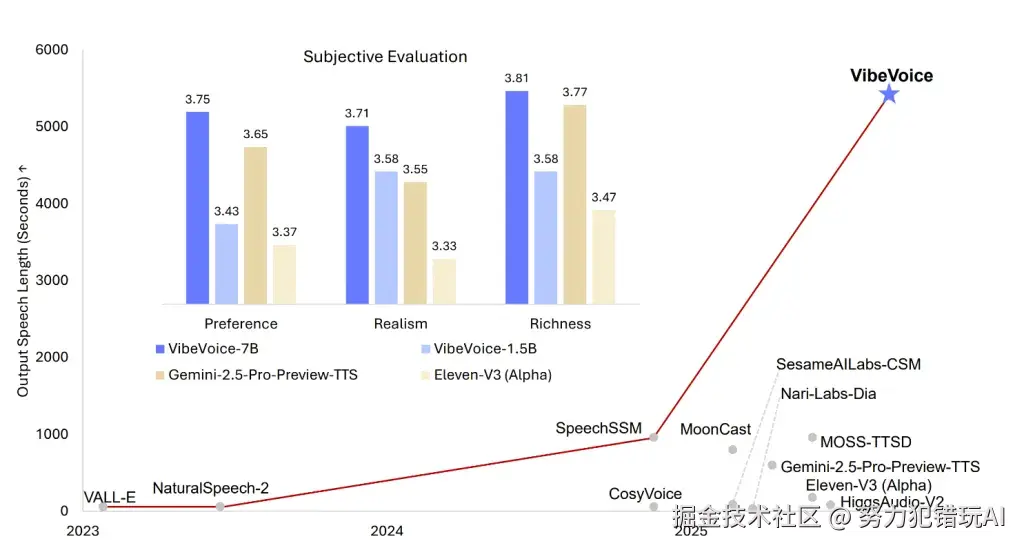
现在,微软研究院扔出了一颗重磅炸弹,名为VibeVoice。它不是对现有技术的修修补补,而是一次彻底的范式颠覆。想象一下,你给它一段长达90分钟的剧本,里面有四个角色,它能为你生成一段听起来就像真人录制的、情感自然、互动流畅的完整音频。
这,就是VibeVoice带来的未来。而且,微软选择将它完全开源。
VibeVoice 相关链接:
- 技术报告链接:arxiv.org/abs/2508.19...
- GitHub :github.com/microsoft/V...
- 在线体验地址 :vibevoice.info/
- AI快站模型下载:aifasthub.com/microsoft/V...
它凭什么能"聊"上90分钟而不"翻车"?
传统TTS之所以处理不了长篇大论,是因为它们像个记性很差的演员,念着念着就忘了自己最初的声线和情绪,导致声音"漂移",前后不一。而VibeVoice之所以能成为"耐力型选手",其秘诀在于一套全新的、堪称巧妙的架构。
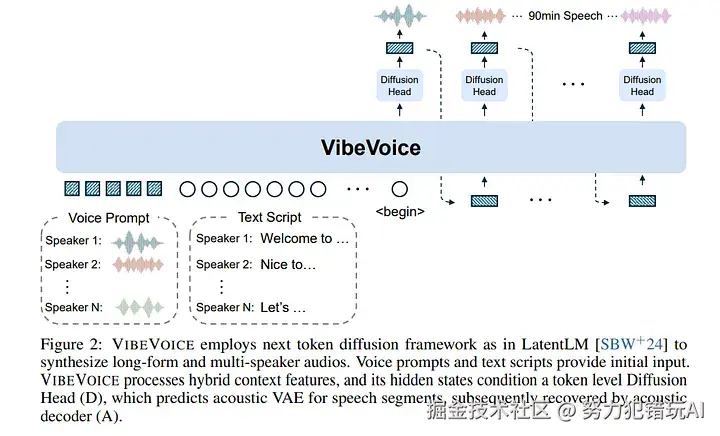
我们可以把它想象成一个顶级的电影制作团队,分工明确:
- "剧本分析师"与"声音指导"的双重准备
在开拍前,团队首先要同时吃透剧本和角色的声音。VibeVoice创新地设计了"双令牌器"来完成这一步。
- 语义令牌器(剧本分析师):它不只是看文字的表面意思,而是深度分析文本的上下文、逻辑和情感。它要搞清楚,这句话是疑问、是感慨,还是在讲一个冷笑话。
- 声学令牌器(声音指导):它不关心文字内容,只专注于"声音"本身。它通过一种叫做残差矢量量化(RVQ)的技术,将真实的人类语音分解并编码成包含了音色、节奏、韵律等核心要素的"声音基因片段"。
这一步是VibeVoice的根基。它让模型在开始生成之前,就同时掌握了"要说什么内容"和"该用什么声音去说"。
- "总导演"------掌控全局的大型语言模型
准备工作就绪后,就轮到剧组的灵魂人物------"总导演"登场了。VibeVoice的"总导演"是一个拥有15亿参数的大型语言模型(基于Qwen2.5-1.5B)。
它的工作,不是像传统模型那样简单地把文字变成声音,而是在脑海中"预演"整场对话。它看着由"剧本分析师"和"声音指导"准备好的令牌序列,以一种自回归的方式,一个令牌接一个令牌地往下预测。
这个过程的精妙之处在于,它预测的是一个"内容"与"声音"交织在一起的序列。当剧本里出现<|speaker1|>的标记时,这位"导演"会立刻心领神会:"好了,现在切换到1号演员的声音风格",并调取对应的"声音基因片段"。正因如此,VibeVoice才能在长达90分钟的对话中,让每个角色的声音始终保持稳定,并实现天衣无缝的自然切换。
- "声音艺术家"------从无到有的声音雕琢
"导演"预演完毕,输出了完整的"声学蓝图"(即声学令牌序列)。最后一步,就是将这份蓝图变为我们能听到的声音。
这项任务交给了团队里的"声音艺术家"------一个基于扩散模型(Diffusion Model)的声码器。
它的工作方式极富艺术感:想象一间寂静无声的房间,艺术家从一团随机的白噪音开始,手握"声学蓝투",一点点地从中"雕刻"出声音的细节。他不断去除噪声,让声音的轮廓逐渐清晰、饱满,直至最终呈现出一段极其逼真、清澈的音频。这种从无到有的生成方式,使得VibeVoice的音质远超传统TTS,几乎听不到任何恼人的电流声或机械感。
这不仅仅是技术,这是内容创作的全新"引擎"
VibeVoice的出现,其意义远不止于一个有趣的AI玩具。它正在成为赋能内容创作的强大引擎:
- 播客与有声书的"一键生成":独立创作者和出版行业,可以将制作周期从数周压缩到数小时,极大地解放生产力。
- 游戏的灵魂注入:游戏开发者可以为成百上千的NPC赋予独一无二、对话自然的嗓音,构建一个前所未有的沉浸式世界。
- 无障碍体验的革命:为视障人士提供的屏幕朗读工具,将不再是冰冷的机器音,而是有温度、有情感的陪伴。
冷静思考:前路漫漫,责任在肩
当然,VibeVoice并非完美。目前它主要针对英语和中文进行了优化,还无法生成背景音乐,也处理不了多人抢话的复杂场景。
更重要的是,微软深知这项技术的潜力与风险。他们在开源的同时,也划定了明确的"红线":严禁利用VibeVoice进行声音冒充、诈骗或传播虚假信息。技术的使用者,必须肩负起相应的道德责任,在生成内容时做出清晰的AI标识。
结语
VibeVoice为我们打开了一扇窗。透过它,我们看到的不再是那个磕磕巴巴学人说话的AI,而是一个初具雏形的"声音叙事大师"。它标志着一个时代的开启:在这个时代里,高质量的音频内容创作将不再是少数人的专利,而创意与思想,将能以更生动、更直接的方式,触达每一个人的耳朵。
VibeVoice 相关链接:
- 技术报告链接:arxiv.org/abs/2508.19...
- GitHub :github.com/microsoft/V...
- 在线体验地址 :vibevoice.info/
- AI快站模型下载:aifasthub.com/microsoft/V...