Seaborn数据可视化实战:从数据到图表的完整旅程
学习目标
通过本课程的学习,你将能够掌握使用Seaborn进行数据可视化的完整流程,从数据准备到图表设计,再到最终的图表呈现。本课程将通过一个具体的项目案例,帮助你全面提升数据可视化的能力。
相关知识点
Seaborn数据可视化实战
学习内容
1 Seaborn数据可视化实战
1.1 数据准备与处理
在数据可视化的过程中,环境准备与数据处理是至关重要的第一步。良好的数据准备可以确保后续的图表设计更加顺利,同时也能提高图表的准确性和可读性。本节将介绍如何使用Pandas进行数据的加载、清洗和预处理,为Seaborn图表的绘制打下坚实的基础。
- 安装必要的库
python
%pip install seaborn- 获取数据集
python
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/4f5446b230a511f0a22bfa163edcddae/data.csv --no-check-certificate-
数据加载
首先,我们需要加载数据。Python中常用的库Pandas提供了强大的数据处理功能,可以轻松地从多种数据源加载数据。例如,从CSV文件加载数据可以使用
pandas.read_csv()函数。
python
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
# 查看数据的前5行
print(data.head())-
数据清洗
数据清洗是数据准备的重要环节,包括处理缺失值、异常值和重复值等。Pandas提供了多种方法来处理这些问题。
python
# 检查缺失值
print(data.isnull().sum())
# 填充缺失值
data.fillna(0, inplace=True)
# 删除重复值
data.drop_duplicates(inplace=True)-
数据预处理
数据预处理包括数据的转换和标准化,以确保数据适合进行可视化。例如,可以将分类数据转换为数值数据,或者对数值数据进行标准化处理。
python
# 将分类数据转换为数值数据
data['Species'] = data['Species'].map({'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2})
# 对数值数据进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']] = scaler.fit_transform(data[['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']])1.2 Seaborn图表设计
Seaborn是一个基于Matplotlib的高级数据可视化库,它提供了许多高级图表类型和美观的默认样式。本课程将介绍如何使用Seaborn绘制各种图表,包括散点图、折线图、柱状图和热力图等。
- 散点图
散点图用于展示两个变量之间的关系。Seaborn的scatterplot函数可以轻松绘制散点图。
python
import seaborn as sns
import matplotlib.pyplot as plt
# 绘制散点图
sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm', data=data, hue='Species')
plt.title('Scatter Plot of Sepal Length and Width for Different Iris Species ')
plt.xlabel('SepalLengthCm')
plt.ylabel('SepalWidthCm')
plt.tight_layout() # 自动调整布局
plt.show()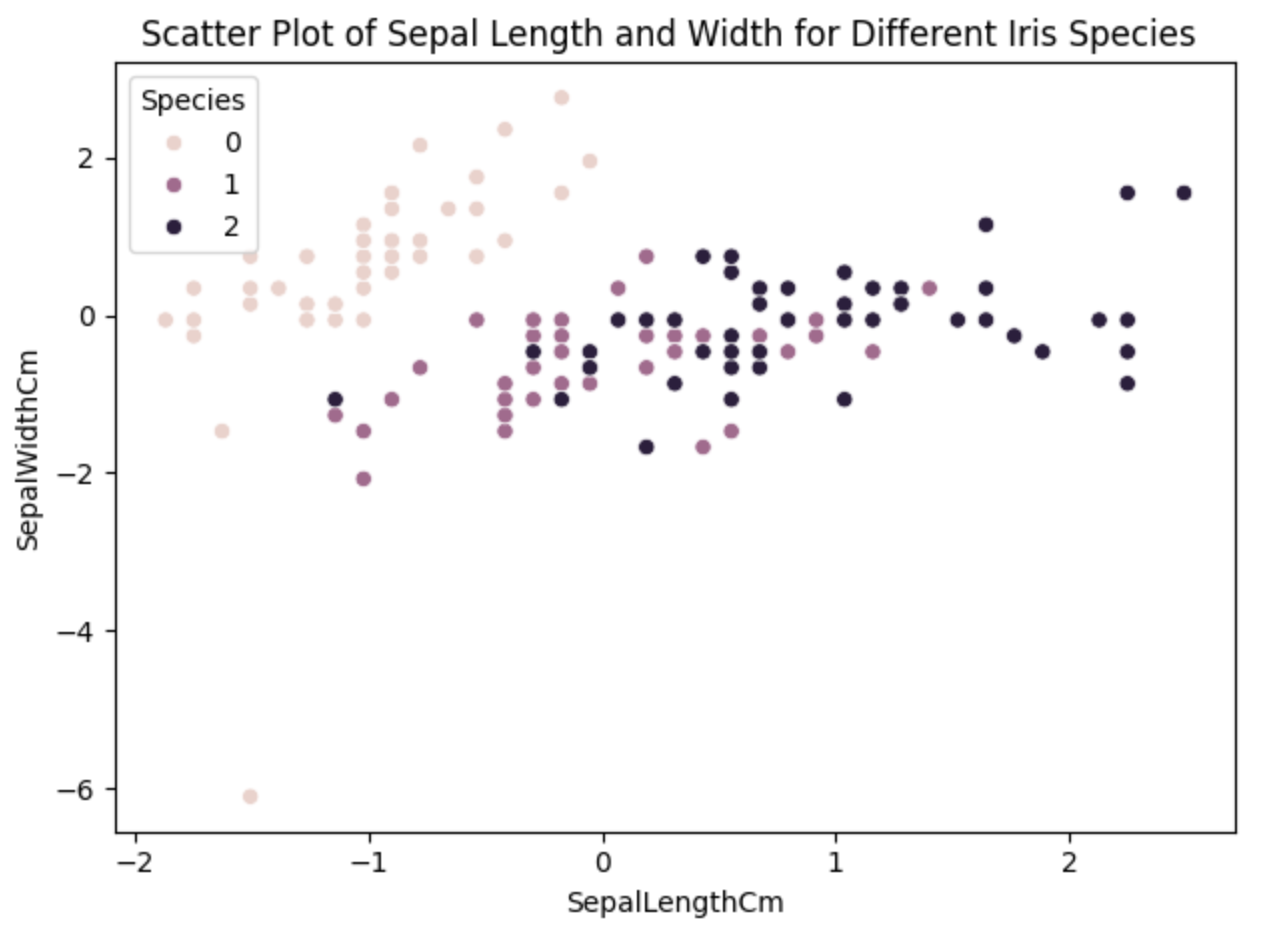
-
折线图
折线图用于展示数据随时间的变化趋势。Seaborn的
lineplot函数可以绘制折线图。
python
# 绘制折线图
sns.lineplot(x='SepalLengthCm', y='SepalWidthCm', data=data, hue='Species')
plt.title('The relationship between petal length and sepal width in Iris flowers')
plt.xlabel('SepalLengthCm')
plt.ylabel('SepalWidthCm')
plt.show()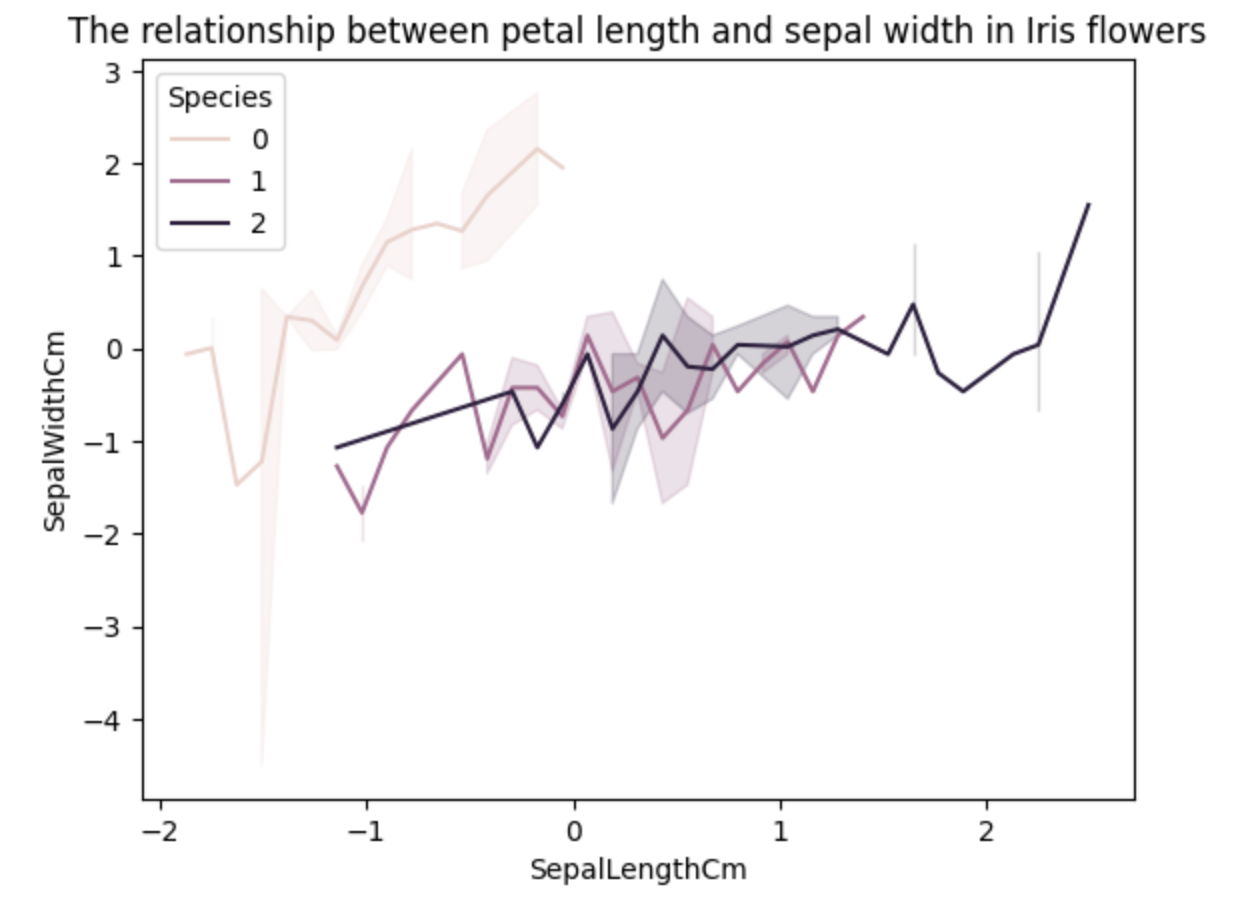
-
柱状图
柱状图用于展示分类数据的分布情况。Seaborn的
barplot函数可以绘制柱状图。
python
# 绘制柱状图
sns.barplot(x='Species', y='SepalLengthCm', data=data, hue='Species')
plt.title('Sepal Length by Iris Species')
plt.xlabel('Species')
plt.ylabel('SepalLengthCm')
plt.show()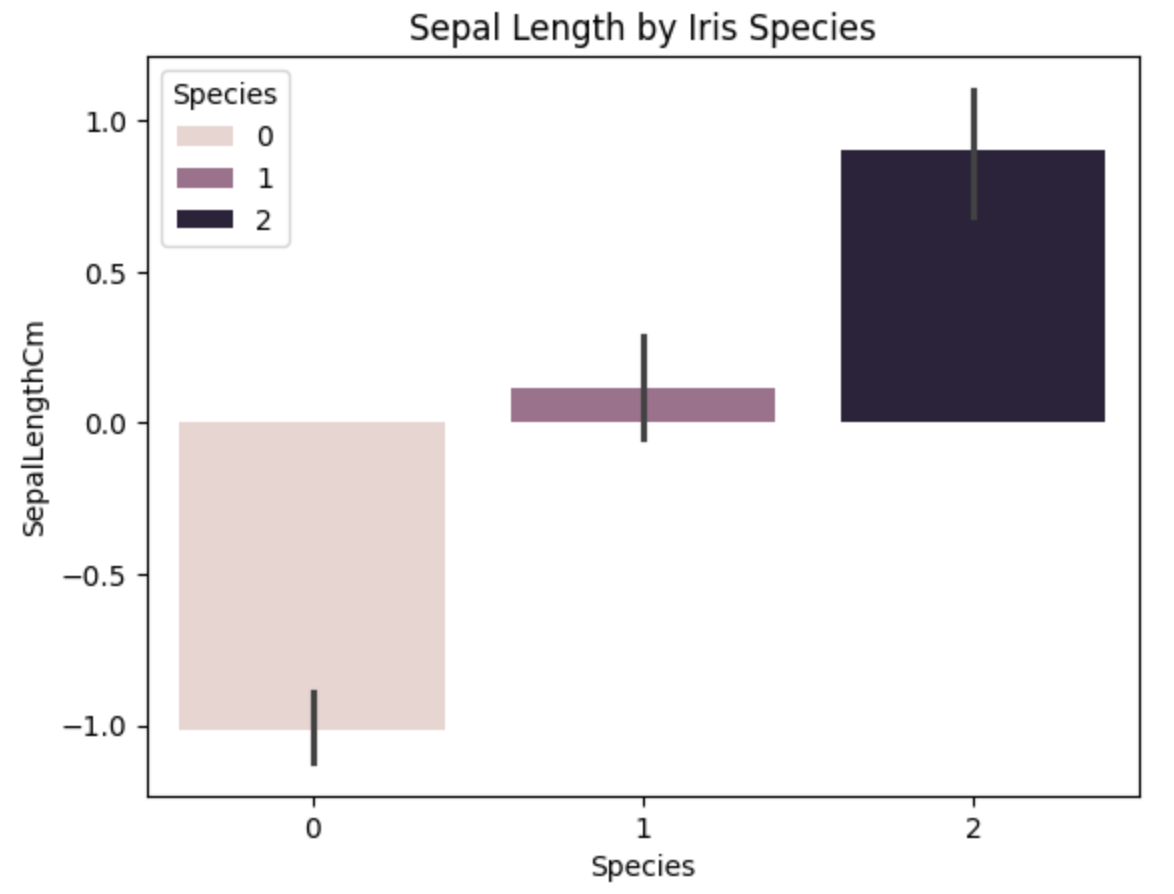
-
热力图
热力图用于展示数据矩阵中的值。Seaborn的
heatmap函数可以绘制热力图。
python
# 绘制热力图
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Heatmap of Correlation Matrix')
plt.show()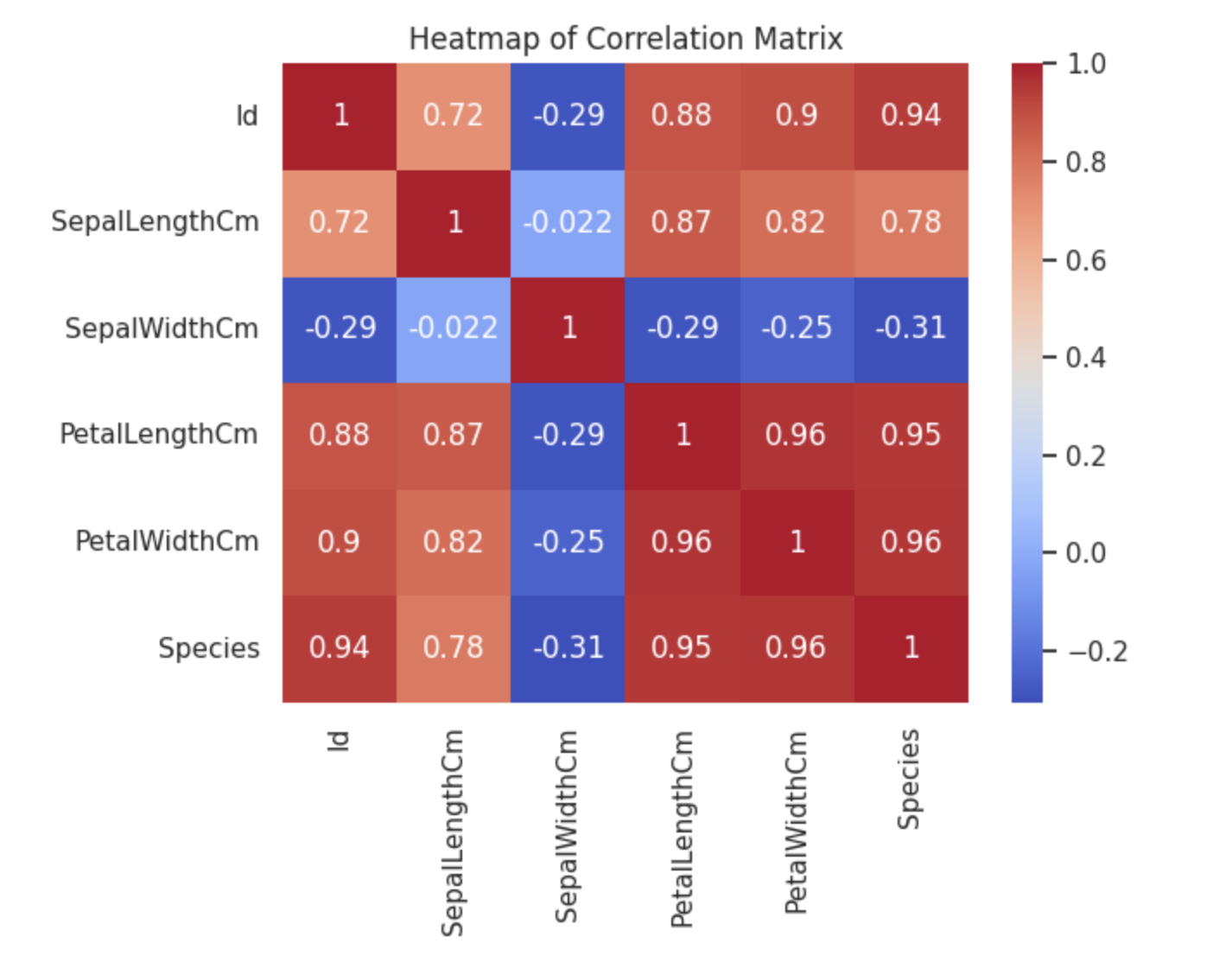
1.3 图表优化与呈现
图表的优化和呈现是数据可视化的重要环节,可以提升图表的美观性和可读性。本课程将介绍如何使用Seaborn和Matplotlib进行图表的优化,包括调整图表样式、添加注释和保存图表等。
- 调整图表样式
Seaborn提供了多种样式设置,可以调整图表的背景、颜色和字体等。
python
# 设置Seaborn样式
sns.set(style="white")
# 浅蓝色背景
plt.figure(facecolor='lightblue')
# 绘制柱状图
ax = sns.barplot(x='Species', y='SepalLengthCm', data=data, color="#F8B195")
# 设置标题和轴标签的字体样式
plt.title('Sepal Length Distribution by Iris Species', fontsize=16, fontweight='bold')
plt.xlabel('Species', fontsize=14)
plt.ylabel('SepalLengthCm', fontsize=14)
# 调整刻度标签字体大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# 显示图表
plt.show()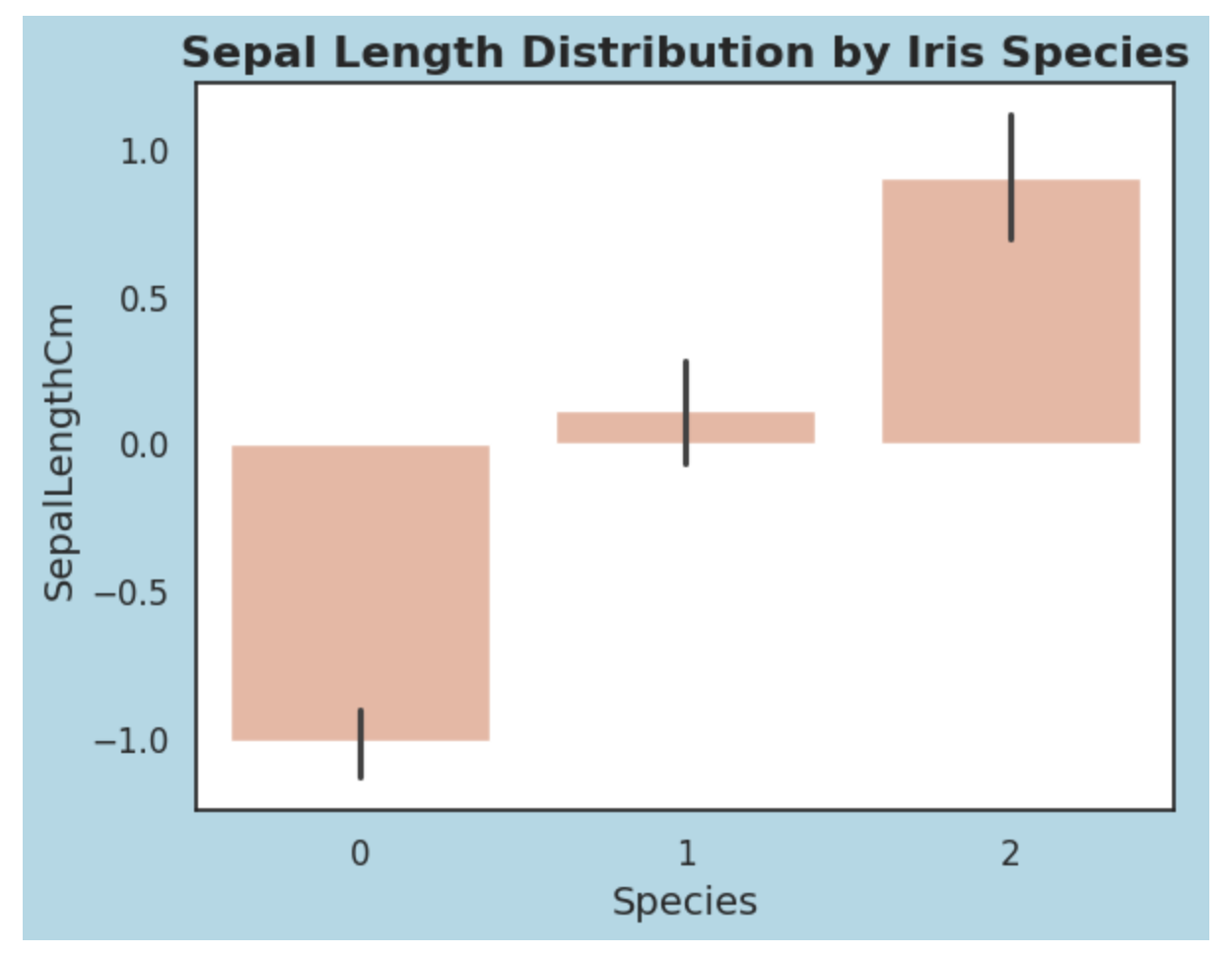
-
添加注释
在图表中添加注释可以提供更多的信息,帮助读者更好地理解图表。
python
# 绘制柱状图
sns.barplot(x='Species', y='SepalLengthCm', data=data)
plt.title('Bar Plot of SepalLengthCm by Species')
plt.xlabel('Species')
plt.ylabel('SepalLengthCm')
# 添加注释
for index, row in data.groupby('Species').mean().iterrows():
value = row['SepalLengthCm']
plt.text(index, value, f'{value:.2f}', ha='center', va='bottom')
# 显示图表
plt.show()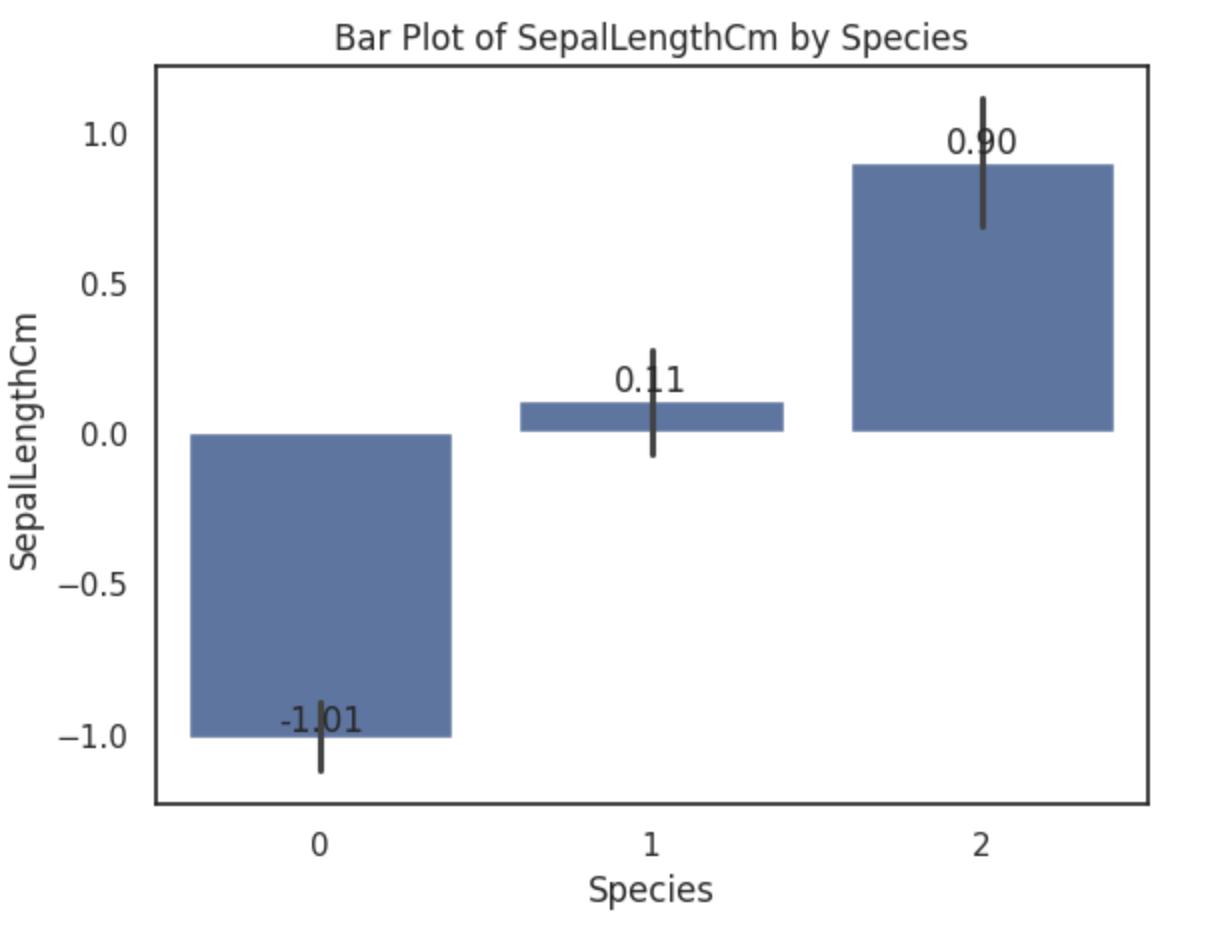
-
保存图表
将图表保存为文件可以方便地在报告或演示中使用。Matplotlib的
savefig函数可以将图表保存为多种格式。
python
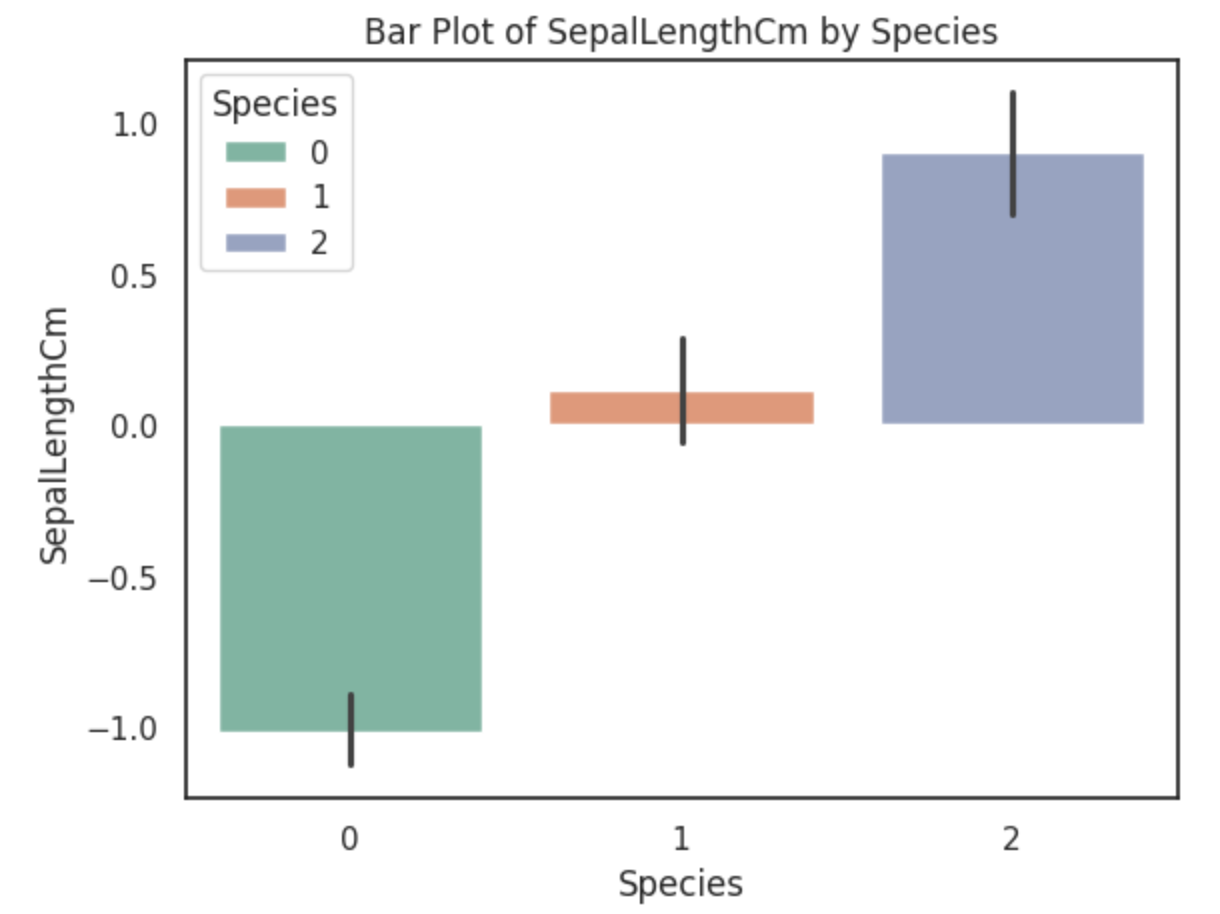
# 绘制柱状图
sns.barplot(x='Species', y='SepalLengthCm', data=data, palette="Set2", hue='Species')
plt.title('Bar Plot of SepalLengthCm by Species')
plt.xlabel('Species')
plt.ylabel('SepalLengthCm')
# 保存图表
plt.savefig('bar_plot.png')
plt.show()