想搭建知识库?Dify、MaxKB、Pandawiki 到底哪家强?

01 引言
2025年是AI的千禧年,全世界掀起了AI浪潮,AI真正的落地变成了企业最关心的问题。
企业里经历了培训、实践以及落地的一站式是实施,到目前来看,真正落地为企业带来收益或者方便的方案屈指可数(至少我们公司是这样)。真正开源的、可落地的当属搭建知识库、智能问答的方案。
本节也将从常用的工具或者开源框架里选择了三类:Dify、MaxKB、Pandawiki。单纯的从搭建知识库这一方面对比一下哪一款更适合?
02 知识库要求
为了测试三款软件搭建知识库的效果,小编打算使用《阿里巴巴Java开发手册》作为外挂知识库,并通过问答的方式,检索的结果怎么样?
知识库里面非常重要的就是文本内容向量化的处理,使用不同的向量化模型对于检索的结果会有直接影响。因为在测试中不同的软件内置的模型不一样,对输出结果有一定的影响。
03 Dify

3.1 简介
Dify是一款开源的大语言模型(LLM)应用开发平台。它融合了后端即服务(Backend as Service)和 [LLMOps](docs.dify.ai/zh-hans/lea...) 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的工作流,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
知识库只是 Dify 的一个功能模块,是它为这些AI应用提供"事实依据"和"背景知识"的工具。它的知识库是为增强AI应用的回答准确性服务的。
GitHub地址:github.com/langgenius/...
3.2 建立知识库
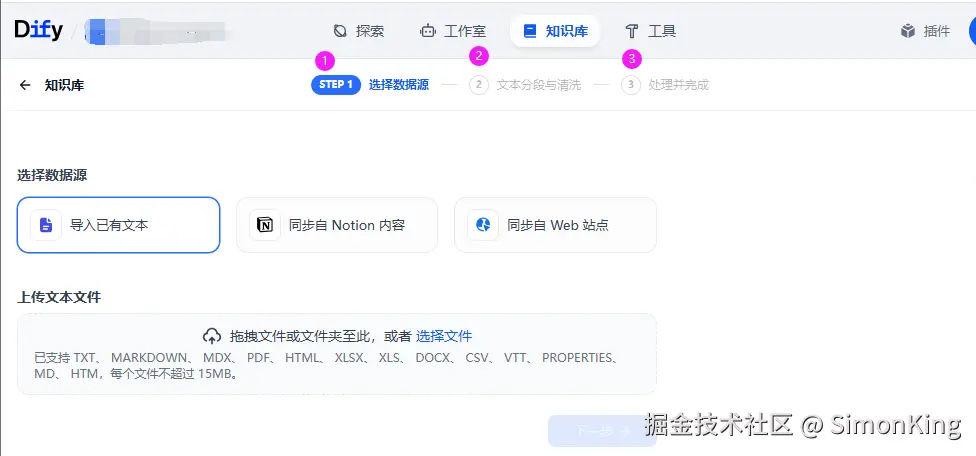
根据Dify工作空间的提示,我们需要导入文本、文本分段清洗最后处理完成。其中分段处理变的尤为重要。
文本分段
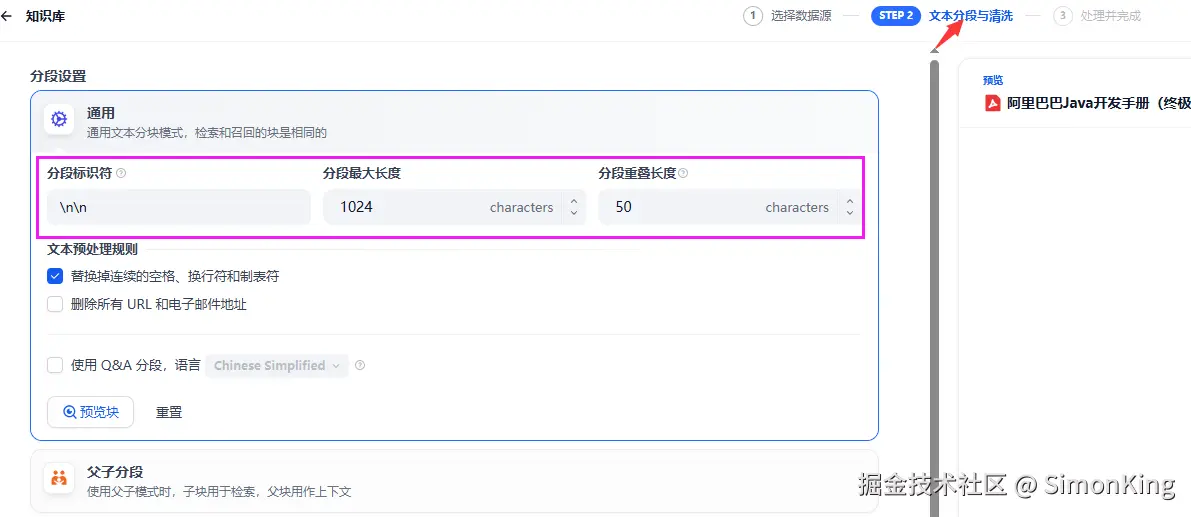
这里使用默认的分段模式
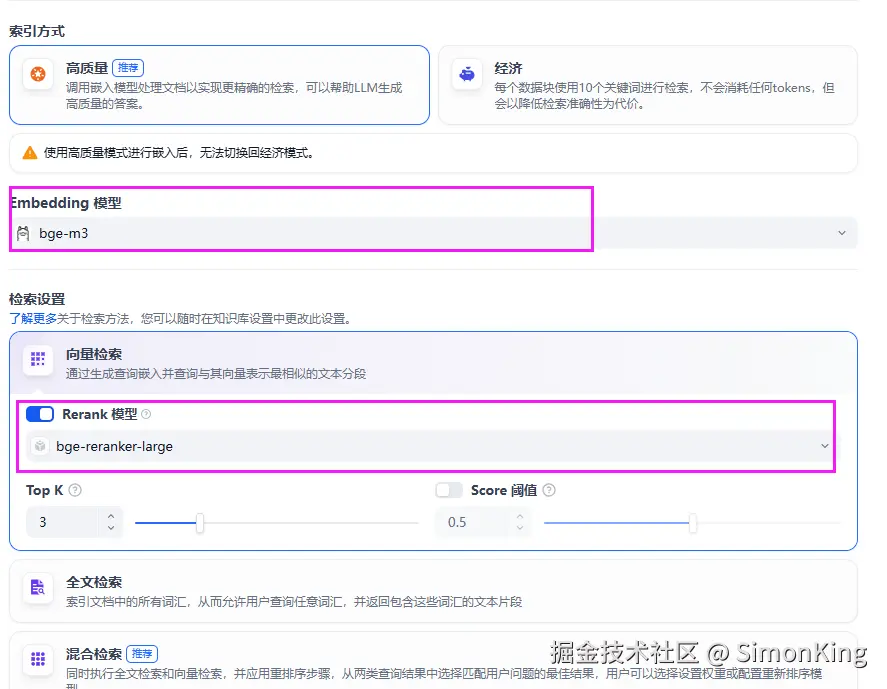
模型选择
等待结果
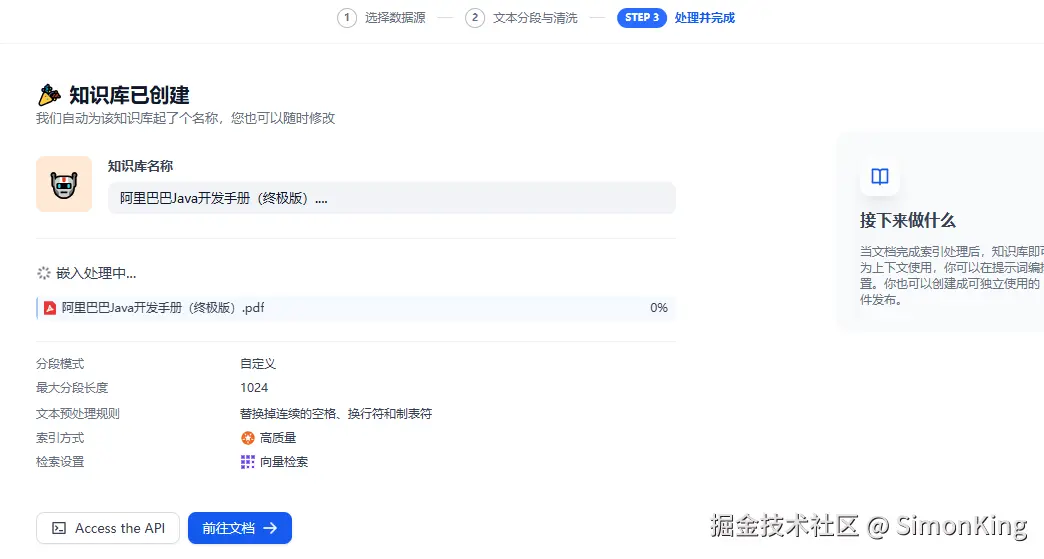
3.3 召回测试
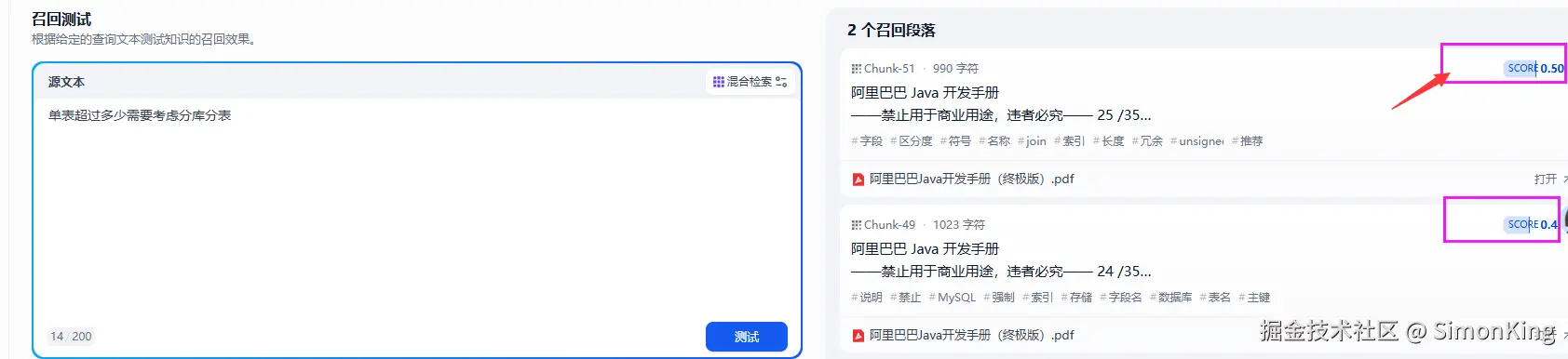
打开第一个查看会发现:
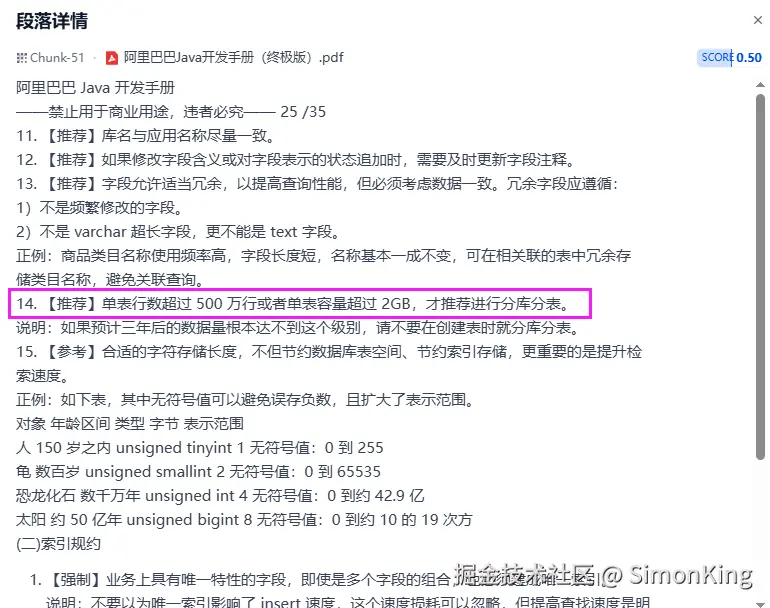
确实查到了,但是无关信息太多。这个和分段有一定的关系。
04 MaxKB

4.1 简介
MaxKB 是强大易用的开源企业级智能体平台,致力于解决企业 AI 落地面临的技术门槛高、部署成本高、迭代周期长等问题,助力企业在人工智能时代赢得先机。
基于docker的部署也很简单:
sh
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/opt/maxkb 1panel/maxkb搭建之后的登录信息:
GitHub地址:github.com/1Panel-dev/...
4.2 建立知识库
MaxKB内置了向量模型shibing624/text2vec-base-chinese,我们需要配置自己带模型。
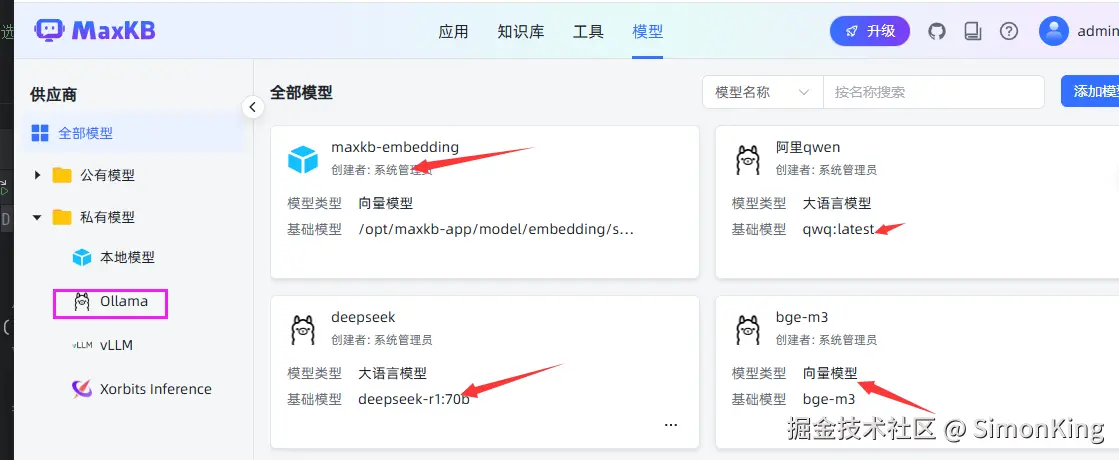
新建知识库
创建知识库的名字,以及上传文档。
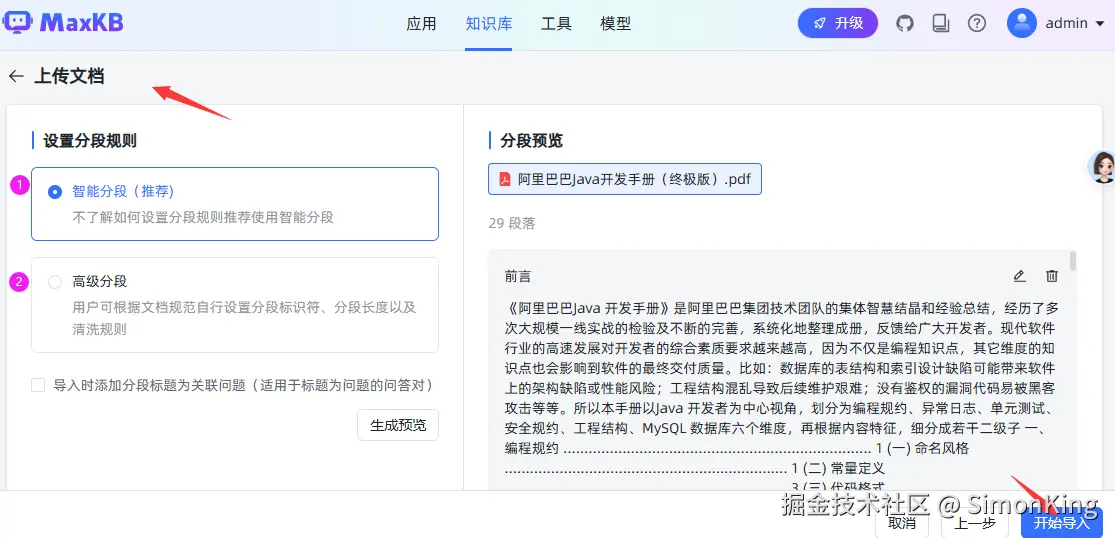
图中需要设置分段规则,这个是Dify有一定的相似之处。高级分段确实就是自定义分段标识,我们这里使用智能分段。
设置向量模型
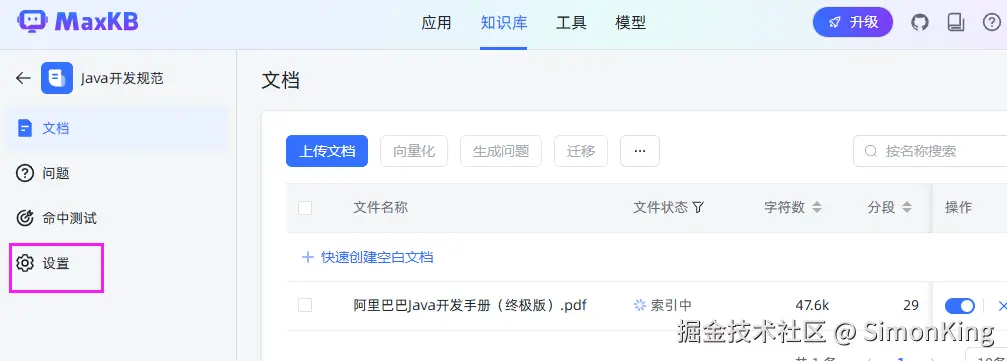
选择向量模型
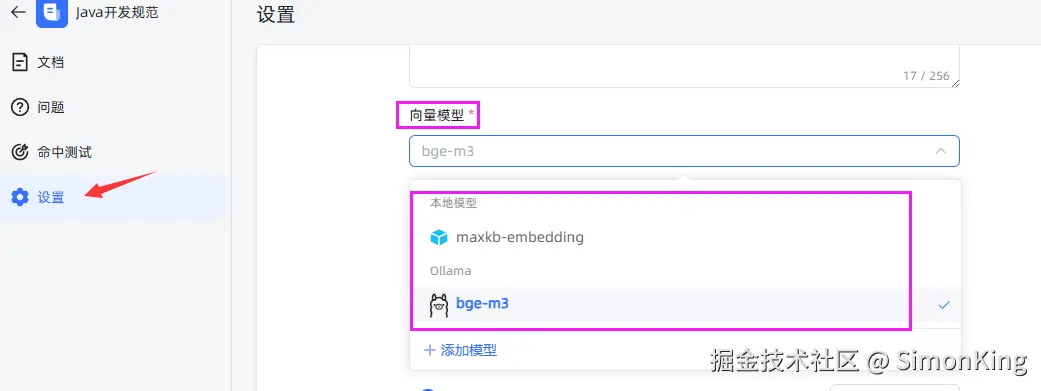
生成问题
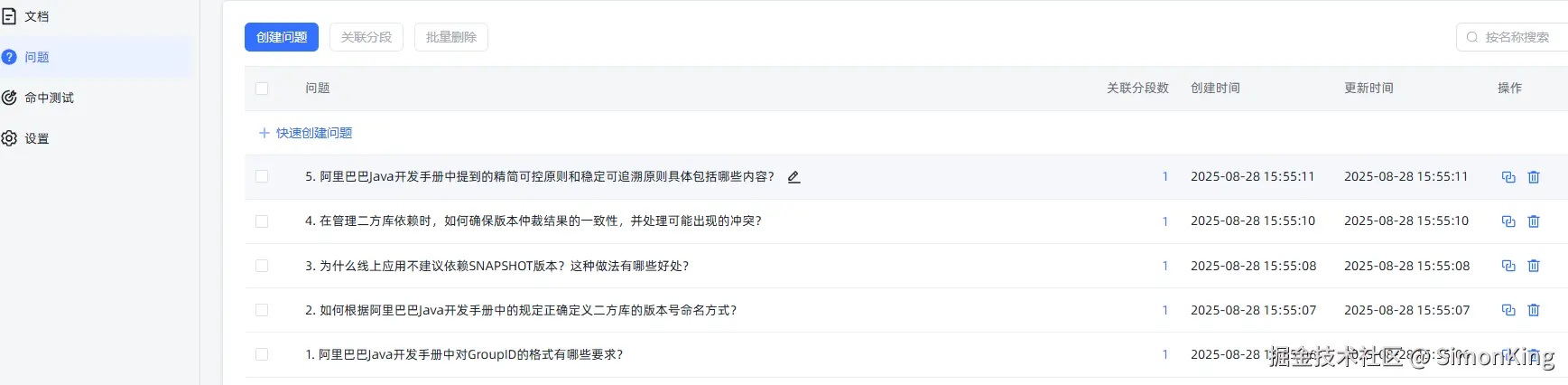
生成问题会自动关联分段,也可以通过创建问题手动关联分段
下面是自动是关联的分段:
4.3 召回测试
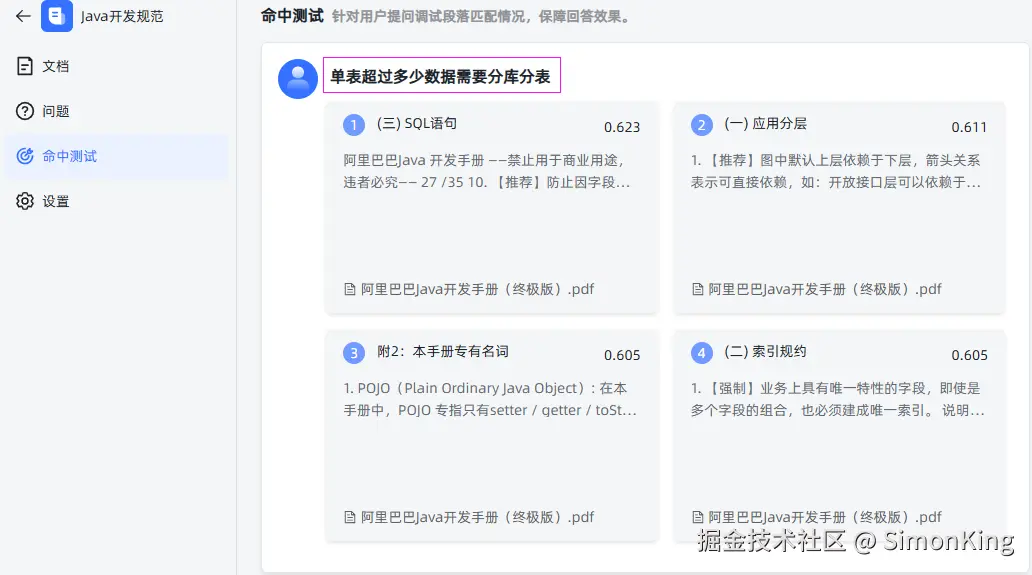
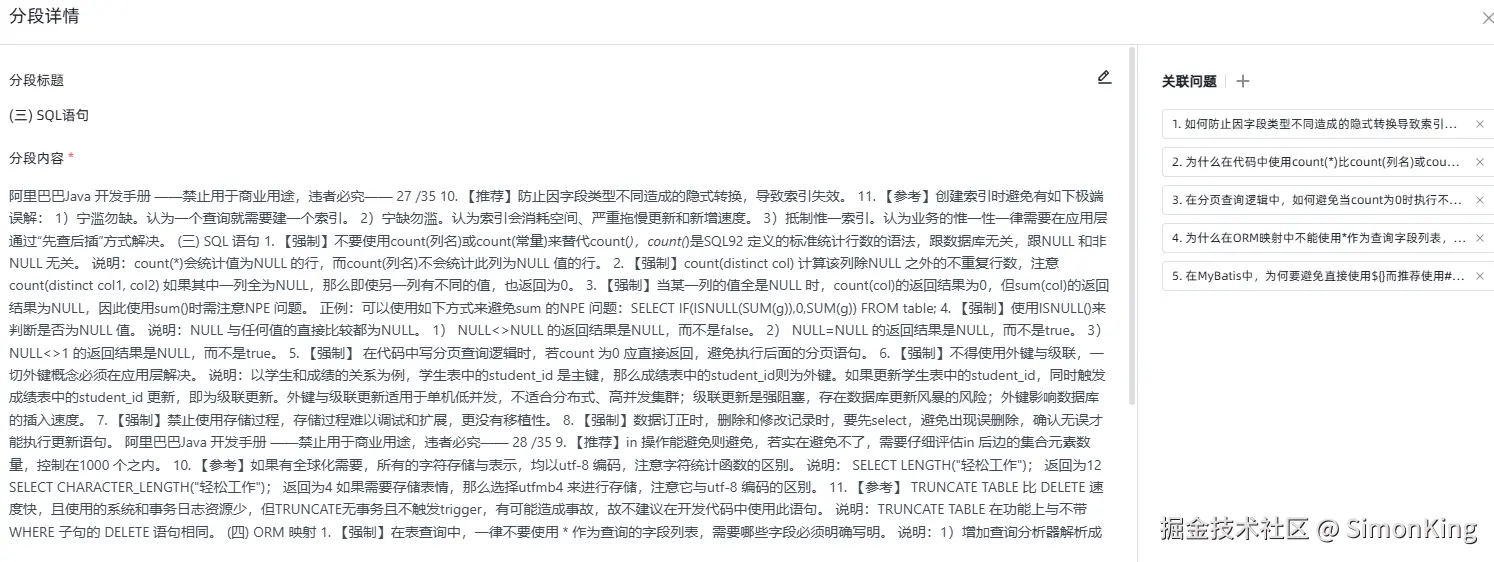
从结果来看,也是通过分段来召回的。回答的准确度取决分段的颗粒度。最优分段中并没有想要的结果。所以效果并不理想。
05 Pandawiki
5.1 简介
PandaWiki 是一款 AI 大模型驱动的开源知识库搭建系统,帮助你快速构建智能化的 产品文档、技术文档、FAQ、博客系统,借助大模型的力量为你提供 AI 创作、AI 问答、AI 搜索等能力。
基于Docker部署也是非常简单,一行命令就可以完成部署。
Github地址:github.com/chaitin/Pan...
文档地址:pandawiki.docs.baizhi.cloud/welcome
5.2 建立知识库
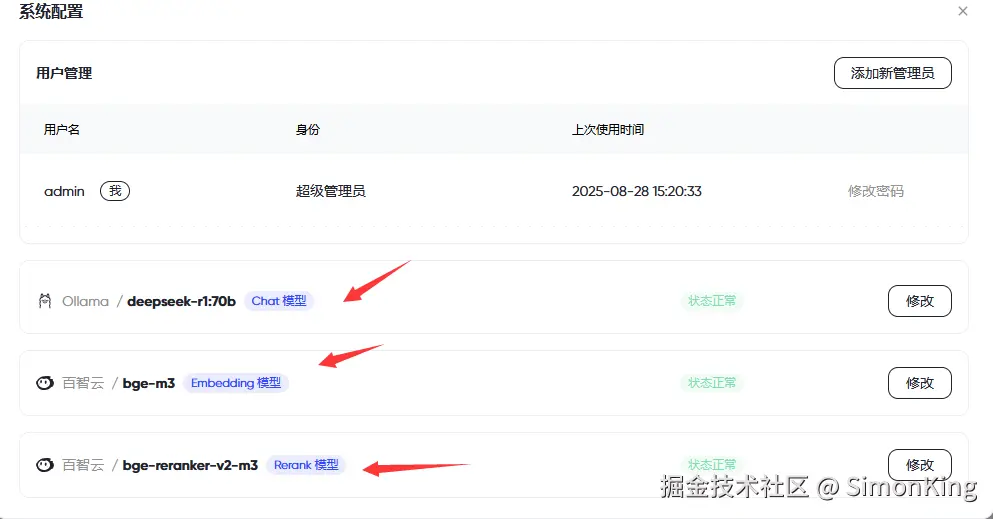
配置模型
创建Wiki以及上传文档并按照要求发布。
访问WIKI网站
直接点击右上角或者直接访问域名+端口
5.3 召回测试
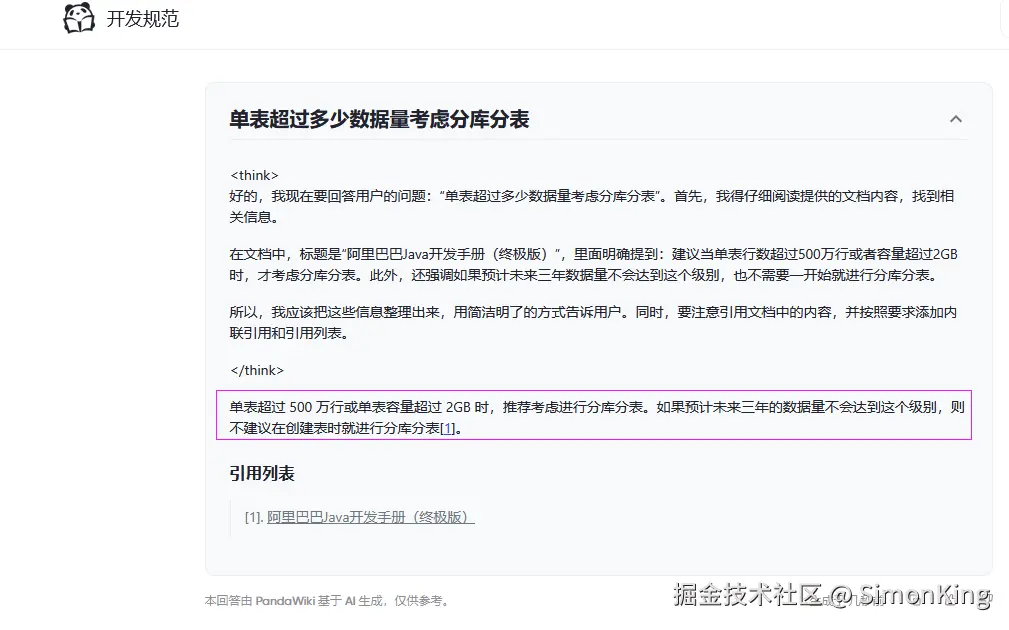
这样的结果深得我心,过滤无关的数据,看起来更简洁明了,简直就是小编理想的回答方式。
5.4 AI问答机器人

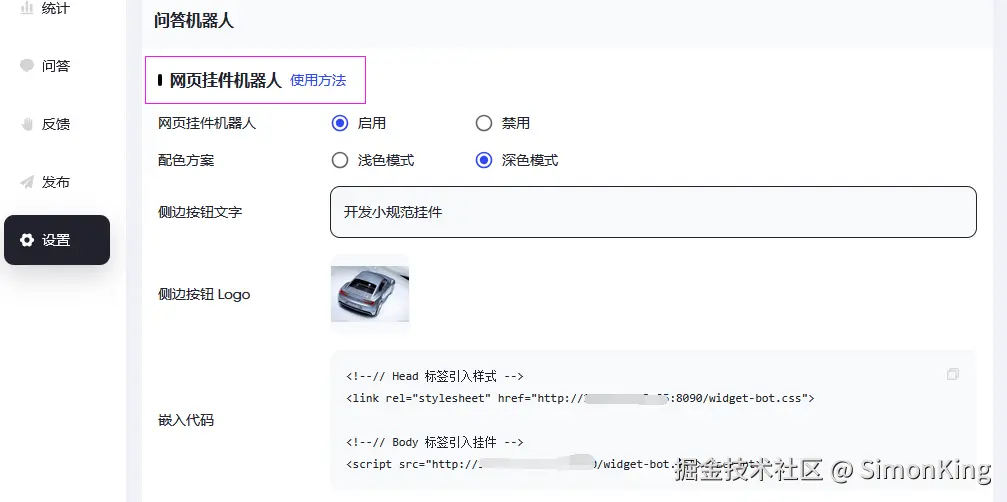
我们以网页挂件机器人为例。
配置
同样在配置里面启用网页挂件机器人。将生成的css和js要引入到页面即可。
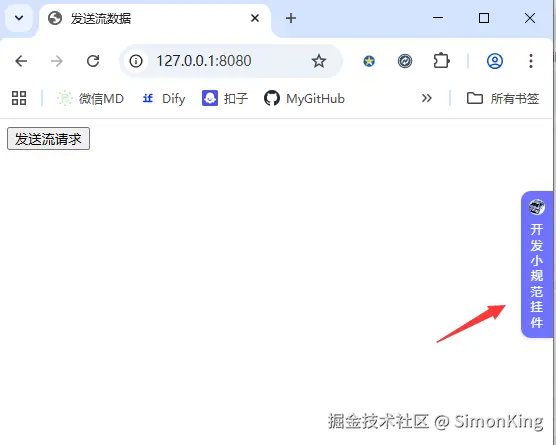
效果图:
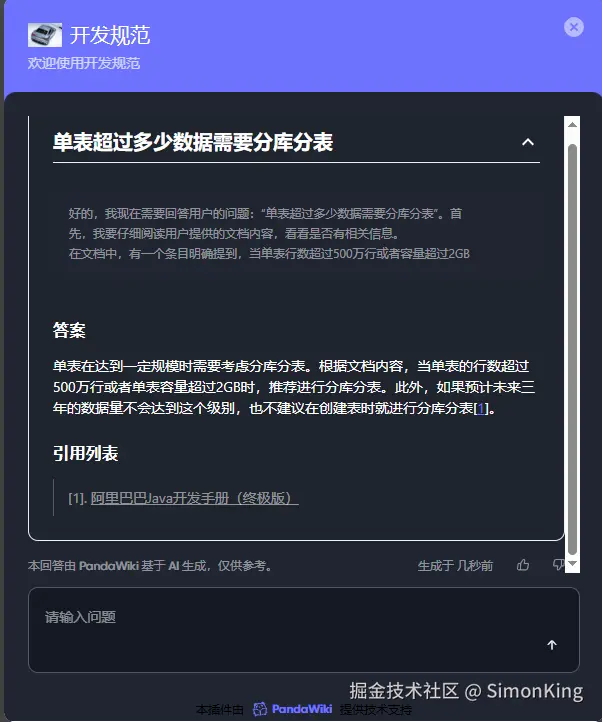
提问效果
06 小结
单从知识库来看,小编觉得Pandawiki用起来更加舒服一些。Dify的功能远不止知识库,还可以制作负责的工作流等。而MaxKB更加适合简单独立的问答需求。搭建知识库你们会怎么选?