
❄专栏传送门:《C语言》、《数据结构与算法》、C语言刷题12天IO强训、LeetCode代码强化刷题、洛谷刷题、C/C++基础知识知识强化补充、C/C++干货分享&学习过程记录
🍉学习方向:C/C++方向学习者
⭐️人生格言:为天地立心,为生民立命,为往圣继绝学,为万世开太平
前言:距离我们学完C语言已经过去一段时间了,在学习了初阶的数据结构之后,博主还要更新的内容就是【C语言16天强化训练】,之前博主更新过一个【C语言刷题12天IO强训】的专栏,那个只是从入门到进阶的IO模式真题的训练。【C语言16天强化训练】既有IO型,也有接口型。和前面一样,今天依然是训练五道选择题和两道编程算法题,希望大家能够有所收获!

目录
[1.1 题目1](#1.1 题目1)
[1.2 题目2](#1.2 题目2)
[1.3 题目3](#1.3 题目3)
[1.4 题目4](#1.4 题目4)
[1.5 题目5](#1.5 题目5)
[2.1 珠玑妙算](#2.1 珠玑妙算)
[2.1.1 题目理解](#2.1.1 题目理解)
[2.1.2 思路](#2.1.2 思路)
[2.1.3 实现](#2.1.3 实现)
[2.2 两数之和](#2.2 两数之和)
[2.2.1 题目理解](#2.2.1 题目理解)
[2.2.2 思路1及其C语言实现](#2.2.2 思路1及其C语言实现)
[2.2.3 思路2及其C语言实现](#2.2.3 思路2及其C语言实现)
[2.2.4 思路3及其C语言实现](#2.2.4 思路3及其C语言实现)
[2.2.5 推荐使用哈希表法的原因](#2.2.5 推荐使用哈希表法的原因)
[2.2.6 思路2和思路3的复杂度分析](#2.2.6 思路2和思路3的复杂度分析)
[2.2.7 失败的C语言实现](#2.2.7 失败的C语言实现)
[2.2.8 C++实现](#2.2.8 C++实现)
一、五道选择题
1.1 题目1
**题干:**有以下函数,该函数的功能是( )
cpp
int fun(char *s)
{
char *t = s;
while(*t++);
return(t-s);
}A. 比较两个字符的大小 B. 计算s所指字符串占用内存字节的个数
C. 计算 s 所指字符串的长度 D. 将s所指字符串复制到字符串 t 中
解析:正确答案就是B选项。
循环在*t为0时停止,同时t++,t最后会停在字符串结束的'\0'之后的一个位置,t作为尾部指针减去头部指针就是整个字符串占用内存的字节数,包含\0在内;而c答案字符串长度不包括最后的\0。
1.2 题目2
**题干:**若有" float a3 = {1.5 , 2.5 , 3.5} , *pa = a;*(pa++)* = 3; ",则 *pa 的值是( )
A. 1.5 B. 2.5 C. 3.5 D. 4.5
解析:正确答案就是B选项。
在*pa=a中指针pa指向a0;pa++返回值仍是操作之前的值;*(pa++)取pa指向的地址的值;*(pa++)*=3将该值变为原来的3倍,也就是数组a的第一个值为4.5;由于pa++之后pa指针移动了sizeof(float)个字节,所以pa指向a1,所以值为2.5。
1.3 题目3
**题干:**以下程序运行后的输出结果是( )
cpp
#include <stdio.h>
int main()
{
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}, *p = a + 5, *q = NULL;
*q = *(p+5);
printf("%d %d\n", *p, *q);
return 0;
}A. 运行后报错 B. 6 6 C. 6 11 D. 5 10
解析:正确答案就是A选项。
指针q初始化为NULL,接着又解引用指针q,是错误的,对NULL指针是不能解引用的。
1.4 题目4
**题干:**设有定义 char *p\[\]={"Shanghai","Beijing","Honkong"}; 则结果为 j 字符的表达式是( )
A. *p1 +3 B. *(p1 +3) C. *(p3 +1) D. p31
解析:正确答案就是B选项。
B选项说,p是个char*类型的数组,p1拿到字符串 "beijing" 的首地址,再加3便是 ' j ' 的地址,解地址拿到 ' j ' 。
1.5 题目5
**题干:**以下叙述中正确的是( )
A. 即使不进行强制类型转换,在进行指针赋值运算时,指针变量的基类型也可以不同
B. 如果企图通过一个空指针来访问一个存储单元,将会得到一个出错信息
C. 设变量p是一个指针变量,则语句p=0;是非法的,应该使用p=NULL;
D. 指针变量之间不能用关系运算符进行比较
解析:正确答案就是B选项。
A 选项描述不正确,不同类型指针一般不可以直接赋值;C选项中,p=NULL;和p=0;是等价的;D选项中,指向同一数组的两指针变量进行关系运算可表示它们所指数组元素之间的位置关系。故B选项正确。
选择题答案如下:
1.1 B
1.2 B
1.3 A
1.4 B
1.5 B
校对一下,大家都做对了吗?
二、两道算法题
2.1 珠玑妙算
力扣链接:面试题 16.15. 珠玑妙算
力扣题解链接:频率统计法(基于计数的双遍扫描算法)解决
题目描述:
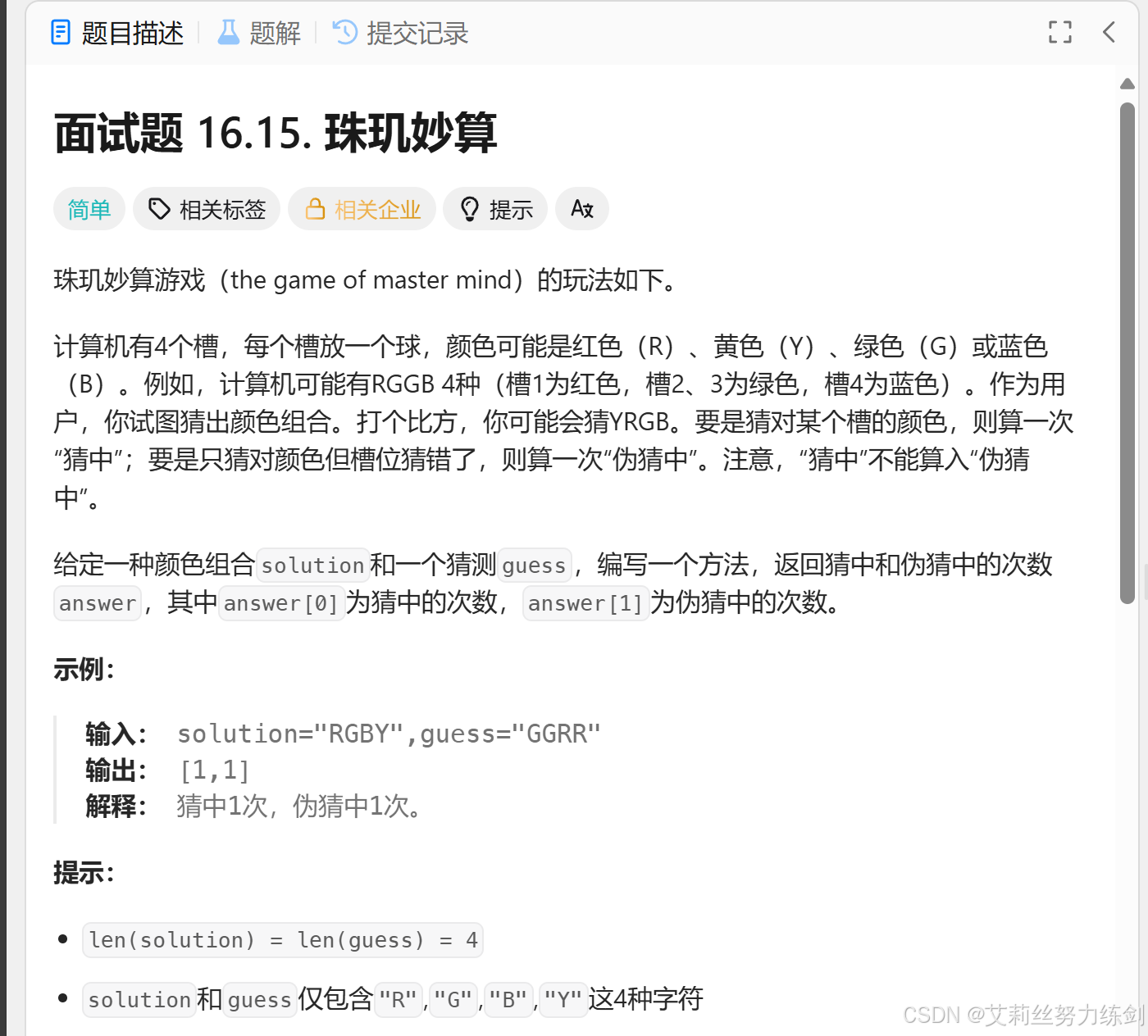
2.1.1 题目理解
给定两个字符串 solution 和 guess(长度均为4,由'R','G','B','Y'组成),计算猜中(位置和颜色都正确)的次数和伪猜中(颜色正确但位置错误,且不能重复计算猜中的部分)的次数。
2.1.2 思路
1、****猜中(Hit):遍历每个位置,如果 solution[i] == guess[i],则猜中次数加1,并且将这两个位置标记(或排除),因为它们不能用于后续的伪猜中计算。
2、伪猜中(Pseudo-Hit):需要统计颜色正确但位置不对的情况。注意:已经被猜中使用的颜色不能重复计算。
(1)我们可以分别统计 solution 和 guess 中非猜中位置的字符频率;
(2)对于每种颜色,伪猜中次数等于 min(该颜色在solution非猜中位置的出现次数, 该颜色在guess非猜中位置的出现次数)。
3、具体步骤:
(1)第一次遍历:计算猜中次数,并记录哪些位置被猜中。
(2)同时,收集非猜中位置的 solution 和 guess 的字符到频率数组(或计数数组)。
(3)第二次遍历:对于每种颜色,计算伪猜中次数 = min(该颜色在solution非猜中位置的出现次数, 该颜色在guess非猜中位置的出现次数)。
2.1.3 实现
这道题是接口型的,下面是C语言的模版(如果是IO型就可以不用管它们了)------
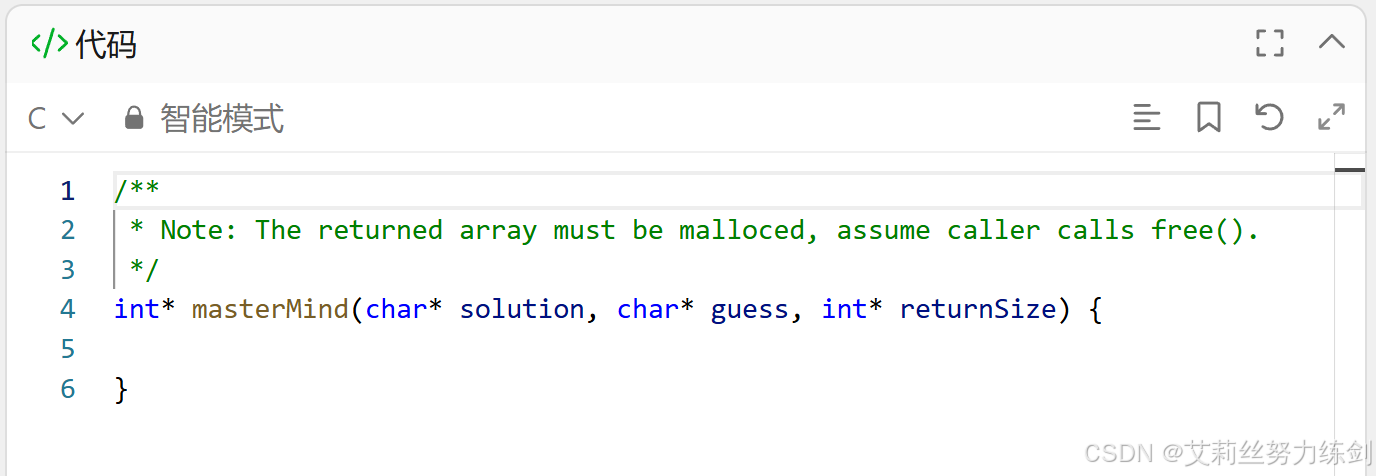
代码演示:
cpp
//C语言实现
//#include <stdlib.h>
//#include <string.h>
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* masterMind(char* solution, char* guess, int* returnSize) {
int* ans = (int*)malloc(2 * sizeof(int));
ans[0] = 0; // 猜中
ans[1] = 0; // 伪猜中
*returnSize = 2;
int len = 4;
int s_count[26] = { 0 }; // 用于统计solution非猜中位置的字符频率(这里只用4个字符,但用26保证安全)
int g_count[26] = { 0 }; // 用于统计guess非猜中位置的字符频率
// 第一遍遍历:计算猜中,并记录非猜中位置的字符
for (int i = 0; i < len; i++) {
if (solution[i] == guess[i]) {
ans[0]++;
}
else {
s_count[solution[i] - 'A']++;
g_count[guess[i] - 'A']++;
}
}
// 计算伪猜中:对于每种颜色,取min(s_count[c], g_count[c])
for (int i = 0; i < 26; i++) {
ans[1] += (s_count[i] < g_count[i]) ? s_count[i] : g_count[i];
}
return ans;
}时间复杂度 :**O(n),**其中 n=4(常数时间),但算法本身是线性扫描两次,所以是高效的;
空间复杂度 :**O(1),**因为使用了固定大小的频率数组(26个元素)。
我们既然明确了要统计猜中次数和伪猜中次数,这个代码还可以这样写------
思路:
1、遍历两个数组,统计猜中次数和伪猜中次数;
2、猜中次数:若位置相同且颜色字符也相同在猜中次数计数器+1;
3、伪猜中次数:颜色相同,但是在不同位置,这时候只需要除去猜中位置之外,统计两个数组中各个字符出现的数量,取较小的一方就是每种颜色伪猜中的数量了。
代码演示:
cpp
int* masterMind(char* solution, char* guess, int* returnSize) {
*returnSize = 2;
static int arr[2] = { 0 };
arr[0] = 0; arr[1] = 0;//静态空间不会进行二次初始化因此每次重新初始化,可以使用memset函数
int s_arr[26] = { 0 };//26个字符位 solution 四种颜色数量统计
int g_arr[26] = { 0 };//26个字符位 guess 四种颜色数量统计
for (int i = 0; i < 4; i++)
{
if (solution[i] == guess[i])
{
arr[0] += 1;//位置和颜色完全一致则猜中数量+1
}
else
{
//统计同一位置不同颜色的两组颜色数量,伪猜中不需要对应位置相同,只需要有对应数量的颜色就行
s_arr[solution[i] - 'A'] += 1; //统计solution对应颜色字符出现次数
g_arr[guess[i] - 'A'] += 1;//统计guess对应颜色字符出现次数
}
}
//在两个颜色数量统计数组中查看颜色数量,取相同位置较小的一方就是为猜中数量
for (int i = 0; i < 26; i++)
{
arr[1] += s_arr[i] > g_arr[i] ? g_arr[i] : s_arr[i];
}
return arr;
}时间复杂度 :**O(n),**其中 n=4(常数时间),但算法本身是线性扫描两次,所以是高效的;
空间复杂度 :**O(1),**因为使用了固定大小的频率数组(26个元素)。
我们学习了C++之后也可以尝试用C++来实现一下,看看自己前段时间C++学得怎么样------
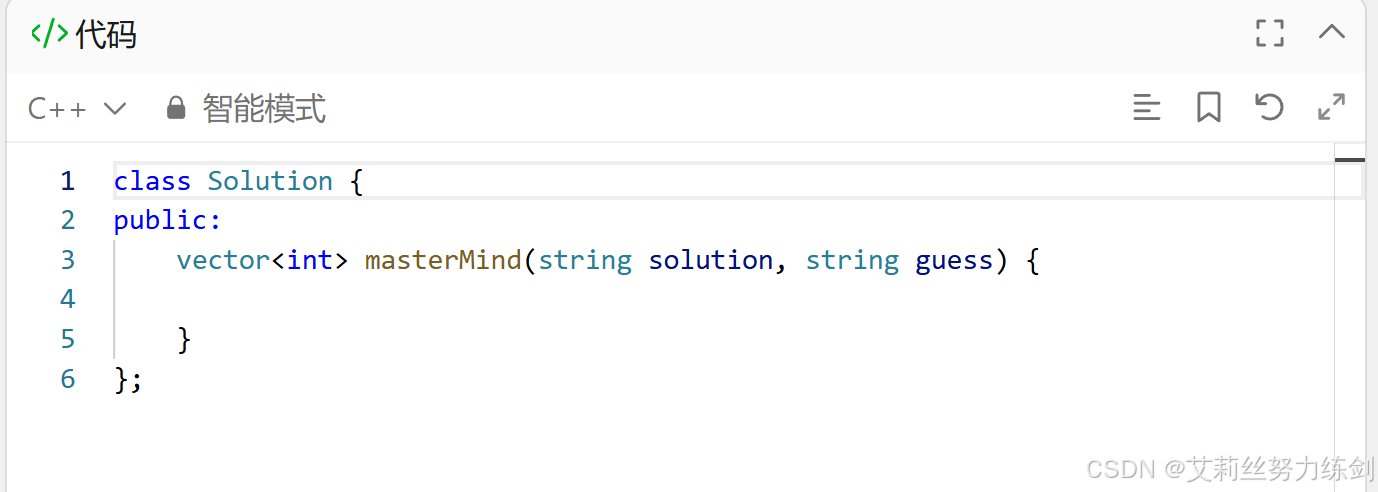
代码演示:
cpp
//C++实现
//#include <vector>
//#include <string>
//#include <algorithm>
//using namespace std;
class Solution {
public:
vector<int> masterMind(string solution, string guess)
{
int hit = 0, pseudoHit = 0;
int s_count[26] = { 0 };
int g_count[26] = { 0 };
int n = solution.size();
for (int i = 0; i < n; i++)
{
if (solution[i] == guess[i])
{
hit++;
}
else {
s_count[solution[i] - 'A']++;
g_count[guess[i] - 'A']++;
}
}
for (int i = 0; i < 26; i++)
{
pseudoHit += min(s_count[i], g_count[i]);
}
return { hit, pseudoHit };
}
};时间复杂度: O(n)****,空间复杂度: O(1)****。
我们目前要写出来C++的写法是非常考验前面C++的学习情况好不好的,大家可以尝试去写一写,优先掌握C语言的写法,博主还没有介绍C++的算法题,之后会涉及的,敬请期待!
2.2 两数之和
牛客网链接:NC61 两数之和
题目描述:
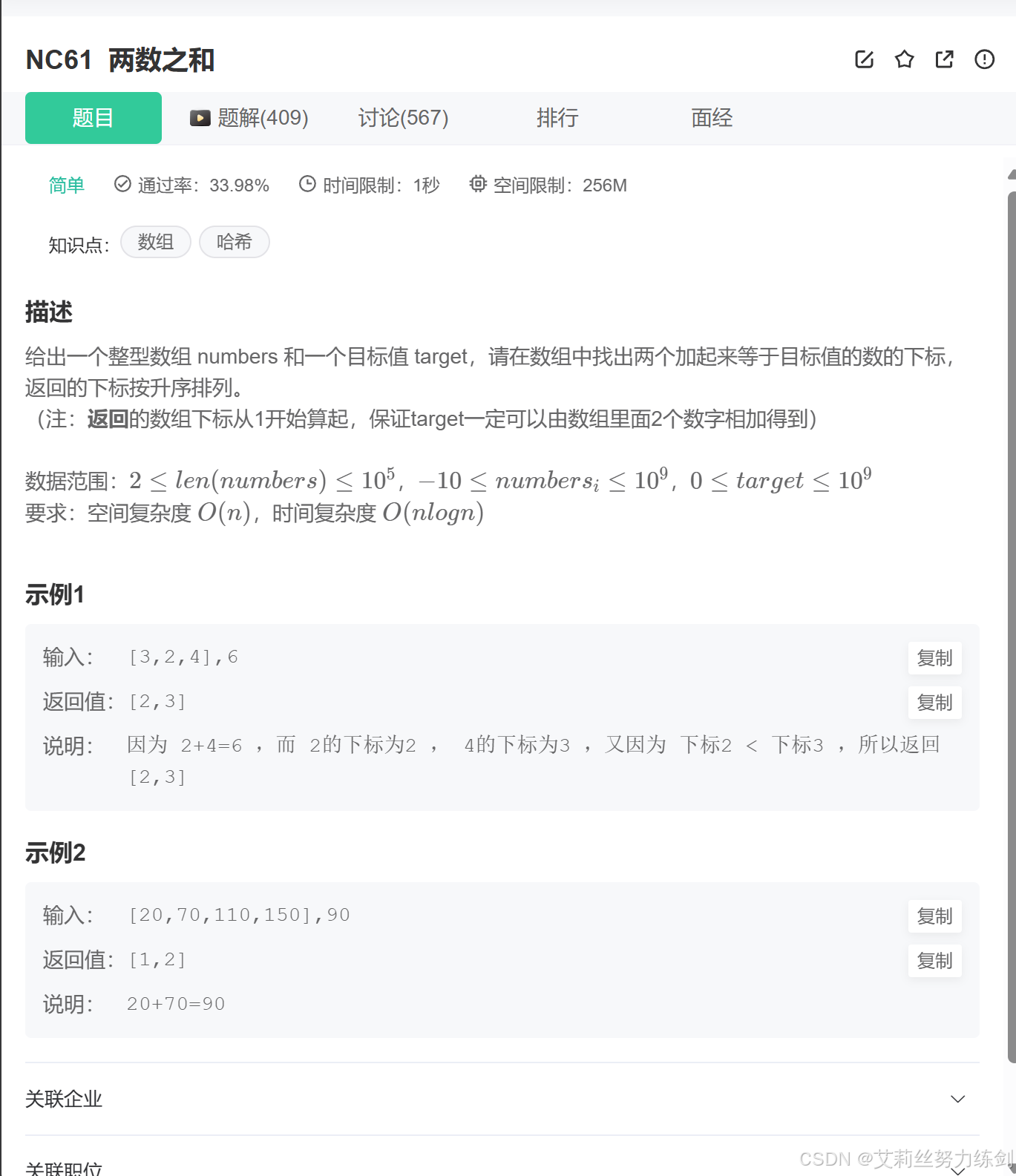
2.2.1 题目理解
在数组中拿到一个数字 num 后,在剩下的数字中查找是否有等于 target - num 的数字即可。
2.2.2 思路1及其C语言实现
在数组中拿到一个数字 num 后,在剩下的数字中查找是否有等于 target - num 的数字即可。
这道题是接口型的,下面是C语言的模版(如果是IO型就可以不用管它们了)------
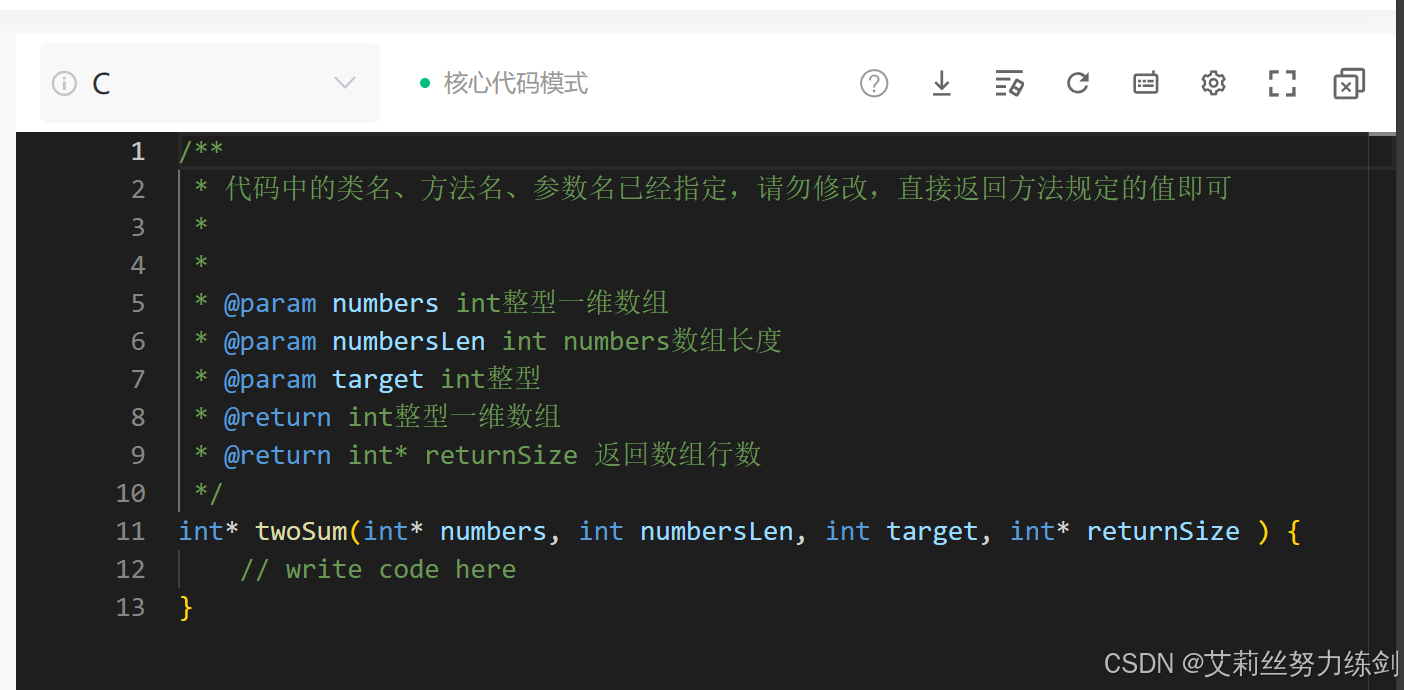
代码演示:
cpp
//C语言------超时
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型一维数组
* @param numbersLen int numbers数组长度
* @param target int整型
* @return int整型一维数组
* @return int* returnSize 返回数组行数
*/
int* twoSum(int* numbers, int numbersLen, int target, int* returnSize) {
*returnSize = 2;
static ret_arr[2] = { 0 };
memset(ret_arr, 0x00, sizeof(ret_arr));
//静态空间不会二次初始化,因此手动初始化
for (int i = 0; i < numbersLen; i++)
{
//从第0个位置开始一个一个数字找
for (int j = i + 1; j < numbersLen; j++)
{
//从第一个数字往后的数字中找出另一个数字
//与numbers[i]相加等于target的数字找到了则i和j就是对应两个数字下标
if (numbers[i] + numbers[j] == target)
{
ret_arr[0] = i + 1;//题目要求下标从1开始
ret_arr[1] = j + 1;
return ret_arr;
}
}
}
*returnSize = 0;//没有符合的下标则返回数组大小为0;
return NULL;
}时间复杂度 :O(n);
空间复杂度 :O(1)。
本质上是双指针方法,但是这段代码报了错------
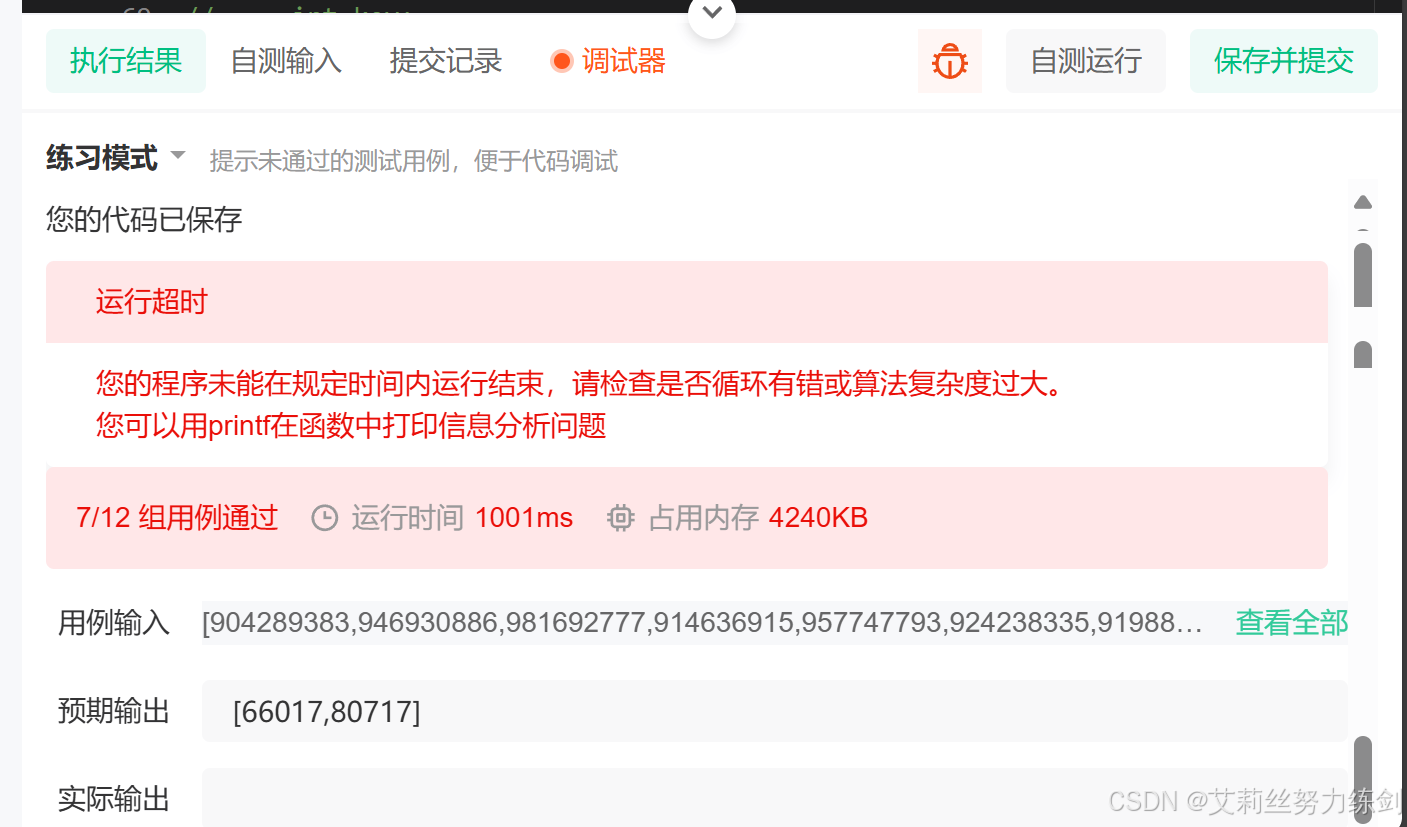
2.2.3 思路2及其C语言实现
思路2:排序+双指针法(需要处理原始下标)。
代码演示:
cpp
//C语言实现------排序+双指针法(需要处理原始下标)
#include <stdlib.h>
typedef struct {
int value;
int originalIndex;
} NumberWithIndex;
int compare(const void* a, const void* b)
{
return ((NumberWithIndex*)a)->value - ((NumberWithIndex*)b)->value;
}
int* twoSum(int* numbers, int numbersLen, int target, int* returnSize) {
// 创建包含值和原始下标的数组
NumberWithIndex* arr = (NumberWithIndex*)malloc(numbersLen * sizeof(NumberWithIndex));
for (int i = 0; i < numbersLen; i++)
{
arr[i].value = numbers[i];
arr[i].originalIndex = i + 1; // 下标从1开始
}
// 按值排序
qsort(arr, numbersLen, sizeof(NumberWithIndex), compare);
int* result = (int*)malloc(2 * sizeof(int));
*returnSize = 2;
// 双指针查找
int left = 0, right = numbersLen - 1;
while (left < right)
{
int sum = arr[left].value + arr[right].value;
if (sum == target)
{
// 确保返回的下标是升序的
if (arr[left].originalIndex < arr[right].originalIndex)
{
result[0] = arr[left].originalIndex;
result[1] = arr[right].originalIndex;
}
else
{
result[0] = arr[right].originalIndex;
result[1] = arr[left].originalIndex;
}
free(arr);
return result;
}
else if (sum < target)
{
left++;
}
else
{
right--;
}
}
free(arr);
return result;
}时间复杂度 :O(nlogn);
空间复杂度 :O(n)。
复杂度分析(思路2C语言实现结合下面C++的实现)------
1、时间复杂度:
(1)C语言实现:排序需要 O(nlogn)O(nlogn),双指针遍历需要 O(n)O(n),因此总时间复杂度为 O(nlogn)O(nlogn),满足要求。
(2)C++实现:使用哈希表,每个元素插入和查找的平均时间复杂度为 O(1)O(1),因此总时间复杂度为 O(n)O(n),优于要求(O(nlogn)O(nlogn))。
2、空间复杂度:
(1)C语言实现:需要额外 O(n)O(n) 空间存储结构体数组,因此空间复杂度为 O(n)O(n)。
(2)C++实现:哈希表最多存储 nn 个元素,因此空间复杂度为 O(n)O(n)。
下面我们总结一下本题对于两种实现方式复杂度的分析------
**总结:**两种实现均满足题目要求。C++实现更简洁且效率更高(O(n)O(n)),但C语言实现由于语言限制,采用了排序+双指针的方法(O(nlogn)O(nlogn)),也符合要求。
2.2.4 思路3及其C语言实现
虽然C语言没有内置哈希表,但我们可以自己实现一个简单的哈希表------
代码演示:
cpp
//哈希表法
#include <stdlib.h>
#define HASH_SIZE 200000
typedef struct HashNode
{
int key;
int value;
struct HashNode* next;
} HashNode;
HashNode* hashTable[HASH_SIZE];
unsigned int hash(int key)
{
return (unsigned int)(abs(key)) % HASH_SIZE;
}
void insert(int key, int value)
{
unsigned int index = hash(key);
HashNode* node = (HashNode*)malloc(sizeof(HashNode));
node->key = key;
node->value = value;
node->next = hashTable[index];
hashTable[index] = node;
}
int find(int key)
{
unsigned int index = hash(key);
HashNode* node = hashTable[index];
while (node != NULL)
{
if (node->key == key)
{
return node->value;
}
node = node->next;
}
return -1;
}
int* twoSum(int* numbers, int numbersLen, int target, int* returnSize) {
// 初始化哈希表
for (int i = 0; i < HASH_SIZE; i++)
{
hashTable[i] = NULL;
}
int* result = (int*)malloc(2 * sizeof(int));
*returnSize = 2;
for (int i = 0; i < numbersLen; i++)
{
int complement = target - numbers[i];
int complementIndex = find(complement);
if (complementIndex != -1)
{
// 找到匹配项,注意下标从1开始
result[0] = complementIndex + 1; // 之前存储的下标
result[1] = i + 1; // 当前下标
// 清理哈希表内存(实际中可以省略,因为程序结束)
return result;
}
// 将当前数插入哈希表
insert(numbers[i], i);
}
return result;
}时间复杂度 :O(nlogn);
空间复杂度 :O(n)。
2.2.5 推荐使用哈希表法的原因
1、更高效 :时间复杂度 O(n),优于排序法的 O(nlogn)。
2、更简单 :不需要处理排序和原始下标的问题。
3、更可靠 :避免排序可能带来的各种边界问题。
2.2.6 思路2和思路3的复杂度分析
1、哈希表法:
(1)时间复杂度:O(n);
(2)空间复杂度:O(n)。
2、排序+双指针法:
(1)时间复杂度:O(nlogn);
(2)空间复杂度:O(n)。
两种方法都满足题目要求,但哈希表法在性能上更优。建议使用哈希表法的实现。
2.2.7 失败的C语言实现
代码演示:
cpp
//C语言实现------失败
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型一维数组
* @param numbersLen int numbers数组长度
* @param target int整型
* @return int整型一维数组
* @return int* returnSize 返回数组行数
*/
int* twoSum(int* numbers, int numbersLen, int target, int* returnSize)
{
// 创建哈希表(这里使用简单数组模拟哈希表可能不适用,因为数字范围很大,但题目要求空间复杂度O(n),所以用哈希表结构)
// 由于C没有内置哈希表,我们使用一个结构体数组来模拟,但更高效的方式是使用uthash等库?但题目要求自己实现。
// 实际上,由于数字范围很大(-10到10^9),我们无法用数组下标直接映射,因此需要其他方法。
// 另一种思路:先排序并记录原始下标?但题目要求返回原始下标,且要求时间复杂度O(nlogn),空间复杂度O(n)
// 但注意:题目要求返回原始下标(从1开始),所以排序会破坏下标。我们需要保留原始下标信息。
// 由于题目数据范围很大,且要求时间复杂度O(nlogn),我们可以先排序,然后使用双指针?但排序会破坏原始下标。
// 因此,我们需要在排序时同时记录原始下标。
// 方法:创建一个结构体数组,保存数值和原始下标(从1开始)
typedef struct
{
int value;
int index;
} Node;
Node* nodes = (Node*)malloc(numbersLen * sizeof(Node));
for (int i = 0; i < numbersLen; i++)
{
nodes[i].value = numbers[i];
nodes[i].index = i + 1; // 下标从1开始
}
// 按value排序
qsort(nodes, numbersLen, sizeof(Node), compare);
// 双指针
int left = 0, right = numbersLen - 1;
int* result = (int*)malloc(2 * sizeof(int));
*returnSize = 2;
while (left < right)
{
int sum = nodes[left].value + nodes[right].value;
if (sum == target)
{
// 找到目标,注意返回下标升序
if (nodes[left].index < nodes[right].index)
{
result[0] = nodes[left].index;
result[1] = nodes[right].index;
}
else
{
result[0] = nodes[right].index;
result[1] = nodes[left].index;
}
free(nodes);
return result;
}
else if (sum < target)
{
left++;
}
else {
right--;
}
}
free(nodes);
return result; // 实际不会执行到这里,因为保证有解
}时间复杂度 :O(nlogn);
空间复杂度 :O(n)。
友友们知道问题出在哪里吗?欢迎在评论区讨论!
2.2.8 C++实现
我们学习了C++之后也可以尝试用C++来实现一下,看看自己前段时间C++学得怎么样------
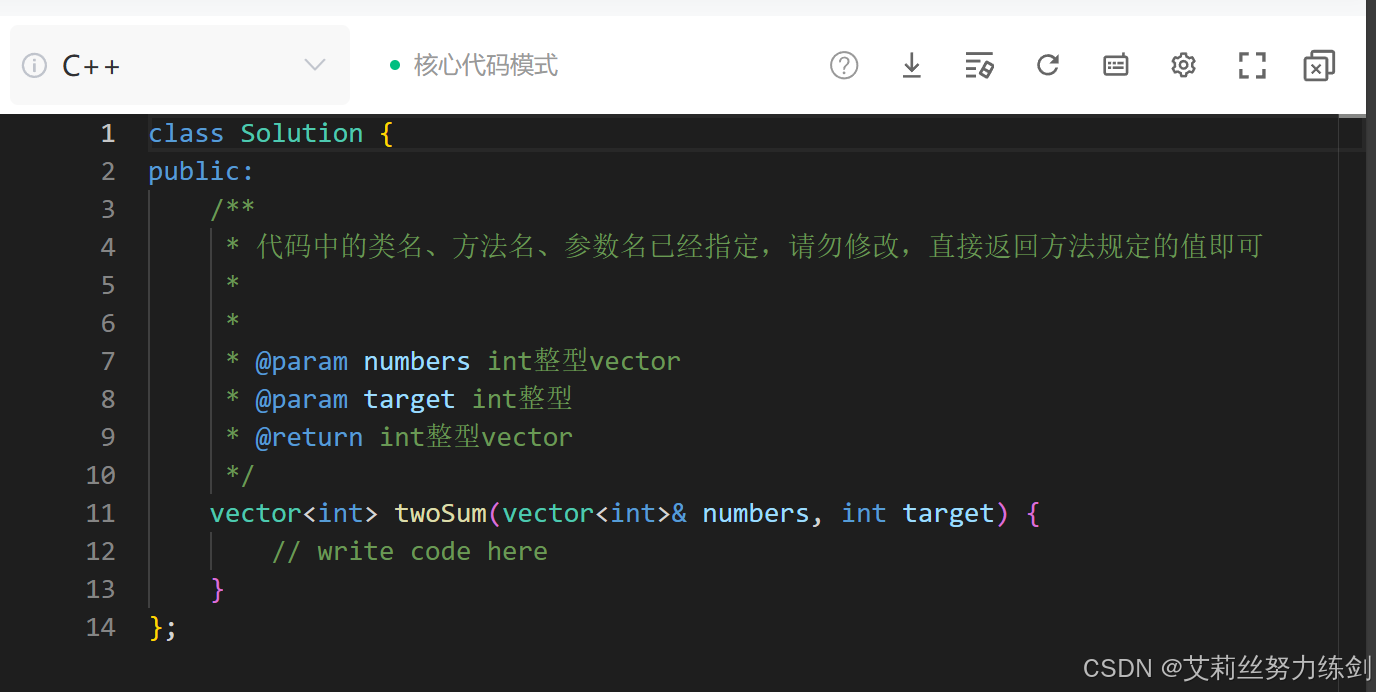
完整代码演示:
cpp
//C++实现
#include <vector>
#include <algorithm>
#include <unordered_map>
using namespace std;
class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target)
{
unordered_map<int, int> hashMap; // key: number, value: index (from 1)
vector<int> result(2);
for (int i = 0; i < numbers.size(); i++)
{
int complement = target - numbers[i];
if (hashMap.find(complement) != hashMap.end())
{
result[0] = hashMap[complement];
result[1] = i + 1;
return result;
}
hashMap[numbers[i]] = i + 1;
}
return result;
}
};时间复杂度: O(nlogn)****,空间复杂度: O(n)****。
我们目前要写出来C++的写法是非常考验前面C++的学习情况好不好的,大家可以尝试去写一写,优先掌握C语言的写法,博主还没有介绍C++的算法题,之后会涉及的,敬请期待!
结尾
本文内容到这里就全部结束了,希望大家练习一下这几道题目,这些基础题最好完全掌握!
往期回顾:
结语: 感谢大家的阅读,记得给博主"一键四连",感谢友友们的支持和鼓励!