本文深入浅出地介绍了Agentic RAG(检索增强生成)技术,结合实际项目案例,详细讲解了查询重写、多路召回、质量评估等关键技术的实现方法。无论你是刚入门的小白还是寻求技术突破的程序员,通过本文都能掌握如何构建高效智能的问答系统,提升RAG应用的查询质量与效率,为你的大模型落地项目提供实践参考。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将 检索技术 与 生成式 AI 结合的技术框架。
其核心流程包括:
- 存储阶段:对输入文档进行清洗、分块等预处理,并存入知识库;
- 查询阶段:接收查询请求后,通过检索系统获取候选结果,再交由生成式 AI 处理,输出逻辑性更强、可读性更好的答复。
在实际应用中,单纯的 RAG 系统往往存在 查询质量不高、手段单一、鲁棒性不足 等问题。于是,业内逐渐探索出结合 Agent 思路的 Agentic RAG实践,用来提升 RAG 系统的查询质量与效率。
Agentic RAG 的核心是引入 查询重写、多路召回、路由决策、质量评估、多步重查等操作,对整个检索-生成链路进行优化。在不引入额外新技术的前提下,仅通过对输入问题与检索策略的智能化控制,就能显著增强查询系统的鲁棒性与准确性。
可以说,Agentic RAG 是 RAG 与 Agent 结合的最佳实践,不仅能指导 RAG 系统的开发,也能对已有 RAG 应用流程设计提供参考。
本文结合我近期完成的 Agentic RAG 实践项目,分享其中的 Agent 设计思路、关键流程和部分代码实现,帮助大家对这类系统架构有一个整体认识。
一、项目目标
结合近半年业内出现的 Agentic RAG 的最佳实践,开发一个 Agent + RAG 原型系统,完成基于知识库的查询任务。
目标拆解如下:
1. 查询前 :对用户输入进行 查询重写,优化问题质量(关键词提取、规范表述、信息补全)。
2. 查询中 :采用 多路召回策略(关键词、向量、融合排序),提高命中率与相关性。
3. 查询后 :对候选结果进行 质量评估;若结果不足,再触发互联网搜索。
4. 结果生成 :将查询结果交由 LLM 理解与重组,生成 语义完整、逻辑性更高、可读性更强的最终回复。
二、关键技术选型
- Agent Framework
主流的 Agent 开发框架有 ADK与 LangChain。二者均能胜任本项目需求。
ADK 的优势是功能完备、代码简洁,即便不依赖 Google Cloud 生态也能独立运行。
我本次实践选用 ADK作为开发框架。
- Agent 流程控制
项目既有顺序执行逻辑,又涉及动态决策,因此:
SequentialAgent(顺序执行)与 ParallelAgent(并行执行)都不合适;
单纯交由 LLM 驱动的 LLMAgent可能产生幻觉,执行不稳定;
只有支持自定义流程的 Custom Agent才能满足要求。
While the standard Workflow Agents (SequentialAgent, LoopAgent, ParallelAgent) cover common orchestration patterns, you'll need a Custom agent when your requirements include:
Conditional Logic
Complex State Management
External Integrations
Dynamic Agent Selection
- 数据源
《中华人民共和国个人信息保护法》,按行切分作为知识库内容。
code-snippet__js
《中华人民共和国个人信息保护法》第一条规定,为了保护个人信息权益,规范个人信息处理活动,促进个人信息合理利用,根据宪法,制定本法。- 存储方案
向量化模型:BGE-M3
检索引擎:FAISS
持久化:Pickle
为更好的展示 Agentic RAG 流程,项目未采用 RAG SaaS 服务或向量数据库。
- 查询重写
模型:DeepSeek
- 多路召回(智能检索)
关键词召回:jieba + BM25
向量召回:BGE-M3
融合排序:RRF + Cross-Encoder
- 质量评估
模型:DeepSeek
- 互联网搜索
工具:SerpAPI
- 结果整合与优化
模型:DeepSeek
三、关键流程
- 查询流程如下:
css
code-snippet__js
shell
code-snippet__js
### 工作流程详解- 核心类如下:
shell
code-snippet__js
### 核心组件- 项目结构如下:
css
code-snippet__js四、关键代码
- 主Agent
1)初始化
scss
code-snippet__js
classConditionalWorkflowAgent(BaseAgent):- 自定义工作流
1)初始化
css
code-snippet__js
@override2)自定义流程
arduino
code-snippet__js
try:- 查询重写
此项目中的查询重写依赖LLM实现。
bash
code-snippet__js
# 查询重写Agent
- 多路召回(智能检索)
1)关键词召回:jieba + BM25
BM25参数:
php
code-snippet__js
defkeyword_search(self, query: str, top_k: int = 10, k1: float = 1.5, b: float = 0.75) -> List[Dict[str, Any]]:使用jieba分词(中文友好):
bash
code-snippet__js
# 对查询进行相同的分词和过滤处理BM25公式:
bash
code-snippet__js
# BM25公式结果排序:
bash
code-snippet__js
# 按分数排序2)向量召回:BGE-M3
bash
code-snippet__js
# 生成查询向量3)融合排序:RRF + Cross-Encoder
bash
code-snippet__js
# 按融合分数排序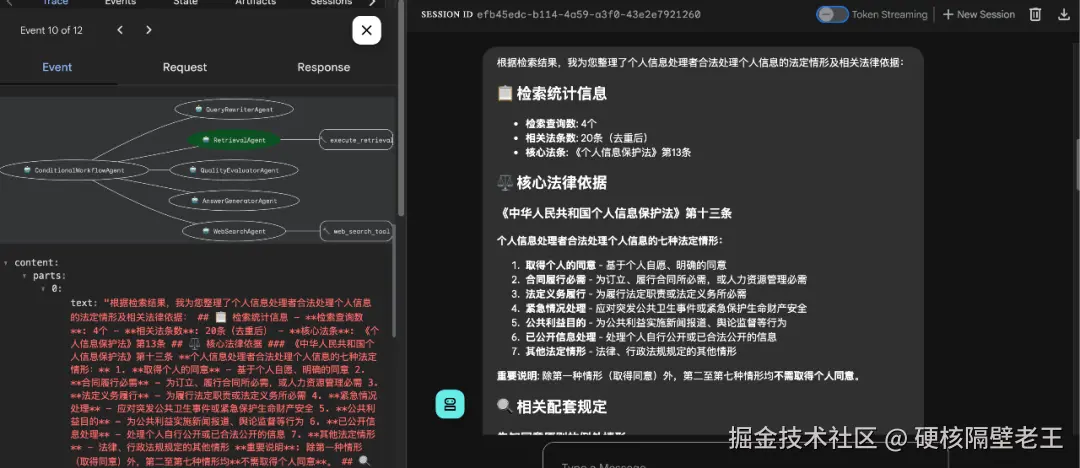
- 质量评估
使用LLM进行质量评估。
bash
code-snippet__js
# 质量评估Agent(含80%阈值判断)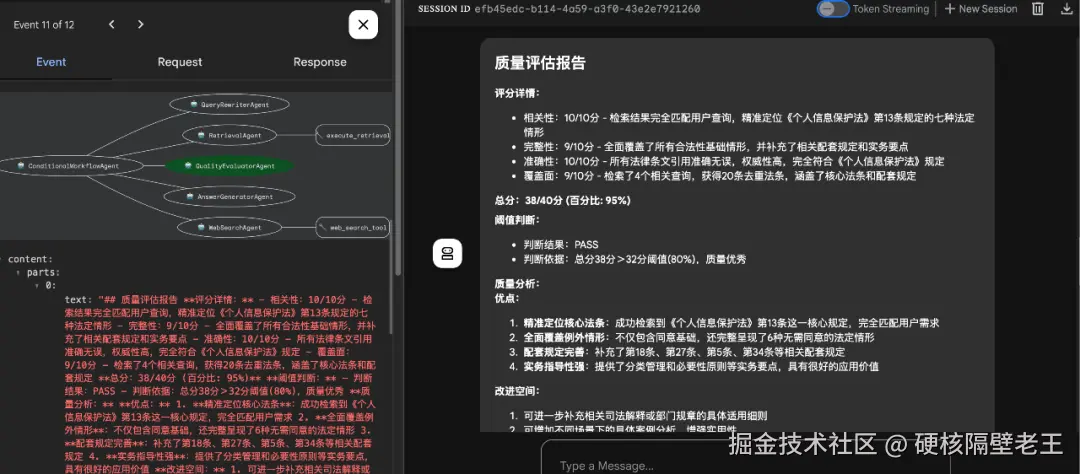
- 互联网搜索
使用SerpAPI进行搜索:
less
code-snippet__js
defweb_search_tool(query: str, max_results: int = 5) -> str:- 结果整合
使用LLM进行结果整合。
bash
code-snippet__js
# 答案生成Agent(基于阈值判断)场景一:命中搜索结果如下:
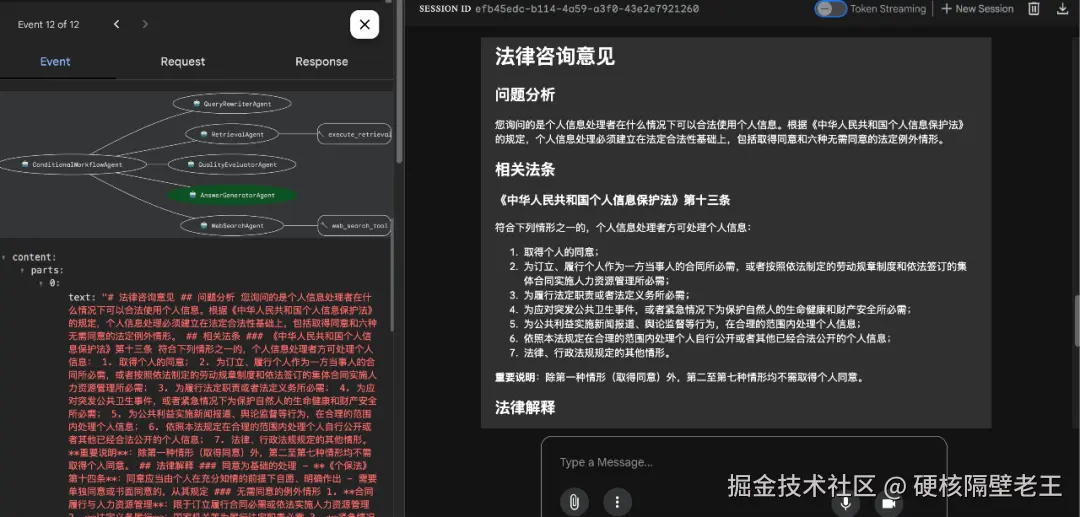
场景二:1. 未命中结果如下:
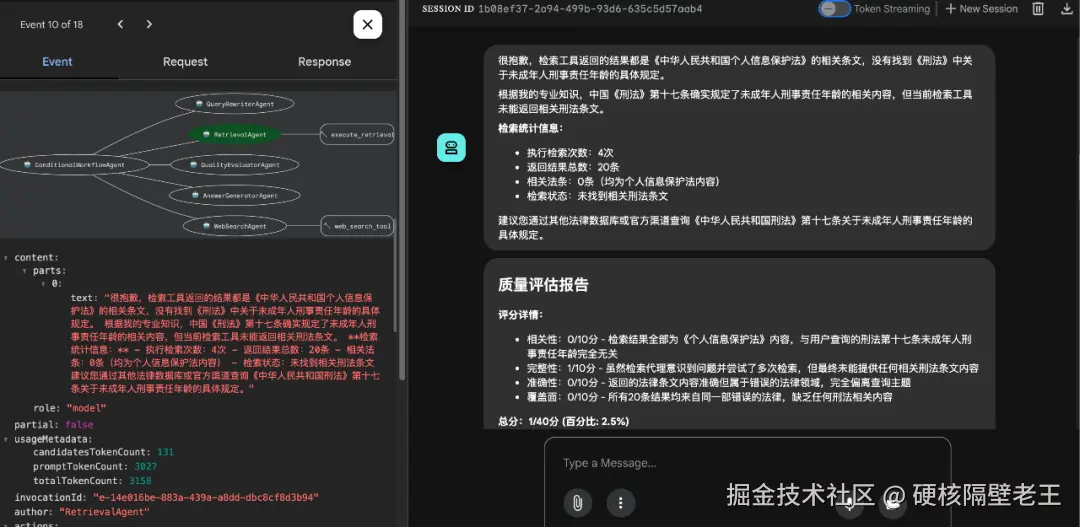
场景二:2. 触发互联网搜索结果如下:
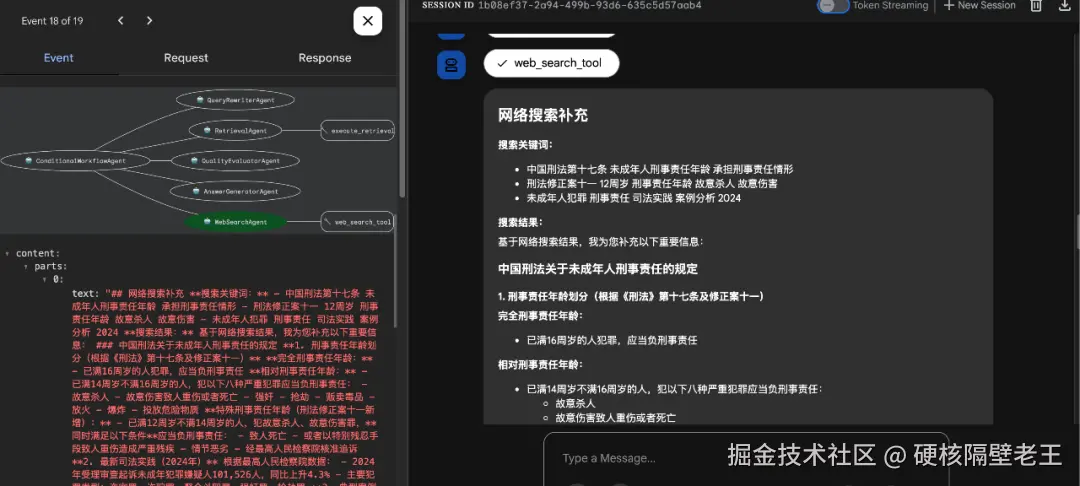
场景二:3. 最终返回结果如下:
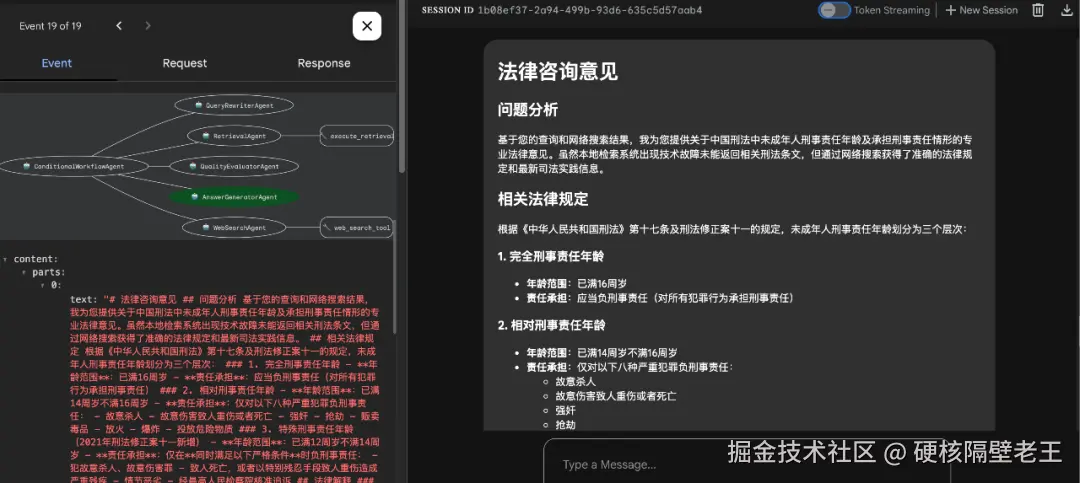
五、实战借鉴意义
即使在日常业务中:
- 查询重写能显著提升命中率。
例如,将口语化表述改写为专业术语;
将模糊问题重写为清晰、完整的查询。
- 查询重写可采用 规则 + LLM双路结合。
小模型 LLM 既能降低成本,也能缩短响应时间。
- 查询路径可采用 漏斗模型:
逐步评估结果质量,若达标提前终止,降低延迟;
若不达标,则逐步扩展搜索途径,确保查询质量。
- 经过 LLM 的二次优化,结果在 逻辑性与可读性上会有显著提升,更贴近实际使用需求。
整体来看,Agentic RAG 在查询链路上提供了可行的优化思路,是企业落地 RAG 系统时非常值得借鉴的一类实践方案。