点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Spark项目下载
- Spark环境配置、配置文件配置
- 项目分发 至 h122和h123服务器

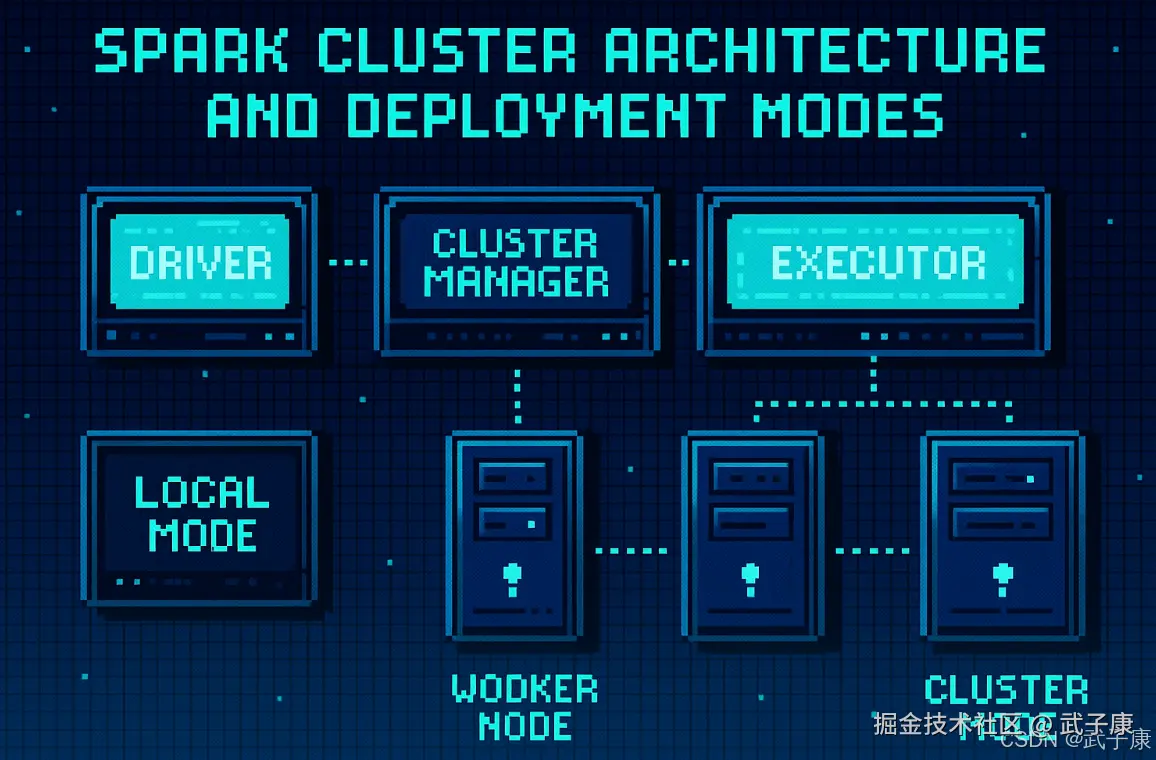
Spark集群架构
在介绍完Spark的核心特性和组件之后,接下来详细探讨一下Spark的集群架构和部署模式。理解Spark的集群架构有助于更好地利用其强大的分布式计算能力,以满足不同的计算需求。 Spark集群主要由以下三个核心组件组成:
- 驱动程序
- 集群管理器
- 执行器
驱动程序(Driver Program)
核心功能
-
应用入口
- 驱动程序是Spark应用的入口点,包含main()方法作为程序执行的起点
- 示例:在Java/Scala中,通过定义main方法启动;在Python中通过if name == "main"启动
-
SparkContext管理
- 负责创建SparkContext对象(Spark 2.0+也可以是SparkSession)
- SparkContext是Spark功能的主要入口,提供:
- 集群连接管理
- RDD创建和操作
- 累加器和广播变量支持
- 作业调度
-
任务调度与分发
- 将用户代码转换为DAG(有向无环图)执行计划
- 将DAG划分为多个Stage和Task
- 通过集群管理器(如YARN、Mesos或Standalone)将Task分发到Executor
详细工作流程
-
初始化阶段
- 解析应用配置参数
- 建立与集群管理器的连接
- 申请Executor资源(核数、内存等)
-
执行阶段
- 将用户代码转换为逻辑执行计划
- 进行优化(如谓词下推、列剪裁等)
- 生成物理执行计划
- 监控任务执行状态:
- 成功/失败任务重试
- 推测执行(Speculative Execution)
- 动态资源分配
-
结果处理
- 收集计算结果(如collect()操作)
- 处理异常情况
- 生成执行日志和指标
运行模式
-
本地模式
- 驱动程序与Executor运行在同一个JVM中
- 适合开发和测试场景
-
集群模式
- Client模式:驱动程序运行在提交节点
- Cluster模式:驱动程序运行在集群工作节点
- 常见部署方式:
- Spark Standalone
- YARN
- Mesos
- Kubernetes
典型生命周期
- 启动并初始化SparkContext
- 创建RDD/DataFrame/Dataset
- 执行转换操作(生成DAG)
- 触发行动操作(提交作业)
- 监控任务执行
- 返回结果
- 关闭SparkContext
容错机制
- 通过心跳机制检测Executor状态
- 失败任务重试机制
- 持久化(Cache/Persist)数据恢复
- 检查点(Checkpoint)机制
性能考量
- 驱动程序通常需要足够内存处理:
- 任务调度开销
- 结果聚合
- 广播变量存储
- 在集群模式下,网络延迟可能影响性能
集群管理器(Cluster Manager)
集群管理器是Spark架构中的核心组件,负责高效管理和分配集群资源。它主要实现以下功能:
- 资源分配:根据应用需求动态分配计算资源(CPU、内存等)
- 任务调度:协调驱动程序和执行器之间的任务分配
- 故障恢复:监控节点状态并处理失败的任务
- 负载均衡:优化资源利用率和任务执行效率
Spark支持多种集群管理器,每种都适用于不同的部署场景:
1. Standalone模式
这是Spark内置的轻量级集群管理器,特点包括:
- 部署简单:只需在集群节点上安装Spark即可运行
- 资源隔离:通过配置可以限制每个应用使用的资源比例
- 典型应用场景:
- 开发测试环境
- 小型生产集群(通常节点数<50)
- 快速原型验证
- 管理工具:提供Web UI(默认端口8080)和命令行工具(spark-submit)
2. YARN(Yet Another Resource Negotiator)
作为Hadoop生态系统的核心组件,YARN的特点包括:
- 架构组成:
- ResourceManager:全局资源管理器
- NodeManager:节点级资源代理
- ApplicationMaster:应用级资源协调器
- 优势:
- 与HDFS深度集成
- 支持多租户资源共享
- 成熟的生产级稳定性
- 部署模式:
- Client模式:驱动程序运行在提交节点
- Cluster模式:驱动程序运行在YARN容器内
- 典型应用:大数据分析平台、ETL流水线
3. Mesos
Apache Mesos是一个通用的集群资源管理系统,特点包括:
- 两阶段调度:
- 资源分配(Resource Offers)
- 任务启动(Task Launch)
- 部署模式:
- Coarse-grained:粗粒度模式,适合长任务
- Fine-grained:细粒度模式,适合短任务
- 优势:
- 支持混合负载(可同时运行Spark、Hadoop等服务)
- 资源隔离(通过Linux容器实现)
- 高可扩展性(支持上万节点)
- 典型应用:多框架混合部署环境
4. Kubernetes
作为容器编排平台,Kubernetes集成方案的特点包括:
- 架构组件:
- Driver Pod:运行Spark驱动程序的Pod
- Executor Pods:动态创建的执行器Pod
- Kubernetes Scheduler:负责资源调度
- 优势:
- 原生容器化支持
- 弹性伸缩(支持Horizontal Pod Autoscaler)
- 多云部署能力
- 部署方式:
- 使用spark-submit直接提交
- 通过Operator模式管理
- 典型应用场景:
- 云原生应用
- 混合云部署
- 微服务架构下的批处理
选择建议
| 特性 | Standalone | YARN | Mesos | Kubernetes |
|---|---|---|---|---|
| 学习曲线 | 低 | 中 | 中 | 高 |
| 部署复杂度 | 简单 | 中等 | 复杂 | 中等 |
| 资源隔离 | 弱 | 强 | 强 | 最强 |
| 扩展性 | 低 | 高 | 极高 | 高 |
| 适合场景 | 开发测试 | 大数据生产 | 混合负载 | 云原生 |
注:实际选择时还需考虑现有技术栈、团队技能和运维成本等因素。
执行器(Executor)
- 执行器是在工作节点(Worker Node)上运行的进程,负责执行分配的任务。每个执行器都具有自己的内存和CPU资源,并独立执行任务。
- 执行器在整个Spark应用的生命周期内都会存在,它不仅执行任务,还会将数据缓存在内存中,以加快后续任务的处理速度。
Spark的集群模式
Spark支持多种集群部署模式,适应不同的工作环境和需求:
本地模式(Local Mode)
在本地模式下,Spark在单一节点上运行,无需集群管理器。这种模式主要用于开发、测试和调试,不适合生产环境。使用本地模式时,可以通过指定线程数(如local\*)来决定并行度。
集群模式(Cluster Mode)
在集群模式下,Spark应用部署在集群中,任务分发到多个工作节点上执行。驱动程序可以运行在本地也可以运行在集群中,前者称为客户端模式(Client Mode),后者称为集群模式(Cluster Mode)。
- 客户端模式:驱动程序在用户的本地机器上运行,适合需要频繁与用户交互的应用。用户提交应用时,集群管理器负责分配资源并启动执行器。
- 集群模式:驱动程序在集群的一个节点上运行,适合长时间运行的作业和生产环境。用户提交应用后,集群管理器会在集群中选择一个节点作为驱动程序运行的地方。
混合模式(Mesos/Kubernetes)
在Mesos或Kubernetes模式下,Spark可以与其他应用共享集群资源,并根据资源需求动态调整资源的分配。这种模式为大规模集群提供了更高的灵活性和资源利用率,适合企业级应用场景。
集群资源管理详解
Spark集群资源管理概述
在Spark集群环境中,资源管理是确保系统高效稳定运行的核心问题。Spark支持多种集群管理器,每种管理器都采用独特的资源分配策略来满足不同业务场景的需求。合理的资源分配策略能显著提升任务执行效率,降低资源浪费。
主要资源管理策略
1. 静态资源分配(Static Resource Allocation)
适用模式:主要用于Spark Standalone集群模式
工作原理:
- 管理员需要预先在spark-defaults.conf配置文件中设置固定参数: spark.executor.memory 4G spark.executor.cores 2 spark.executor.instances 10
- 集群启动时,这些资源会被预先分配并保持固定
- 资源分配基于"First Come, First Serve"原则
特点:
- 实现简单,管理方便
- 资源利用率可能较低(尤其在任务负载波动时)
- 适合负载稳定可预测的生产环境
典型应用场景:
- 长期运行的ETL作业
- 批处理分析任务
- 资源需求稳定的流处理应用
2. 动态资源分配(Dynamic Resource Allocation)
适用模式:YARN和Kubernetes集群模式
核心机制: Spark通过以下参数启用动态分配:
arduino
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.minExecutors 2
spark.dynamicAllocation.maxExecutors 20
spark.dynamicAllocation.initialExecutors 3工作流程:
- 资源扩展:当任务积压时,Spark会向集群管理器请求更多executor
- 资源收缩 :当executor空闲超过
spark.dynamicAllocation.executorIdleTimeout(默认60秒)时,会被释放 - 弹性调度:结合Spark的推测执行(speculative execution)机制处理慢节点
优势特性:
- 自动根据负载调整资源规模
- 支持优雅降级(在资源紧张时减少executor数量)
- 与Kubernetes的HPA(Horizontal Pod Autoscaler)或YARN的弹性资源管理协同工作
应用场景:
- 交互式查询(如Spark SQL)
- 负载波动大的流处理作业
- 多租户共享集群环境
- 云原生部署场景
进阶配置建议
- 资源隔离:在共享集群中,通过命名空间或队列隔离不同团队的资源
- 监控集成:结合Prometheus和Grafana监控资源使用情况
- 成本优化:在云环境中,可配置spot实例策略降低成本
性能调优提示
- 对于长任务,适当增加
spark.dynamicAllocation.executorIdleTimeout - 在YARN模式下,设置
spark.yarn.executor.memoryOverhead应对JVM开销 - 考虑使用资源调度器(如YARN的Capacity Scheduler)实现更精细的控制
集群监控与调优
为了确保Spark集群的稳定运行和高效利用,集群监控与调优是不可或缺的环节。Spark提供了多种监控工具和日志记录功能,帮助管理员了解集群的运行状态并进行调优。
- Spark UI:这是一个基于Web的用户界面,显示作业的执行状态、任务的分配情况、资源的使用情况等详细信息。通过Spark UI,用户可以深入了解应用的执行过程,并找出性能瓶颈。
- Ganglia、Prometheus等监控工具:这些工具可以与Spark集成,提供更细粒度的监控数据,帮助管理员实时监控集群的健康状态。 日志与指标:Spark生成的日志文件和性能指标数据也可以帮助管理员分析集群的运行情况,发现并解决潜在的问题。
Hadoop 集群启动
在 h121 节点上进行执行,我们启动服务:
shell
start-all.sh启动的结果如下图所示: 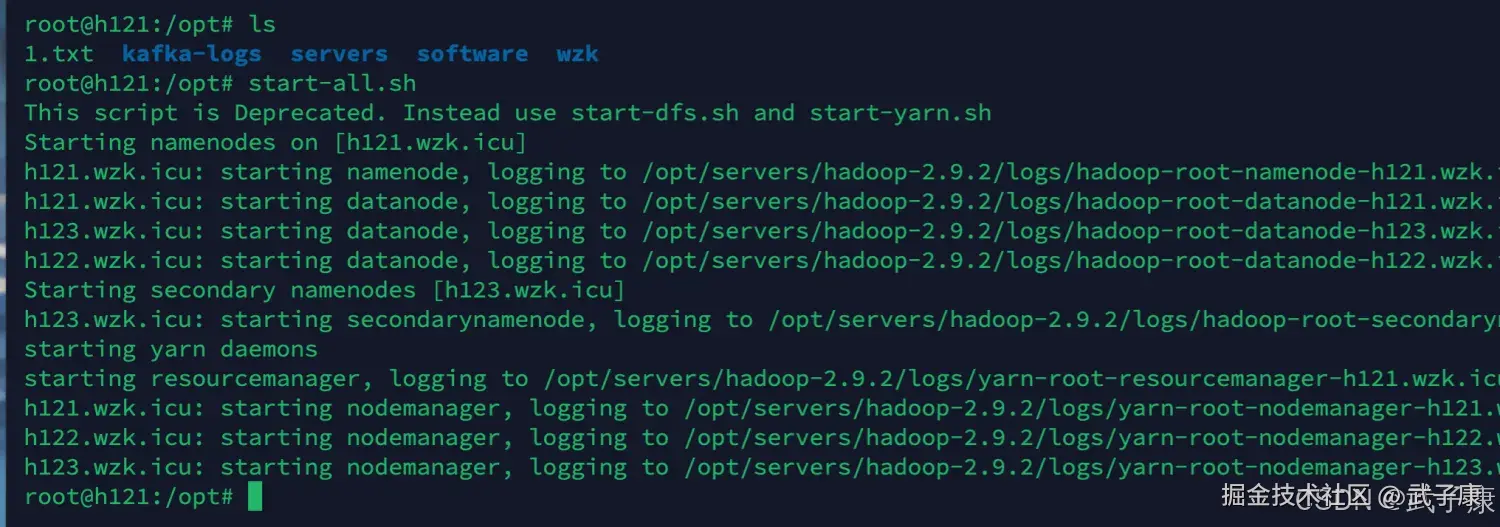
Spark 集群启动
接着我们需要到目录下,启动集群的Spark
shell
cd /opt/servers/spark-2.4.5-bin-without-hadoop-scala-2.12/sbin
./start-all.shh121 节点
通过 jps 我可以可以看到:Master 和 Worker 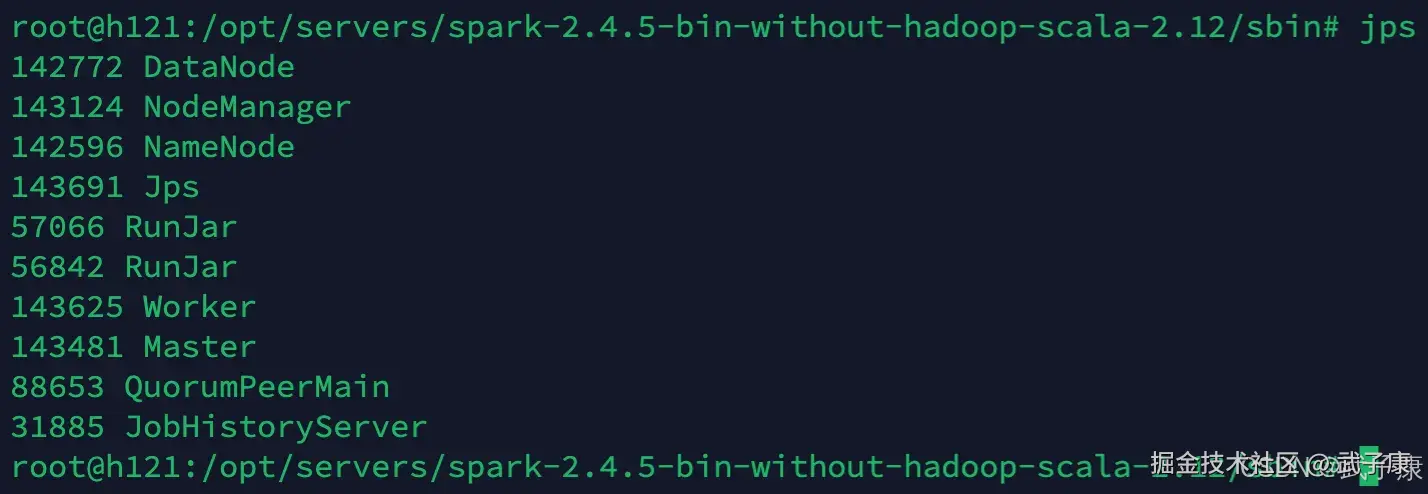
h122 节点
通过 jps 我们可以看到: 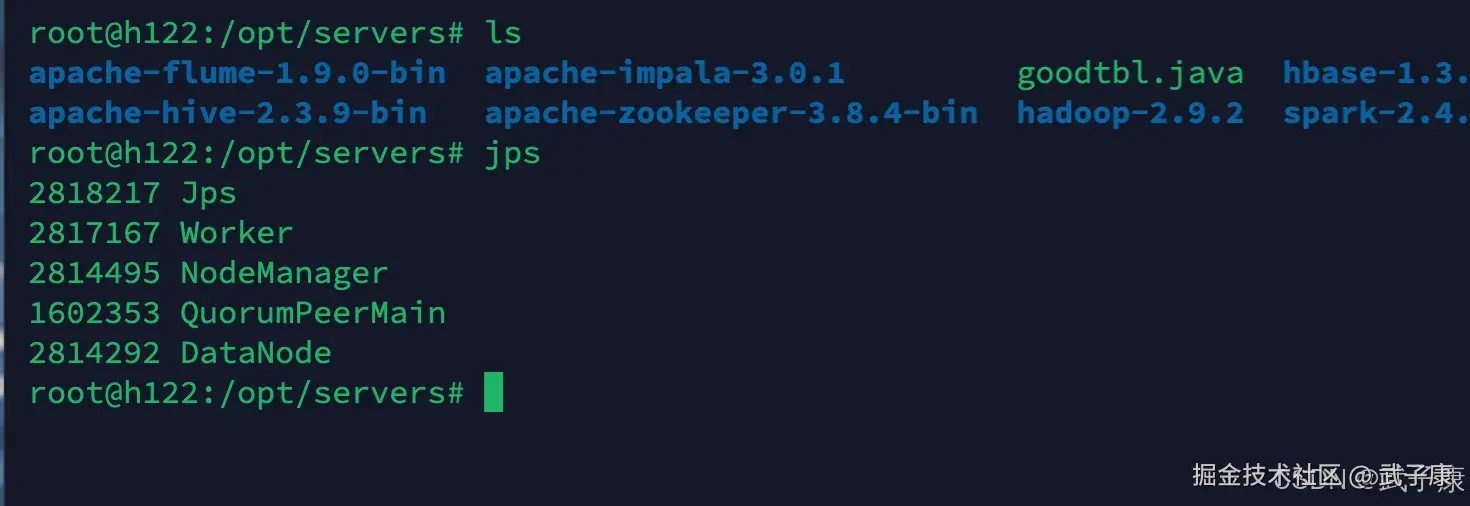
h123 节点
通过 jps 我们可也看到: 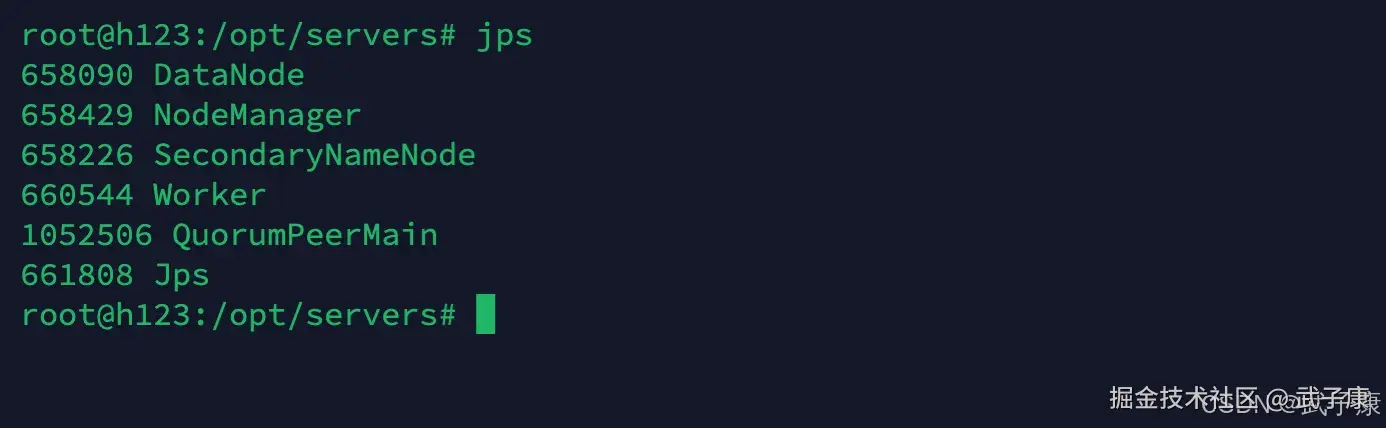
查看结果
我们通过查看 h121 的日志,可以看到是 8081 的端口(我的8080好像是被占用了) 这个在Spark的目录下的 logs下,如果你也遇到了无法访问,可以看看这个logs 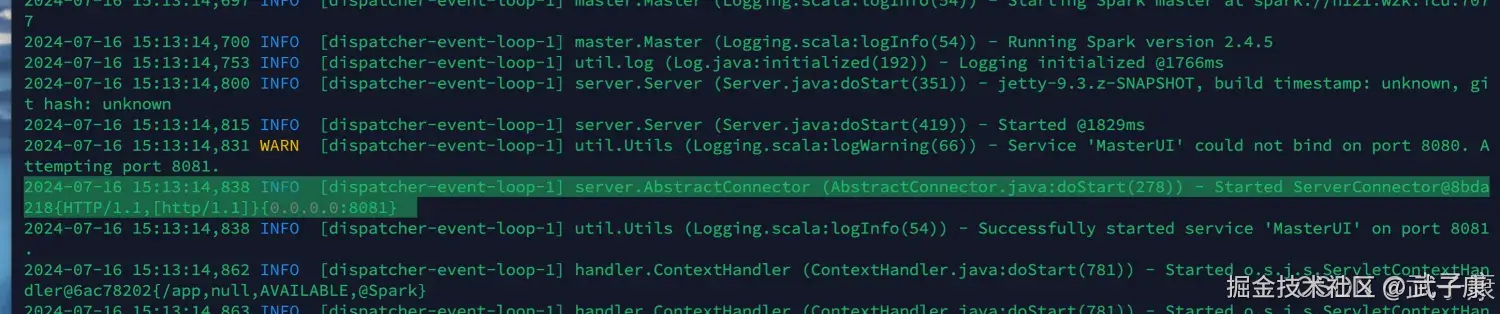
测试运行
这里Spark提供了一个官方的HelloWorld(前提你配置好环境变量,不然你需要到指定目录执行)
shell
run-example SparkPi 10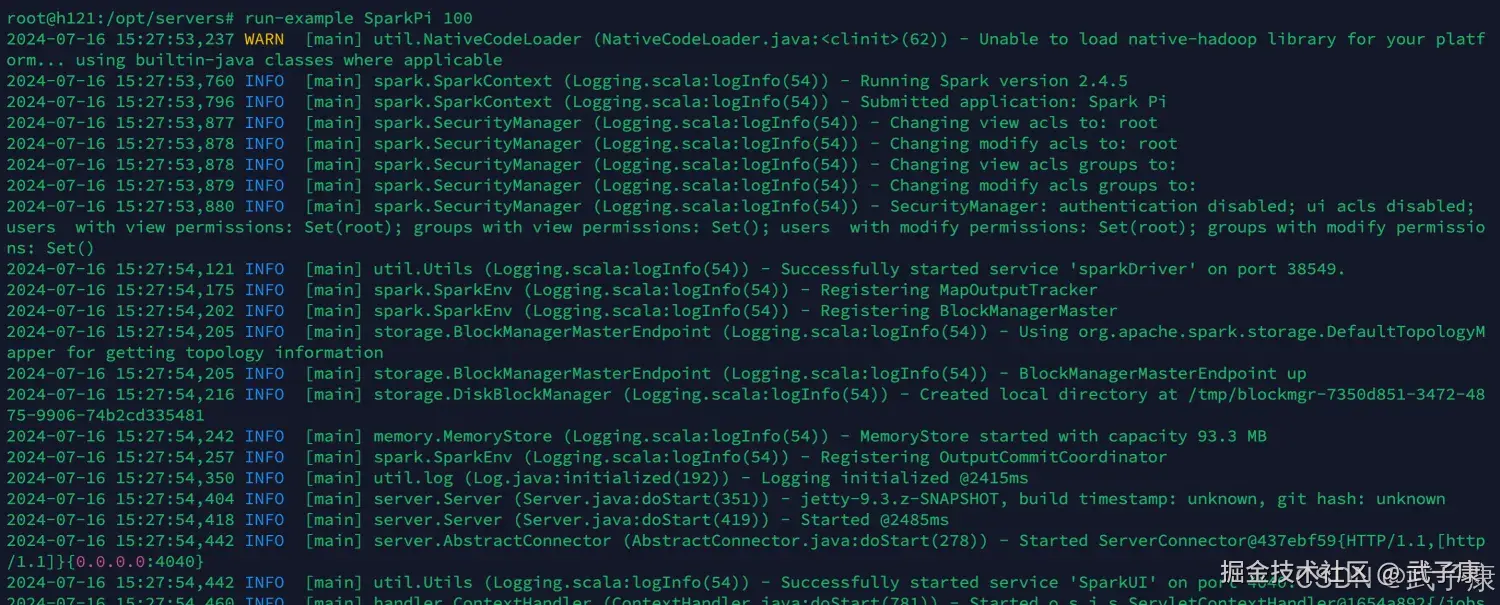 可以看到如下的结果为:
可以看到如下的结果为: 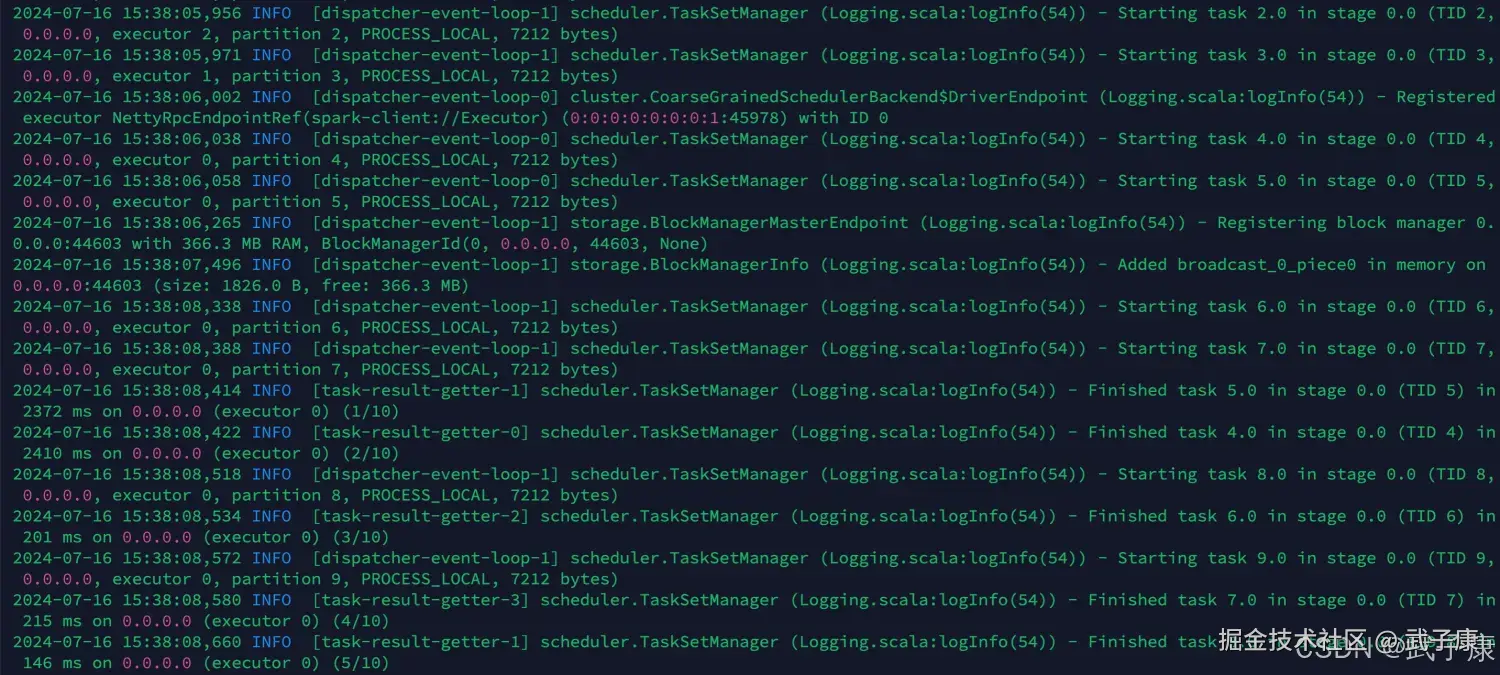
SparkShell
我们可以简单的启动一个Shell来测试Spark的效果: (后续有更深入的学习!)
shell
spark-shell --master local-cluster[*]这里有一些之前测试的图片: 
先不管别的,先写一段感受一下:
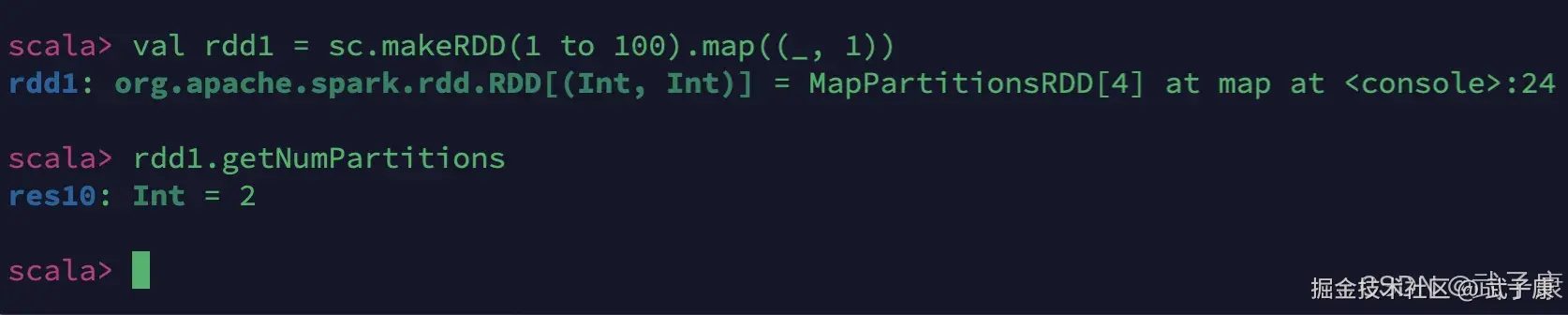
shell
val rdd1 = sc.makeRDD(1 to 100).map((_, 1))
rdd1.getNumPartitions