F012 百度地图+vue+flask+爬虫 推荐算法旅游大数据可视化系统Echarts mysql数据库 带沙箱支付+图像识别技术
📚编号: F012
文章结尾部分有CSDN官方提供的学长 联系方式名片
博主开发经验15年,全栈工程师,专业搞定大模型、知识图谱、算法和可视化项目和比赛
视频介绍
百度地图+vue+flask+爬虫 推荐算法旅游大数据可视化系统Echarts mysql数据库 带沙箱支付+图像识别技术
简介:vue+flask+爬虫 旅游景点推荐算法与可视化大数据系统源码-包含基于用户和基于物品的协同过滤算法、多种百度地图API集成(热力图、地图)、Echarts分析图、WordCloud词云、支付宝沙箱支付、百度AI图像识别(OCR识别身份证-实名认证) 👉 👈
1 系统功能
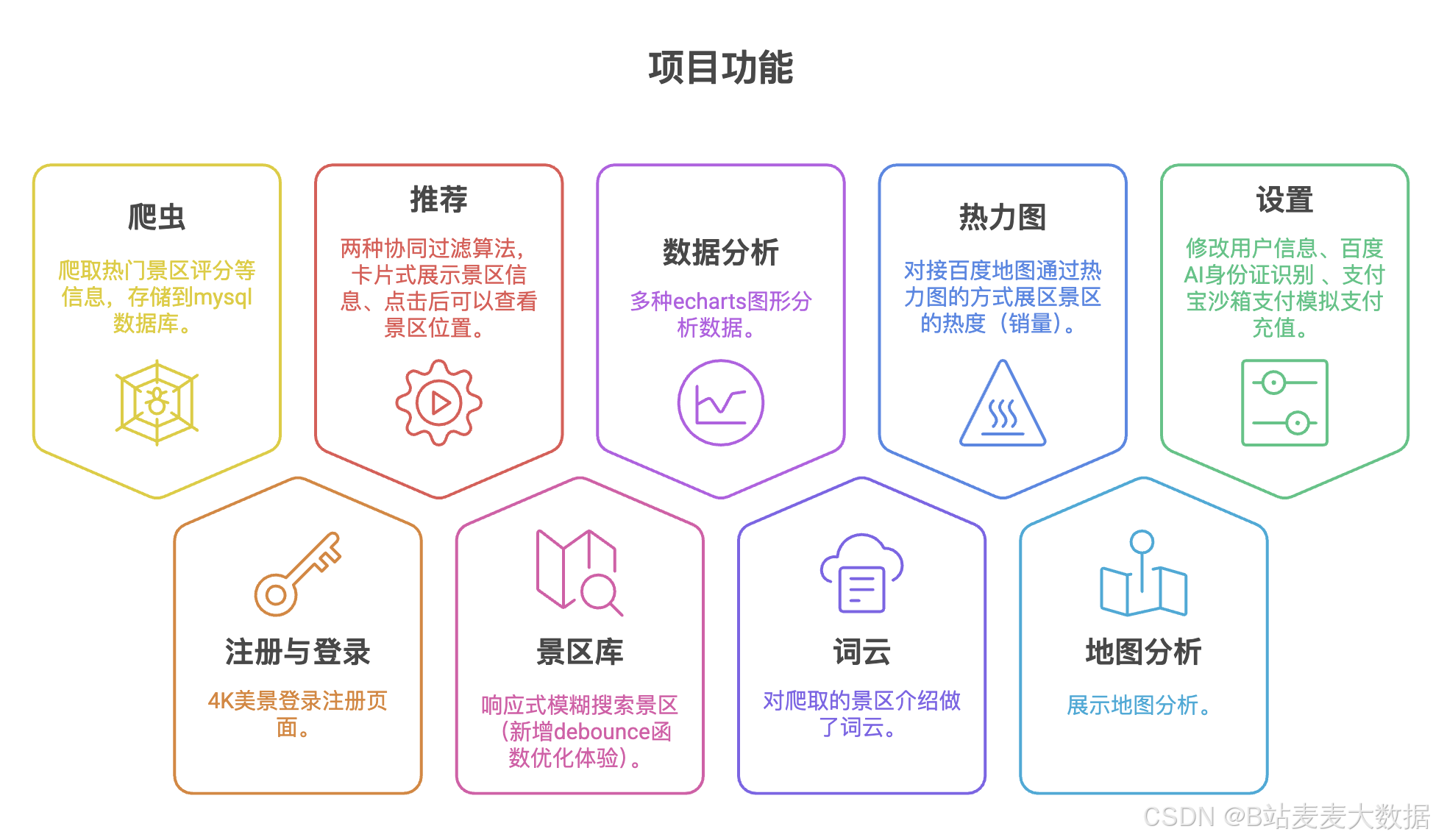
- 爬虫:爬取热门景区评分等信息,存储到mysql数据库;
- 注册与登录 : 4K美景登录注册页面;
- 推荐:两种协同过滤算法,卡片式展示景区信息、点击后可以查看景区位置;
- 景区库: 响应式模糊搜索景区(新增debounce函数优化体验);
- 数据分析: 多种echarts图形分析数据;
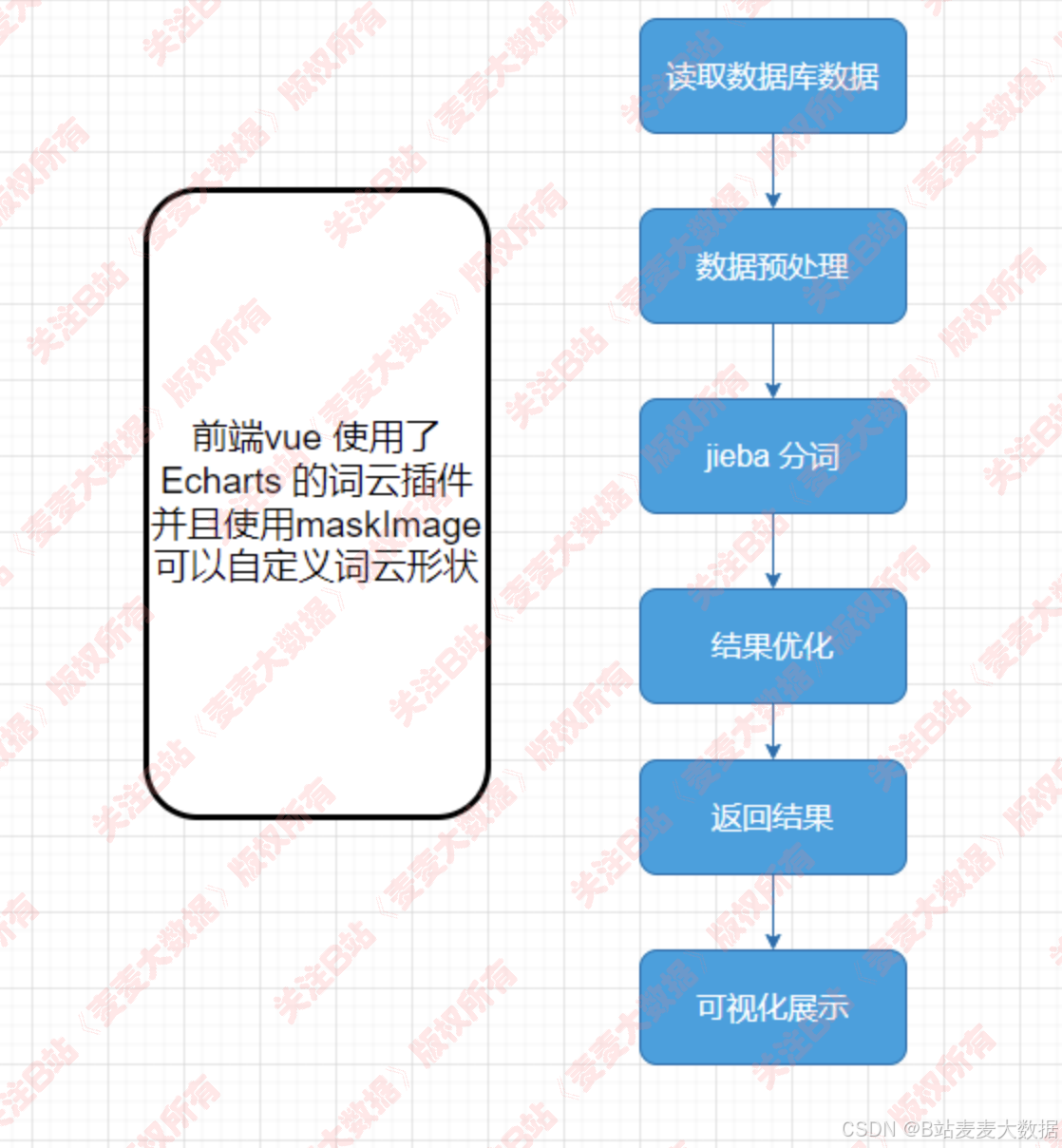
- 词云: 对爬取的景区介绍做了词云;
- 热力图:对接百度地图通过热力图的方式展区景区的热度(销量)
- 地图分析: 展示地图分析;
- 设置:修改用户信息、百度AI身份证识别 、支付宝沙箱支付模拟支付充值;
2 系统亮点 ⭐
- 实现的分析图:数据大屏、景区热力图、景区分布地图、景区交互地图、词云、多种折线图、饼图、环图等;
- 景区地图展示:可以直接在百度地图中给出景区位置;
- 推荐算法: 两种协同过滤推荐算法使用。 【User Based & Item Based】;
- 实名认证功能:通过使用百度AI-ORC识别身份证实现 【python实现】;
- 充值功能:完美集成支付宝沙箱支付;
- 自适应移动端;
- 界面主题可修改,配置化批量修改配色;
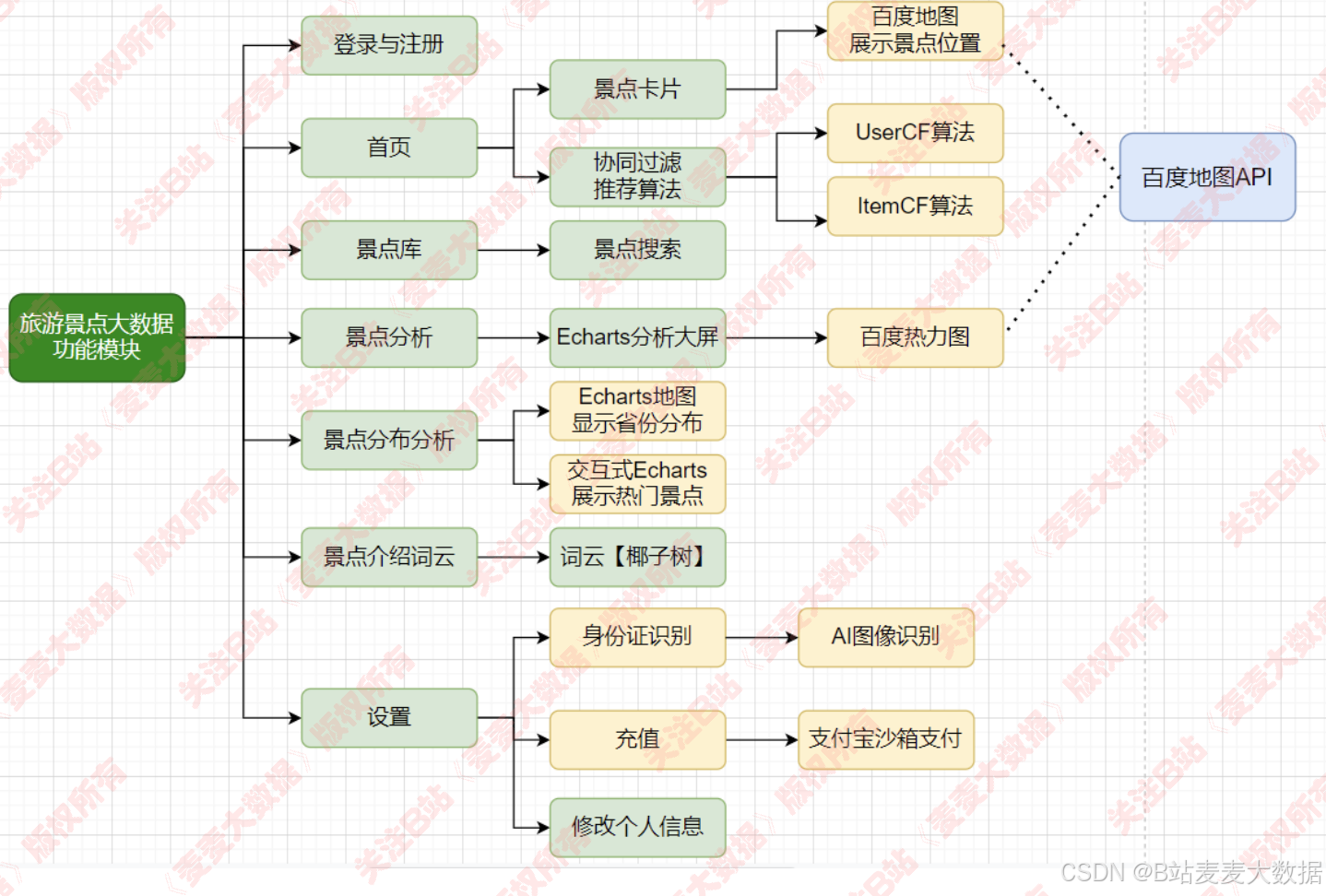
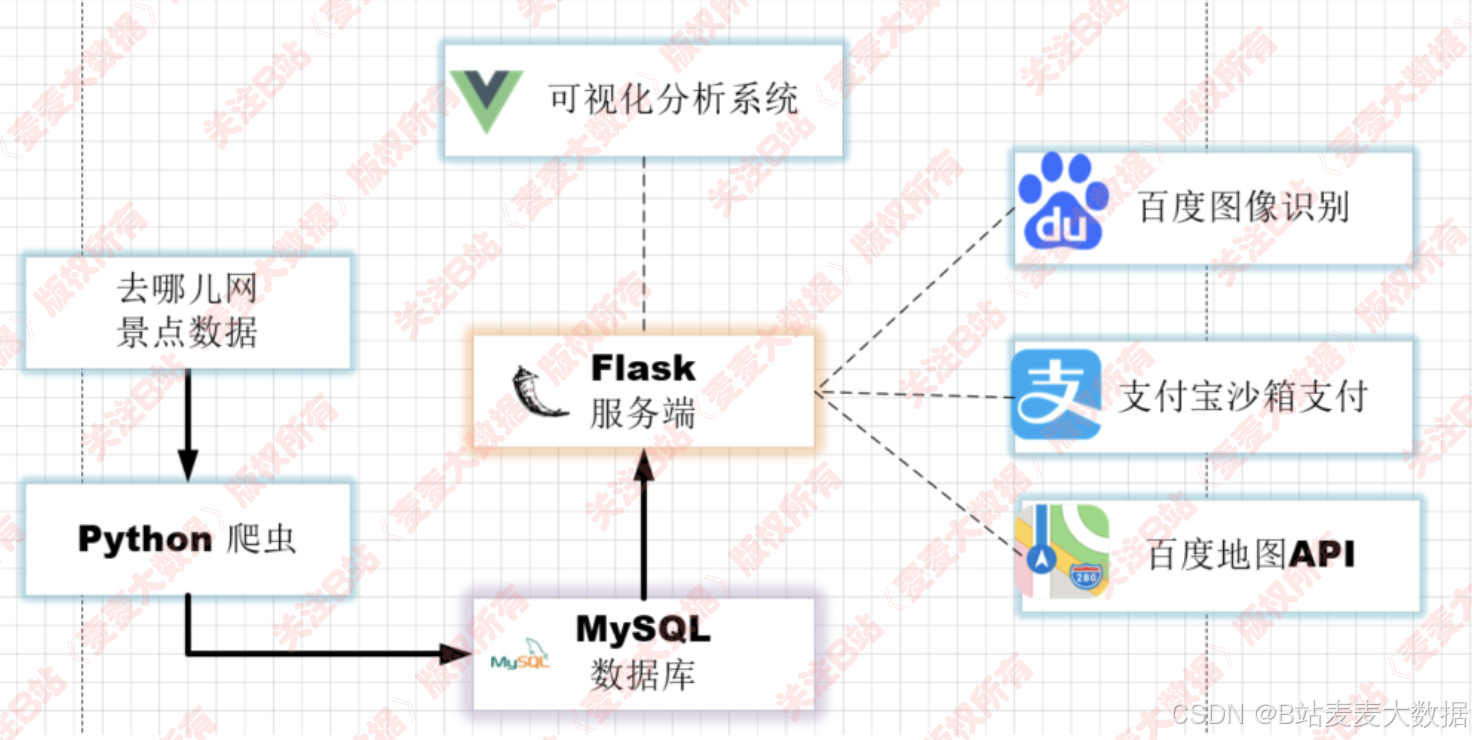
3 架构功能图
3.1 功能图
3.2 架构图
3.3 词云处理逻辑
4 功能介绍
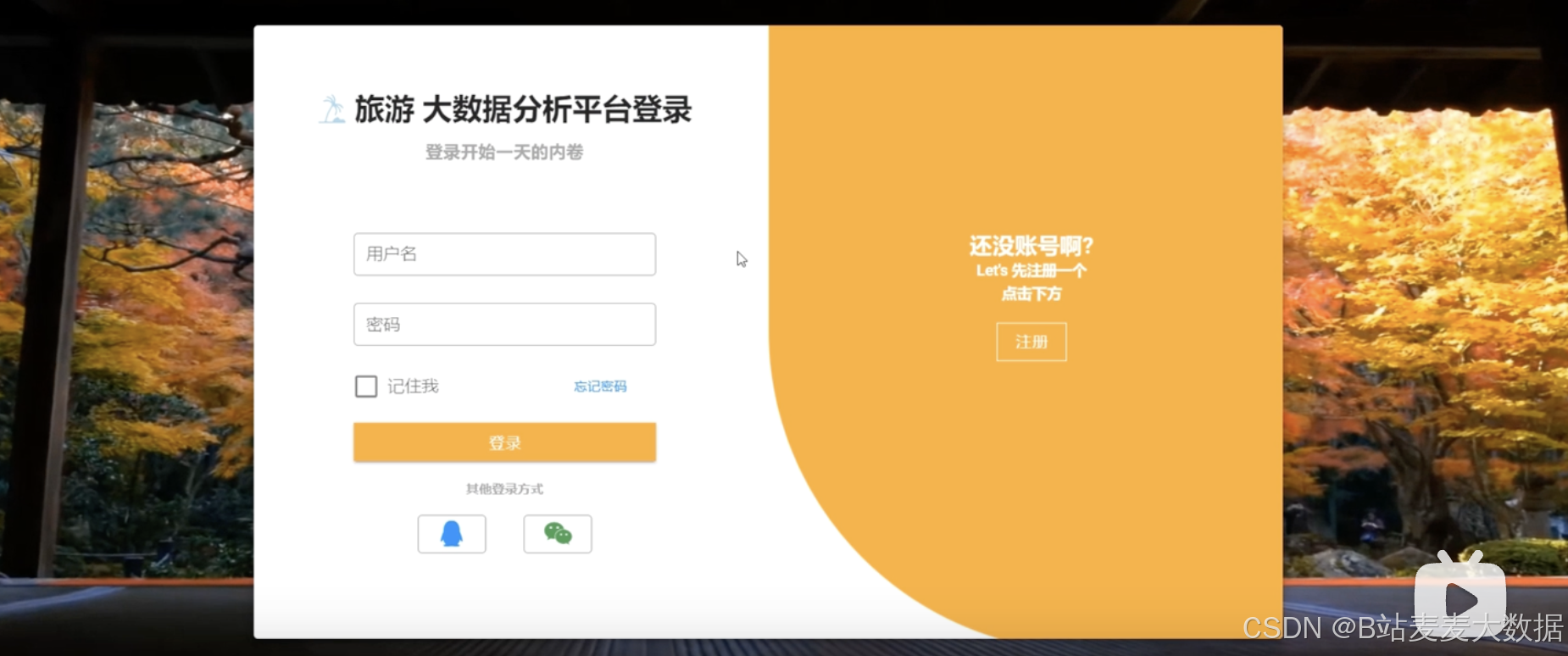
4.1 登录 (动态效果背景)
4.2 推荐算法
主页展示景点卡片 【展示图片、名称等信息】
基于usercf+itemcf 双协同过滤推荐算法的景点推荐
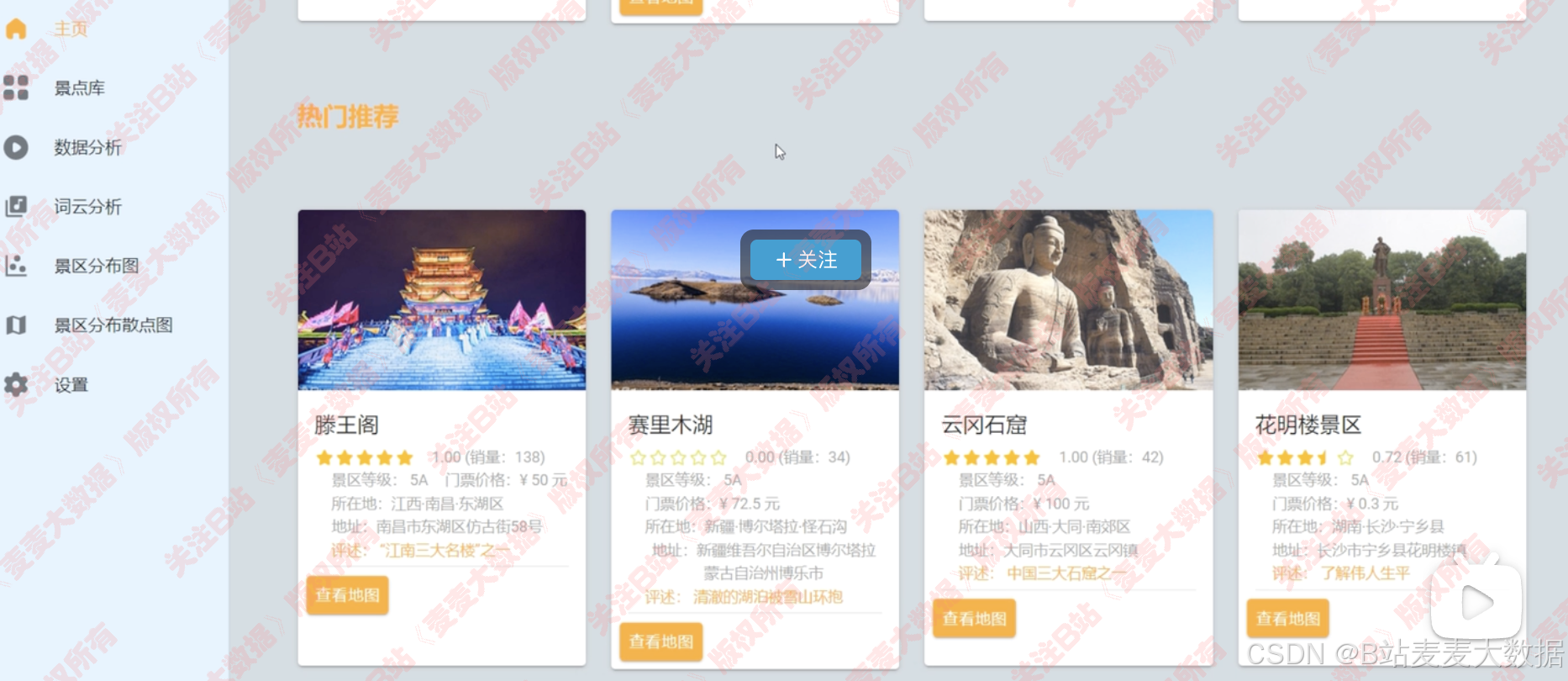
热门景点展示

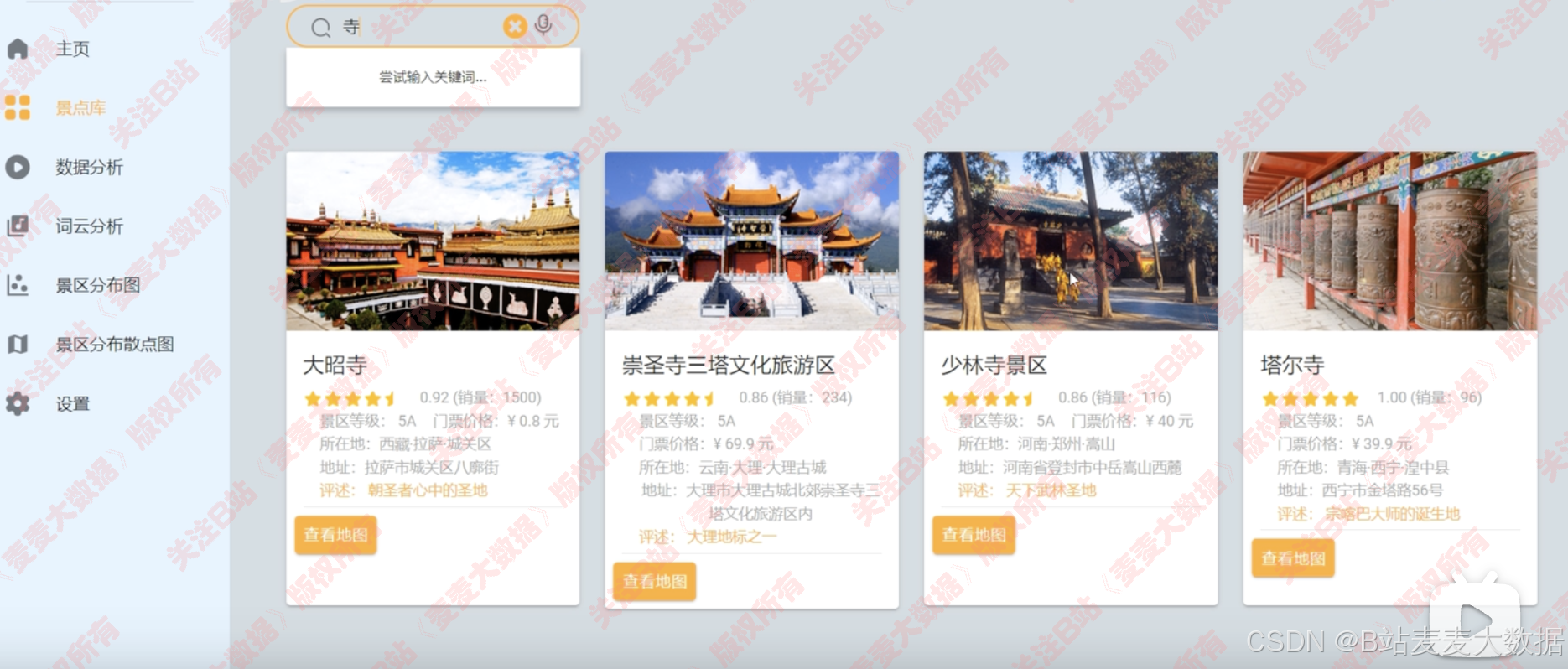
景点库可以进行模糊搜索
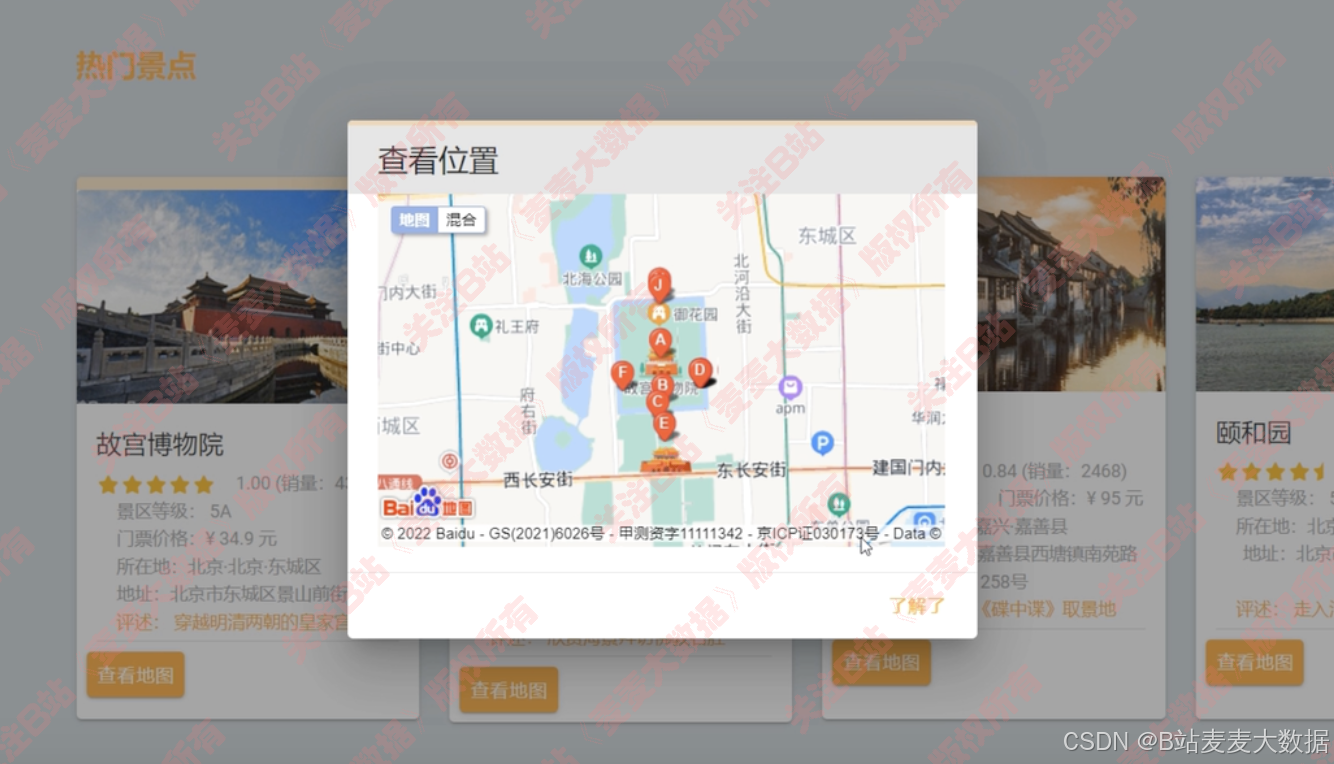
景点卡片可以点击查看具体的位置,对接百度地图方式
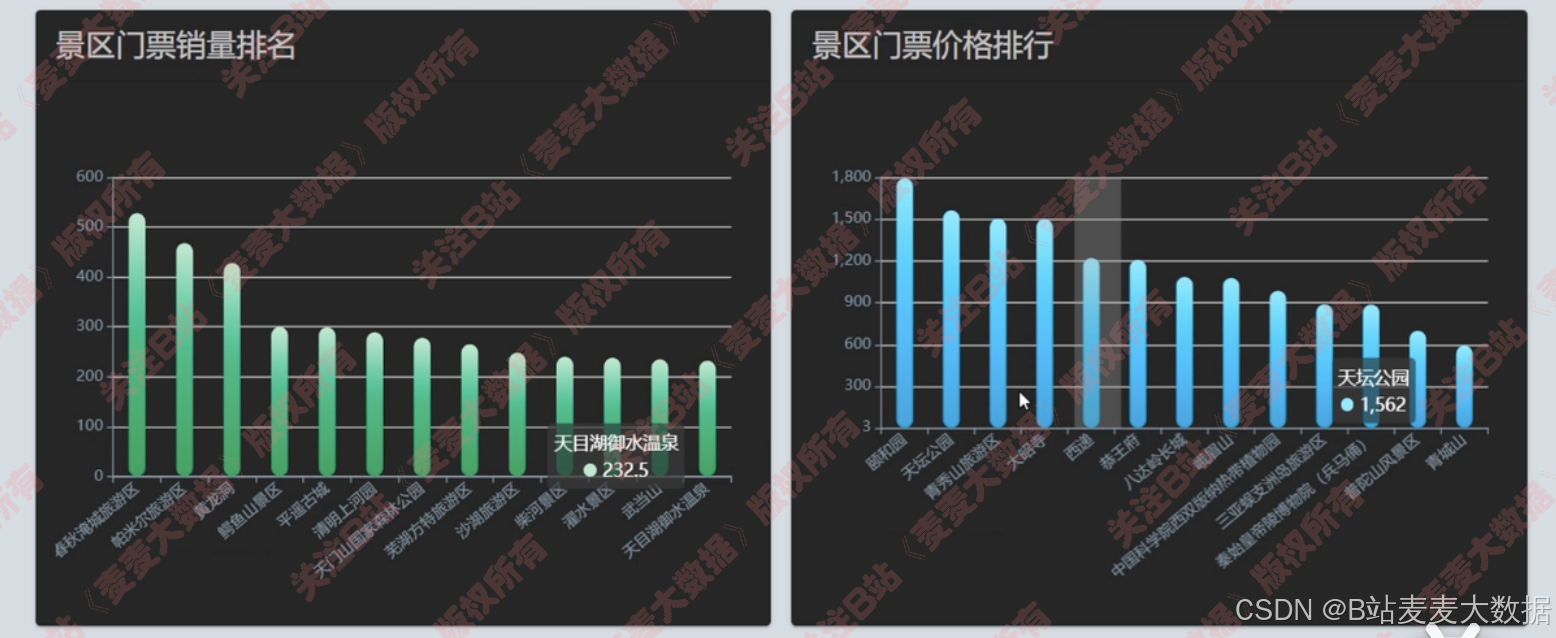
4.3 数据可视化
可视化大屏、 景点热力图、 下方是可以滚动的柱状图
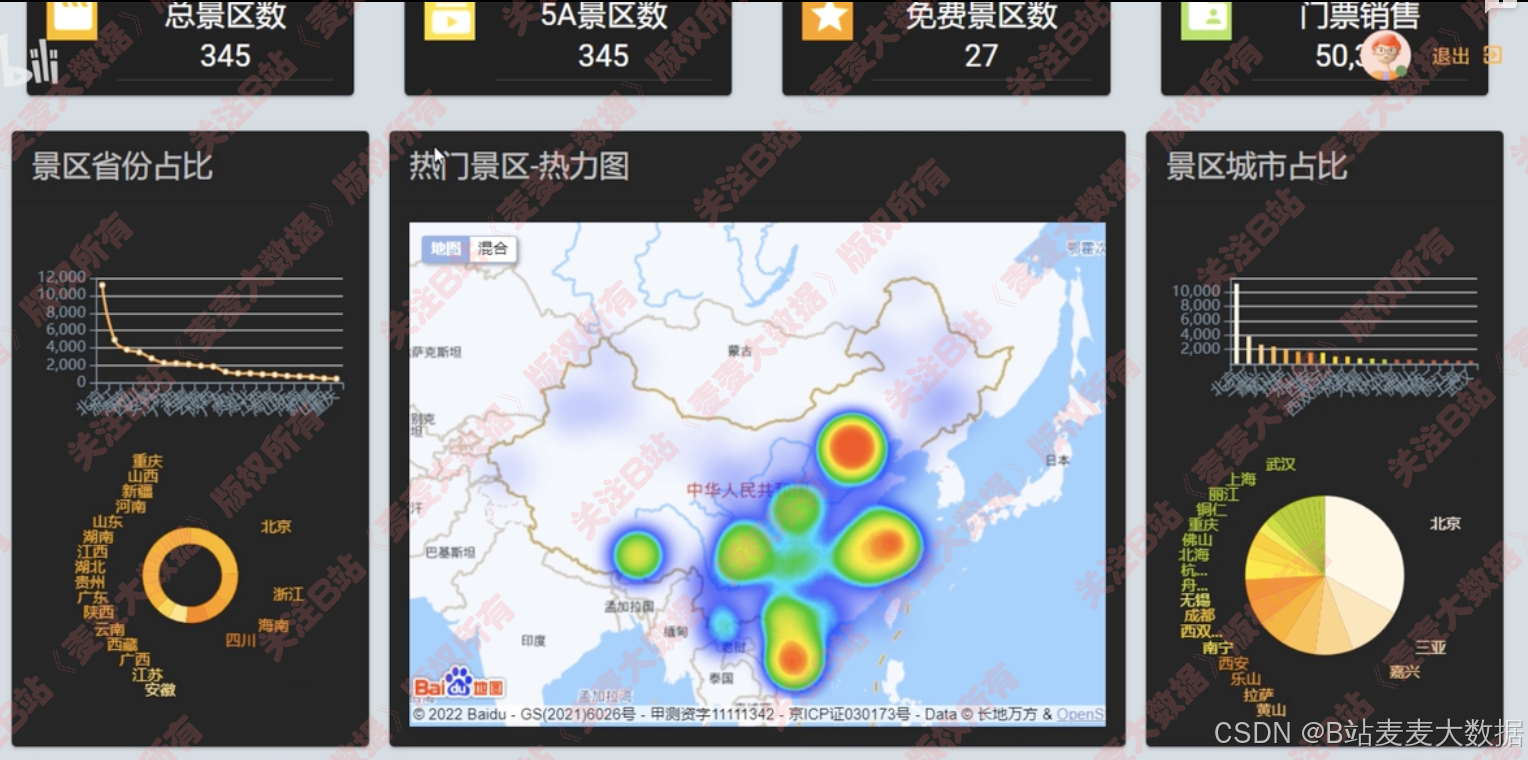
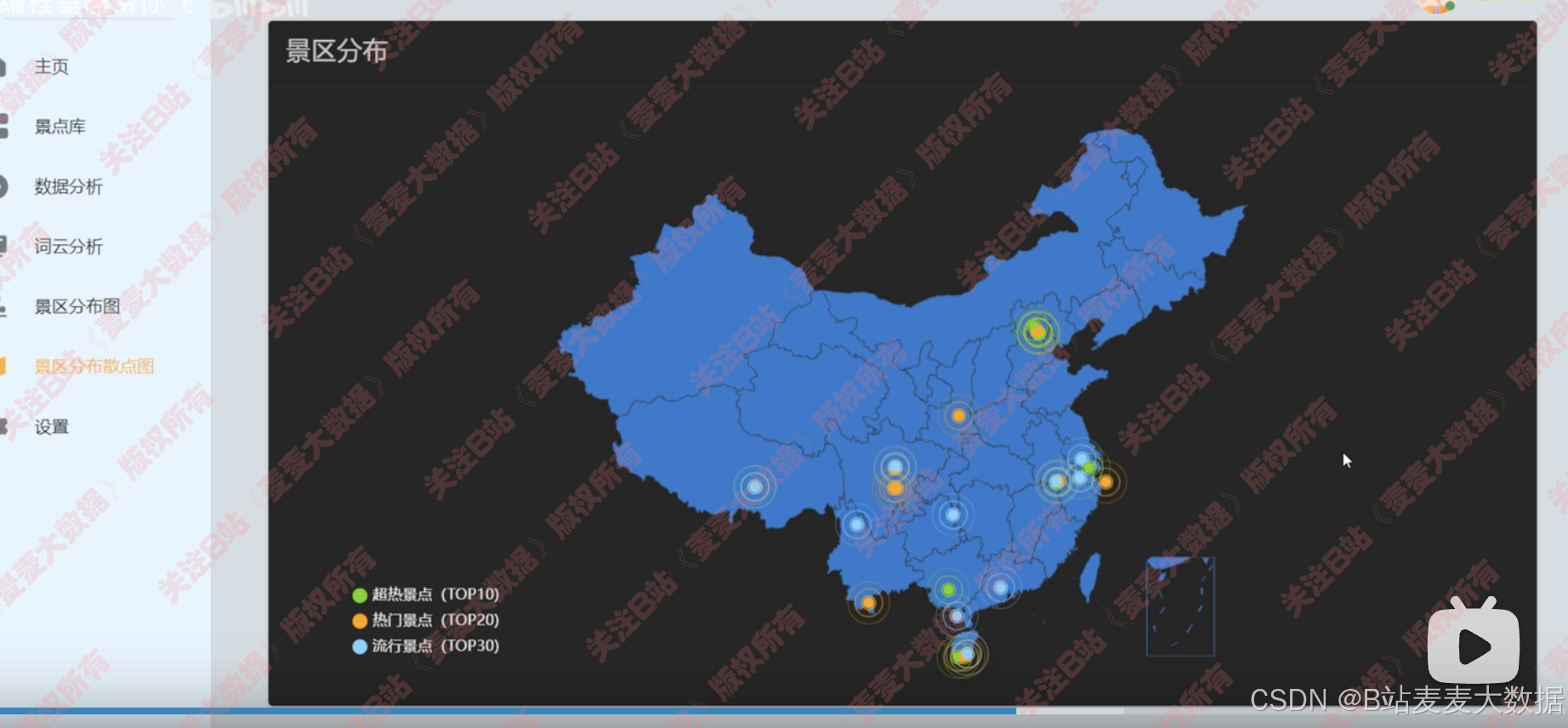
地图分析(分布热力图)

散点图+地图的分析
词云分析

4.4 个人设置
4.5 爬虫
5 开发环境和关键技术
- 服务端技术:Flask 、百度地图API、百度AI识别、支付宝沙箱支付、SQLAlchemy、MarshMallow、Blueprint 等
- 前端技术:Vue 、Echarts 、Axios、Vuex、WordCloud 等
- 爬虫技术: requests 等
- 数据库:MySQL
- 开发语言: Python 3.8 Vue 2.x
- 集成开发环境: PyCharm-2025 WebStorm-2025 Windows-11 Node-16
6 推荐算法
算法介绍:
该协同过滤推荐算法基于用户相似性为中国旅游景点提供个性化推荐。首先构建用户-景点评分矩阵,使用余弦相似度计算用户间的偏好相似性。对于目标用户,系统查找与其最相似的K个用户,通过聚合相似用户对未评分景点的评价,生成评分预测。最终推荐预测评分最高的景点。该算法能够有效解决旅游信息过载问题,帮助用户发现符合兴趣的新景点。在实际应用中,可配合在线旅游平台收集真实用户行为数据,进一步优化模型并通过A/B测试评估推荐质量。

python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
# 生成模拟数据
np.random.seed(42)
users = [f'User{i}' for i in range(1, 101)]
attractions = [
'故宫博物院', '长城', '西湖', '兵马俑', '九寨沟',
'张家界', '漓江', '黄山', '布达拉宫', '鼓浪屿'
]
# 创建用户-景点评分矩阵 (0分表示未访问)
ratings = np.zeros((len(users), len(attractions)))
for i in range(len(users)):
# 每个用户随机评价2-5个景点
rated_indices = np.random.choice(len(attractions), np.random.randint(2, 6), replace=False)
ratings[i, rated_indices] = np.random.randint(1, 6, len(rated_indices))
# 转换为DataFrame
ratings_df = pd.DataFrame(ratings, index=users, columns=attractions)
def recommend_attractions(user_id, k=3):
"""
协同过滤景点推荐
:param user_id: 目标用户ID
:param k: 使用的最相似用户数量
:return: 推荐景点列表
"""
# 计算用户相似度
user_similarity = pd.DataFrame(
cosine_similarity(ratings_df),
index=ratings_df.index,
columns=ratings_df.index
)
# 获取目标用户未评分的景点
user_idx = np.where(ratings_df.index == user_id)[0][0]
unrated_attractions = ratings_df.columns[ratings_df.iloc[user_idx] == 0]
# 预测评分
predictions = {}
for attraction in unrated_attractions:
# 找到评价过该景点的用户
rated_users = ratings_df.index[ratings_df[attraction] > 0]
# 计算加权评分
numerator = 0
denominator = 0
count = 0
# 获取k个最相似用户
similar_users = user_similarity[user_id].drop(user_id).sort_values(ascending=False)[:k]
for other_user in similar_users.index:
if other_user not in rated_users:
continue
similarity = user_similarity.loc[user_id, other_user]
rating = ratings_df.loc[other_user, attraction]
numerator += similarity * rating
denominator += abs(similarity)
count += 1
# 仅当有有效评分时才预测
if count > 0:
predicted_rating = numerator / denominator if denominator != 0 else 0
predictions[attraction] = predicted_rating
# 返回前3个推荐景点
return [attraction for attraction, _ in sorted(predictions.items(), key=lambda x: x[1], reverse=True)[:3]]
# 测试推荐系统
if __name__ == "__main__":
target_user = 'User1'
recommendations = recommend_attractions(target_user)
print(f"{target_user} 的推荐景点:")
for i, attraction in enumerate(recommendations, 1):
print(f"{i}. {attraction}")