在计算机科学的排序算法家族中,快速排序(Quick Sort)无疑是最具影响力的算法之一。它由英国计算机科学家托尼・霍尔(Tony Hoare)于 1960 年提出,凭借平均时间复杂度低、空间开销小、缓存友好等特性,成为诸多编程语言标准库(如 C++ 的std::sort、Python 的sorted)的默认排序实现。然而,快排的时间性能并非始终稳定,其在不同输入数据下的波动问题,既是算法设计的经典课题,也是工程实践中必须关注的核心要点。本文将从原理出发,拆解快排时间波动的本质,详解优化策略,并探讨其在实际场景中的应用。
一、快速排序的核心原理:分治思想的极致体现
快速排序的本质是分治策略的应用,通过 "划分 - 递归" 的循环,将大规模问题拆解为小规模子问题,最终实现整体有序。其核心步骤可概括为 "选基准、做划分、递归来" 三步,具体流程如下:
1. 核心三步:从 "无序" 到 "有序" 的拆解
- 步骤 1:选择基准(Pivot)
从当前待排序数组(或子数组)中,选择一个元素作为 "基准"。基准是快排的 "指挥棒",后续所有元素的位置调整都围绕基准展开。
- 步骤 2:划分(Partition)
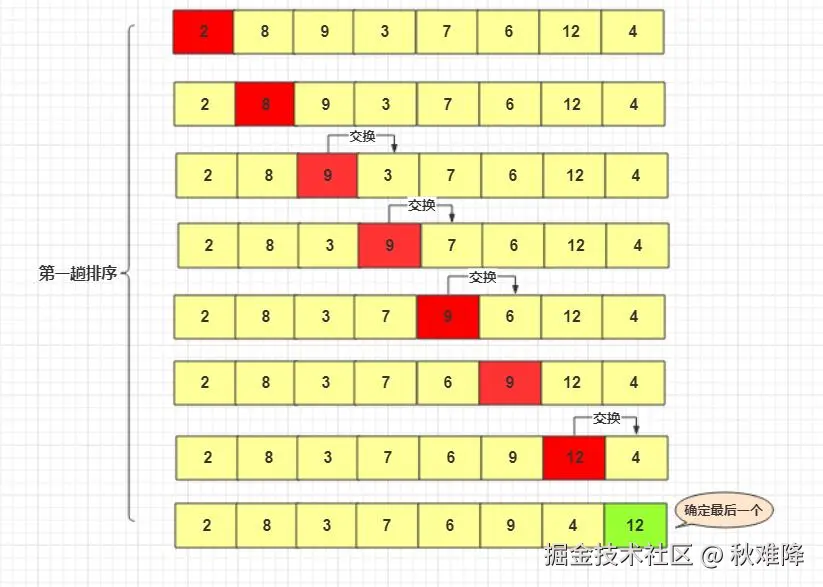
遍历数组,将所有小于基准的元素移到基准左侧,所有大于基准的元素移到基准右侧,等于基准的元素可暂归为任意一侧(普通快排)。此时,基准的位置已 "固定"------ 它在最终有序数组中的位置不再变化。
- 步骤 3:递归排序子数组
对基准左侧的 "小于子数组" 和右侧的 "大于子数组",重复上述 "选基准 - 划分" 过程,直到子数组长度为 1(天然有序)或 0(无需排序)。
2. 时间复杂度的理论基础
快排的时间复杂度由 "划分的均衡性" 直接决定:
- 理想情况 :若每次划分后,左右子数组的长度接近(如基准为当前数组的中位数),递归树的深度为log₂n(每一层处理n个元素,共log₂n层),总时间复杂度为O(n log n) 。
- 最坏情况 :若每次划分极度失衡(如基准为当前数组的最值,一侧子数组为空,另一侧为n-1个元素),递归树退化为 "单链",深度为n(每一层处理n、n-1、...、1 个元素),总时间复杂度退化为O(n²) 。
- 平均情况 :在随机分布的输入数据下,基准大概率落在数组中间区域,划分趋于均衡,平均时间复杂度为O(n log n) ,且常数项远小于同为O(n log n)的归并排序。
二、时间波动的根源:基准选择与数据特性的 "博弈"
快排时间性能的波动,本质是 "基准选择策略" 与 "输入数据分布" 相互作用的结果。看似简单的 "选基准" 步骤,直接决定了算法在不同场景下的表现。
1. 基准选择:快排的 "命门"
最朴素的快排实现(如固定选择数组首元素或尾元素作为基准),是导致时间波动的主要诱因:
- 场景 1:输入为已排序 / 逆序数组
若固定选首元素为基准,已排序数组的首元素是 "最小值",逆序数组的首元素是 "最大值"。每次划分后,一侧子数组为空,另一侧为n-1个元素,直接触发O(n²)的最坏情况。例如,对1,2,3,4,5排序时,第一次划分基准为 1,右侧子数组为2,3,4,5;第二次基准为 2,右侧子数组为3,4,5...... 以此类推,效率极低。
- 场景 2:输入含大量重复元素
普通快排会将所有等于基准的元素归到同一侧(如全部放到左侧),导致划分失衡。例如,对2,2,2,2,2排序时,若基准为中间的 2,所有元素都等于基准,左侧子数组为2,2,右侧为2,2(看似均衡),但实际每次划分都需遍历所有元素,且无法减少待排序元素数量,时间复杂度接近O(n²)。
2. 输入数据分布:波动的 "催化剂"
不同场景下的输入数据,会放大基准选择的缺陷:
- 随机分布数据:基准落在中间区域的概率高,划分均衡,时间复杂度稳定在O(n log n),这也是快排 "平均性能优秀" 的来源。
- 有序 / 接近有序数据:如数据库中的日志记录(按时间排序)、学生成绩表(按分数排序),这类数据在实际场景中极为常见,若基准选择不当,会直接暴露快排的最坏情况。
- 极端倾斜数据:如1,3,5,7,9,2(前半段有序,后半段插入一个小值),固定基准会导致前几次划分失衡,后续虽可能恢复均衡,但整体效率已受损。
3. 递归开销:波动的 "放大器"
划分失衡不仅增加计算量,还会导致递归深度异常。例如,对n=10000的有序数组,固定基准的快排递归深度可达10000,远超大多数编程语言默认的函数调用栈深度(如 Python 默认栈深度约为1000),直接引发栈溢出错误。
三、工程化优化:让快排 "稳定高效" 的实用策略
实际应用中,快排的波动问题可通过针对性优化解决。主流优化策略围绕 "基准选择""重复元素处理""递归开销""小规模数据适配" 四大方向展开,让快排在各类场景下都能稳定接近O(n log n)的性能。
1. 基准选择优化:避免 "极端值陷阱"
(1)随机化基准:用概率对抗极端情况
- 原理:从当前子数组中随机选择一个元素作为基准,而非固定首 / 尾 / 中间元素。随机选择能大幅降低选到 "最值" 的概率 ------ 对长度为n的数组,选到最值的概率仅为2/n,随着n增大,最坏情况出现的概率趋近于 0。
- 实现细节:在划分前,生成一个介于 "子数组左边界" 和 "右边界" 之间的随机索引,将该索引对应的元素与首元素(或尾元素)交换,再按固定基准的逻辑划分。例如,对1,2,3,4,5,随机选择基准可能选中 3,第一次划分后得到1,2,3,4,5(左侧1,2,右侧4,5),后续递归效率极高。
- 优势:实现简单,无需额外计算,能有效应对有序 / 逆序数据,是工程中最常用的基准优化手段。
(2)三数取中法:用 "中位数" 保证均衡
- 原理:从子数组的 "首、尾、中间" 三个位置各取一个元素,计算这三个元素的中位数,将其作为基准。例如,子数组为1,3,5,7,9,首元素 1、尾元素 9、中间元素 5,中位数为 5,直接作为基准;若子数组为1,2,3,4,5,6,首 1、尾 6、中间 3,中位数为 3,作为基准。
- 优势:比随机化基准更稳定,尤其在处理接近有序的数据时(如1,2,3,4,5,7,6),三数取中能精准选中中间值,避免划分失衡。C++ 的std::sort在处理较大数组时,就采用了三数取中法选择基准。
- 扩展:九数取中法:对超大规模数组(如n>100000),可从子数组中均匀选取 9 个元素(如首、1/8、2/8、...、尾),取其中位数作为基准,进一步降低选到极端值的概率,但实现稍复杂,适合对稳定性要求极高的场景。
2. 重复元素处理:三路划分法
针对含大量重复元素的场景,普通快排的 "二划分"(小于 / 大于)会导致失衡,而三路划分(小于 / 等于 / 大于)能从根本上解决问题:
- 原理:将数组划分为三个区域 ------"小于基准区""等于基准区""大于基准区"。递归时,仅需对 "小于区" 和 "大于区" 排序,"等于区" 已天然有序,无需再处理。
- 实现细节:
-
- 初始化三个指针:left(小于区右边界)、current(当前遍历指针)、right(大于区左边界)。
-
- 遍历数组:
-
-
- 若arrcurrent < pivot:交换arrcurrent与arrleft,left++,current++(小于区扩大)。
-
-
-
- 若arrcurrent == pivot:current++(等于区扩大)。
-
-
-
- 若arrcurrent > pivot:交换arrcurrent与arrright,right--(大于区扩大)。
-
-
- 递归处理left_start, left-1(小于区)和right+1, right_end(大于区)。
- 优势:对全重复数组(如2,2,2,2),一次划分即可完成排序,时间复杂度降至O(n);对含部分重复元素的数组(如3,1,4,1,5,9,2,6,5),能减少递归次数,效率提升显著。Python 的sorted在处理重复元素时,就融合了三路划分的思想。
3. 小规模数据优化:切换插入排序
快排的递归开销在处理小规模子数组(如n<15)时占比过高 ------ 此时,递归调用的时间可能超过排序本身的时间,而插入排序(Insertion Sort)在小规模数据上的 "常数项优势"(无需递归、缓存友好)更为明显。
- 优化方案:设定一个阈值(如10或15,需根据编程语言和硬件环境调整),当子数组长度小于阈值时,停止递归,改用插入排序;仅对长度大于阈值的子数组继续使用快排。
- 原理:插入排序的时间复杂度为O(n²),但在n较小时(如n=10),n²=100,而快排的n log n≈33,看似快排更优 ------ 但快排的 "n log n" 包含较大的常数项(递归调用、元素交换),实际运行时,插入排序在n<15时更快。例如,C++ 的std::sort默认阈值为16,当子数组长度小于16时,自动切换为插入排序。
4. 递归开销优化:尾递归消除
快排的递归深度问题,可通过 "尾递归消除" 解决。尾递归是指函数的最后一步仅调用自身,编译器可将其优化为循环,减少栈帧消耗。
- 原理:每次划分后,对 "较短的子数组" 进行递归,对 "较长的子数组" 通过循环继续处理。例如,划分后左侧子数组长度为k,右侧为n-k-1,若k < n-k-1,则递归处理左侧,右侧通过循环再次划分;反之则递归处理右侧,左侧通过循环处理。
- 优势:递归深度由 "较短子数组的长度" 决定,最坏情况下递归深度为log₂n(如n=10000时,log₂n≈14),远低于原始快排的n,彻底避免栈溢出问题。
5. 并行化优化:利用多核提升效率
在多核 CPU 或分布式系统中,快排的 "分治特性" 可被进一步利用 ------ 左右子数组的排序可并行执行,大幅提升大规模数据的排序速度。
- 实现思路:每次划分后,将左侧子数组的排序任务分配给一个线程,右侧子数组分配给另一个线程,待两个线程执行完毕后,合并结果(快排无需显式合并,因划分已保证基准位置固定)。
- 注意事项:线程创建和调度存在开销,需避免对过小的子数组并行化(通常当子数组长度大于1000时,并行化收益才明显)。
四、快排的实际应用:从理论到工程的落地
优化后的快排,凭借稳定的性能和低空间开销,成为工程实践中的 "排序首选"。以下是其典型应用场景:
1. 编程语言标准库
几乎所有主流编程语言的排序函数都以快排为核心:
- C++ std::sort:采用 "introsort"(内省排序),结合快排、堆排序和插入排序 ------ 当快排递归深度超过2*log₂n时,自动切换为堆排序(避免最坏情况),子数组长度小于16时切换为插入排序。
- Python sorted:采用 "Timsort"(蒂姆排序),融合快排的划分思想、归并排序的稳定性和插入排序的小规模优势,在实际数据上性能远超传统快排。
- Java Arrays.sort:对基本类型(如int、long)采用双轴快排(Dual-Pivot Quick Sort),对对象类型采用归并排序(保证稳定性)。
2. 大规模数据排序
在数据库、大数据处理(如 Hadoop、Spark)中,快排是核心排序算法之一。例如,数据库的 "ORDER BY" 操作,若数据无法全部加载到内存(外排序),会先将数据分块,用快排对每块排序,再通过归并排序合并块,实现高效外排序。
3. 嵌入式系统与资源受限场景
快排的空间复杂度为O(log n)(递归栈开销),远低于归并排序的O(n),适合内存有限的嵌入式系统(如智能家居设备、工业控制器)。优化后的快排(如无递归的迭代实现),还能避免栈溢出,进一步提升可靠性。
五、总结:快排的 "优" 与 "思"
快速排序的核心魅力,在于其 "分治思想" 的简洁与高效 ------ 通过合理选择基准和优化策略,能在绝大多数场景下实现O(n log n)的时间复杂度,同时保持低空间开销。其时间波动的根源并非算法缺陷,而是 "基准选择" 与 "数据特性" 的不匹配,通过工程化优化(如随机化基准、三路划分、切换插入排序),完全可将波动降至最低。
从理论到实践,快排的发展也给我们带来启示:优秀的算法不仅需要严谨的理论证明,更需要结合实际场景进行优化 ------ 毕竟,在工程中,"稳定的性能" 往往比 "理论上的最优" 更重要。无论是处理日常开发中的数据排序,还是设计大规模分布式系统的核心组件,理解快排的原理与优化逻辑,都能帮助我们做出更合理的技术选择。