深入理解原型模式:原理、实例、优缺点及模式对比
在软件开发中,创建型设计模式负责处理对象创建的机制,确保对象的创建与使用解耦,提高系统的灵活性和可维护性。原型模式作为创建型模式的重要一员,通过复制现有对象(原型)来创建新对象,避免了频繁使用构造函数创建对象带来的开销,尤其在创建复杂对象或大量相似对象时具有显著优势。本文将从原型模式的基本概念出发,结合实例代码深入分析其实现方式,探讨其优缺点,并与其他创建型模式进行对比,帮助开发者更好地理解和应用原型模式。
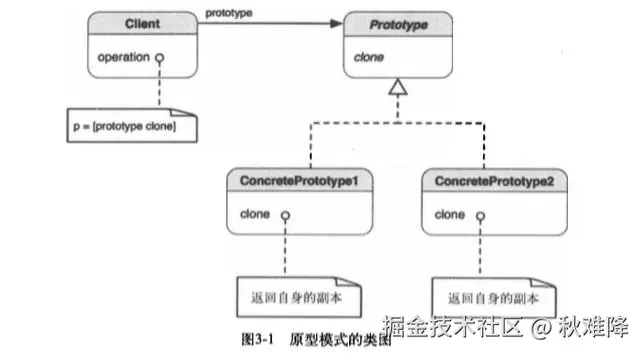
一、原型模式的定义与核心思想
1.1 定义
原型模式(Prototype Pattern)是指用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。它允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节。
1.2 核心思想
原型模式的核心在于 "克隆",即通过复制已有的对象(原型)来生成新对象。这种方式与通过构造函数创建对象不同,它跳过了对象初始化的部分步骤,直接复制原型对象的属性和状态,从而提高对象创建的效率。在原型模式中,通常会定义一个原型接口,该接口声明了克隆自身的方法,具体的原型类实现该接口,实现克隆的具体逻辑。
二、原型模式的实例代码分析
原型模式的实现主要分为浅克隆(Shallow Clone)和深克隆(Deep Clone)两种方式,下面将通过 Java 语言分别给出具体的实例代码。
2.1 浅克隆实例
浅克隆是指当原型对象被克隆时,只复制对象本身以及对象中基本数据类型的属性,而对于对象中的引用数据类型属性,只复制其引用,不复制引用指向的实际对象。也就是说,原型对象和克隆对象共享引用数据类型的属性。
2.1.1 原型接口(Prototype)
首先定义一个原型接口,该接口中声明了克隆方法clone()。
csharp
public interface Prototype {
Prototype clone();
}2.1.2 具体原型类(ConcretePrototype)
创建一个具体的原型类Student,实现Prototype接口,并重写clone()方法。该类包含基本数据类型属性id、name和引用数据类型属性address(Address类的对象)。
arduino
// 地址类(引用数据类型)
class Address {
private String city;
public Address(String city) {
this.city = city;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Address{" +
"city='" + city + ''' +
'}';
}
}
// 具体原型类:学生类
class Student implements Prototype {
private int id;
private String name;
private Address address; // 引用数据类型属性
public Student(int id, String name, Address address) {
this.id = id;
this.name = name;
this.address = address;
}
// 浅克隆实现
@Override
public Prototype clone() {
try {
// 使用Object类的clone()方法实现浅克隆
return (Student) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
// getter和setter方法
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + ''' +
", address=" + address +
'}';
}
}2.1.3 客户端测试代码
在客户端中,创建一个原型对象student1,然后通过clone()方法克隆出student2对象,并修改student2中引用数据类型属性address的city值,观察原型对象和克隆对象的变化。
csharp
public class ShallowCloneTest {
public static void main(String[] args) {
// 创建引用数据类型对象
Address address = new Address("北京");
// 创建原型对象
Student student1 = new Student(1, "张三", address);
// 克隆原型对象得到克隆对象
Student student2 = (Student) student1.clone();
System.out.println("克隆前原型对象:" + student1);
System.out.println("克隆后克隆对象:" + student2);
// 修改克隆对象中引用数据类型属性的值
student2.getAddress().setCity("上海");
System.out.println("修改克隆对象引用属性后,原型对象:" + student1);
System.out.println("修改克隆对象引用属性后,克隆对象:" + student2);
}
}2.1.4 运行结果与分析
运行上述代码,输出结果如下:
ini
克隆前原型对象:Student{id=1, name='张三', address=Address{city='北京'}}
克隆后克隆对象:Student{id=1, name='张三', address=Address{city='北京'}}
修改克隆对象引用属性后,原型对象:Student{id=1, name='张三', address=Address{city='上海'}}
修改克隆对象引用属性后,克隆对象:Student{id=1, name='张三', address=Address{city='上海'}}从结果可以看出,克隆对象student2初始时与原型对象student1的属性值完全相同。但当修改student2中address的city值后,student1的address的city值也随之改变,这说明浅克隆中原型对象和克隆对象共享引用数据类型的属性,这是浅克隆的主要特点。
2.2 深克隆实例
深克隆是指当原型对象被克隆时,不仅复制对象本身以及基本数据类型的属性,还会复制引用数据类型属性所指向的实际对象。也就是说,原型对象和克隆对象拥有各自独立的引用数据类型属性,修改其中一个对象的引用数据类型属性不会影响另一个对象。
在 Java 中,实现深克隆有多种方式,如通过重写clone()方法实现、通过序列化和反序列化实现等。下面以序列化和反序列化的方式为例,实现深克隆。
2.2.1 具体原型类(ConcretePrototype)修改
要实现序列化和反序列化,需要让相关类实现Serializable接口(标记接口,无需实现任何方法)。修改Address类和Student类,使其实现Serializable接口,并在Student类中通过序列化和反序列化的方式实现深克隆。
arduino
import java.io.*;
// 地址类(引用数据类型),实现Serializable接口
class Address implements Serializable {
private String city;
public Address(String city) {
this.city = city;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Address{" +
"city='" + city + ''' +
'}';
}
}
// 具体原型类:学生类,实现Serializable接口
class Student implements Prototype, Serializable {
private int id;
private String name;
private Address address; // 引用数据类型属性
public Student(int id, String name, Address address) {
this.id = id;
this.name = name;
this.address = address;
}
// 深克隆实现:通过序列化和反序列化
@Override
public Prototype clone() {
try {
// 序列化:将对象写入字节流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 反序列化:从字节流中读取对象(生成新对象)
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Student) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
return null;
}
}
// getter和setter方法(同浅克隆实例)
// ...(此处省略getter和setter方法,与浅克隆实例中的Student类一致)
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + ''' +
", address=" + address +
'}';
}
}2.2.2 客户端测试代码
客户端测试代码与浅克隆实例类似,创建原型对象并克隆,然后修改克隆对象的引用数据类型属性,观察结果。
csharp
public class DeepCloneTest {
public static void main(String[] args) {
// 创建引用数据类型对象
Address address = new Address("北京");
// 创建原型对象
Student student1 = new Student(1, "张三", address);
// 克隆原型对象得到克隆对象
Student student2 = (Student) student1.clone();
System.out.println("克隆前原型对象:" + student1);
System.out.println("克隆后克隆对象:" + student2);
// 修改克隆对象中引用数据类型属性的值
student2.getAddress().setCity("上海");
System.out.println("修改克隆对象引用属性后,原型对象:" + student1);
System.out.println("修改克隆对象引用属性后,克隆对象:" + student2);
}
}2.2.3 运行结果与分析
运行上述代码,输出结果如下:
ini
克隆前原型对象:Student{id=1, name='张三', address=Address{city='北京'}}
克隆后克隆对象:Student{id=1, name='张三', address=Address{city='北京'}}
修改克隆对象引用属性后,原型对象:Student{id=1, name='张三', address=Address{city='北京'}}
修改克隆对象引用属性后,克隆对象:Student{id=1, name='张三', address=Address{city='上海'}}从结果可以看出,深克隆中,修改克隆对象student2的address的city值后,原型对象student1的address的city值并未改变,这表明原型对象和克隆对象各自拥有独立的引用数据类型属性,实现了完全的克隆,这是深克隆与浅克隆的本质区别。
三、原型模式的优缺点
3.1 优点
- 提高对象创建效率:当创建一个复杂对象时,使用原型模式通过克隆现有对象来创建新对象,避免了重新执行复杂的初始化过程(如读取配置文件、数据库查询等),大大提高了对象创建的效率。例如,在一个电商系统中,创建一个包含大量商品信息的订单对象,如果每次都通过构造函数重新获取商品数据并初始化订单,会消耗较多时间和资源,而使用原型模式克隆已有的订单原型对象,则可以快速创建新的订单对象。
- 简化对象创建过程:原型模式无需知道对象创建的具体细节,只需调用原型对象的克隆方法即可创建新对象,简化了对象的创建流程。开发者无需关注对象的构造函数参数、初始化步骤等,降低了代码的复杂度。
- 灵活性高:通过原型模式,可以动态地添加或删除原型对象,并且可以根据需要修改原型对象的属性,从而创建出不同类型或不同状态的新对象。例如,在一个图形编辑软件中,可以定义不同形状(如圆形、矩形)的原型对象,用户可以根据需要克隆这些原型对象,并修改其颜色、大小等属性,得到各种个性化的图形对象。
- 便于扩展:当需要创建新类型的对象时,只需创建该类型的原型对象并实现克隆方法,无需修改现有代码,符合开闭原则(对扩展开放,对修改关闭)。
3.2 缺点
- 深克隆实现复杂:如果原型对象中包含较多的引用数据类型属性,实现深克隆会比较复杂,需要处理多层嵌套的引用对象的克隆。例如,一个对象中包含多个引用对象,而这些引用对象又包含其他引用对象,此时实现深克隆需要逐一处理每个引用对象的克隆,代码量较大,且容易出错。
- 需要为每个原型类实现克隆方法:虽然原型接口定义了克隆方法,但每个具体的原型类都需要自行实现该方法,这增加了代码的编写工作量。尤其是当系统中存在大量原型类时,维护这些克隆方法会比较繁琐。
- 克隆对象可能隐藏一些问题:由于克隆对象是通过复制原型对象得到的,可能会继承原型对象中的一些隐藏状态或依赖关系,这些问题在克隆后可能会暴露出来,增加了代码调试的难度。例如,原型对象中存在一个与外部资源(如文件句柄、网络连接)相关的属性,克隆对象会共享该资源引用,可能导致资源竞争或释放问题。
四、原型模式与其他创建型模式的对😘😘😘😘😘😘😘😘😘😘😘
创建型模式除了原型模式外,还包括单例模式、工厂方法模式、抽象工厂模式和建造者模式。这些模式各有特点,适用于不同的场景,下面将从创建对象的方式、适用场景、灵活性等方面对原型模式与其他创建型模式进行对比。
4.1 与单例模式对比
- 创建对象的方式:
-
- 原型模式:通过克隆现有原型对象来创建新对象,每次克隆都会生成一个新的对象实例(除非在克隆方法中做特殊限制)。
-
- 单例模式:确保一个类只有一个实例,并提供一个全局访问点来获取该实例,不允许创建多个对象实例。
- 适用场景:
-
- 原型模式:适用于创建复杂对象、创建大量相似对象或需要动态扩展对象类型的场景。例如,在游戏开发中,创建大量相同类型但属性略有差异的敌人对象时,使用原型模式可以快速生成敌人实例。
-
- 单例模式:适用于系统中只需要一个实例的场景,如配置管理类、日志记录类、数据库连接池等。例如,一个系统的配置信息只需要加载一次,使用单例模式可以确保配置管理类只有一个实例,避免重复加载配置。
- 灵活性:
-
- 原型模式:灵活性较高,可以通过修改原型对象的属性或添加新的原型对象来创建不同类型或状态的对象,易于扩展。
-
- 单例模式:灵活性较低,一旦单例类被定义,其实例是固定的,无法动态创建新的实例或修改实例的类型(除非修改单例类的代码)。
4.2 与工厂方法模式对比
- 创建对象的方式:
-
- 原型模式:通过克隆原型对象创建新对象,对象的创建依赖于已有的原型实例,无需定义专门的工厂类。
-
- 工厂方法模式:通过定义工厂接口和具体工厂类,由具体工厂类负责创建相应的产品对象,对象的创建依赖于工厂类,需要为每种产品类型创建对应的工厂类。
- 适用场景:
-
- 原型模式:适用于对象创建成本较高、对象结构复杂或需要动态生成对象的场景。例如,在一个报表系统中,生成一份复杂的报表需要读取大量数据并进行复杂计算,使用原型模式克隆已有的报表原型对象,可以快速生成新的报表。
-
- 工厂方法模式:适用于需要创建多种产品对象,且客户端不需要知道产品创建细节的场景。例如,在一个日志系统中,需要支持多种日志输出方式(如文件日志、控制台日志),可以定义日志工厂接口和具体的日志工厂类(文件日志工厂、控制台日志工厂),由客户端根据需要选择对应的工厂类创建日志对象。
- 代码复杂度:
-
- 原型模式:代码相对简单,只需定义原型接口和具体原型类,并实现克隆方法即可,无需额外的工厂类。
-
- 工厂方法模式:代码复杂度较高,需要定义产品接口、具体产品类、工厂接口和具体工厂类,类的数量较多,当产品类型较多时,代码维护成本较高。
4.3 与抽象工厂模式对比
- 创建对象的方式:
-
- 原型模式:专注于单个对象的克隆创建,每次克隆只生成一个对象实例,不涉及对象族的创建。
-
- 抽象工厂模式:用于创建一系列相关或相互依赖的对象族(一组对象),由抽象工厂类定义创建对象族的接口,具体工厂类实现该接口,创建对应的对象族。
- 适用场景:
-
- 原型模式:适用于创建独立的、相似的对象,不强调对象之间的关联性。例如,创建多个独立的用户对象,每个用户对象的属性(如姓名、年龄)可以通过克隆