正则表达式基础语法
Java正则表达式基于java.util.regex包,核心类是Pattern和Matcher。基本语法遵循标准正则规范:
.匹配任意单个字符(除换行符)\d匹配数字,等价于[0-9]\w匹配单词字符,等价于[a-zA-Z0-9_]\s匹配空白字符(空格、制表符等)[]字符集合,如[abc]匹配a、b或c^在字符集中表示否定,如[^abc]匹配非a/b/c的字符*匹配前一个元素0次或多次+匹配前一个元素1次或多次?匹配前一个元素0次或1次{n}精确匹配n次{n,}匹配至少n次{n,m}匹配n到m次- | 写在方括号外面,表示或
- && 交集,表示与
- (?!) 忽略后面字符的大小写
常用预定义字符类
\\d 数字 [0-9]
\\D 非数字 [^0-9]
\\s 空白字符 [ \\t\\n\\x0B\\f\\r]
\\S 非空白字符 [^\\s]
\\w 单词字符 [a-zA-Z_0-9]
\\W 非单词字符 [^\\w]边界匹配符
^匹配行首$匹配行尾\b匹配单词边界\B匹配非单词边界
Java中的特殊处理
在Java字符串中需要使用双反斜杠转义:
java
// 匹配数字的正则表达式
String regex = "\\d+"; // 实际表示 \d+Pattern和Matcher使用示例
java
import java.util.regex.*;
String text = "Hello 123 World";
// Pattern:表示正则表达式
Pattern pattern = Pattern.compile("\\d+");
// Matcher:文本匹配器,从头开始读取,直到读取到匹配的字符串
Matcher matcher = pattern.matcher(text);
// 查找匹配
while (matcher.find()) {
System.out.println("Found: " + matcher.group());
}
// 匹配整个字符串
boolean isMatch = Pattern.matches("Hello.*", text);- 贪婪爬取:用+,*,表示尽可能多的获取数据
- 非贪婪爬取:在+,*后面加上?,表示尽可能少的获取数据
java
String str = "aaaaaaaaaabbbbbbbbaaaaaaaaa";
System.out.println("--------- 贪婪匹配 ---------");
// 贪婪匹配
Pattern p = Pattern.compile("ab+");
Matcher m = p.matcher(str);
while (m.find()) {
System.out.println(m.group());
}
System.out.println("--------- 懒惰匹配 ---------");
// 懒惰匹配
Pattern p1 = Pattern.compile("ab+?");
Matcher m1 = p1.matcher(str);
while (m1.find()) {
System.out.println(m1.group());
}效果图:

分组和捕获
使用()创建捕获组:
java
String str = "a123a";
String str1 = "abc123abc";
String str2 = "1117891111";
String str3 = "aa7879a";
// 捕获分组
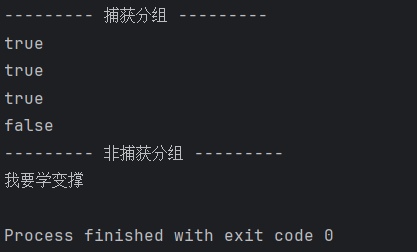
System.out.println("--------- 捕获分组 ---------");
String regex = "(.).+\\1";
String regex1 = "(.+).+\\1";
String regex2 = "((.)\\2).+\\1";
System.out.println(str.matches(regex));
System.out.println(str1.matches(regex1));
System.out.println(str2.matches(regex2));
System.out.println(str3.matches(regex2));
// 非捕获分组
System.out.println("--------- 非捕获分组 ---------");
String str4 = "我要学学变变变变撑撑撑撑撑";
str4 = str4.replaceAll("(.)\\1+", "$1");// replaceAll() 方法用于把所有满足匹配的字符串替换成指定的字符串
System.out.println(str4);效果图:
- 从1开始,连续不断
- 以左括号为基准
- 捕获分组(默认):① 内部:\\组号 ② 外部:$组号(组号会保留下来)
- 非捕获分组:使用条件,不占组号
- "?=":表示任一数据
- "?:":表示所有数据
- "?!":表示不包含这些数据
常用正则表达式示例
- 邮箱验证:
java
String emailRegex = "^[\\w-_.+]*[\\w-_.]@([\\w]+\\.)+[\\w]+[\\w]$";- 手机号验证(中国大陆):
java
String phoneRegex = "^1[3-9]\\d{9}$";- 身份证号验证(简易版):
java
String idCardRegex = "^[1-9]\\d{5}(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\\d|3[01])\\d{3}[0-9Xx]$";- URL验证:
java
String urlRegex = "^(https?://)?([\\w-]+\\.)+[\\w-]+(/[\\w-./?%&=]*)?$";特殊匹配模式
通过Pattern的常量设置匹配模式:
java
// 不区分大小写匹配
Pattern.CASE_INSENSITIVE
// 多行模式(^和$匹配每行的开头和结尾)
Pattern.MULTILINE
// 示例:不区分大小写匹配
Pattern.compile("hello", Pattern.CASE_INSENSITIVE).matcher("Hello").find(); // true字符串替换
使用正则表达式进行字符串替换:
java
String text = "a1b2c3";
String replaced = text.replaceAll("\\d", "-"); // a-b-c-性能优化建议
- 预编译常用正则表达式:
java
private static final Pattern EMAIL_PATTERN = Pattern.compile(emailRegex);-
避免过度使用
.通配符,尽可能明确匹配范围 -
对于简单固定字符串匹配,优先使用
String.contains()或String.startsWith()等原生方法 -
谨慎使用回溯量大的表达式(如嵌套的量词)