📚 微调系列文章
一文了解微调技术的发展与演进
一文搞懂 LoRA 如何高效微调大模型
LoRA详细步骤解析 一文搞懂如何用 QLoRA 高效微调大语言模型
一文理解 AdaLoRA 动态低秩适配技术
一文理解提示微调(Prefix Tuning/Prompt Tuning/P Tuning)
随着大模型能力不断提升,单纯依赖监督微调难以满足复杂的人类偏好需求。强化学习,尤其是 PPO(Proximal Policy Optimization),成为调优模型生成行为 、提升输出质量 和对齐性的关键技术。
阅读本文时,请带着这三个问题思考:
- PPO 为什么成为强化学习中的主流算法?
- PPO 的核心原理和算法流程是什么?
- 在大模型微调中如何有效应用 PPO?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、PPO 背景与意义
强化学习通过奖励信号优化策略,适合训练生成模型以符合复杂目标。然而传统强化学习算法如 TRPO 复杂难调,训练不稳定。
PPO是OpenAI 2017年提出的一种强化学习算法,简化了约束策略更新的方式,保证训练稳定且高效,广泛应用于大模型的 RLHF 微调阶段。
二、PPO 的核心原理与流程
我们在上学的时候,如果老师采取非常极端的教学方式,有时候极度表扬,有时候又极度训斥,是不是容易让我们产生厌学的情绪,一个好的老师是会使用温和的教学方式,每次指导学生进步一点点。PPO的核心思想也就类似温和的老师,它认为在更新模型的生成策略时,更新的步伐不应该过大。
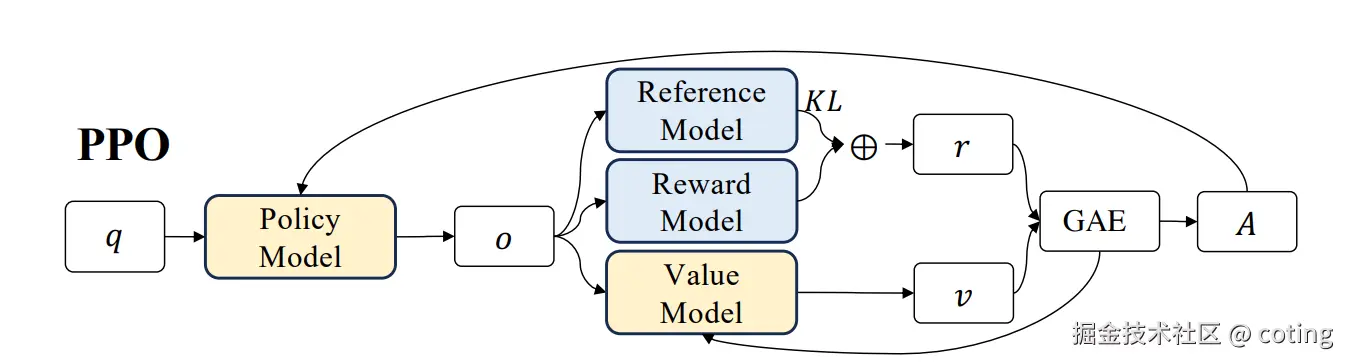
1. 代理策略与旧策略
PPO 维护两个策略:当前策略 (agent)和旧策略。

训练时用采集的数据估计策略改变量,限制新旧策略的差异,防止训练"跳变"过大导致性能崩溃。
为了在不重复交互的前提下评估新策略表现,引入概率比率
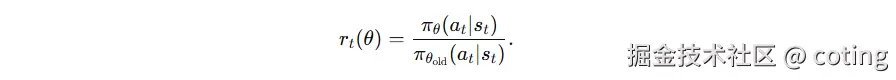
这个比率告诉我们:在新策略下,样本中这些动作"应不应该被更鼓励"。
2. 剪切目标函数(Clipped Objective)
PPO 引入剪切函数限制策略概率比率(ratio)在 1-ε, 1+ε 之间波动,平衡探索与稳定。
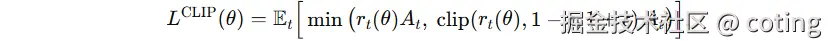
目标函数为 clipped surrogate objective,避免更新幅度过大。
3.优势函数
优势 At 衡量"该动作比平均策略好多少"。PPO 通常用 GAE(λ):
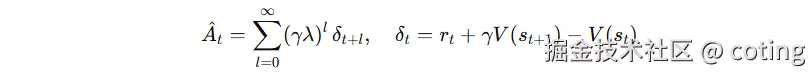
- γ:折扣因子(长期回报权重)
- λ:偏差-方差折中(0 更"短视"、1 更"长视")
- 实操里对 A^ 做均值方差归一化,提升数值稳定。
4. 算法步骤
- 采集行为数据(模型生成文本及奖励)
- 计算优势函数(Advantage Estimate)
- 优化 clipped 目标函数更新策略参数
- 多次迭代,确保策略逐步提升
三、PPO 的示例代码
python
# 初始化 policy πθ 和 value function Vϕ
for iteration in training_steps:
trajectories = collect_data(policy=πθ, env=environment)
# 计算优势函数 A(s, a)
advantages = compute_advantages(trajectories, Vϕ)
# PPO 目标函数
ratio = πθ(a|s) / πθ_old(a|s)
clipped = clip(ratio, 1 - ε, 1 + ε) * advantages
loss_policy = -min(ratio * advantages, clipped)
# 更新策略和价值函数
θ = θ - lr * ∇loss_policy
ϕ = update_value_function(trajectories, Vϕ)四、PPO 的优势与挑战
优势
- 训练稳定,收敛快,易于实现。
- 适应性强,能处理复杂的连续动作空间。
- 成为强化学习领域标配,社区支持丰富。
挑战
- 超参数较多,需要精细调优。
- 计算资源消耗较大,训练成本高。
- 训练过程对奖励模型质量依赖强。
五、PPO使用建议
- 合理选择剪切阈值 ε 和 KL 惩罚系数,保证训练平滑。
- 结合监督预训练模型进行初始化,提升训练效率。
- 监控训练指标,防止奖励过拟合和模式坍缩。
- 配合高质量人类偏好数据,确保训练信号有效。
最后我们回答一下文章开头提出的三个问题:
- PPO 为什么成为强化学习中的主流算法?
因为它设计了简单而有效的策略更新约束,平衡了训练稳定性和性能提升,解决了传统算法难调的难题。 - PPO 的核心原理和算法流程是什么?
通过剪切目标函数限制策略更新步幅,采用优势函数估计,多轮迭代优化策略,稳健提升性能。 - 在大模型微调中如何有效应用 PPO?
利用奖励模型作为反馈,结合 KL 散度约束,细致调参和监控,确保模型生成更符合人类期望。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!
以上内容部分参考了相关开源文档与社区资料。非常感谢,如有侵权请联系删除!