写在前面
在人工智能技术飞速发展的今天,如何快速构建一个实用的智能问答系统成为了许多开发者关注的重点。本文将介绍如何利用Dify和Neo4j图数据库,构建一个基于菜谱知识的RAG(Retrieval Augmented Generation)系统,帮助读者掌握从数据准备到系统实现的全流程。
一句话概括
使用Dify+Neo4j构建菜谱智能问答系统。
数据准备
我们从上海人工智能实验室下载菜谱数据集,使用openxlab工具进行数据获取。 opendatalab.com/OpenDataLab...
首先需要安装openxlab库:
bash
pip install openxlab #安装
pip install -U openxlab #版本升级
openxlab login #进行登录,输入对应的AK/SK
openxlab dataset info --dataset-repo OpenDataLab/XiaChuFang_Recipe_Corpus #数据集信息及文件列表查看
openxlab dataset get --dataset-repo OpenDataLab/XiaChuFang_Recipe_Corpus #数据集下载
openxlab dataset download --dataset-repo OpenDataLab/XiaChuFang_Recipe_Corpus --source-path /README.md --target-path /path/to/local/folder #数据集文件下载下载完成后,我们会获得一个名为recipe_corpus_full.json的JSON文件,其中包含了丰富的菜谱信息,包括菜名、食材、制作步骤等关键数据。
知识图谱构建
Neo4j环境搭建
我们使用Docker快速部署Neo4j图数据库:
ini
docker run -itd \
--name neo4j \
-p 7474:7474 \
-p 7687:7687 \
-e NEO4J_dbms_memory_transaction_total_max=4G \
-e NEO4JLABS_PLUGINS='["apoc"]' \
-e NEO4J_apoc_import_file_enabled=true \
-e NEO4J_AUTH=neo4j/neo4j123456 \
neo4j:5.23.0参数说明:
-
--name neo4j:为容器指定名称
-
-p 7474:7474:映射HTTP端口
-
-p 7687:7687:映射Bolt协议端口
-
-e NEO4J_dbms_memory_transaction_total_max=4G:限制事务内存最大为4GB
-
-e NEO4JLABS_PLUGINS='"apoc"':启用APOC插件
-
-e NEO4J_apoc_import_file_enabled=true:启用文件导入功能
-
-e NEO4J_AUTH=neo4j/neo4j123456:设置数据库用户名和密码
neo4j安装可参考:【深度探索】图数据库Neo4j:从Docker轻松安装到APOC数据导入的全栈指南
数据导入
将下载的菜谱数据复制到容器中:
bash
docker cp recipe_corpus_full.json neo4j:/var/lib/neo4j/import/执行以下Cypher查询创建知识图谱:
php
// 加载JSON数据并创建Recipe节点及基础属性
CALL apoc.load.json("file:///recipe_corpus_full.json") YIELD value
UNWIND value AS recipe
CREATE (r:Recipe {
name: recipe.name,
dish: recipe.dish,
description: recipe.description,
author: recipe.author,
instructions: recipe.recipeInstructions
})
// 创建Ingredient节点并建立关系
WITH recipe, r
UNWIND recipe.recipeIngredient AS ingredient
MERGE (i:Ingredient {name: ingredient})
CREATE (r)-[:CONTAINS]->(i)
// 创建Keyword节点并建立关系
WITH recipe, r
UNWIND recipe.keywords AS keyword
MERGE (k:Keyword {name: keyword})
CREATE (r)-[:BELONGS_TO]->(k)数据验证
使用以下查询验证数据导入情况:
scss
MATCH (n) RETURN labels(n) AS NodeLabels, COUNT(*) AS NodeCount也可以通过API方式查询:
vbnet
curl -X POST "http://localhost:7474/db/neo4j/tx/commit" \
-H "Authorization: Basic bmVvNGo6bmVvNGoxMjM0NTY=" \
-H "Content-Type: application/json" \
-d '{
"statements": [{
"statement": "MATCH (n) RETURN n, labels(n) as labels",
"parameters": {}
}]
}'其中bmVvNGo6bmVvNGoxMjM0NTY=是user_name/password的base64编码结果
Dify chatflow实现
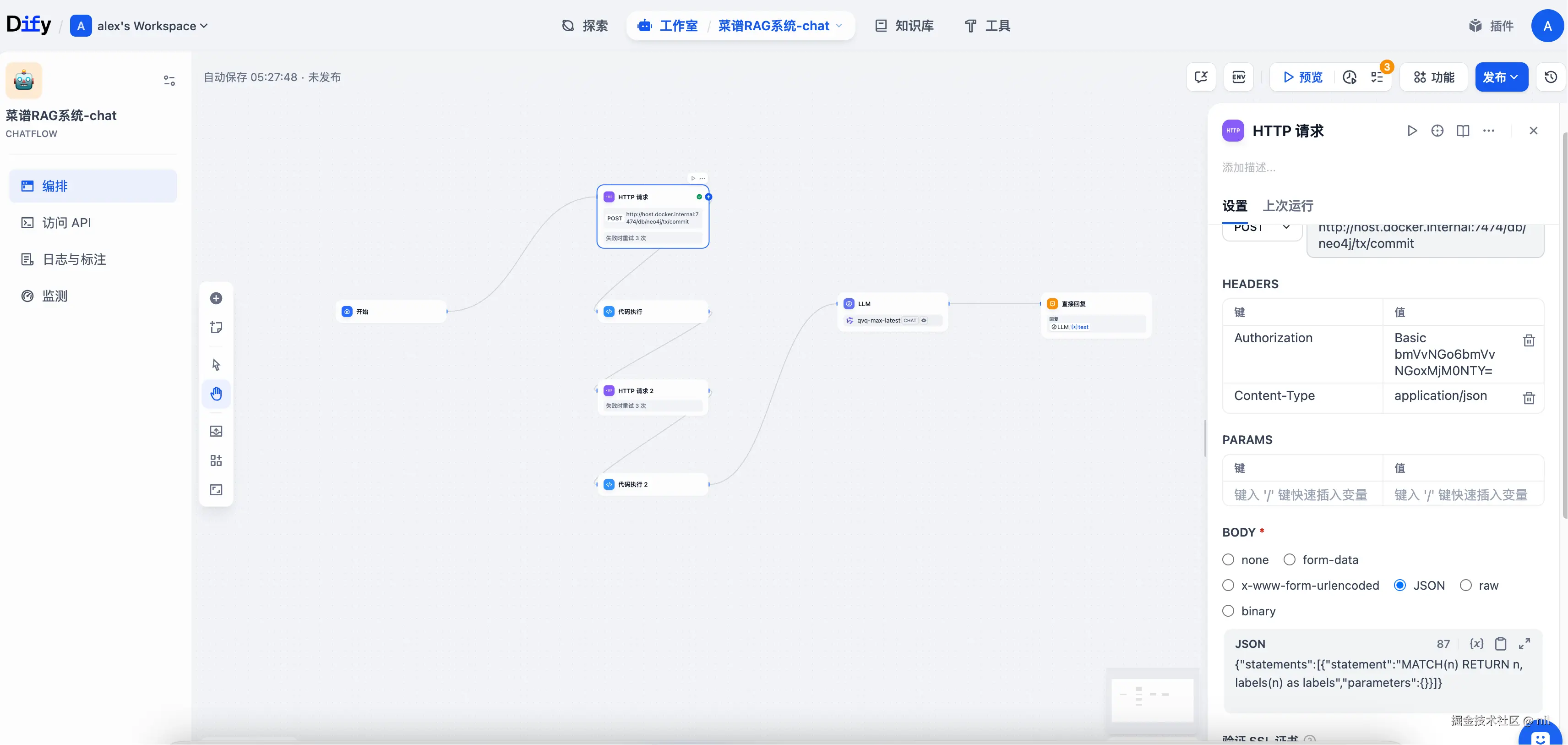 我们在Dify中构建一个包含7个节点的chatflow:
我们在Dify中构建一个包含7个节点的chatflow:
-
1.开始节点 接收用户输入的菜谱相关问题
-
2.HTTP节点 查询Neo4j数据库中相关的实体:
swift
curl -X POST "http://host.docker.internal:7474/db/neo4j/tx/commit" \
-H "Authorization:Basic bmVvNGo6bmVvNGoxMjM0NTY=" \
-H "Content-Type: application/json" \
-d "{\"statements\":[{\"statement\":\"MATCH(n) RETURN n, labels(n) as labels\",\"parameters\":{}}]}"-
3.过滤出包含用户输入的实体
-
4.查询这些实体的关联关系和属性
-
5.将相关信息拼接起来
-
6.调用大模型节点 整合查询到的信息,输出自然语言回答:
makefile
你是一个专业的厨师助手,请根据以下菜谱信息回答用户的问题。
菜谱信息:
{knowledge}
用户问题: {user_input}
请提供专业、详细的回答:- 7.直接回复节点 将大模型生成的回答返回给用户
总结
通过本文的介绍,我们完成了从数据准备、知识图谱构建到Dify chatflow实现的完整流程。这个基于菜谱的RAG系统不仅能够准确回答用户关于菜谱的各类问题,还展示了如何将图数据库与大语言模型有效结合。
这种架构可以轻松扩展到其他领域,只需更换数据源和调整Cypher查询即可