
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT),经海量数据训练后能完成文本生成、图像创作等复杂任务,显著提升效率,但面临算力消耗、数据偏见等挑战。当前正加速与教育、科研融合,未来需平衡技术创新与伦理风险,推动可持续发展。
文章目录
前言
随着AI技术蓬勃发展,大语言模型成为产业变革的核心引擎。DeepSeek凭借其出色的自然语言理解能力,在智能交互领域大放异彩。它不仅能精准解析语言背后的深层含义,还能以智能、高效的方式响应需求,为行业创新注入新活力。从智能客服到内容创作,DeepSeek-V3.1正持续赋能,推动着人机交互迈向更智能、更人性化的新高度。
基于蓝耘元生代智算云强大的分布式算力支持,本文将深入探讨蓝耘MaaS(Model as a Service)平台的特点和优势,分享蓝耘MaaS平台与DeepSeek-V3.1模型的融合亮点及应用拓展实例,并提供了API工作流调用相关使用技巧和实践体验。
一、DeepSeek-V3.1模型简介
据DeepSeek官方介绍,DeepSeek-V3.1是一款集思考与非思考模式于一体的混合型模型。用户可以根据实际需求,灵活切换这两种模式,从而在效率和能力之间找到最佳平衡点。这一创新设计,无疑为用户带来了更加便捷和高效的使用体验。
DeepSeek-V3.1在多个方面均取得了显著进步。得益于深度优化的训练策略和大规模长文档扩展,该模型在推理速度、工具调用智能、代码和数学任务处理等方面均表现出色。据官方公布的测试结果显示,DeepSeek-V3.1在AIME 2025(美国数学邀请赛2025版)、GPQA Diamond(高难度研究生级知识问答数据集的Diamond子集)以及LiveCodeBench(实时编码基准)等多个基准测试中的得分均优于老模型R1-0528。
尤为DeepSeek-V3.1在输出tokens数量上实现了大幅减少,同时保持了相似或略高的准确率。这意味着该模型在计算资源优化方面取得了显著优势,为用户节省了宝贵的计算资源。
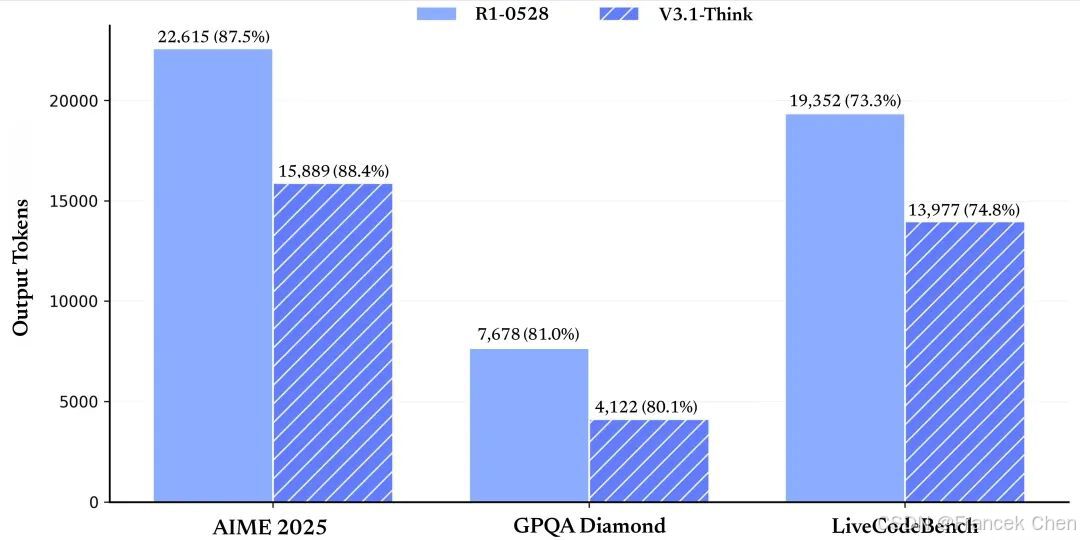
图1 R1-0528和V3.1-Think的输出tokens对比
在软件工程和Agent任务基准上,DeepSeek-V3.1同样表现出色。在SWE-Bench Verified测试中,该模型得分66.0%,远高于V3-0324和R1-0528。在多语言版本的SWE-Bench测试中,DeepSeek-V3.1也取得了54.5%的高分,显示出其在多语言支持方面的显著进步。而在Terminal-Bench测试中,该模型得分31.3%,同样优于前代模型,展现了其在Agent框架下效率的大幅提升。
DeepSeek-V3.1的这次更新,不仅增强了模型的智能体能力,还在搜索Agent、长上下文理解、事实问答和工具使用等领域展现了强劲性能。基于MoE架构的DeepSeek-V3.1(总参数671B,激活37B)在大多数基准上均显著优于R1-0528,尤其在工具使用和事实QA中领先,为构建AI Agent应用提供了有力支持。
DeepSeek-V3.1性能评估如表1所示。
表1 DeepSeek-V3.1性能评估
| Category | Benchmark (Metric) | DeepSeek V3.1-NonThinking | DeepSeek V3 0324 | DeepSeek V3.1-Thinking | DeepSeek R1 0528 |
|---|---|---|---|---|---|
| General | |||||
| MMLU-Redux (EM) | 91.8 | 90.5 | 93.7 | 93.4 | |
| MMLU-Pro (EM) | 83.7 | 81.2 | 84.8 | 85.0 | |
| GPQA-Diamond (Pass@1) | 74.9 | 68.4 | 80.1 | 81.0 | |
| Humanity's Last Exam (Pass@1) | - | - | 15.9 | 17.7 | |
| Search Agent | |||||
| BrowseComp | - | - | 30.0 | 8.9 | |
| BrowseComp_zh | - | - | 49.2 | 35.7 | |
| Humanity's Last Exam (Python + Search) | - | - | 29.8 | 24.8 | |
| SimpleQA | - | - | 93.4 | 92.3 | |
| Code | |||||
| LiveCodeBench (2408-2505) (Pass@1) | 56.4 | 43.0 | 74.8 | 73.3 | |
| Codeforces-Div1 (Rating) | - | - | 2091 | 1930 | |
| Aider-Polyglot (Acc.) | 68.4 | 55.1 | 76.3 | 71.6 | |
| Code Agent | |||||
| SWE Verified (Agent mode) | 66.0 | 45.4 | - | 44.6 | |
| SWE-bench Multilingual (Agent mode) | 54.5 | 29.3 | - | 30.5 | |
| Terminal-bench (Terminus 1 framework) | 31.3 | 13.3 | - | 5.7 | |
| Math | |||||
| AIME 2024 (Pass@1) | 66.3 | 59.4 | 93.1 | 91.4 | |
| AIME 2025 (Pass@1) | 49.8 | 51.3 | 88.4 | 87.5 | |
| HMMT 2025 (Pass@1) | 33.5 | 29.2 | 84.2 | 79.4 |
- 搜索智能体使用我们内部的搜索框架进行评估,该框架采用商业搜索API+网页过滤器+128K上下文窗口。R1-0528的搜索智能体结果通过预定义工作流进行评估。
- SWE-bench 使用我们内部的代码智能体框架进行评估。
- HLE 评估仅基于纯文本子集进行。
二、蓝耘元生代平台简介
蓝耘科技成立于2004年,完成从传统IT系统集成向GPU算力云服务的战略转型。凭借敏锐的市场洞察力,在算力资源管理调度、性能优化及运维运营等环节构建成熟可复制的工程化能力体系,服务覆盖高校科研、人工智能、自动驾驶、工业设计等多领域,为各行业创新发展提供坚实算力支撑,成为行业关键力量。蓝耘元生代平台主页如图2所示。
图2 蓝耘元生代平台主页
蓝耘元生代智算平台基于Kubernetes构建,提供高性能GPU集群,支持动态资源调配与分布式计算框架(如PyTorch、TensorFlow、DeepSpeed等),并具备自动化调度和故障恢复能力,可显著提升训练效率。其关键特性包括:灵活资源配置、分布式训练优化、实时监控界面。蓝耘元生代智算云架构如图3所示。

图3 蓝耘元生代智算云架构
三、蓝耘MaaS平台使用DeepSeek-V3.1模型
蓝耘MaaS平台,作为模型即服务(Model as a Service)的先行者,以创新的云计算平台模式,将训练有素的AI模型以标准化服务形式呈现给用户。其核心优势在于丰富的预训练模型库,涵盖自然语言处理、计算机视觉、语音识别等多个领域,用户无需从零开始训练模型,大大节省时间和资源。
(一)注册蓝耘智算平台账号
点击注册链接:https://cloud.lanyun.net//#/registerPage?promoterCode=0131
输入手机号获取验证码,输入邮箱(这里邮箱会收到信息,要激活邮箱),设置密码,点击注册。如图4所示。

图4 注册蓝耘智算平台账号
新用户福利:注册后可领取免费试用时长(20元代金券,可直接当余额来使用)。
若已经注册过帐号,点击下方"已有账号,立即登录"即可。
(二)进入蓝耘MaaS模型广场
登录后进入首页,点击"MaaS平台",如图5所示。
图5 进入蓝耘MaaS平台
接着进入MaaS平台的模型广场。在这里,用户可以看到多种来自不同供应商的模型,如DeepSeek、通义等。页面详细列出了模型名称、类型(如文本生成)、上下文长度等信息,还提供了API示例、查看详情和立即体验等操作选项。图6中展示的是蓝耘元生代MaaS平台的模型广场页面。
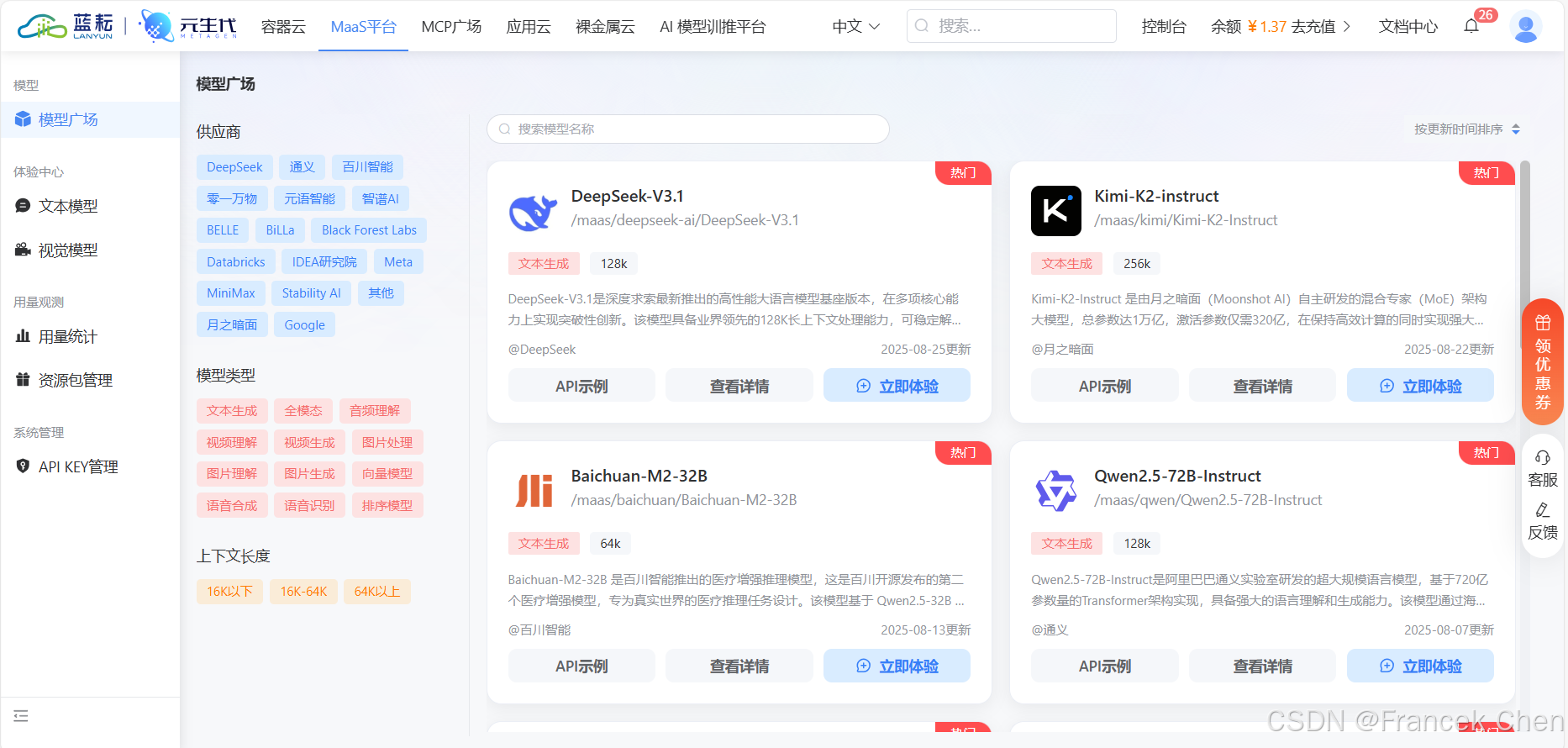
图6 蓝耘MaaS平台模型广场
然后,找到DeepSeek-V3.1大模型,点击"立即体验"。如图7所示。
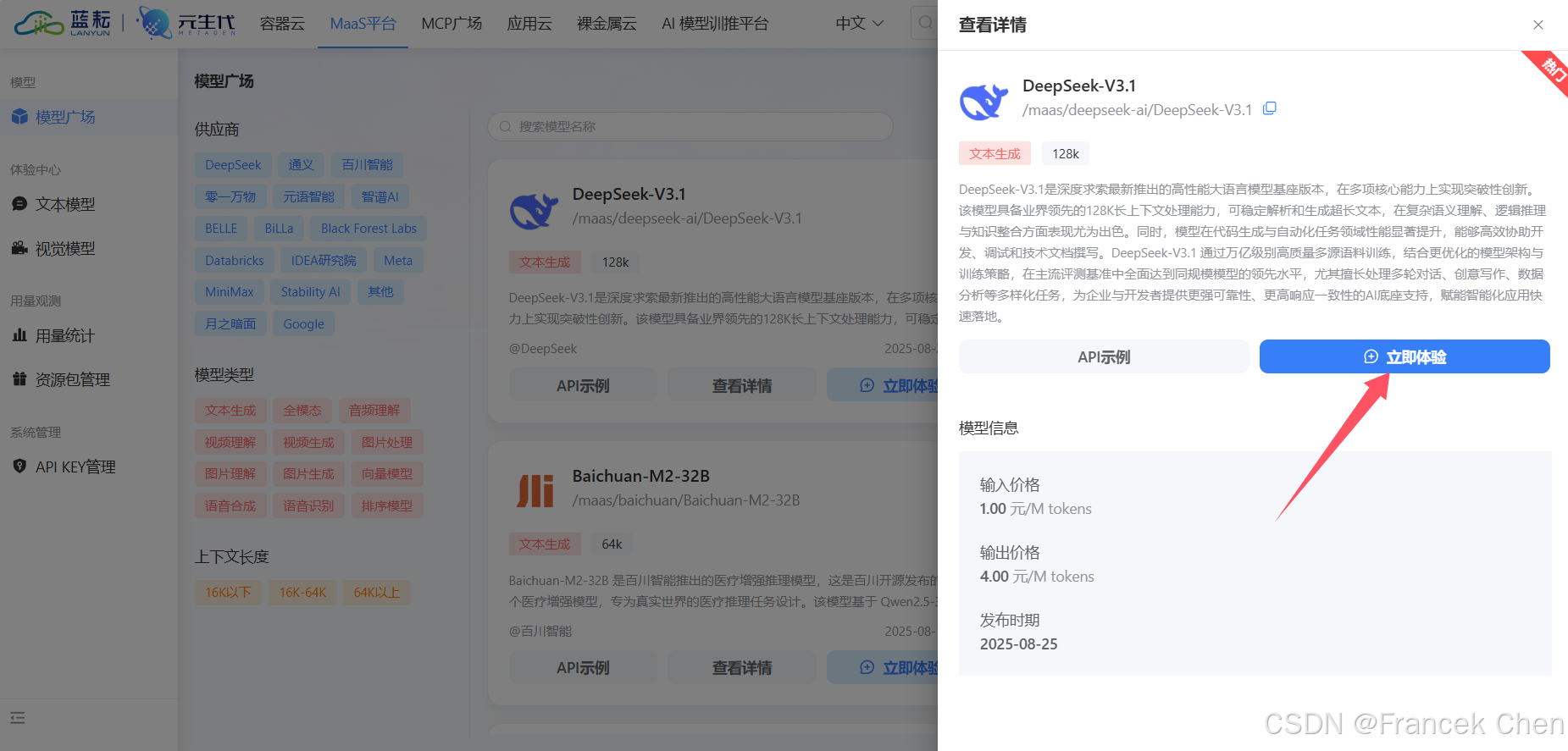
图7 蓝耘MaaS平台模型广场→DeepSeek-V3.1
图8中展示的是蓝耘元生代MaaS平台的对话界面。左侧是功能导航栏,包含模型广场、文本模型等选项。对话框上方是模型选择区域,点击可展开选择如DeepSeek-V3.1、QwQ-32B等多种模型。下方是对话输入区,用户可输入问题,有"深度思考""联网搜索"等功能按钮,输入框显示token限制。这里选择的是"DeepSeek-V3.1"模型。
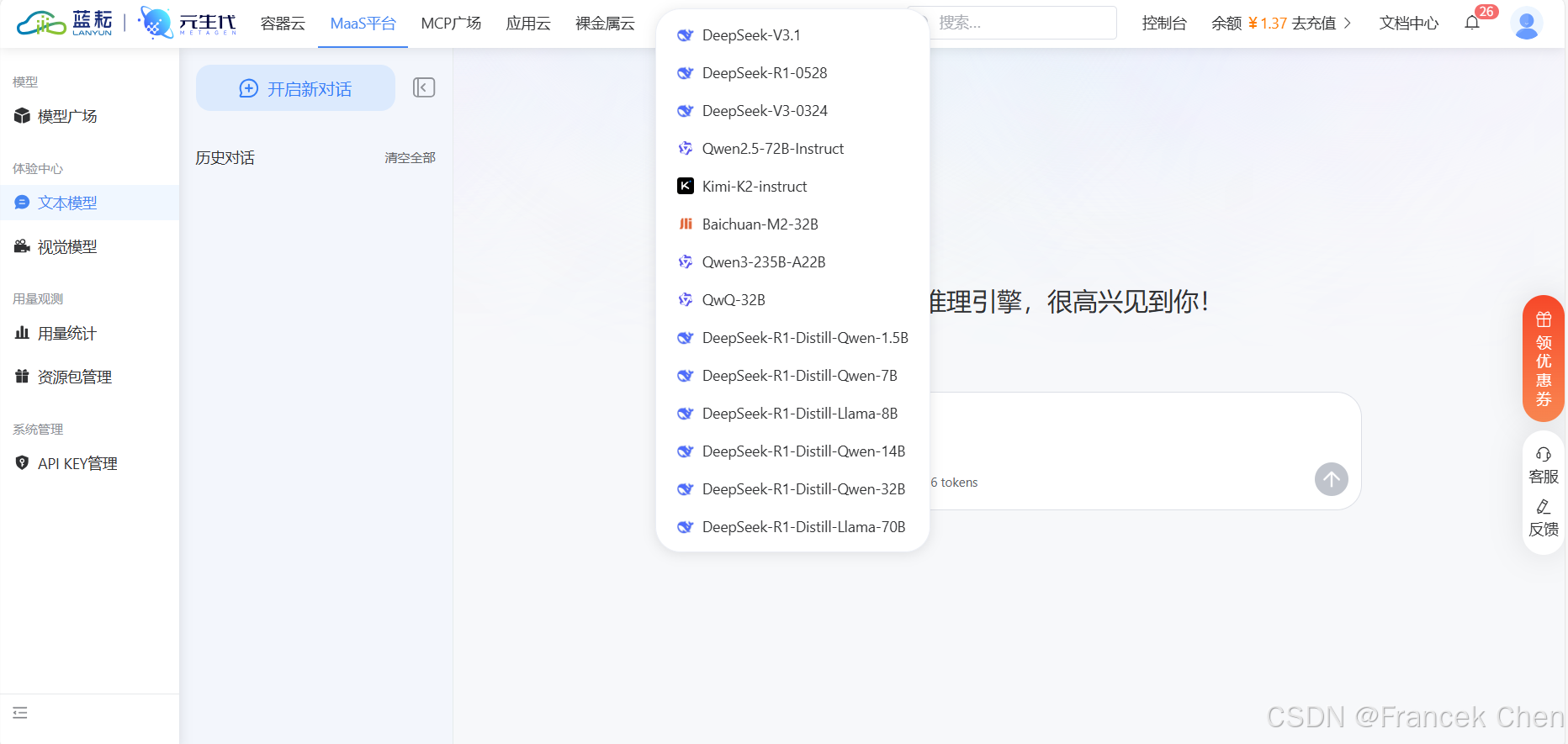
图8 蓝耘MaaS平台对话界面
(三)使用DeepSeek-V3.1模型生成文案
在输入框中输入提示词,然后回车,或者用鼠标点击提示词输入框右侧的箭头按钮,向DeepSeek-V3.1发起提问。DeepSeek-V3.1给出的回答如图9所示,需要注意的是,大模型属于概率模型,每次生成的回答内容可能不完全相同。提示词如下:
text
请为我规划一次为期一周的连云港自由行;
(1)第1步:列出必去的景点,如江苏海洋大学、花果山、连岛景区、云台山、桃花涧风景区、海州古城;
(2)第2步:根据景点位置安排每日行程,确保交通便利;
(3)第3步:推荐几家当地的特色餐厅,包括早餐、午餐和晚餐;
(4)第4步:提供一家性价比高的酒店住宿建议,并考虑其位置是否便于游览。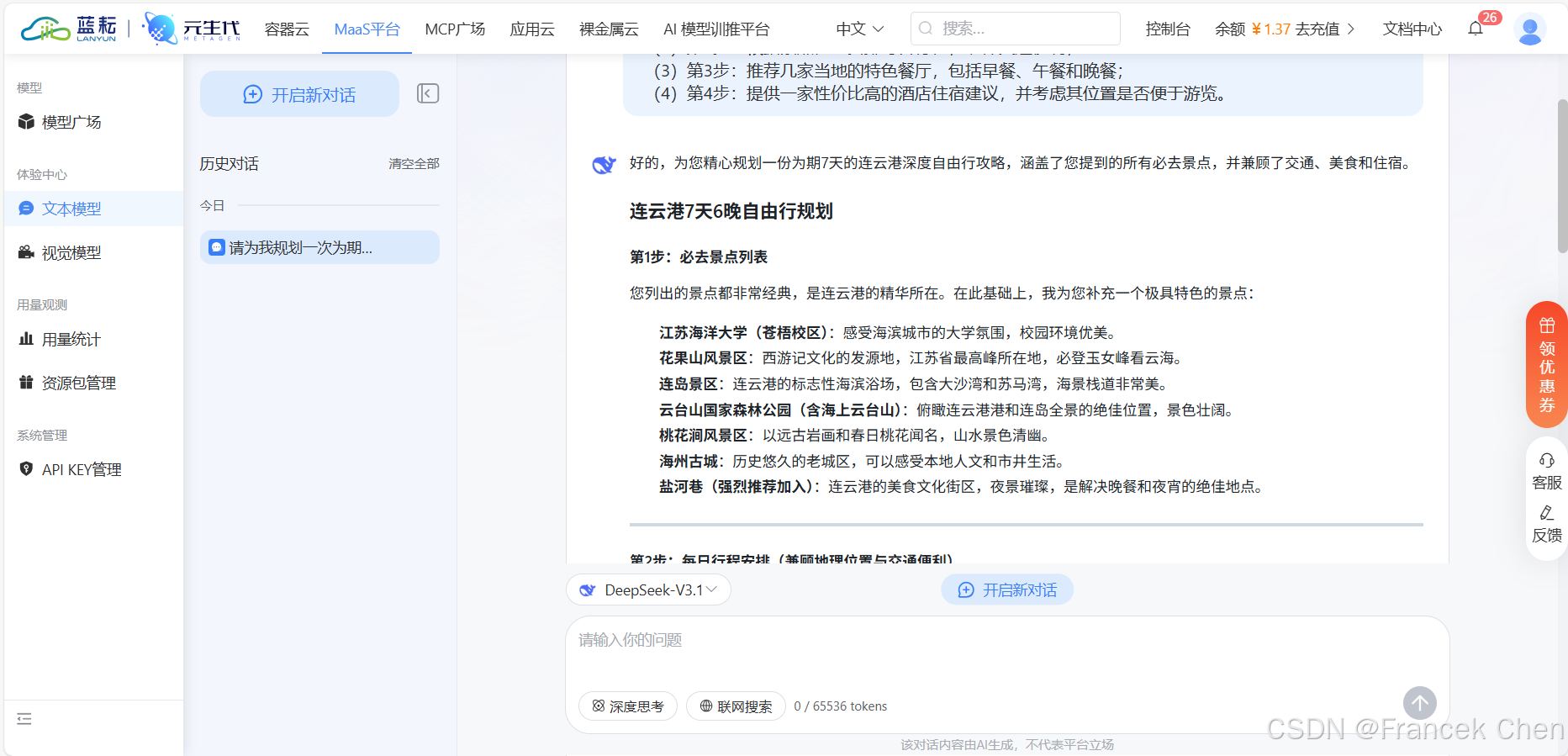
图9 DeepSeek-V3.1模型生成文案结果(1)
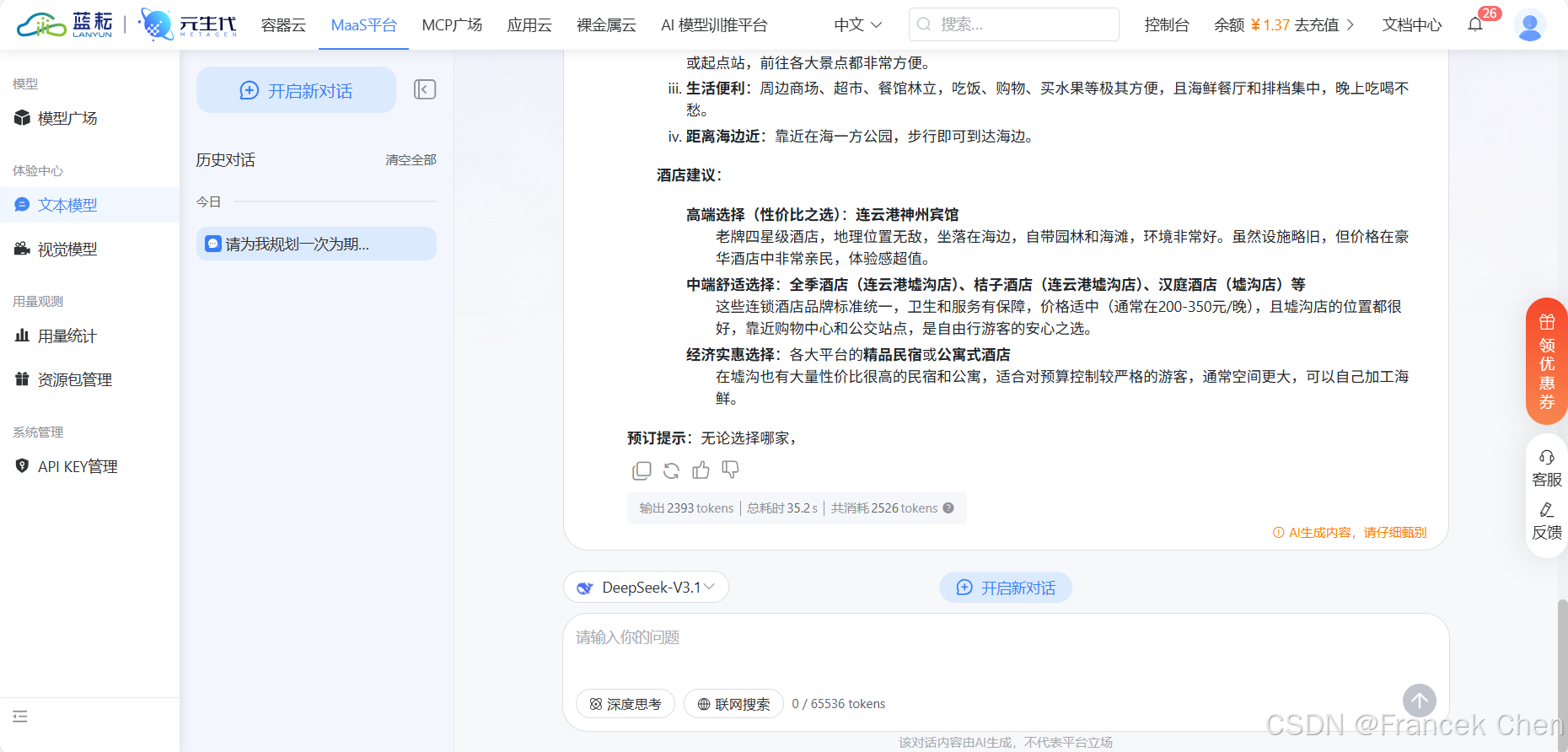
图10 DeepSeek-V3.1模型生成文案结果(2)
此次对话输出输出2393tokens,总耗时35.2s,共消耗2526tokens。该对话token消耗的数量=输入token数+输出token数。
(四)使用DeepSeek-V3.1模型生成代码
生成有关机器学习分类预测的代码,提示词如下:
text
帮我生成一段关于机器学习分类预测的代码,要求使用scikit-learn库。输出结果如图11所示。
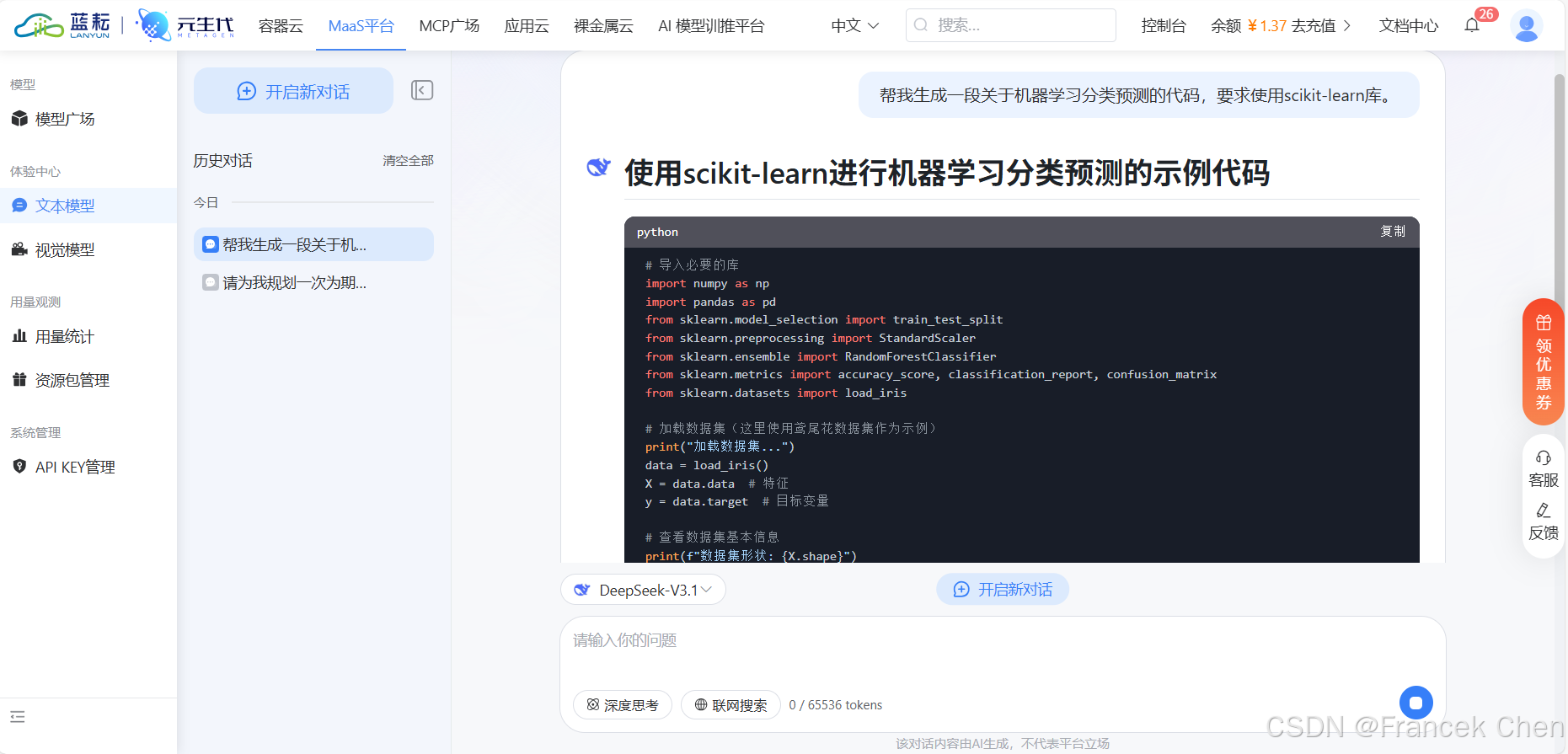
图11 DeepSeek-V3.1模型生成代码结果(1)
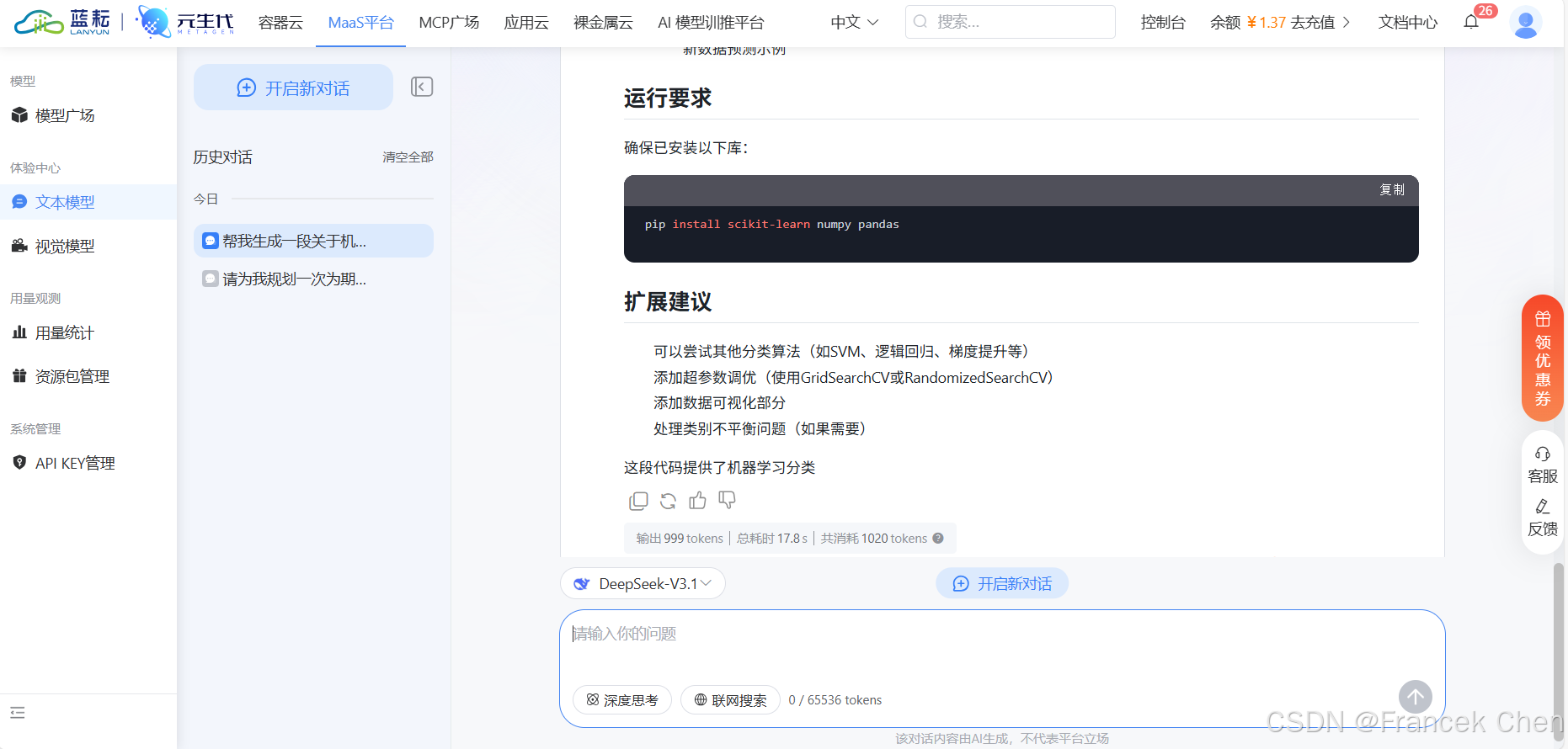
图12 DeepSeek-V3.1模型生成代码结果(2)
此次对话输出999tokens,总耗时17.8s,共消耗1020tokens。该对话token消耗的数量=输入token数+输出token数。
输出代码如下:
python
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.datasets import load_iris
# 加载数据集(这里使用鸢尾花数据集作为示例)
print("加载数据集...")
data = load_iris()
X = data.data # 特征
y = data.target # 目标变量
# 查看数据集基本信息
print(f"数据集形状: {X.shape}")
print(f"类别标签: {np.unique(y)}")
print(f"特征名称: {data.feature_names}")
print(f"目标名称: {data.target_names}")
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集大小: {X_train.shape[0]}")
print(f"测试集大小: {X_test.shape[0]}")
# 数据标准化(很多机器学习算法需要标准化数据)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建并训练随机森林分类器
print("训练模型...")
model = RandomForestClassifier(
n_estimators=100, # 树的数量
random_state=42, # 随机种子,确保结果可重现
max_depth=3 # 树的最大深度
)
model.fit(X_train, y_train)
# 在训练集上进行预测
y_train_pred = model.predict(X_train)
train_accuracy = accuracy_score(y_train, y_train_pred)
print(f"训练集准确率: {train_accuracy:.4f}")
# 在测试集上进行预测
print("进行预测...")
y_pred = model.predict(X_test)
test_accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {test_accuracy:.4f}")
# 输出详细的分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=data.target_names))
# 输出混淆矩阵
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# 预测新数据示例(使用标准化后的数据进行预测)
print("\n新数据预测示例:")
new_data = np.array([[5.1, 3.5, 1.4, 0.2]]) # 新样本
new_data_scaled = scaler.transform(new_data) # 使用相同的标准化器
prediction = model.predict(new_data_scaled)
predicted_class = data.target_names[prediction[0]]
print(f"预测类别: {predicted_class}")
# 获取特征重要性(对于树模型)
print("\n特征重要性:")
feature_importance = model.feature_importances_
for i, (feature, importance) in enumerate(zip(data.feature_names, feature_importance)):
print(f"{i+1}. {feature}: {importance:.4f}")
# 使用交叉验证获取更稳健的性能评估
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(model, X, y, cv=5)
print(f"\n5折交叉验证准确率: {cv_scores.mean():.4f} (+/- {cv_scores.std() * 2:.4f})")四、蓝耘平台免费送超千万Token
只需注册蓝耘平台账号,新用户即可轻松获赠千万Token!如此丰厚的Token免费资源包,具体使用细则详见图13。
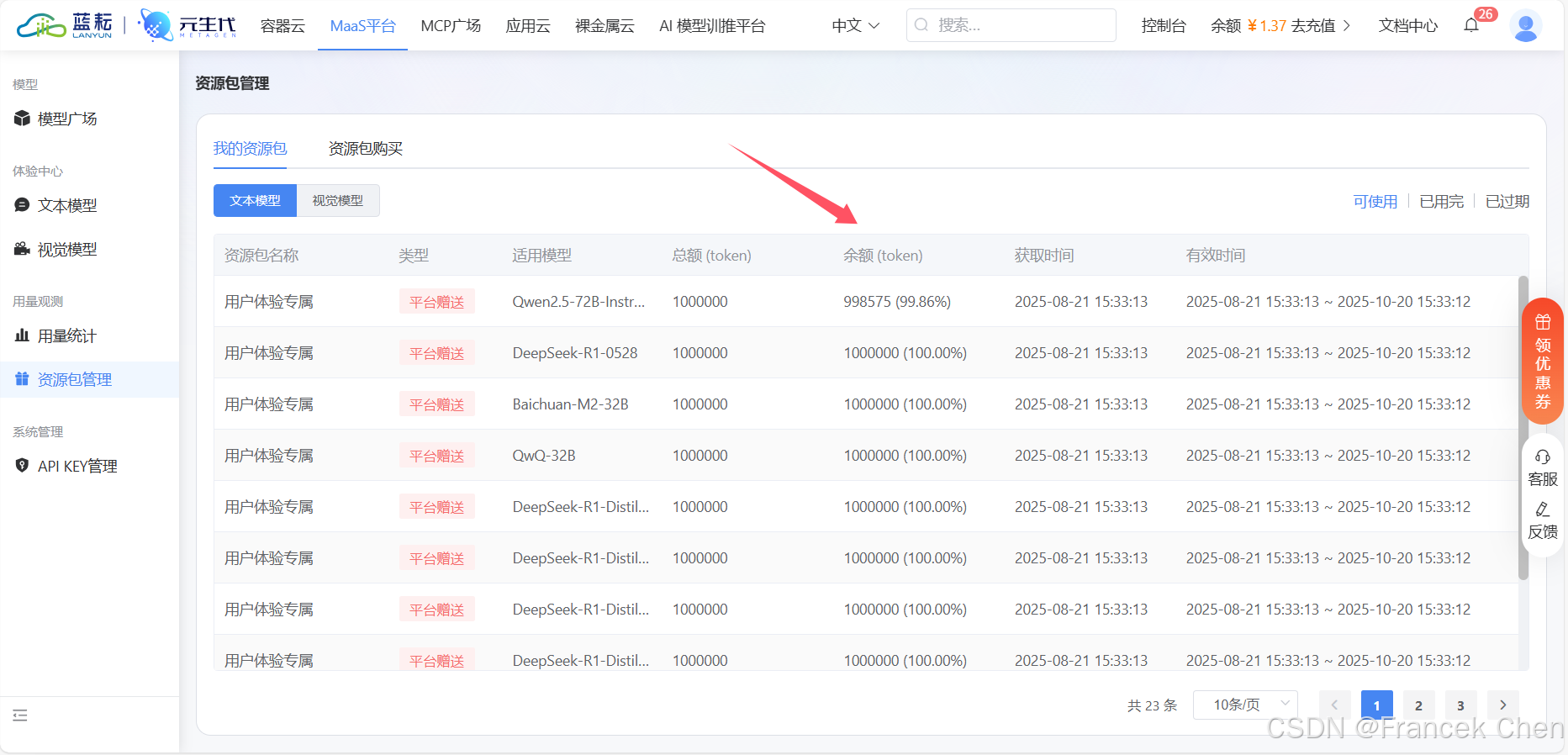
图13 Token免费资源包使用明细
关于Token的计算规则,我们为您详细说明:中文方面,1个汉字约计为1.2 Token;英文方面,1个英文单词则约计为1 Token。此外,使用API调用时,会额外消耗5%的系统Token。
以下是我们平台各项操作的Token消耗情况,供您参考:
| 操作类型 | 内容长度 | 消耗Token | 备注说明 |
|---|---|---|---|
| 文本分类 | 50字中文内容 | 60 Token | 此费用已包含系统开销 |
| 知识库查询 | 200字问题描述 | 250 Token | 包含向量检索费用 |
| 智能对话 | 10轮对话交流 | 约800 Token | 对话上下文越长,消耗Token越多 |
五、未来展望
在AI技术普惠化的时代浪潮下,DeepSeek-V3.1与蓝耘MaaS平台深度融合,共同开启智能应用发展的新纪元。DeepSeek-V3.1通过端侧部署创新,突破硬件限制,将大模型能力拓展至移动终端,构建起隐私安全与实时响应并重的智能生态系统,为用户提供全方位智能体验。蓝耘MaaS平台则依托弹性算力调度机制与"模型即服务"模式,大幅降低AI应用门槛,使中小企业无需承担高昂成本和复杂部署,即可轻松调用千亿参数模型,踏上AI赋能之路。
二者的协同创新推动了三大变革:其一,重塑人机交互模式,通过本地化多模态推荐技术实现服务零延迟精准触达,提升交互自然性与效率;其二,催生边缘智能新业态,在工业质检、智慧医疗等领域培育低功耗AI解决方案,助力行业智能化升级;其三,加速AI民主化进程,平台提供的免费资源包让数百万开发者可快速验证创意,激发创新活力。
展望未来,随着蓝耘持续优化分布式训练框架,DeepSeek-V3.1不断迭代多模态理解能力,双方有望构建"云端训练-边缘推理"的完整生态链。这一生态链将强化算力与模型的协同效应,为数字经济注入新动能,推动社会迈向更智能、高效的未来。
小结
本文聚焦DeepSeek-V3.1与蓝耘MaaS平台的协同创新价值。DeepSeek-V3.1通过轻量化设计、自适应部署系统突破硬件限制实现端侧智能,两阶段训练机制使推荐场景准确率提升35%;蓝耘MaaS平台依托弹性算力调度与丰富预训练模型库,大幅降低AI应用门槛。二者融合推动三大变革:重构人机交互范式、培育边缘智能新业态、加速AI民主化进程。实际案例验证其在创作辅助与算法开发领域的实用性,平台提供的千万级免费Token资源将助推开发者生态建设,为"云端训练-边缘推理"生态链发展注入新动能。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
