📌本篇摘要:
- 本篇将承接上次的**
UDP系列网络编程**,来深入认识下UDP协议的结构,特性,底层原理,注意事项及应用场景!


🏠欢迎拜访🏠:
点击进入博主主页
**📌本篇主题📌:**再续UDP协议
📅制作日期📅: 2025.09.01
🧭隶属专栏🧭:点击进入所属Linux专栏
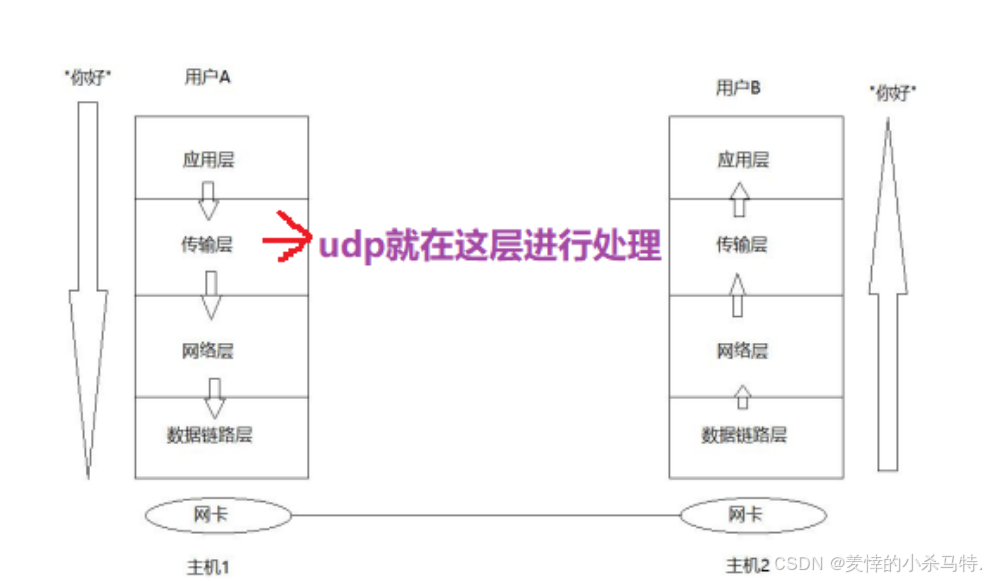
一. 🔍再识UDP协议
-
传输层: 负责数据能够从发送端传输到接收端。
-
可以先理解成用于数据在传输层封装的协议。
💡再认识传输层上面那常见的几个层结构:
会话层: 用于连接与断开的(如tcp)。
表示层: 可以理解成之前我们用于序列化与反序列化。
应用层: 用户设计一些通信完成的功能。
这里UDP就是在这层工作的:
二. 🔥重新认识下端口号
- TCP/IP协议(包含UDP)中常见五元组:"
源 IP", "源端口号", "目的 IP", "目的端口号", "协议号"(可以用netstat -n 查看)。
端口号范围划分
-
0 - 1023:知名端口号,HTTP, FTP, SSH等这些广为使用的应用层协议, 他们的端口号都是固定的。 -
1024 - 65535:操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的。</font>
认识知名端口号(Well-Know Port Number)
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下这些固定的端口号:
-
ssh 服务器,使用 22 端口。 -
ftp 服务器,使用 21 端口。 -
telnet 服务器,使用 23 端口。 -
http 服务器,使用 80 端口。 -
https 服务器,使用 443端口。
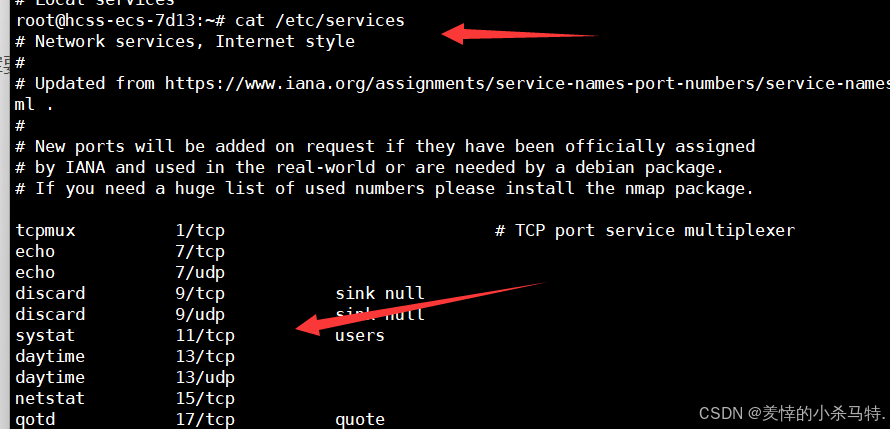
使用下面指令查看知名端口号(也就是我们网络通信的时候绑定要避开的端口号):
cpp
cat /etc/services如下:
💡重新认识下之前的两个问题:
- 一个进程是否可以
bind多个端口号? - 一个端口号是否可以被多个进程
bind?
原因:端口号的目的是通过它找到指定进程!
三.⚠️ UDP 协议端格式
首先看张图了解下:
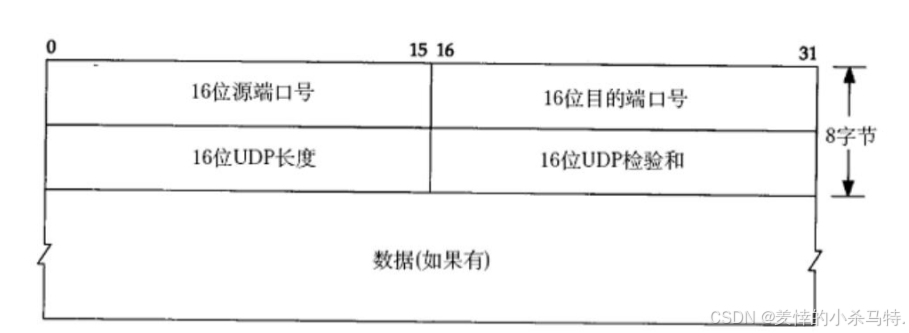
上面有了五大元组的目的端口号与源端口号(剩下的会在ip层完成封装)
-
16 位 UDP 长度:表示整个数据报(UDP 首部+UDP 数据)的最大长度。 -
16位UDP校验和:如果校验和出错,就会直接丢弃。
⚠️ 那么数据如果要是有的话,可以是2^16-1-8个字节数据, 如果比它多了就需要应用层手动的分包,多次发送,并在接收端手动拼装。
其实传输的就是上面样式的结构体:
cpp
struct udphdr {
uint16_t uh_sport;/* 源端口 */
uint16_t uh_dport;/*目的端口 */
uint16_t uh_ulen;/* UDP 长度 */
uint16 _t uh_sum;/*校验和 */
};因为内核规定的端口号就是16位,因此我们要传递的就是这个格式。
四. ⏳UDP特点
-
无连接:知道对端的 IP 和端口号就直接进行传输,不需要建立连接。 -
不可靠:没有确认机制,没有重传机制;如果因为网络故障该段无法发到对方,UDP 协议层也不会给应用层返回任何错误信息。 -
面向数据报:不能够灵活的控制读写数据的次数和数量。
下面再深入了解下不可靠性以及面向数据报:
1. 🎆对于它的不可靠性:
- udp无发送缓冲区,故不能像tcp那样可以先把数据储存在发送缓冲区,如果它的接收缓冲区满了导致没收到数据,就可以再次把保存在发送缓冲区的数据再发一次! udp如果发送的时候
接收缓冲区满了,或者其他原因就会丢包现象!
2. 🎆对于面向数据报:
- 应用层交给 UDP 多长的报文,UDP 原样发送,既不会拆分,也不会合并:
比如UDP传输100字节数据,如果发送端调用一次 sendto,发送 100 个字节,那么接收端
也必须调用对应的100次 recvfrom,接收 100 个字节; 而不能循环调用 10 次recvfrom,每次接收 10 个字节。
- 可以简单理解成udp对数据发的信息原样转发出去,不能像tcp那样灵活读取,这里就认为是一团数据,一口气发送或者接收!
五. UDP缓冲区
-
UDP 没有真正意义上的 发送缓冲区.调用 sendto 会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作。
-
UDP 具有接收缓冲区.但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致; 如果缓冲区满了,再到达的 UDP 数据就会丢弃。
这里有个疑问,为啥它没发送缓冲区?
-
1·
面向用户数据报:它只要遇到用户准备的数据就直接进行转发! -
2·
无连接特性:不用像tcp那样先连接好才能通信,需要等待这个时间,所以把它放到对应的发送缓冲区! -
3
.尽力而为服务:它是不可靠的,udp只管完成认为把用户准备发的信息发送出去,不管可靠交付、顺序到达以及无重复等! -
4.
实时性要求:一般适用于如音频、视频流的传输等需要实时更新的任务,如果设置了发送缓冲区,就会导致数据等待而产生延迟,这点就不能保证了!
六. 底层基于 UDP 的应用层协议
-
NFS:网络文件系统。 -
TFTP:简单文件传输协议。 -
DHCP:动态主机配置协议 比如路由器给电脑分配的ip地址。 -
BOOTP:启动协议(用于无盘设备启动)。 -
DNS:域名解析协议 http时候的解析域名成ip。 -
当然,也包括自己写 UDP 程序时自定义的应用层协议。
常用于 可靠性低 允许丢包 语音 比赛等实时性高的通信任务!
七. 🎃OS如何管理封装的报文
首先我们说到了UDP有接收缓冲区,当收到数据包的时候,OS也是需要管理的。
首先我们先理解一下sk _buff这里就是os用来管理在那几层传递的报文:
下面看张图(这里把TCP换成UDP是一样的):
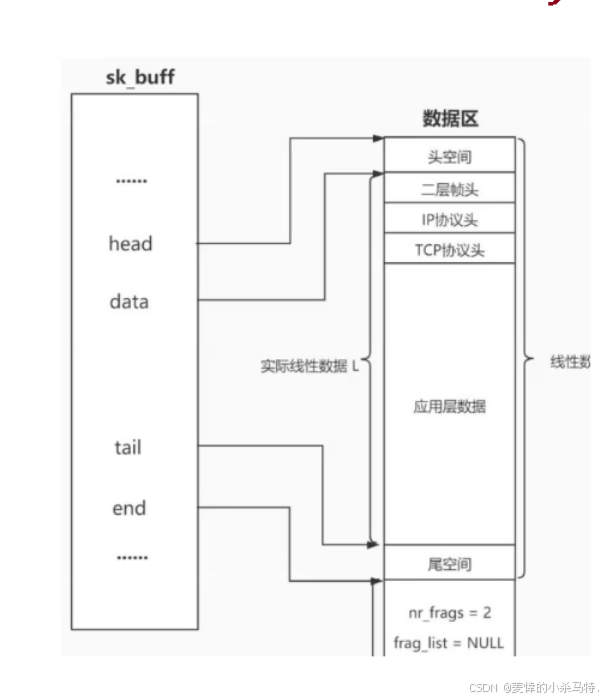
- 假设操作系统收到对应的报文,在链路层进行
"先描述后组织"(可以认为就是对sk_buff进行链表式的组织然后就能通过里面对应的指针找到内存里的数据!),再一层一层往上交互进行解包等操作。
这里只需要认识四个指针:
-
head,end就是对应的内存空间划分。 -
data,tail就会是对应数据,当进行发送就要添加不同层的报头,那么此时data就--,如果是进行接收也就是解包,此时data再++,tail标识的就是这段报文的结尾.
也就是根据 报文 =报头+ 有效载荷 这一原则进行的。
sk_buff结构代码如下:
cpp
struct sk_buff {
/* List management pointers */
struct sk_buff_head *list;
struct sk_buff *next;
/* Control buffer for private use */
char cb[48] __aligned(8);
/* Pointers to the data in the buffer */
unsigned char *head, *data;
unsigned char *tail, *end;
/* Length of the buffer */
unsigned int truesize;
/* Reference count */
atomic_t users;
/* State flags */
unsigned int state;
/* Destructor function */
void *destructor;
/* Protocol type */
__be16 protocol;
/* Length of the packet */
unsigned int len;
/* Length of the data in the buffer */
unsigned int data_len;
/* MAC header length */
__u16 mac_len;
/* Network header length */
__u16 network_header_len;
/* Transport header length */
__u16 transport_header_len;
/* Timestamp */
struct timespec64 tstamp;
/* Socket pointer */
struct sock *sk;
/* Network device pointer */
struct net_device *dev;
/* Space in front of data (headroom) */
unsigned int headroom;
/* Space at the end of data (tailroom) */
unsigned int tailroom;
};这里只需大致了解一下即可!
❗此时还有个小问题:
如果应用层正在进行报文的解析,处理,会不会影响OS继续从网络中读取报文?
- 答:不会,因此我们就可以知道,当udp在进行数据接收后在进行解析的时候(应用层),但是底层还是会不断接收信息(以sk_buff形式管理),也就是利用了os的中断机制了,
因此是可以同时进行的!
八. 📌UDP协议总结
🔍特性分析
-
**核心特性:**无连接、不可靠传输,以数据报为单位,首部仅8字节,传输效率高。
-
**优势:**无需建立连接,传输速度快、延迟低,支持广播/多播 ,资源消耗少。
-
**劣势:**不保障数据完整性、有序性,易丢包,网络差时问题更突出。
🔍应用场景及注意事项:
- 实时音视频(直播、视频会议、语音通话)
应用原因:低延迟保证画面、声音连贯性。
注意事项:需在应用层补充丢包恢复机制(如FEC前向纠错)、抗抖动缓冲处理。
- 在线游戏
应用原因:快速传输玩家操作信息,确保游戏流畅。
注意事项:增加状态同步机制,解决少量数据丢失或乱序问题。
- 网络管理(SNMP)
应用原因:频繁发送管理信息,UDP开销小更合适。
注意事项:关键管理指令需设计应用层确认重传机制。
- 广播与多播(网络电视、在线广播)
应用原因:支持同时向多目标发送相同数据。
注意事项:对带宽依赖高,需控制数据报大小,避免网络拥塞 。
九. 📌本篇小结
- 本篇介绍了在之前经历了
UDP编程后,有了一定基础认识,再深入的了解了UDP大致结构及相关信息后,更加丰富了对UDP的理解,后续将进行TCP相关的讲解,欢迎订阅!