一、先聊个扎心的场景:为啥没索引会 "等死"?
上次线上查用户订单,我写了句 select * from order where user_id=123,结果等了 18 秒 ------ 产品经理在旁边盯着,我手心全是汗。后来 DBA 扔来一句:"没建索引?全表扫描 100 万行,不死才怪!"
这就像你找一本没贴标签的书,得从书架第一本翻到最后一本;而索引,就是图书馆的 "检索架",直接告诉你书在第几排第几层。
二、3 分钟搞懂索引:是什么?为什么要?本质是啥?
1. 什么是数据库索引?
官方定义太绕,直白说:给数据贴的 "导航标签" 。比如给user表的user_id建索引,数据库查user_id=123时,不用扫全表,直接通过索引定位到数据所在的 "磁盘地址",一秒搞定。
2. 为啥非要建索引?
核心就一个:减少 IO 次数。
- 没索引:查 1 条数据,可能要读 100 次磁盘(全表扫描);
- 有索引:读 3 次磁盘就够(B + 树索引的三层结构)。
毕竟磁盘 IO 是 "慢动作",少一次就快一截。
3. 索引的本质是啥?
说穿了就是 "空间换时间" 的权衡 。
索引本身也是数据,要占磁盘空间(比如 100 万行的表,一个索引可能占 20MB),但换来了查询速度的飞跃。就像你给笔记本做笔记,笔记占页数,但复习时不用重看全书 ------ 这买卖不亏。
三、索引怎么干活的?用 B + 树给你画个图
大部分数据库(MySQL、PostgreSQL)的索引用B + 树,这玩意儿像 "倒过来的树",分三层:
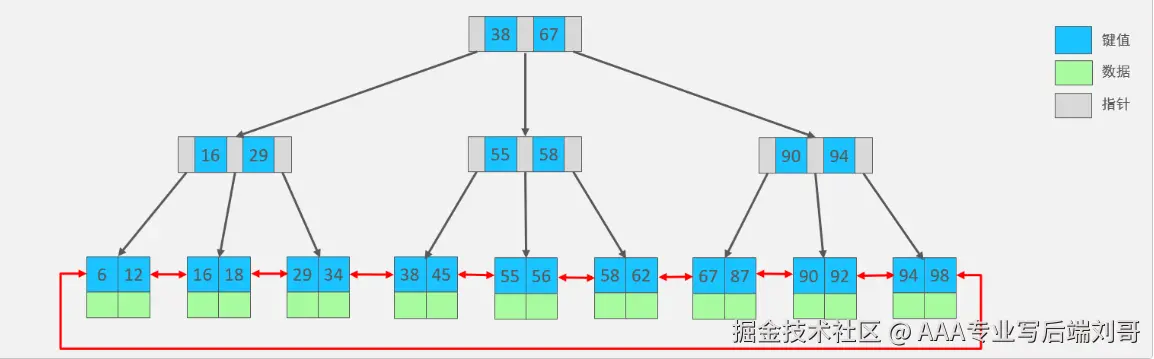
- 根节点:最上层导航(比如 "user_id 1-1000 放左子树,1001-2000 放右子树");
- 中间节点:分类筛选(比如 "1-500 放左,501-1000 放右");
- 叶子节点:存真实数据地址(InnoDB 的聚簇索引直接存数据)。
查user_id=666时,路径是:根节点→中间节点(501-1000)→叶子节点(666 的地址),3 步到位,不用扫全表。
四、10 道索引面试题:面试官常问,我踩过的坑都在这
1. 为啥加了索引,查询还是慢?
别慌!大概率是这 4 个坑:
- 坑 1:索引没用到(比如用了函数:left(name,2)='张',索引直接失效);
- 坑 2:数据量太小(表就 10 行,数据库觉得全表扫描更快,懒得用索引);
- 坑 3:索引建错了(查age却建了name索引,白搭);
- 坑 4:索引碎片多(长期增删改后,索引文件碎片化,查数据跳来跳去)。
解决:用 EXPLAIN 看执行计划, key 字段为 NULL 就是没用到索引。
2. 索引是不是越多越好?
绝对不是!索引多了,写入会变慢。
比如你给order表建了 5 个索引,插一条数据时,不仅要改表数据,还要同步更新 5 个索引文件 ------ 相当于你写一篇文章,要同步发 5 个平台,能不慢吗?
建议:一张表建 3-5 个索引,够用就行。
3. 联合索引的 "最左前缀原则" 是啥?
面试必问!联合索引就是多个字段一起建的索引(比如(name, age, gender)),最左前缀原则是:
必须从索引的 "最左边" 字段开始用,不然索引失效。
比如:
- 查age=25:没带name,索引失效;
- 查name='张三' and gender='男':带了name,索引能用;
- 查name='张三' and age=25:能用,且比只查name更快。
简单记:联合索引像糖葫芦,得从第一个糖球开始吃,不能跳。
4. 怎么选联合索引的字段顺序?
核心原则:过滤性强的字段放前面。
过滤性强 = 字段取值重复率低,比如name(每个人名字不同)比age(很多人 25 岁)过滤性强,所以(name, age)比(age, name)好。
另外,常出现在 where 里的字段放前面,比如每次查都带name,就把name放第一。
5. 覆盖索引是啥?为啥重要?
覆盖索引 =索引包含了查询需要的所有字段,不用再 "回表" 查数据。
比如建了(name, age)索引,查select name, age from user where name='张三',直接从索引里拿数据,不用再去主键索引(聚簇索引)找全行数据 ------ 少一次 IO,速度直接翻倍!
MySQL 执行计划里的 "Using index",就是用到了覆盖索引,这是优化的大杀器。
6. NULL 值对索引有影响吗?
有坑!但不是不能存 NULL:
- 能用is null查(比如where age is null),索引能用;
- 不能用=null查(where age=null),索引失效(因为 NULL 不等于任何值,包括它自己);
- 字段经常为 NULL,索引效率会降(要单独处理 NULL 的存储)。
建议:给索引字段设默认值(比如默认 0、默认空字符串),别让它为 NULL。
7. 索引对排序 / 分组有啥影响?
索引的 "有序性" 能帮排序 / 分组省大事!
比如建了age索引,查select * from user order by age,数据库直接按索引顺序取数据,不用额外 "文件排序"(filesort);如果没索引,就得先查数据,再放内存排序(数据多了还得写临时文件,贼慢)。
注意:排序字段要和索引顺序一致,比如索引是 age asc ,别用 order by age desc ,不然可能失效。
8. 怎么发现索引失效的场景?
用EXPLAIN分析执行计划,看这 3 个关键点:
- type:显示ALL= 全表扫描,索引没用到;
- key:显示NULL= 没用到索引;
- Extra:有Using filesort/Using temporary= 排序 / 分组没用到索引,效率低。
另外记几个常见失效场景:索引字段用函数、用!=/not in、字符串没加引号(比如name=123,实际name是 varchar)。
9. 怎么维护和优化索引?
分 4 步走,别等出问题再搞:
- 删无效索引:用sys.schema_unused_indexes(MySQL)找长期没用到的索引,占空间还拖慢写入;
- 清索引碎片:InnoDB 用alter table 表名 engine=InnoDB重建索引,整理碎片;
- 监控慢查询:开启慢查询日志(slow_query_log),找慢 SQL,看是不是索引没建好;
- 删重复索引:比如建了(name)又建(name, age),(name)就是重复的,删掉!
10. 不同数据库的索引有啥差异?
别只懂 MySQL,面试官可能问跨库差异:
| 数据库 | 索引类型 | 核心特点 |
|---|---|---|
| MySQL(InnoDB) | B + 树索引 | 聚簇索引(存数据)+ 二级索引(存主键) |
| MySQL(MyISAM) | B + 树索引 | 非聚簇索引,索引和数据分开存 |
| Oracle | B 树 / 哈希 / 位图 / 函数索引 | 支持函数索引(如upper(name)) |
| MongoDB | B 树 / 地理空间 / 文本索引 | 适合非结构化数据,支持文本检索 |
五、最后说句大实话
索引不是 "建了就完事",而是要 "跟着业务调"。比如业务从 "查 name" 变成 "查 age",就得及时加 age 索引、删没用的 name 索引。
如果老铁们有索引踩坑经历,或者想深入了解 "聚簇索引 vs 非聚簇索引",评论区喊我,下次专门写一篇!
觉得有用的话,点赞 + 收藏,面试前翻出来看,准能少慌一会儿~